断言匹配的不是文本,而是位置。
常见的断言有三种:单词边界,行起始/结束位置,环视。
单词边界
在文本处理中,经常会进行单词替换,比如将一段文本中的row替换成line。
替换前:The row we are looking for is row 10.
替换后:The line we are looking for is line 10.
不过,这样的替换也可能造成错误
替换前:Tomorrow I will wear a brown shirt in row 10.
替换后:Tomorline I will wear a blinen shirt in line 10.
为了解决这个问题,必须要有办法确定是单词row,而不是字符串row,为此,正则提供了单词边界,记为\b。它匹配的是位置(单词边界),而不是字符。\b能够匹配的是在这样的位置:一边是单词字符,另一边不是单词字符。单词字符是指\w(0-9a-zA-Z_)能匹配的字符。
'Tomorrow I will wear a brown shirt in row 10'.replace(/\brow\b/,'line')// Tomorrow I will wear a brown shirt in line 10
与\b对应的是\B,指非单词边界。因此[\b\B]也能够表达任意字符。
行起始/结束位置
- ^默认情况下这只能匹配整个字符串的开始位置,如果指定多行模式,则可以匹配字符串内部文本行的开始位置
- $默认情况下这只能匹配整个字符串的结束位置,如果指定多行模式,则可以匹配字符串内部文本行的结束位置
- 即便字符串末尾有换行符,$也只能匹配字符串的结束位置,而不会匹配末尾换行符之前的位置。所以进行验证的时候,可以放心的在表达式里使用^和$ ```javascript /^1/.test(‘1\n2’) // true /^2/.test(‘1\n2’) // false /^2/m.test(‘1\n2’) // true
/2$/.test(‘1\n2’) // true /1$/.test(‘1\n2’) // false /1$/m.test(‘1\n2’) // true
<a name="1911e"></a># 环视单词边界匹配的是这样的位置:一边是单词字符,一边不是单词字符。从另一个角度来看,它能进行这样的判断:在某个位置向左/向右看,必须出现或不能出现某类字符。正则表达式提供了环视,在它旁边的文本需要满足某种条件,而且本身并不匹配任何字符。| 名字 | 记法 | 判断方向 || --- | --- | --- || 肯定顺序环视(positive lookahead) | (?=regexp) | 向右 || 否定顺序环视(negative lookahead) | (?!regexp) | 向右 || 肯定逆序环视(positive lookbehind ES2017+) | (?<=regexp) | 向左 || 否定逆序环视(negative lookbehind ES2017+) | (?<!regexp) | 向左 |例如,对于字符串'12345',4种环视能匹配的位置<br />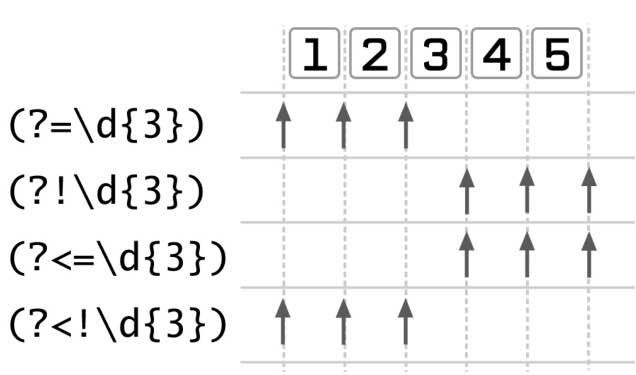<br />例如,格式化金额显示1234567->1,234,567```javascript// 我们需要把逗号添加到这样的位置:左侧是数字字符,右侧的数字字符串的长度是3的倍数,这里的数字字符串要是整个数字字符串,而不能是它的某一个子串,也就是要一直匹配到右侧不能再有数字字符的位置。'1234567'.replace(/(?<=\d)(?=(\d{3})+(?!\d))/g,',') // 1,234,567
观察这个例子可以发现,出现了环视的 嵌套 和 并列 两种组合结构

若有收获,就点个赞吧
0 人点赞
