1.nosql数据库
非关系型数据库
- 不遵循sql标准
- 不支持acid
-
1.1nosql适用场景
高并发
- 海量数据的读写
-
1.2nosql不适用场景
需要事务
-
2.redis数据类型
redis 单线程操作 redis就是单线程+io复用实现的
2.1 String类型key->value 二进制安全的 value最大为512M 类似于ArrayList

如图所示 像ArrayList一样,先放分配一块空间,然后设定一个可扩容长度,如果超过这个值就会扩容
如图中所示,内部为当前字符串实际分配的空间 capacity一般要高于实际字符串长度len.当字符串长度小于 1M时,扩容都是加倍现有的空间,如果超过 IM,扩容时一次只会多扩 IM 的空间。需要注意的是字符串最大长度为 512M
- get
- set
- append 拼接value
- setnx 没有key才能设置 key的值
- strlen value 长度
- incr 原子加一 也就是线程之间不会打断 因为是单线程操作
- decr 原子减一 也就是线程之间不会打断 因为是单线程操作
- incrby key 步长 每次加步长长度
- mset
- mget
- msetnx
- getrang 0 3 获取value0-3 有值的value
- setrang 3 value 在第三个位置插入value
- setex key 过期时间 value
-
2.2 List列表 结构就是双向链表结构 查询效率比较低
lpush/rpush key value value ….. 从左插入多个值/从右边插入多个值
lpush hhh v1 v2 v3 lrang hhh 0 -1 "v3" "v2" "v1" 懂了吗?lpop/rpop key 从左边/右边吐出一个值 键在值在,键亡值亡
- rpoplpush key1 key2 从列表右边吐出一个值 加入到左边
- lrang key 0 -1 取所有的value
- index key 按照下标获取value
-
2.3 Set string类型的无序集合。它的底层就是一个value为null的hash表,所以添加、删除、查找都是o(1)级别也就是数据不管多少,查询时间不变,因为使用hash算法,就计算一次hash值
sadd key value…..
- smembers key
- sismember key 查看是不是存在这个value 有1 无0
- scard key 集合个数
- srem key value… 删除集合某个元素
- srandmember key n 随机取出n个值,不会从集合删除
- smove
- sinter key1 key2 返回两个集合的交集
- sunion key1 key2 返回两个集合的并集
- sdiff key1 key2 返回两个集合的差集(key1包含,不包含key2的)
Java中 Hashset 的内部实现使用的是 HashMap,只不过所有的value 都指向同一个对象。Redis 的set 结构也是一样,它的内部也使用 hash结构,所有的value 都指向同一个内部值
2.4Hash key ->key:value形式 string类型的field和value的映射表
- hset key field value
- hget key field
- hmset key field value field value ….. 添加多个键值对
- hexiste key field 查看key的field是否存在
- heys key 列出该hash集合所有field
- hkeys key 查出hash所有的value
- hincrby key key field 步长 为key的field的值原子 +1 或者-1
- hsetnx key field value 将hash 的key的field的值设为value 仅在field不存在的时候
Hash 类型对应的数据结构是两种:ziplist(压缩列表),hashtable〔哈希表)。当field-value 长度较短且个数较少时,使用ziplist,否则使用 hashtable
2.5 Zset 和set很相似 没有重复元素的有序的字符串集合
- zadd key score value score value…… 一个或者多个元素和score(排名)值加入 有序key中 按score做排序
- zrange key 0 -1 +/withscore
- zrangebyscore key min max [withscore]
- zrevrangebyscore key max min [wirhscore] 按照你的max ->min 排序
- zincrby key score value 指定value 的score加值
- zrem key value 删除value
- zcount key min max 统计min-max的值
- zrank key value 返回集合中的排名
Sortedset (zset)是Redis 提供的一个非常特别的数据结构,一方面它等价于 Java的数据结Map
两种数据结构(什么时候使用压缩列表什么时候使用跳表)
1.有序集合保存的元素数量小于128个
2.有序集合保存的所有元素的长度小于64字节 类似hashmap自动从二叉树转成红黑树
- hash 的作用就是关联元素 value 和权重 score,保障元素 value 的唯一性,可以通过元素 value 找到相应score值
- 跳跃表,跳跃表的目的在于给元素 value 排序,根据 score 的范围获取元素列表
3.跳跃表 它的索引就是用二分法建立索引(跳表)
1.简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现 ,可以用数组、平衡树、链表等。数组不便元素的插入,删除;平衡树或红黑树里然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单 我们使用普通的链表的时间复杂度是O(n)级别 而跳表是O(logn)
有序链表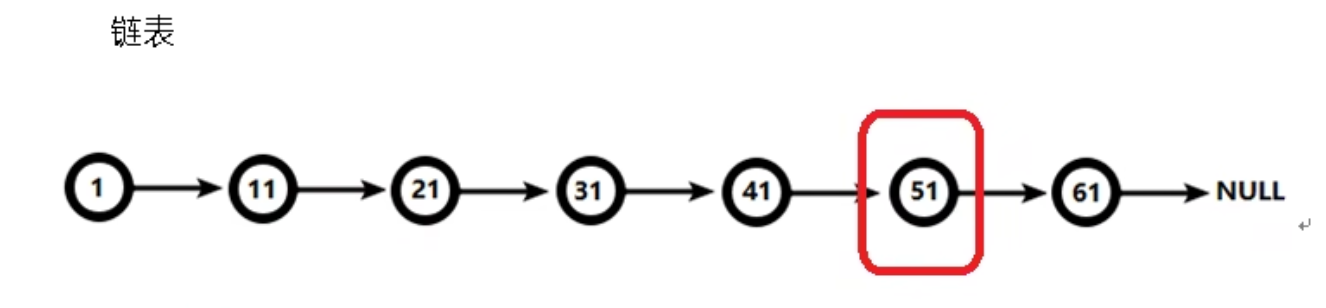
跳表结构 ```java
/**
```java
/**
- 跳表的一种实现方法。
跳表中存储的是正整数,并且存储的是不重复的。 */ public class SkipList {
private static final int MAX_LEVEL = 16;
private int levelCount = 1;
private Node head = new Node(); // 带头链表
private Random r = new Random();
public Node find(int value) {
Node p = head; for (int i = levelCount - 1; i >= 0; --i) { while (p.forwards[i] != null && p.forwards[i].data < value) { p = p.forwards[I]; } } if (p.forwards[0] != null && p.forwards[0].data == value) { return p.forwards[0]; } else { return null; }}
public void insert(int value) {
int level = randomLevel(); Node newNode = new Node(); newNode.data = value; newNode.maxLevel = level; Node update[] = new Node[level]; for (int i = 0; i < level; ++i) { update[i] = head; } // record every level largest value which smaller than insert value in update[] Node p = head; for (int i = level - 1; i >= 0; --i) { while (p.forwards[i] != null && p.forwards[i].data < value) { p = p.forwards[I]; } update[i] = p;// use update save node in search path } // in search path node next node become new node forwords(next) for (int i = 0; i < level; ++i) { newNode.forwards[i] = update[i].forwards[I]; update[i].forwards[i] = newNode; } // update node hight if (levelCount < level) levelCount = level;}
public void delete(int value) {
Node[] update = new Node[levelCount]; Node p = head; for (int i = levelCount - 1; i >= 0; --i) { while (p.forwards[i] != null && p.forwards[i].data < value) { p = p.forwards[I]; } update[i] = p; } if (p.forwards[0] != null && p.forwards[0].data == value) { for (int i = levelCount - 1; i >= 0; --i) { if (update[i].forwards[i] != null && update[i].forwards[i].data == value) { update[i].forwards[i] = update[i].forwards[i].forwards[I]; } } }}
// 随机 level 次,如果是奇数层数 +1,防止伪随机 private int randomLevel() {
int level = 1; for (int i = 1; i < MAX_LEVEL; ++i) { if (r.nextInt() % 2 == 1) { level++; } } return level;}
public void printAll() {
Node p = head; while (p.forwards[0] != null) { System.out.print(p.forwards[0] + " "); p = p.forwards[0]; } System.out.println();}
public class Node {
private int data = -1; private Node forwards[] = new Node[MAX_LEVEL]; private int maxLevel = 0; @Override public String toString() { StringBuilder builder = new StringBuilder(); builder.append("{ data: "); builder.append(data); builder.append("; levels: "); builder.append(maxLevel); builder.append(" }"); return builder.toString(); }}
}
<a name="xOL5v"></a>
## 4.Redis发布和订阅(MQ MQ MQ)
类似于MQ的消息模式 消费者模式 <br />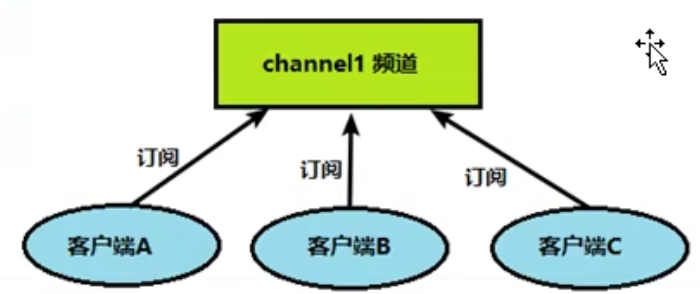
<a name="PmAns"></a>
## 5.新的数据类型 Redis6 Bitma

- setbit key offset(偏移量) value
- gitbit key offset
- bitcount start end
- bitop and (or/not/xor) destkey key.......
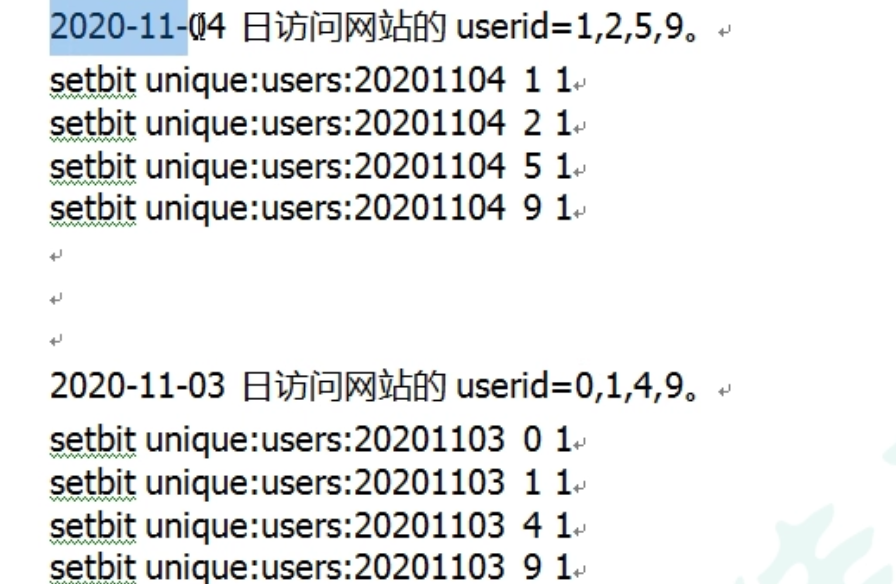
- 例子
- 
```java
bitop and unique:users:20201104_03(这个是起的名字类似mysql索引的别名) unique:users:20201103 unique:users:20201104
查出来是2因为两天只有两个id都访问了
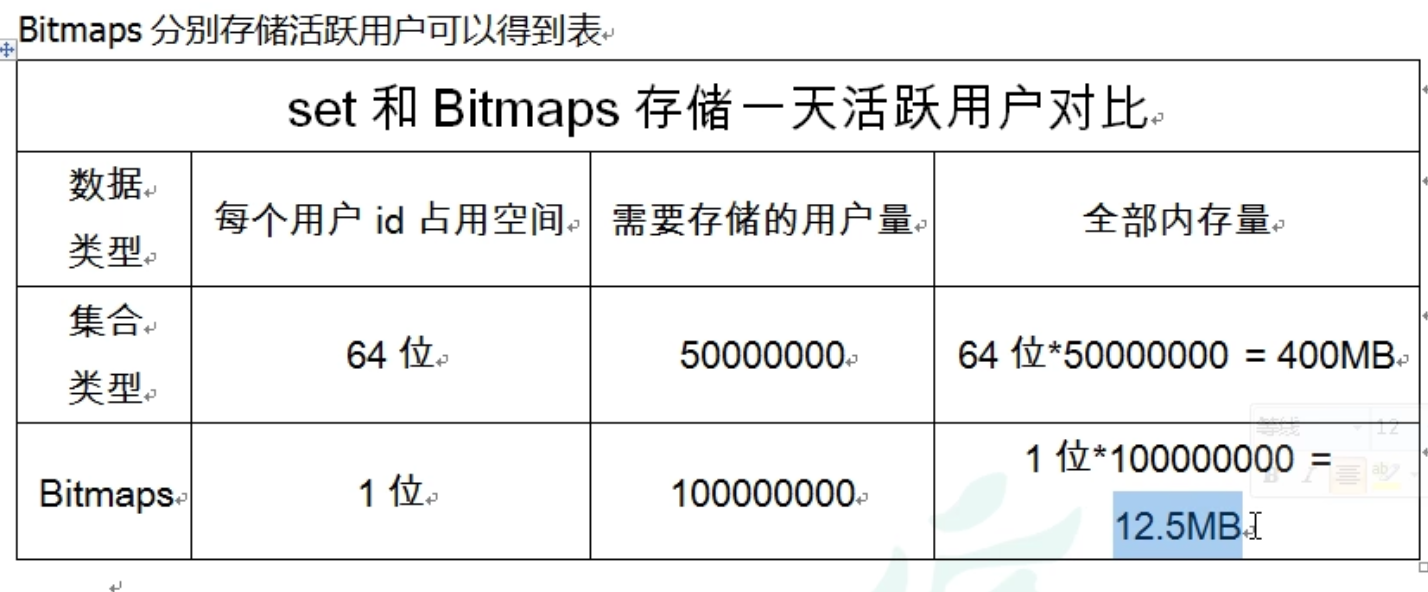
5.1BitMaps和Set比较

6.HyperLogLog

基数就是不重复元素{1,3,4,5,5,7,7}基数为5 说白了就是不可重复的数组
- pfadd key element……
- pfcount key
pfmerge key value….. 合并 value
pfcount program 此时value 是两个 pfadd k1 "a" pfadd k1 "b" pfcount k1 此时这个value是两个 pfmerge k100 k1 program (program有两个值) pfcount k100 此时有四个值 k1的两个 program两个7.Geospatial(地图坐标)
两极无法直接添加,一般会下载城市数据,直接通过 Java程序一次性导入。
有效的经度从-180 度到 180 度。有效的纬度从-85.05112878 度到85.05112878度 当坐标位置超出指定范国时,该命公将会返回一个错误geoadd key longitude latitude value ……..
- geopos key value 取到指定value的经纬度
- geodist key value1 value2 [m/km/mi(英里)/ft(英尺)] 获取两个位置之间的直线距离
- georadius key longitude latitude long(方圆多少) [m/km/mi/ft] 以给定的经纬度为中心,找出某一半径内的元素
8.Jedis操作redis
无用,不用学了9.SpringBoot整合Redis
配置类:网上搜一下一次一大把redisTemplate.opsForValue().set("",""); redisTemplate.opsForValue().get("","");
高级篇
10.redis 事务 锁机制 秒杀
redis的事务是啥? Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序的执行。事务在执行的过程中,不会被其他客户端发送来的命令打断,(大白话解释,串行化,就是一根筋,单线程,独瘤)说的尼玛高大上,真恶心 术业有专攻,闻道有先后!!!天天整一些名词恶心人10.1Multi、Exec、discard

- 第一步 组队阶段:将所有命令放入队列
- 第二步 执行阶段 exec 将所有放入队列的命令执行 类似commit
第三不 如果你执行一半不想执行了怎么办,discard 停止事务 类似于Mysql的Rollback回滚
10.2事务错误处理
组队过程中都有一个失败就都失败
-
10.3事务的冲突问题

嗨嗨嗨 悲观锁行锁 表锁,读锁写锁 上厕所例子
乐观锁 生产消费者模式,每次来检查版本号 类似mvcc 的版本机制 隐藏列trx_id 查询版本号 乐观锁通常和自旋搭配 这里bb说了一大堆,屁用没有
10.4乐观锁的使用
WATCH key …. 监视key 的 multi 判断版本号
在执行multi 之前,先执行 watch key1 Ikey2],可以监视一个(或多个)key,如果在事务执行之前这个(或这些)key 被其他命令所改动,那么事务将被打断。10.5Redis事务特性
单独的隔离操作
- 事务所有命令都会序列化、按顺序的执行。事务在执行的过程中,不会被其他客户端发来的命令打断
- 没有隔离级别的概念
- 队列的命令没有提交之前都不会实际被执行,因为事务提交前任何指令都不会被实际执行
- 不保证原子性
- 事务如果有一条命令执行失败,其余的命令仍然会被执行,没有回滚。

若有收获,就点个赞吧
0 人点赞
