
day01:mybatis plus
Mybatis是什么?
Mybatis-Plus是什么?
答案:是mybatis的增强工具,在 MyBatis 的基础上只做增强不做改变
Mybatis-Plus相对于Mybatis的优点是什么?
答:(1)某种程度上可以减轻开发人员的工作负担,简单的单表的增删改查的sql已经由Mybatis- Plus的底层实现,开发人员只需要写复杂sql
(2)Mybatis-Plus内置代码生成器,可以直接提供官方提供的代码快速生成符号开发人员 各异性需求的mapper,pojo,service,controller等模板,减轻开发人员工作量
(3)具有自动填充功能
(4)支持构造者模式
(5)分页功能相较于mybatis更加简便
Mybatis-Plus所需依赖
现行市场spring-boot泛用性广,考虑到有部分可能不使用该技术,故提供以下两种核心依赖
普通Maven项目下的依赖<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus</artifactId><version>3.4.2</version></dependency>SpringBoot环境下的MP(项目中使用)<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.1</version></dependency>
Mybatis-Plus模板制作流程
1)数据库环境准备:建立数据库,创建表格,考虑到工作以后都是linux操作系统,故在虚拟机的Mysql数据库创建数据库和表,示例如下:
CREATE DATABASE /*!32312 IF NOT EXISTS*/`mp_db` /*!40100 DEFAULT CHARACTER SET utf8 */;USE `mp`;SET NAMES utf8mb4;SET FOREIGN_KEY_CHECKS = 0;-- ------------------------------ Table structure for tb_user 没有给自增-- ----------------------------DROP TABLE IF EXISTS `tb_user`;CREATE TABLE `tb_user` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`user_name` varchar(255) DEFAULT NULL,`password` varchar(255) DEFAULT NULL,`name` varchar(255) DEFAULT NULL,`age` int(11) DEFAULT NULL,`email` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;-- ------------------------------ Records of tb_user-- ----------------------------BEGIN;INSERT INTO `tb_user` VALUES (1, '赵一伤', '123456', 'zys', 19, 'zys@itcast.cn');INSERT INTO `tb_user` VALUES (2, '钱二败', '123456', 'qes', 18, 'qes@itcast.cn');INSERT INTO `tb_user` VALUES (3, '孙三毁', '123456', 'ssh', 20, 'ssh@itcast.cn');INSERT INTO `tb_user` VALUES (4, '李四摧', '123456', 'lsc', 20, 'lsc@itcast.cn');INSERT INTO `tb_user` VALUES (5, '周五输', '123456', 'zws', 20, 'zws@itcast.cn');INSERT INTO `tb_user` VALUES (6, '吴六破', '123456', 'wlp', 21, 'wlp@itcast.cn');INSERT INTO `tb_user` VALUES (7, '郑七灭', '123456', 'zqm', 22, 'zqm@itcast.cn');INSERT INTO `tb_user` VALUES (8, '王八衰', '123456', 'wbs', 22, 'wbs@itcast.cn');INSERT INTO `tb_user` VALUES (9, '张无忌', '123456', 'zwj', 25, 'zwj@itcast.cn');INSERT INTO `tb_user` VALUES (10, '赵敏', '123456', 'zm', 26, 'zm@itcast.cn');INSERT INTO `tb_user` VALUES (11, '赵二伤', '123456', 'zes', 25, 'zes@itcast.cn');INSERT INTO `tb_user` VALUES (12, '赵三伤', '123456', 'zss1', 28, 'zss1@itcast.cn');INSERT INTO `tb_user` VALUES (13, '赵四伤', '123456', 'zss2', 29, 'zss2@itcast.cn');INSERT INTO `tb_user` VALUES (14, '赵五伤', '123456', 'zws', 39, 'zws@itcast.cn');INSERT INTO `tb_user` VALUES (15, '赵六伤', '123456', 'zls', 29, 'zls@itcast.cn');INSERT INTO `tb_user` VALUES (16, '赵七伤', '123456', 'zqs', 39, 'zqs@itcast.cn');COMMIT;SET FOREIGN_KEY_CHECKS = 1;

2)创建SpringBoot工程,引入MyBatisPlus的启动器依赖,即依赖环境,就目前的练习而言,依赖如下,后续再补充:
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.10.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><properties><java.version>1.8</java.version></properties><dependencies><!-- mysql 驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.49</version></dependency><!-- lombok ,自动生成get,Set 方法--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!--mybatisplus起步依赖--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.1</version></dependency></dependencies>
3)在yml或者yaml中编写DataSource相关配置
# datasourcespring:datasource:url: jdbc:mysql://192.168.200.128:3306/mp_db?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=falseusername: rootpassword: rootdriver-class-name: com.mysql.jdbc.Driver#mybatis-plus配置控制台打印完整带参数SQL语句mybatis-plus:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
4)编写mapper
pojo的映射封装类对应的的mapper接口继承mybatis-plus提供的BaseMapper
public interface UserMapper extends BaseMapper<User> {}
5)编写配置类
新建config包,创建配置类,使用@Configuration 和@MapperScan
@Configuration@MapperScan(basePackages = {"com.itheima.mapper"})public class MPConfig {}
6)编写启动类
@SpringBootApplication//@MapperScan("com.itheima.mapper")public class MPApplication {public static void main(String[] args) {SpringApplication.run(MPApplication.class, args);}}
7)编写测试类
@SpringBootTestpublic class MPTest {}
8)编写service层

接口的编写:接口继承mybatis-plus提供的IService
public interface UserService extends IService<User> {}
其实现类继承mybatis-plus提供的ServiceImpl
@Service("userService")public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {}
mybatis-plus的主键生成策略
主键生成策略大致分为以下三种,注解: @TableId(type = IdType.AUTO),作用与属性id之上
AUTO(0),INPUT(2),ASSIGN_ID(3),ASSIGN_UUID(4)//其中auto是由数据库提供的主键回填,input是由开发人员写的,不写默认雪花算法,//ASSIGN_ID底层是雪花算法, ASSIGN_UUID是UUID//案例@Data@AllArgsConstructor@NoArgsConstructor@Builder@TableName("tb_user")public class User {@TableId(type = IdType.AUTO)private Long id;private String userName;private String password;private String name;private Integer age;private String email;@TableField(fill = FieldFill.INSERT)private LocalDateTime createTime;@TableField(fill = FieldFill.UPDATE)private LocalDateTime updateTime;}
普通列注解-@TableField
作用:.通过@TableField(“表列名”) 指定映射关系,当数据库的字段名字和pojo的属性不一致时候,可以用该注解,省略情况:
- 名称一样
- 数据库字段使用_分割,实体类属性名使用驼峰名称(自动开启驼峰映射)
忽略某个字段的查询和插入 @TableField(exist = false)
public class User { @TableId(type = IdType.AUTO) private Long id; @TableField("user_name") private String userName; private String password; private String name; private Integer age; private String email; @TableField(fill = FieldFill.INSERT) private LocalDateTime createTime; @TableField(fill = FieldFill.UPDATE) private LocalDateTime updateTime; }分页拦截器
直接配置在config下,需要将对应的数据库改成使用的数据库
@Configuration public class MybatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); PaginationInnerInterceptor paginationInterceptor = new PaginationInnerInterceptor(DbType.MYSQL); // 设置请求的页面大于最大页后操作, true调回到首页,false 继续请求 默认false // paginationInterceptor.setOverflow(false); // 设置最大单页限制数量,-1不受限制 paginationInterceptor.setMaxLimit(-1L); interceptor.addInnerInterceptor(paginationInterceptor); return interceptor; } }查询示例:
@Test public void testPage() { Page<User> page = new Page<>(1, 5); Page<User> userPage = userMapper.selectPage(page, Wrappers.emptyWrapper()); // 获取分页数据信息 List<User> records = userPage.getRecords(); //总条数 long total = userPage.getTotal(); //当前页 long current = userPage.getCurrent(); //总页数 long pages = userPage.getPages(); System.out.println("总页数" + pages); System.out.println("当前页" + current); System.out.println("获取分页数据信息" + records); System.out.println("总条数:" + total); }当已完成项目需要修改数据库字段的情况策查询的编写,不再使用QueryWrapper,改成使用 LambdaQueryWrapper,该种方式可以由mybatis-plus底层找到对应的pojo类中的属性的注解找到对应数据库的字段,不会因为数据库的修改而改变
@Test public void testConditions2Query() { LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>(); lambdaQueryWrapper.like(User::getUserName, "伤"); lambdaQueryWrapper.eq(User::getPassword, "123456"); lambdaQueryWrapper.in(User::getAge, 19, 25, 29); lambdaQueryWrapper.orderByAsc(User::getAge); //限定字段 lambdaQueryWrapper.select(User::getUserName, User::getAge); //查询 List<User> users = userMapper.selectList(lambdaQueryWrapper); System.out.println("users = " + users); }
mybatis-plus封装service
1.定义一个服务扩展接口,该接口继承公共接口IService;
//在公共接口的基础上扩展
public interface UserService extends IService<User> {
}
2.定义一个服务实现类,该类继承ServiceImpl
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {}
应用:测试时候不再注入对应的mapper,仅仅使用userService足以,效果一样
//使用前
@Test
public void testConditionsOrQuery() {
Page<User> page = new Page<>(2, 5);
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
LambdaQueryWrapper<User> lambdaQueryWrapper1 = lambdaQueryWrapper.eq(User::getPassword, "123456")
.or()
.in(User::getAge, 20, 21, 22)
.select(User::getUserName,User::getAge);
Page<User> userPage = userMapper.selectPage(page, lambdaQueryWrapper);
//当前页数据
List<User> records = userPage.getRecords();
//总条数
long total = userPage.getTotal();
//当前页
long current = userPage.getCurrent();
//总页数
long pages = userPage.getPages();
System.out.println("pages = " + pages);
System.out.println("current = " + current);
System.out.println("total = " + total);
System.out.println("records = " + records);
}
//使用后
@Autowired
private UserService userService;
@Test
public void testConditionsOrQuery2() {
Page<User> page = new Page<>(2, 5);
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
LambdaQueryWrapper<User> lambdaQueryWrapper1 = lambdaQueryWrapper.eq(User::getPassword, "123456")
.or()
.in(User::getAge, 20, 21, 22)
.select(User::getUserName,User::getAge);
Page<User> userPage = userService.page(page, lambdaQueryWrapper);
//当前页数据
List<User> records = userPage.getRecords();
//总条数
long total = userPage.getTotal();
//当前页
long current = userPage.getCurrent();
//总页数
long pages = userPage.getPages();
System.out.println("pages = " + pages);
System.out.println("current = " + current);
System.out.println("total = " + total);
System.out.println("records = " + records);
}
Mybatis-Plus自动填充
例如创建时间和更新时间的填充,使用的注解如下,有三类:
public enum FieldFill {
/**
* 默认不处理
*/
DEFAULT,
/**
* 插入时填充字段
*/
INSERT,
/**
* 更新时填充字段
*/
UPDATE,
/**
* 插入和更新时填充字段
*/
INSERT_UPDATE
}
在pojo中的注解形式:
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
@TableField(fill = FieldFill.UPDATE)
private LocalDateTime updateTime;
配置:使用最近的版本
@Slf4j
@Component
public class MyMetaObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("start insert fill ....");
this.strictInsertFill(metaObject, "createTime", () -> LocalDateTime.now(), LocalDateTime.class); // 起始版本 3.3.3(推荐)
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("start update fill ....");
this.strictUpdateFill(metaObject, "updateTime", () -> LocalDateTime.now(), LocalDateTime.class); // 起始版本 3.3.3(推荐)
}
}
代码生成器
素材见代码见素材库

day2:docker
常用的docke命令:
安装:
1)更新yum包
yum update
本人打算全部在/usr/local目录下进行以下操作
2)安装需要的软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
3)设置yum源(阿里仓库)
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
4)查看远程仓库中所有docker版本
yum list docker-ce --showduplicates | sort -r
5)安装docker
yum install docker-ce #安装最新版
yum install docker-ce-20.10.1-3.el7 #安装指定版本(推荐安装此方式)
修改Docker远程仓库
#创建目录地址
mkdir -p /etc/docker
#创建 daemon 文件
vi /etc/docker/daemon.json
#配置镜像加速器
{
"registry-mirrors": ["自己个人的docker 加速地址"]
}
#实际:
{
"registry-mirrors": ["https://b73a2jct.mirror.aliyuncs.com"]
}
获取加速码方式:登录阿里云搜索容器镜像服务
6)重新启动服务
systemctl daemon-reload
systemctl restart docker
执行命令查看结果
docker info
Docker应用需要用到各种端口,逐一去修改防火墙设置。!!!!!!!!!!!!
# 关闭
systemctl stop firewalld
# 禁止开机启动防火墙
systemctl disable firewalld
然后输入命令,可以查看docker版本:
docker -v
docker自动补全命令输入
yum install -y bash-completion
source /usr/share/bash-completion/bash_completion
source /usr/share/bash-completion/completions/docker
镜像命令
#构建镜像
docker build
#推送镜像到服务
docker push
#从服务拉取对象★★★
docker pull
#实例:docker pull nginx:1,14,1
#实例:docker pull nginx ——默认下载最新版本
#保存镜像为压缩包★★★
docker save
#实例:docker save -o nginx.tar nginx:1.14.1
#加载压缩包为镜像★★★
docker load
#查看镜像★★★
docker images
#删除镜像★★★
docker rmi
容器的相关命令
#创建并运行一个容器,处于运行状态★★★
docker run
#实例: docker run --name nginx -p 80:80 -d nginx:1.14.1 ——不独占一屏
#实例: docker run --name nginx -p 80:80 nginx:1.14.1 ——独占一屏
#让一个运行的容器暂停
docker pause
#让一个容器从暂停状态恢复运行
docker unpause
#停止一个运行的容器★★★
docker stop
#让一个停止的容器再次运行★★★
docker start
#删除一个容器★★★
docker rm
#今日容器执行命令★★★
docker exec
#实例:docker exec -it nginx bash ——it:给容器创建终端
#查看容器运行日志★★★
docker logs
#查看所有运行的容器及状态★★★
docker ps
#docker pa -f nginx ——实时查看日志
创建和查看数据卷
docker volume [COMMAND]
- create 创建一个volume
- inspect 显示一个或多个volume的信息
- ls 列出所有的volume
- prune 删除未使用的volume
- rm 删除一个或多个指定的volume
```shell
创建数据卷
docker volume create
查看所有数据卷
docker volume ls
查看数据卷详情信息卷
docker volume inspect html
删除指定数据卷
docker volume rm
删除所有未使用数据卷
docker volume prune
<a name="bC8h3"></a>
### 数据卷挂载
① 创建容器并挂载数据卷到容器内的HTML目录
```shell
docker run --name mn -v html:/usr/share/nginx/html -p 80:80 -d nginx
② 进入html数据卷所在位置,并修改HTML内容
# 查看html数据卷的位置
docker volume inspect html
# 进入该目录
cd /var/lib/docker/volumes/html/_data
# 修改文件
vi index.html
直接挂载
dockers run --name mysql -v /temp/mysql:/etc/mysql/conf.d -v /temp/mysql/data:/var/lib/mysql --privileged -d mysql:5.7
Dockerdile的语法

#指定基础镜像
FROM
#设置环境变量,可在后, 指令使用
ENV
#拷贝本地文件到镜像的指定目录
COPY
#执行Linux的shell命令。一般都是安装过程的命令
RUN
#指定容器运行时的监听端口,给镜像使用者看的
EXPOSE
#镜像中应用的启动命令,容器运行时调用
ENTRYPOINT
docker-compose
#安装
curl -L https://github.com/docker/compose/release/download/1.24.1/docker-compose-`uname -s
day3 SpringCloud
SpringCloud是微服务分布式架构的实现一站式的解决方案
微服务出现的原因:由于国内人口多,业务频繁,网络发展快,出现了高并发的情况,单体架构不满足需求
单体架构
概念:将业务的所有功能集中在一个项目中开发,打成一个包部署。
单体架构的优缺点如下:
优点:
- 架构简单
- 部署成本低
缺点:
- 耦合度高(维护困难、升级困难)
- 技术栈受限
分布式架构
概念:根据业务功能对系统做拆分,每个业务功能模块作为独立项目开发,称为一个服务,可以理解为把一件事的各个环节拆解成各个不能再拆分的小功能,每个小功能由不同的人去做,此为分布式;对于某一些功能,如果一个人无法解决,则加派人手,让多个人做同一种事,此为集群
集群: 减轻单个服务压力 实现高可用 
分布式架构的优缺点:
优点:
- 降低服务耦合
- 有利于服务升级和拓展
- 技术栈不受限
缺点:
- 服务调用关系错综复杂
微服务架构的特征

- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责
- 自治:团队独立、技术独立、数据独立,独立部署和交付
- 面向服务:服务提供统一标准的接口,与语言和技术无关
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
微服务拆分原则
- 不同微服务,不要重复开发相同业务
- 微服务数据独立,不要访问其它微服务的数据库
- 微服务可以将自己的业务暴露为接口,供其它微服务调用

说明:cloud-demo:父工程
oerder-service:订单微服务,负责订单相关业务
user-service:用户微服务,负责用户相关业务
spring clound版本选择
spring cloud是基于springboot选择版本的,目前使用的springboot2.3.12版本对应的版本是springcloud的SR12版本
spring cloud代码结构

其中order-service与user-service是cloud-demo的子项目,其插件,依赖基于父项目版面控制,其中spring cloud的依赖来自于以下依赖
<!-- springCloud,所需的依赖都在这里-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
spring cloud的服务调用关系中,存在以下角色:
服务提供者(生产者):一次业务中,被其他微服务调用的服务。
服务消费者:一次业务中,调用其他微服务的服务。
某一个服务既可以是消费者,也可以是生产者,比如该案例的order-service即能调用user-service的服务,也可以被其他服务调用
消费者调用生产者的实现过程:
消费者:
生产者:
第一步:在配置config包中注册RestTemplate
package cn.itcast.order.config;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
/**
* @author lenovo
* date: 2022/5/29 21:26
* Description:
*/
@MapperScan("cn.itcast.order.mapper")
@Configuration
public class Config {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
第二步:在controller与前端进行逻辑书写的地方,进行调用生产者
调用前:
@RestController
@RequestMapping("order")
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("{orderId}")
public Order queryOrderByUserId(@PathVariable("orderId") Long orderId) {
// 根据id查询订单并返回
return orderService.queryOrderById(orderId);
}
}
调用后
@RestController
@RequestMapping("order")
public class OrderController {
@Autowired
private OrderService orderService;
@Autowired
private RestTemplate restTemplate;
@GetMapping("{orderId}")
public Order queryOrderByUserId(@PathVariable("orderId") Long orderId) {
// 根据id查询订单并返回
Order order = orderService.queryOrderById(orderId);
//远程查询url
String url = "http://127.0.0.1:8085/user/" + order.getUserId();
//发起调用
User user = restTemplate.getForObject(url, User.class);
order.setUser(user);
return order;
}
}


Eureka注册中心

服务方称为注册中心的服务端,客户端称为注册中心的客户端
运行流程:
(1)首先启动注册中心的服务端,然后服务消费者和服务提供者要向注册中心注册各自信息及状态,上图所示.
(2)为保证各个服务的正常状态,要每30秒左右向注册中心发送心跳,以此告诉注册中心自己的状态,若不发送,注册中心默认该服务异常,干掉
(3)order-service调用user-servoice,order-service向注册中心拉取user-service的信息
服务注册
注册服务器:
(1)新建eureka-service模块
(2)引入SpringCloud为eureka提供的starter依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
(3)编写启动类
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}
(4)编写配置文件
server:
port: 10086
spring:
application:
name: eureka-server
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
register-with-eureka: false # 不注册自己
fetch-registry: false #不拉取服务本eureka服务中的服务信息
(5)启动服务,出现该页面即为成功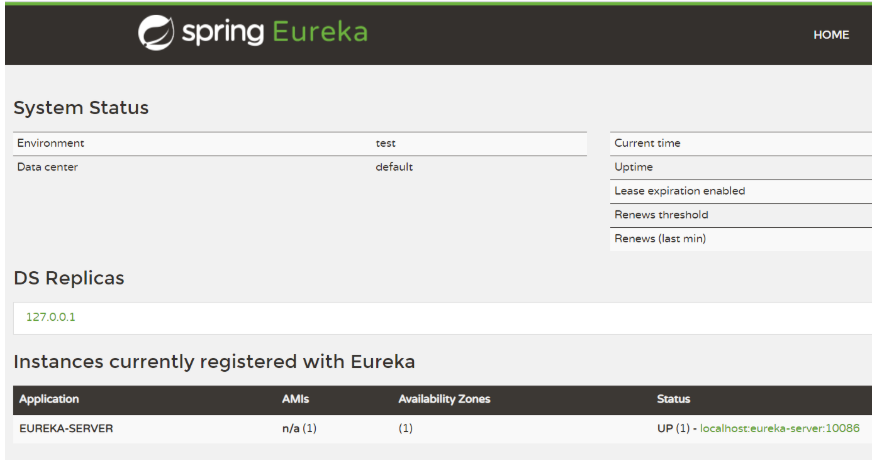
注册客户端
user-service注册到eureka-server中去。
(1)在user-service的pom文件中,引入下面的eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
(2)在原来基础上,修改application.yml文件,添加服务名称、eureka地址
server:
port: 8080
spring:
application:
name: orderservice
datasource:
url: jdbc:mysql://192.168.200.128/cloud_order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
mybatis:
type-aliases-package: cn.itcast.user.pojo
configuration:
map-underscore-to-camel-case: true
logging:
level:
cn.itcast: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
instance: # 在Eureka中显示服务的ip地址
ip-address: 127.0.0.1 # 配置服务器ip地址
prefer-ip-address: true # 更倾向于使用ip,而不是host名
instance-id: ${eureka.instance.ip-address}:${server.port} # 自定义实例的id
(3)在启动类上写@EnableDiscoveryClient
@SpringBootApplication
@EnableEurekaClient
public class UserApplication {
public static void main(String[] args) {
SpringApplication.run(UserApplication.class, args);
}
}
在order-service上注册服务
(1)依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
(2)在原基础上添加配置
server:
port: 8080
spring:
application:
name: orderservice
datasource:
url: jdbc:mysql://192.168.200.128/cloud_order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
mybatis:
type-aliases-package: cn.itcast.user.pojo
configuration:
map-underscore-to-camel-case: true
logging:
level:
cn.itcast: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
instance: # 在Eureka中显示服务的ip地址
ip-address: 127.0.0.1 # 配置服务器ip地址
prefer-ip-address: true # 更倾向于使用ip,而不是host名
instance-id: ${eureka.instance.ip-address}:${server.port} # 自定义实例的id
(3)在配置的RestTemplate上加@@LoadBalanced
@MapperScan("cn.itcast.order.mapper")
@Configuration
public class Config {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
(4)在启动类写注解@EnableDiscoveryClient
@EnableEurekaClient
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
}
负载均衡
常用负载均衡策略:
(1)RoundRobinRule:简单轮询服务列表来选择服务器。
(2)ZoneAvoidanceRule:以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。
(3)RandomRule:随机选择一个可用的服务器,该策略存在一个致命错误,当无法获取服务时,死循环
自定义负载均衡策略:在config配置中加入对应策略的Bean即可
@Bean
public IRule randomRule(){
return new RandomRule();
}
饥饿加载:在消费者中加载
server:
port: 8080
spring:
application:
name: orderservice
datasource:
url: jdbc:mysql://192.168.200.128/cloud_order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
mybatis:
type-aliases-package: cn.itcast.user.pojo
configuration:
map-underscore-to-camel-case: true
logging:
level:
cn.itcast: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
ribbon:
eager-load:
enabled: true
clients: userservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka
instance: # 在Eureka中显示服务的ip地址
ip-address: 127.0.0.1 # 配置服务器ip地址
prefer-ip-address: true # 更倾向于使用ip,而不是host名
instance-id: ${eureka.instance.ip-address}:${server.port} # 自定义实例的id
Nacos注册中心
Nacos的结构与eurwka结构相似,不同点在于nacos2.0的心跳检测采用长连接,nacos1.0的心跳检测的时间间隔不是30秒,而是5秒无法接收临时示例的状态响应,会直接切断该连接。对应临时性实例,一旦失去实例的心跳监测,会直接切断联系,但是对于非临时实例,失去心跳监测,注册中心会主动询问该非临时实例,若无响应,也不处理该非临时实例。
修改实例的临时属性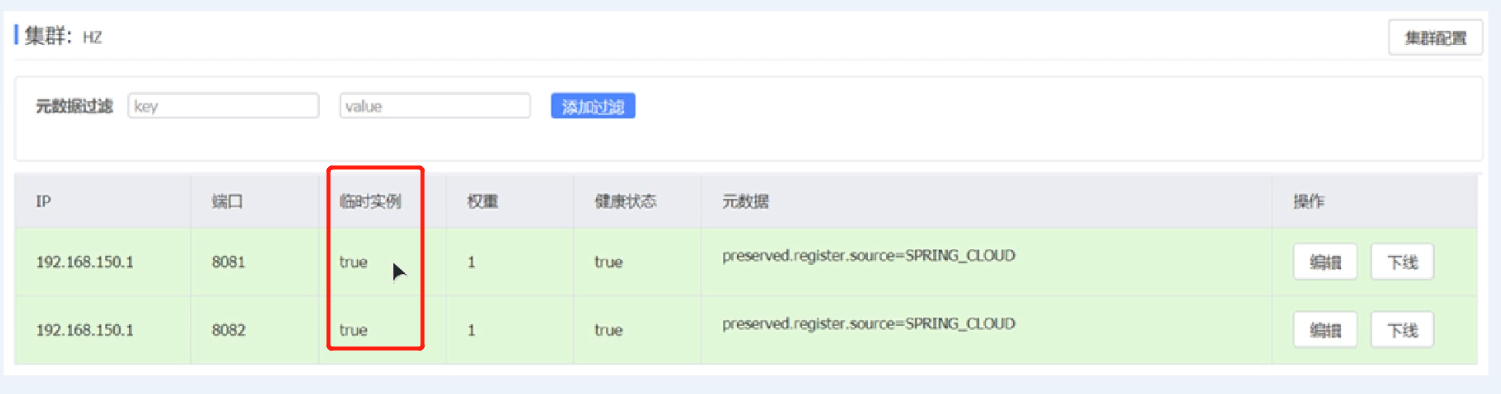
Nacos安装
拉取镜像
docker pull nacos/nacos-server:1.4.1
1)基于Docker安装并启动nacos
docker run --env MODE=standalone --name nacos -d -p 8848:8848 nacos/nacos-server:1.4.1
父项目依赖:注意需要把eureka依赖注掉
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
代码实现
子项目依赖:注意需要把eureka依赖注掉,不需要给服务器euraka-service配置,只给user-service和order-service
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
修改服务配置:均需要删掉euraka配置,配置后重启
order-service修改
server:
port: 8080
spring:
application:
name: orderservice
cloud:
nacos:
server-addr: 192.168.200.128:8848
discovery:
cluster-name: HZ
datasource:
url: jdbc:mysql://192.168.200.128/cloud_order?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
mybatis:
type-aliases-package: cn.itcast.user.pojo
configuration:
map-underscore-to-camel-case: true
logging:
level:
cn.itcast: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
ribbon:
eager-load:
enabled: true
clients: userservice
#eureka:
# client:
# service-url:
# defaultZone: http://127.0.0.1:10086/eureka
# instance: # 在Eureka中显示服务的ip地址
# ip-address: 127.0.0.1 # 配置服务器ip地址
# prefer-ip-address: true # 更倾向于使用ip,而不是host名
# instance-id: ${eureka.instance.ip-address}:${server.port} # 自定义实例的id
user-servoce配置,相同区域的集群设备不需要特有配置
server:
port: 8085
spring:
application:
name: userservice
cloud:
nacos:
server-addr: 192.168.200.128:8848
discovery:
cluster-name: HZ
datasource:
url: jdbc:mysql://192.168.200.128/cloud_user?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
mybatis:
type-aliases-package: cn.itcast.user.pojo
configuration:
map-underscore-to-camel-case: true
logging:
level:
cn.itcast: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
#eureka:
# client:
# service-url:
# defaultZone: http://127.0.0.1:10086/eureka
# instance: # 在Eureka中显示服务的ip地址
# ip-address: 127.0.0.1 # 配置服务器ip地址
# prefer-ip-address: true # 更倾向于使用ip,而不是host名
# instance-id: ${eureka.instance.ip-address}:${server.port} # 自定义实例的id
以上配置得到的Nacos结果
order
user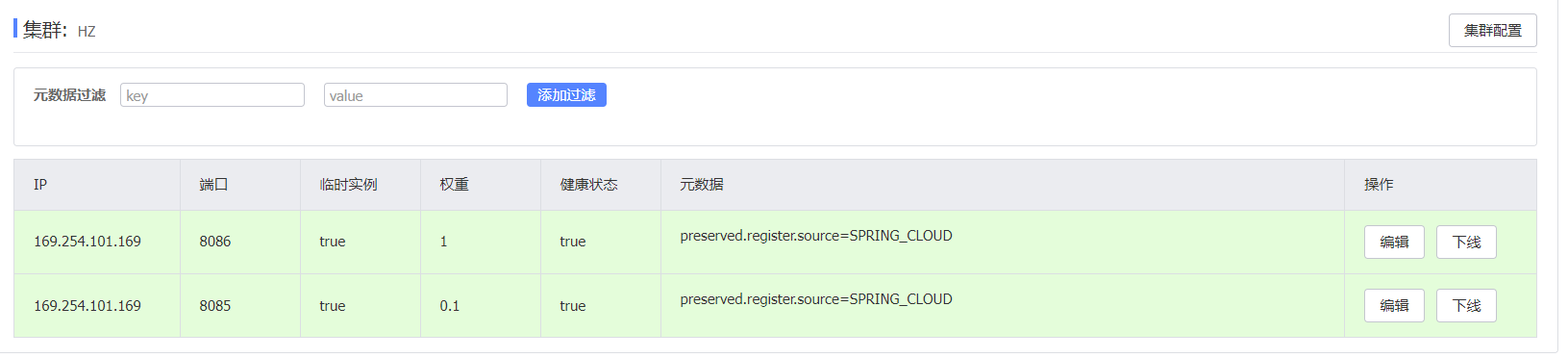
上海用户的集群配置,配置后重启
异地设备配置:
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH
修改负载均衡规则:
修改@Bean下的方式为 NacosRule()
@MapperScan("cn.itcast.order.mapper")
@Configuration
public class Config {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
@Bean
public IRule randomRule(){
return new NacosRule();
}
}
权重配置:一般性能高的设备接收更多的请求
方式:在Nacos可视化平替修改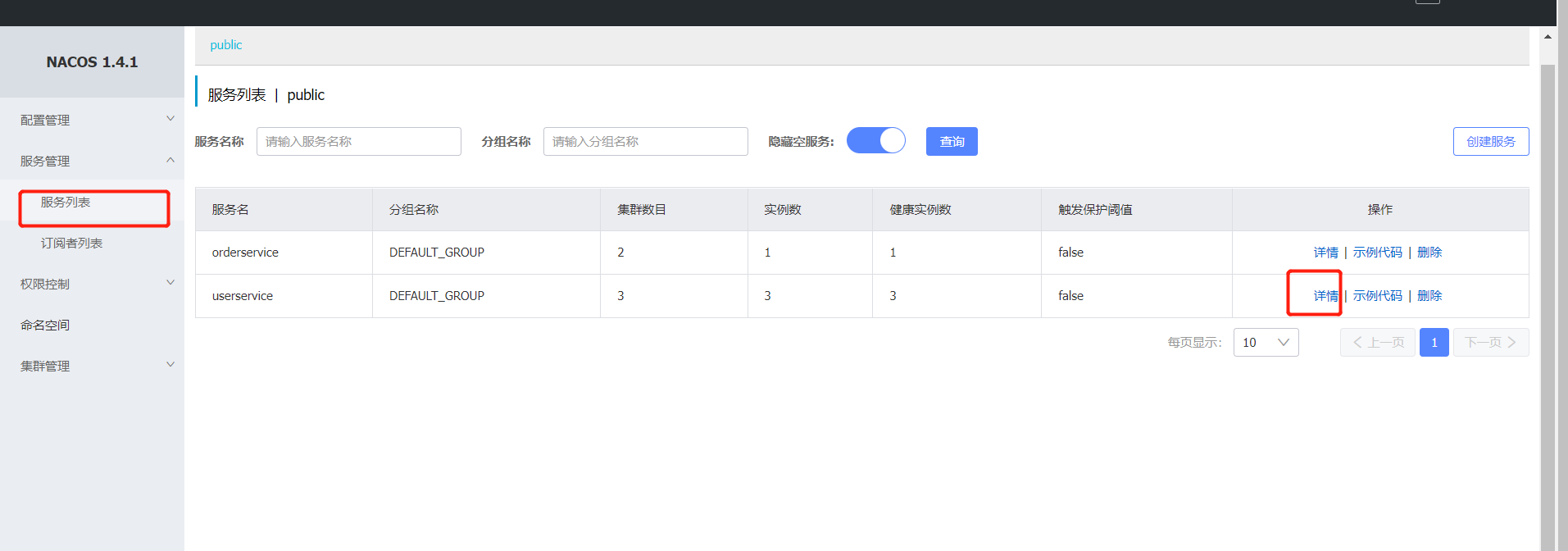

注意:如果权重修改为0,则该实例永远不会被访问
环境隔离:
Nacos提供了namespace来实现环境隔离功能。
- nacos中可以有多个namespace
- namespace下可以有group、service等
- 不同namespace之间相互隔离,例如不同namespace的服务互相不可见
生成命名空间前后差异:
前:
后:
分组,分环境配置:在order-service和user-service进行以下配置
cloud:
nacos:
server-addr: 192.168.200.128:8848
discovery:
cluster-name: HZ
namespace: b695b351-5ef7-4bf9-95cc-4d268b5ac11b
group: 001
效果: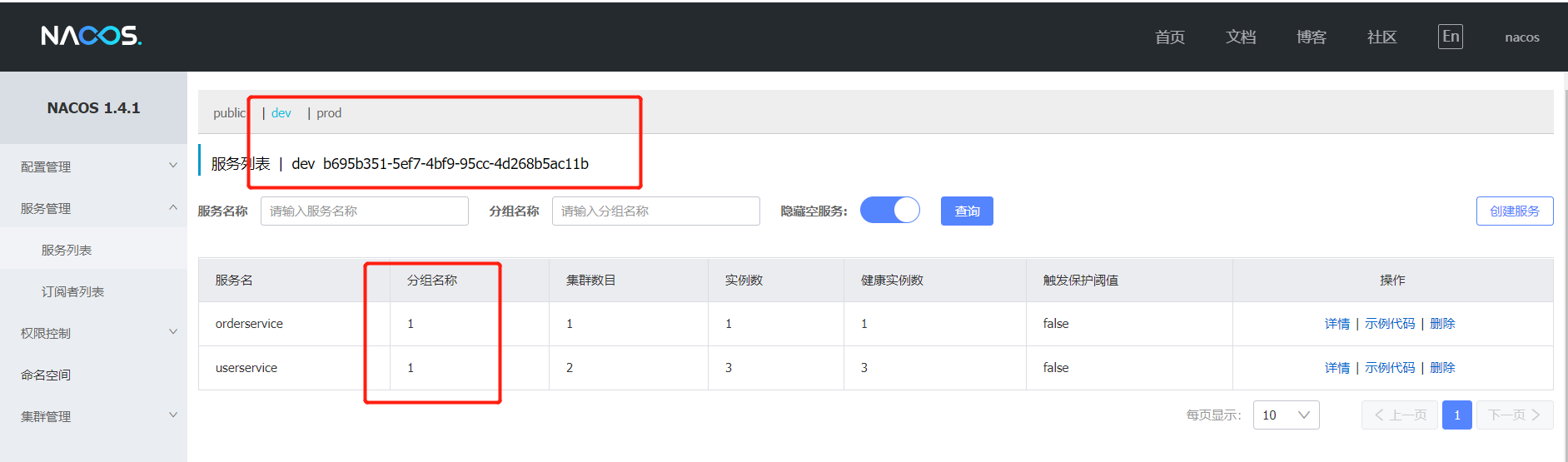
Robbon的面试题:
客户端负载均衡:调用方知道被调服务的地址,Robbon属于客户端负载均衡
服务端负载均衡:调用方不知道服务地址,只知道代理地址,nginx的负载均衡属于服务端的负载均衡。
day4 Spring Cloud+
统一配置管理
配置中心Nacos的好处:
(1)便于统一管理,配置和维护信息性能强
(2)复用性强
方式:
在nacos中添加各个微服务的信息,以dataId为标识,然后再服务中引入nacos-config依赖,同时使用bootstrap.yml代替application.yml,并读取配置
在nacos中添加配置文件

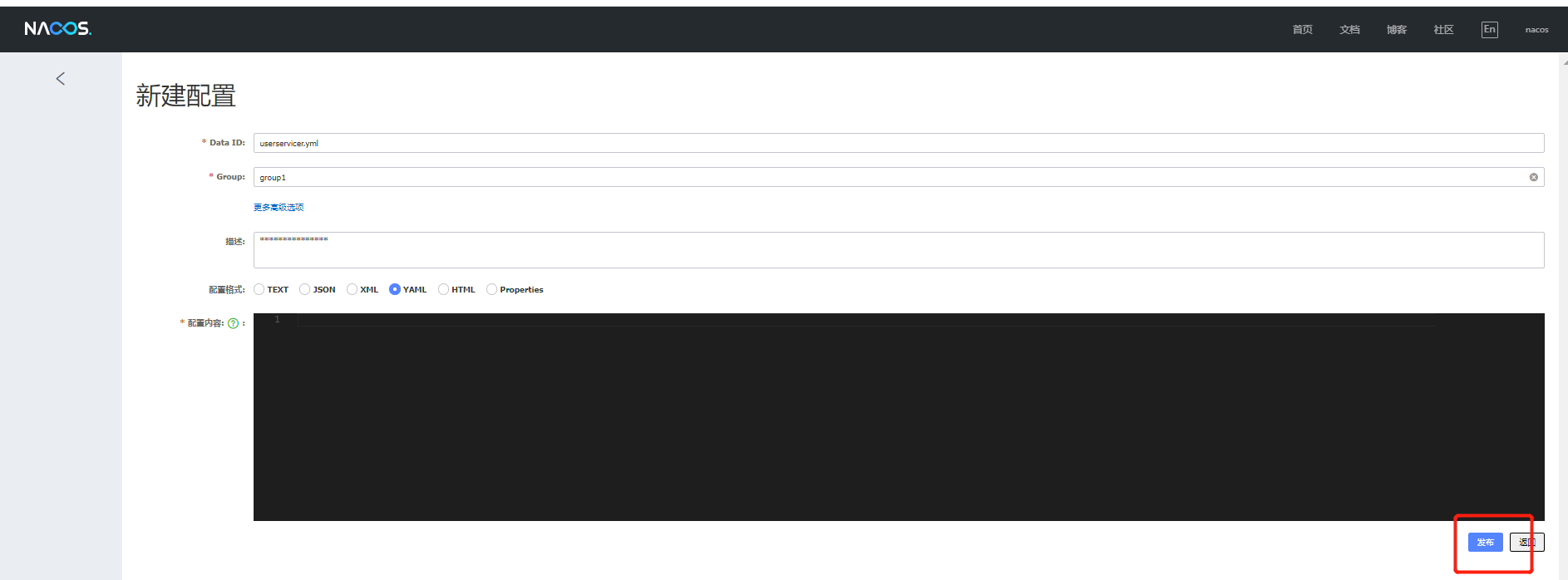
从微服务拉取配置

(1)引入nacos-config依赖
<!--nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
(2)bootstrap.yaml替代application.yaml
server:
port: 8085
spring:
application:
name: userservice
cloud:
nacos:
discovery:
server-addr: 192.168.200.128:8848
cluster-name: HZ
namespace: b695b351-5ef7-4bf9-95cc-4d268b5ac11b
group: xtzx
#以下是新加字段-------------
config:
server-addr: 192.168.200.128:8848 # Nacos地址
cluster-name: HZ
namespace: b695b351-5ef7-4bf9-95cc-4d268b5ac11b
group: xtzx
file-extension: yml
#--------------------------
datasource:
url: jdbc:mysql://192.168.200.128/cloud_user?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
mybatis:
type-aliases-package: cn.itcast.user.pojo
configuration:
map-underscore-to-camel-case: true
logging:
level:
cn.itcast: debug
#以下是新加字段------------------
com:
alibaba:
cloud:
nacos:
client: debug
#---------------------
pattern:
dateformat: MM-dd HH:mm:ss:SSS
(3)读取nacos配置
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Value("${pattern.dateformat}")
private String dateformatStr;
/**
* 路径: /user/110
*
* @param id 用户id
* @return 用户
*/
@GetMapping("/{id}")
public User queryById(@PathVariable("id") Long id) {
return userService.queryById(id);
}
@GetMapping("/date")
public String queryByIdByNacos() {
String s = LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformatStr));
return s;
}
}
配置热更新
最终的目的,是修改nacos中的配置后,微服务中无需重启即可让配置生效
方式一:
在@Value注入的变量所在类上添加注解@RefreshScope:
@Slf4j
@RestController
@RequestMapping("/user")
@RefreshScope
public class UserController {
...
}
方式二:
使用@ConfigurationProperties注解代替@Value注解。在生产方的服务中,添加一个类读取patterrn.dateformat属性:
@Component
@Data
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
}
多环境支持
环境种类:
开发环境:namespace 区分
开发组:group 区分
项目服务: dataid 区分
配置:profile
持久化配置:
由于每一个配置中心都对应一个内置数据库,对应集群环境,这样的配置不便于维护,于是有了唯一的外置数据库的概念,该外置数据库位于docker的容器中,需要如下配置:
1)mysql中新建nacos_config数据库,并执行资料/nacos持久化下的nacos-mysql.sql,材料上传到仓库
进入nacos容器该路径,进入conf中的application.properties进行编辑
docker exec -it nacos /bin/bash
exit退出nacos容器空间,重启nacos容器
docker restart nacos
#查看nacos的日志
docker logs -f nacos
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://192.168.200.128:3306/nacos_config?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=root
db.password=root

出现以下字样表名配置成功
注意:在启动之前,在nacos服务里面进行配置备份,再次使用导入即可
Feign远程调用(调用方配置,以下配置在本案例中均在orderservice中)
官方地址:https://github.com/OpenFeign/feign
Feign替代RestTemplate
1)引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2)启动类上写@EnableFeignClients注解
3)编写feihn客户端,新建包feign,创建接口UserFeignClient
@FeignClient("userservice")
public interface UserFeignClient {
@GetMapping("/user/{id}")
User queryById(@PathVariable("id") Long id);
}
4)测试:在controller中,注掉RestTemplate,注入UserFeignClient
@RestController
@RequestMapping("order")
public class OrderController {
//
// @Autowired
// private RestTemplate restTemplate;
@Autowired
private UserFeignClient userFeignClient;
@GetMapping("{orderId}")
public Order queryOrderByUserId(@PathVariable("orderId") Long orderId) {
// 根据id查询订单并返回
Order order = orderService.queryOrderById(orderId);
//远程查询url
// String url = "http://userservice/user/" + order.getUserId();
//发起调用
// User user = restTemplate.getForObject(url, User.class);
User user = userFeignClient.queryById(order.getUserId());
order.setUser(user);
return order;
}
}
自定义日志配置:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
日志的配置有两种方式:
方式一:局部
feign:
client:
config:
userservice: # 针对某个微服务的配置
loggerLevel: FULL # 日志级别
全局:
feign:
client:
config:
default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置
loggerLevel: FULL # 日志级别
方式二:代码
先在config里面定义一个类DefaultFeignConfiguration,@Bean的内容是主要
@Configuration
@EnableFeignClients(basePackages ="cn.itcast.feign.client")
public class Config {
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.FULL; // 日志级别为BASIC
}
}
}
全局生效:在启动类上写注解
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration.class) // 开启feign客户端的支持
@EnableFeignClients // 开启feign客户端的支持
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
}
局部生效:在服务客户端上写注解
// 指定服务日志配置
@FeignClient(value = "userservice",configuration = DefaultFeignConfiguration.class)
public interface UserFeignClient {
@GetMapping("/user/{id}")
User queryById(@PathVariable("id") Long id);
}
Feign使用优化(调用方)
连接池优化:默认实现的不支持连接池,但是我们要使用连接池,选择Apache HttpClient或者OKHttp任意一个即可
•URLConnection:默认实现,不支持连接池
•Apache HttpClient :支持连接池
•OKHttp:支持连接池
步骤:配置下列即可,无需其他配置
1)引入依赖
<!--httpClient的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>
2)配置连接池
feign:
httpclient:
enabled: true # 开启feign对HttpClient的支持
max-connections: 200 # 最大的连接数
max-connections-per-route: 100 # 每个路径的最大连接数
服务客户端抽取方式:
把openfeign的依赖和配置放到一个独立的模块中,然后以把模块作为依赖给其他服务使用,使用springBoot自带的META-INF/spring.factories方式解决配置扫描问题
新建Maven模块
1)依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
把客户端,配置及user抽取到该模块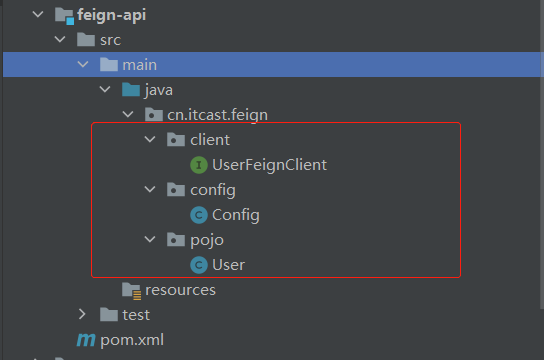
4)将本模块作为依赖放到其他调用服务的服务中
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
解决扫描问题:
1)在 feign-api 的包下添加 FeignConfig 配置类,其中扫描的是 feign-api 的包下的客户端
@Configuration
@EnableFeignClients(basePackages = {"cn.itcast.feign.clients"})
public class FeignConfig {
}
2.在 feign-api 工程下添加 spring.factories 配置文件
org.springframework.boot.autoconfigure.EnableAutoConfiguration=cn.itcast.feign.config.FeignConfig
Gateway服务网关
Gateway是所有微服务的统一入口。核心功能包括:请求路由、权限控制和限流。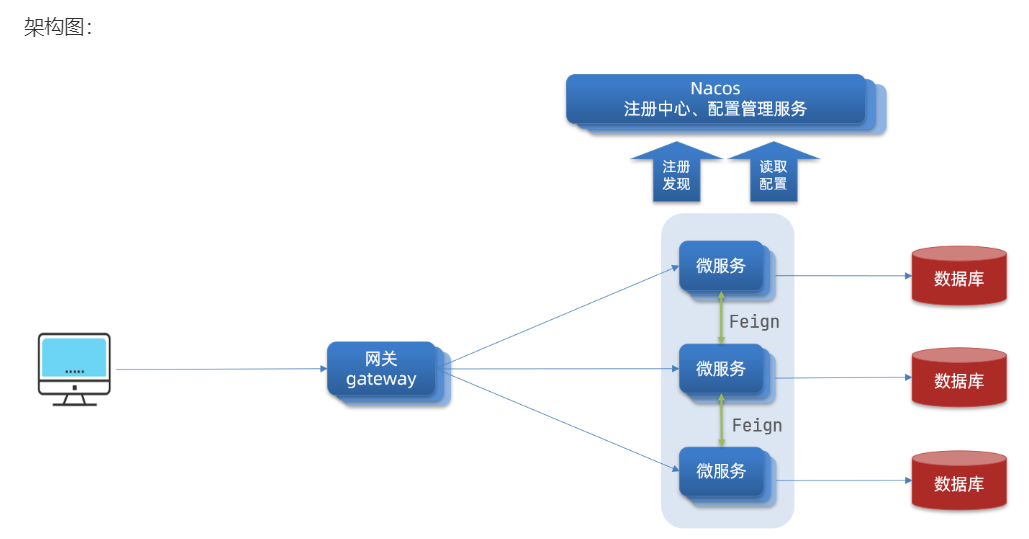
权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。
路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。存在多个目标服务时,由负载均衡进行管理请求转发。
限流:当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。
网关访问流程: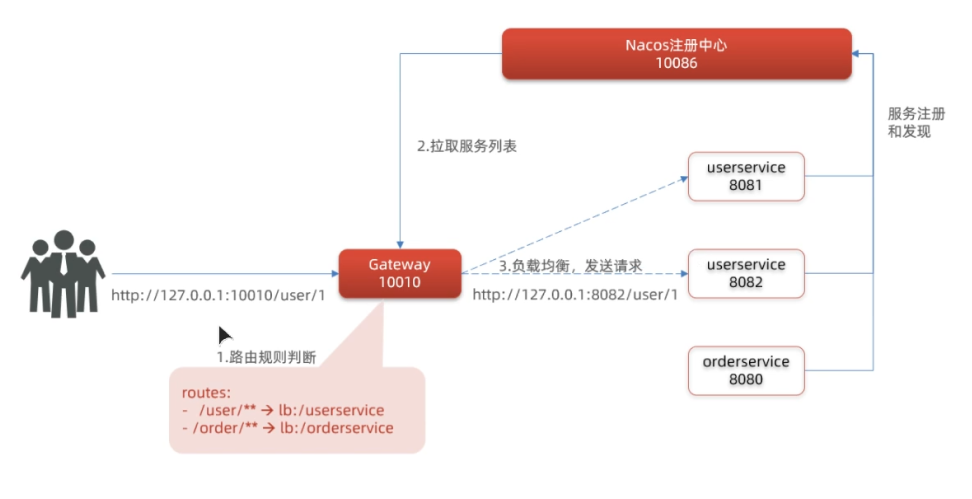
网关会和服务一块注册到注册中心,当请求访问到网关时,IP截断,/user/**部分匹配Path,若为true,则把访问内容转发到注册中心,此刻网关就好从注册中心拉取服务列表,同时网关进行负载均衡,然后向服务发送请求。
gateway快速入门
1)创建gateway服务,引入依赖
2)引入依赖
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
3)编写启动类
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
}
4)编写路由规则,在该服务下创建application.yml
server:
port: 10010 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 网关路由配置
- id: user-service # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://userservice # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求
5)配置好以后,当通过http://localhost:10010/user/1,符合该网关的规则,会通过网关
总结:
网关搭建步骤:
- 创建项目,引入nacos服务发现和gateway依赖
- 配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括:
- 路由id:路由的唯一标示
- 路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断路由的规则,
- 路由过滤器(filters):对请求或响应做处理
过滤器工厂

过滤器优先级如上图所示:默认过滤器>局部过滤器>全局过滤器
常用的过滤器种类
| 名称 | 说明 |
|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 |
| RemoveRequestHeader | 移除请求中的一个请求头 |
| AddResponseHeader | 给响应结果中添加一个响应头 |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 |
| RequestRateLimiter | 限制请求的流量 |
局部过滤器
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
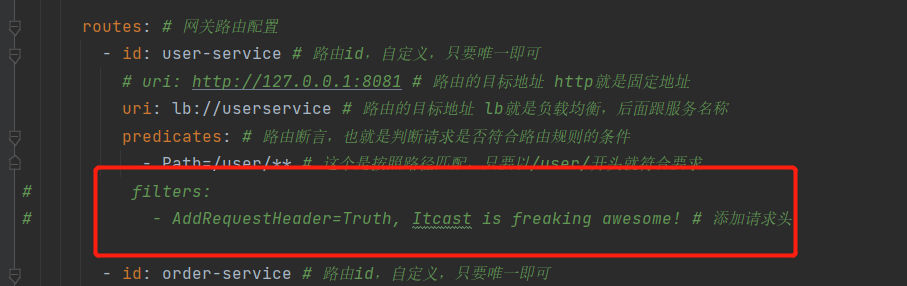
filters: # 过滤器
- AddRequestHeader=Truth, Itcast is freaking awesome! # 添加请求头
测试:在对应的controller中,进行测试,重新运行网关和服务后,访问:http://localhost:10010/order/handle
@GetMapping("/handle")
public String queryById(@RequestHeader("Truth")String truth) {
return truth;
}
默认过滤器
默认过滤器模拟全局过滤器
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默认过滤项
- AddRequestHeader=Truth, Itcast is freaking awesome!
测试:
该方法可以在任意服务器的controller中步骤测试,访问:http://localhost:10010/order/handle和http://localhost:10010/user/handle都可以
@GetMapping("/handle")
public String queryById(@RequestHeader("Truth")String truth) {
return truth;
}
全局过滤器
新建filter类AuthorizeFilter实现GlobalFilter,创建启动类GlobalFilter
其中@Order(-1)括号中数字越小,优先级越高
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.获取authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
return exchange.getResponse().setComplete();
}
}
解释:只有访问中存在authorization参数的才能通过,比如:http://localhost:10010/order?authorization=admin才能通过,否则不通过
跨域问题
协议,域名,端口三者中任意一者不同即为跨域
最重要的是服务器访问其他会产生跨域
解决办法:
在gateway服务的application.yml文件中,添加下面的配置:
spring:
cloud:
gateway:
# 。。。
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: "*" # 允许哪些网站的跨域请求
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期
spring cloud 组件学习总结
1.注册中心
作用:服务注册与发现。服务治理(状态)
组件实现:
Rruka-Spring Cloud
Nacos-Spring Cloud Alibaba
2.负载均衡
作用:微服务实现方(SpringBoot)服务间的调用,被调方以集群的方式体现
需要组件完成负载均衡的算法,来调用服务地址
简洁版:完成微服务于微服务调用时的负载均衡
组件实现:
Ribbon-SPring Cloud
3.配置中心
作用:实现分布式架构中的各个微服务的配置管理
配置信息统一管理:配置维护性高、配置复用性强
实现组件:
Nacos-Spring Cloud Alibaba
4.远程调用
作用:完成服务间(微服务之间)的远程调用像调用本地方法一样来发送远程请求
实现组件:
Feign-Spring Cloud
5.服务网关
作用:为微服务提供门卫的功能
路由的转发、权限控制、访问的限流
目的是保护后端微服务全体,所以的前端必须访问网关才可以获得后端业务服务的数据,前端无法之间访问后端微服务
实现组件:
Gateway-Spring Cloud
day5 RabbitMQ
Ribbon:
服务与服务之间调用 也会用到 ribbon
负载均衡也会用到
网关
调用 微微服务
服务于服务调用
Nginx负责网关的负载均衡
微服务技术栈内服务的调用的负载均衡用Ribbo,前端调用后端用Nginx
同步通讯:
优点:时效性较强,可以立即得到结果
缺点: (1)耦合度高
(2)性能和吞吐能力下降(请求和响应能力低)
(3)有额外的资源消耗(点对点的连接时候,其他请求访问无法得到响应,这些请求也会占据资源)
(4)有级联失败的问题(一方失败,影响另一方)
与异步通讯:
优点: (1)吞吐能力提升:无需等待订阅者处理完成,响应更快速
(2)服务没有直接调用,不存在级联失败的问题(各个请求已经隔离开,不会互相影响)
(3)调用没有阻带,不会造成无效的资源占用
(4)耦合度极低,每个服务都可以灵活插拔,可替换
(5)流量削峰:不管发布事件的流量波动多大,都由Broker接收,订阅者可以按照自己的速度去处理事件,即遇到大并发的请求时,使用中间件,服务每次从中间件中获取固定数量的请求进行处理,而不至于海量请求访问服务器导致服务器宕机。
解决大并发的方案:限流(进服务器之后)、削锋(进服务器之前)
削峰前 |
削峰后 |
|---|---|
缺点 : (1)架构复杂了(中间多了一个消息队列),业务没有明显的流程线,不好管理
(2)需要依赖于Broker的可靠、安全、性能
RabbitMQ技术选型:
MQ,中文是消息队列(MessageQueue),是存放消息的队列,事件驱动架构中的Broker.常见的技术类型:|
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit(最高) | Apache | 阿里(活跃度低) | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般(万级) | 差 | 高(十万级) | 非常高(百万级) |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般(会出现消息丢失情况) |
常见的需求:
追求可用性:、RabbitMQ、Kafka、 RocketMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:Kafka、RocketMQ
追求消息低延迟:RabbitMQ、Kafka
以上四种需求,RabbitMQ满足三项,所以选择RabbitMQ
注意:Erlang专门解决大并发的开发语言
Scala伪java语言
RabbitMQ结构图:
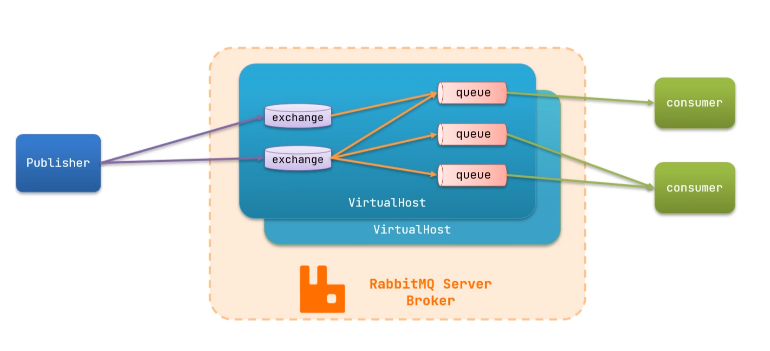
RabbitMQ中的一些角色:
- publisher:生产者
- consumer:消费者,对于消息,阅读以后销毁
- exchange:交换机,接收生产者的消息,负责消息路由
- queue:队列,存储消息
- virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
中间虚线框内为MQ的服务端,也成为Broker——终端
流程:publisher先把消息发送给终端,然后由终端把消息发送给消费者
完整图:
channel:通道
RabbitMQ的结构与其他几种技术不一样,但是每一种技术都有共同点,即队列
安装RabbitMQ
在线拉取:官方版本跟新过快,此版本稳定,故用
docker pull rabbitmq:3.8-management
创建MQ容
docker run \
-e RABBITMQ_DEFAULT_USER=itcast \ #账号
-e RABBITMQ_DEFAULT_PASS=1234 \ #密码
-v mq-plugins:/plugins \ #数据卷挂载
--name mq \ #当前容器名称
--hostname mq \ #系统的hostname
-p 15672:15672 \ #可视化操作界面登录端口
-p 5672:5672 \ #消费者登录端口
-d \
rabbitmq:3.8-management
docker run \
-e RABBITMQ_DEFAULT_USER=itcast \
-e RABBITMQ_DEFAULT_PASS=1234 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
-d \
rabbitmq:3.8-management
登录网站:http://192.168.200.128:15672/
系统界面:
RabbitMQ快速入门

入门以简单队列模型为例进行快速入门,上图虽然没有注明交换机所在,实际上是存在一个默认交换机
官方书写方式入门:
生产者:仅需一个启动类和测试类里面书写逻辑
public class PublisherTest {
@Test
public void testSendMessage() throws IOException, TimeoutException {
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.200.128");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("itcast");
factory.setPassword("1234");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.发送消息
String message = "hello, rabbitmq!";
channel.basicPublish("", queueName, null, message.getBytes());
System.out.println("发送消息成功:【" + message + "】");
// 5.关闭通道和连接
channel.close();
connection.close();
}
}
消费者:仅需要启动类和单元测试
public class ConsumerTest {
public static void main(String[] args) throws IOException, TimeoutException {
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.200.128");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("itcast");
factory.setPassword("1234");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.订阅消息
channel.basicConsume(queueName, true, new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
// 5.处理消息
String message = new String(body);
System.out.println("接收到消息:【" + message + "】");
}
});
System.out.println("等待接收消息。。。。");
}
}
当生产者启动以后,会在终端生成以下数据
当测试启动以后,信息发送到消费者,阅后即焚,生产者结束进程

基本消息队列的消息发送流程:
- 建立connection
- 创建channel
- 利用channel声明队列
- 利用channel向队列发送消息
基本消息队列的消息接收流程:
- 建立connection
- 创建channel
- 利用channel声明队列
- 定义consumer的消费行为handleDelivery()
- 利用channel将消费者与队列绑定
SpringAMQP优化后:
SpringAMQP是基于RabbitMQ封装的一套模板,同时利用了SpringBoot的自动装配,即spring.factories,该概念是一个协议,并没有实现,RabbitMQ实现了,但是太过繁琐,SpringAMQP对其进行了封装,其底层依旧是Spring-rabbit默认实现,其中的spring-amqp是基础抽象
SpringAmqp的官方地址:https://spring.io/projects/spring-amqp
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息
依赖:
<!--AMQP依赖,包含RabbitMQ-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
配置:
spring:
rabbitmq:
host: 192.168.200.128 # 主机名
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: itcast # 用户名
password: 1234 # 密码
在publisher服务中编写测试类SpringAmqpTest,并利用RabbitTemplate实现消息发送:
@SpringBootTest
public class SpringTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSimpleQueue() {
/*
* 参数1:队列名称
* 参数2:消息
* */
rabbitTemplate.convertAndSend("simple.queue", "hello girl");
}
}
在consumer服务的cn.itcast.mq.listener包中新建一个类SpringRabbitListener
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void testSimpleQueue1(String mag) {
System.out.println("amqp消费者1接收消息:_______"+mag);
}
}
RabbitMQ消息中间件的消息模型
分类:
(1)简单队列模式(BasicQueue)
(2)工作队列模式(WorkQueue)
(3)发布/订阅
广播模式(Fanout Exchange)
路由模式(Direct Exchane)
主题模式(Topic Exchange)
简单队列模式的模型图:
工作队列模式的模型图:
发布订阅的模型图:
WorkQueue
也被称为(Task queues),任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息,该模式,队列在同一时刻向任意一个消费者发送消息
使用场景:
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
代码修改:仅仅需要再添加一个消费者
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void testSimpleQueue1(String mag) {
System.out.println("amqp消费者接收消息:"+mag);
}
@RabbitListener(queues = "simple.queue")
public void testSimpleQueue2(String mag) {
System.err.println("amqp消费者接收消息:"+mag);
}
}
能者多劳
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
#整体如下
spring:
rabbitmq:
host: 192.168.200.128 # 主机名
port: 5672 # 端口
virtual-host: / # 虚拟主机
username: itcast # 用户名
password: 1234 # 密码
listener:
simple:
prefetch: 1 # 每次只能获取一条消息,处理完成才能获取
发布订阅
Fanout:广播
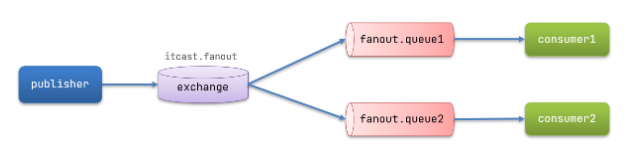
流程:
- 1) 可以有多个队列
- 2) 每个队列都要绑定到Exchange(交换机)
- 3) 生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定
- 4) 交换机把消息发送给绑定过的所有队列
- 5) 订阅队列的消费者都能拿到消息
注意:消费者一定要先开启,否则可能出现以下问题
解决办法,启动消费者以后解决的
代码:
配置:
@Configuration
public class FanoutConfig {
//第一个队列
@Bean
public Queue fanoutQueue1() {
return new Queue("fanout.queue1");
}
//第一个队列
@Bean
public Queue fanoutQueue2() {
return new Queue("fanout.queue2");
}
//交换机
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("itcast.fanout");
}
//绑定交换机与队列1
@Bean
public Binding fanoutBinding1(Queue fanoutQueue1,FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
//绑定交换机与队列2
@Bean
public Binding fanoutBinding2(Queue fanoutQueue2,FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
生产者:
@Test
public void testFanoutExchange() {
// 队列名称
String exchangeName ="itcast.fanout";
// 消息
String message = "hello, everyone!";
rabbitTemplate.convertAndSend(exchangeName, "", message);
}
消费者:
@RabbitListener(queues = "fanout.queue1")
public void testSimpleQueue1(String mag) throws InterruptedException {
System.out.println("amqp消费者1接收消息:_______" + mag);
//每秒处理50条数据
Thread.sleep(20);
}
@RabbitListener(queues = "fanout.queue2")
public void testSimpleQueue2(String mag) throws InterruptedException {
System.err.println("amqp消费者2接收消息:_____________________" + mag);
//每秒处理10条数据
Thread.sleep(100);
}
Direct:路由key模式
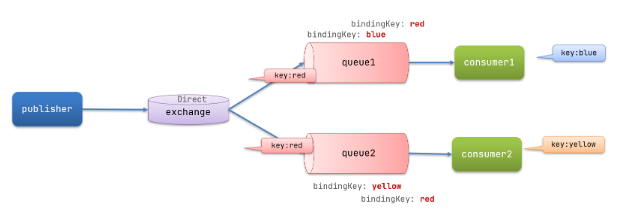
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key)
- 消息的发送方在 向 Exchange发送消息时,也必须指定消息的 RoutingKey。
- Exchange不再把消息交给每一个绑定的队列,而是根据消息的Routing Key进行判断,只有队列的Routingkey与消息的 Routing key完全一致,才会接收到消息
生产者代码:
@Test
public void testDirectExchange() {
// 队列名称
String exchangeName ="itcast.direct";
// 消息
String message = "hello, everyone!";
rabbitTemplate.convertAndSend(exchangeName, "blue", message);
}
注解形式消费者代码:
@RabbitListener(bindings = {@QueueBinding(
value = @Queue("direct.queue1"),
exchange = @Exchange(value = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red","blue"}
)
}
)
public void testDirectQueue1(String mag) {
System.out.println("amqp消费者1接收消息:_______" + mag);
}
@RabbitListener(bindings = {@QueueBinding(
value = @Queue("direct.queue2"),
exchange = @Exchange(value = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red","yellow"}
)
}
)
public void testDirectQueue2(String mag) {
System.err.println("amqp消费者2接收消息:_____________________" + mag);
}
配置方式的消费者代码:
weixie暂时
Topic模式:
:匹配一个或多个词
*:匹配不多不少恰好1个词
消费者代码:
@RabbitListener(bindings = {@QueueBinding(
value = @Queue("topic.queue1"),
exchange = @Exchange(value = "itcast.direct", type = ExchangeTypes.DIRECT),
key = "red.#"
)
}
)
public void testDirectQueue1(String mag) {
System.out.println("amqp消费者1接收消息:_______" + mag);
}
@RabbitListener(bindings = {@QueueBinding(
value = @Queue("topic.queue2"),
exchange = @Exchange(value = "itcast.topic", type = ExchangeTypes.TOPIC),
key = "#.red"
)
}
)
public void testDirectQueue2(String mag) {
System.err.println("amqp消费者2接收消息:_____________________" + mag);
}
生产者:
@Test
public void testTopicExchange() {
// 队列名称
String exchangeName ="itcast.topic";
// 消息
String message = "hello, everyone!";
rabbitTemplate.convertAndSend(exchangeName, "red", message);
}
消息转换器
一定一定一定一定要首先把依赖导入,否则必读宝报错!!!!!!!!!!!!!
如果报下列错,就运行官方文件!!!!!!!!!!!!!!!!!!!
依赖
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
在生产者启动类放入下@Bean
import org.springframework.amqp.support.converter.Jackson2JsonMessageConverter;
import org.springframework.amqp.support.converter.MessageConverter;
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
代码:消费者
@RabbitListener(queues = "simple.queue")
public void testSimpleQueue1(String mag) {
System.out.println("amqp消费者1接收消息:_______"+mag);
}
生产者
@Test
public void testSendMap() throws InterruptedException {
// 准备消息
Map<String,Object> msg = new HashMap<>();
msg.put("name", "Jack");
msg.put("age", 21);
// 发送消息
rabbitTemplate.convertAndSend("simple.queue",msg);
}
day6 elasticsearch
ELK技术栈
(1)elasticsearch是一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
(2)elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK),elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。
(3)elasticsearch底层是基于lucene来实现的,Lucene是一个Java语言的搜索引擎类库。

倒排索引与正向索引
正向索引:根据id索引的方式,但是根据词条查询时,需要逐行获取每一个文档,然后判断文档中是否包含所需词条,即在一条完整数据中找一个关键字
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描,逐行扫描
倒排索引:通过关键字找一条数据
优点:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
mysql与elasticseach的特点:
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算
因此,对安全性要求较高的写操作,使用mysql实现,对查询性能要求较高的搜索需求,使用elasticsearch实现,两者基于某种方式,实现数据的同步,保证一致性
分词器
ElasticSearch 内置分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认\W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
以上分词器均不适用于中国,由下图可知,一段话被完全拆解,故不适用
索引库操作
创建索引库
创建索引库的请求格式:
- 请求方式:PUT
- 请求路径:/索引库名
- 请求参数:格式:
创建索引库语法:
put /创建的索引库名称
put /heima
查询索引库
GET /创建的索引库名称
GET /heima
查询所有索引库:
GET _cat/indices
#删除索引库
DELETE /索引库库名
DELETE /heima
映射的属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)(不可分词)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
索引库存在时
语法:
PUT /索引库名/_mapping
{
"properties": {
"字段名1": {
"type": "类型",
"index": true,
"analyzer": "分词器"
},
"字段名2": {
"type": "类型",
"index": true,
"analyzer": "分词器"
},
...
}
}
案例
PUT /heima3/_mapping
{
"properties": {
"id":{
"type": "long"
},
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"images":{
"type": "keyword",
"index": false
},
"price":{
"type": "float"
}
}
}
索引库不存在时
语法:
PUT /索引库名
{
"mappings":{
"properties": {
"字段名1": {
"type": "类型",
"index": true,
"analyzer": "分词器"
},
"字段名2": {
"type": "类型",
"index": true,
"analyzer": "分词器"
},
...
}
}
}
创建案例:
PUT /heima2
{
"mappings": {
"properties": {
"id":{
"type": "long"
},
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"images":{
"type": "keyword",
"index": false
},
"price":{
"type": "float"
}
}
}
}
查看映射关系
语法
GET /索引库名/_mapping
查询案例:
GET /heima2/_mapping
查询结果
{
"heima2" : {
"mappings" : {
"properties" : {
"id" : {
"type" : "long"
},
"images" : {
"type" : "keyword",
"index" : false
},
"price" : {
"type" : "float"
},
"title" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
}
对于映射就行修改和删除,ES官方特别声明:
修改:
1.无法修改映射中已有字段进行修改
2.可以向已有的映射中添加映射
删除:
无法直接将索引库下的映射直接删除,只能通过删除索引库来达到删除映射的目的
以上说法指的是:对已经构建映射的索引库,不能在对已经修改的字段进行修改,但是可以添加,同时不能对某个字段进行删除,只能通过删除整个索引库进行删除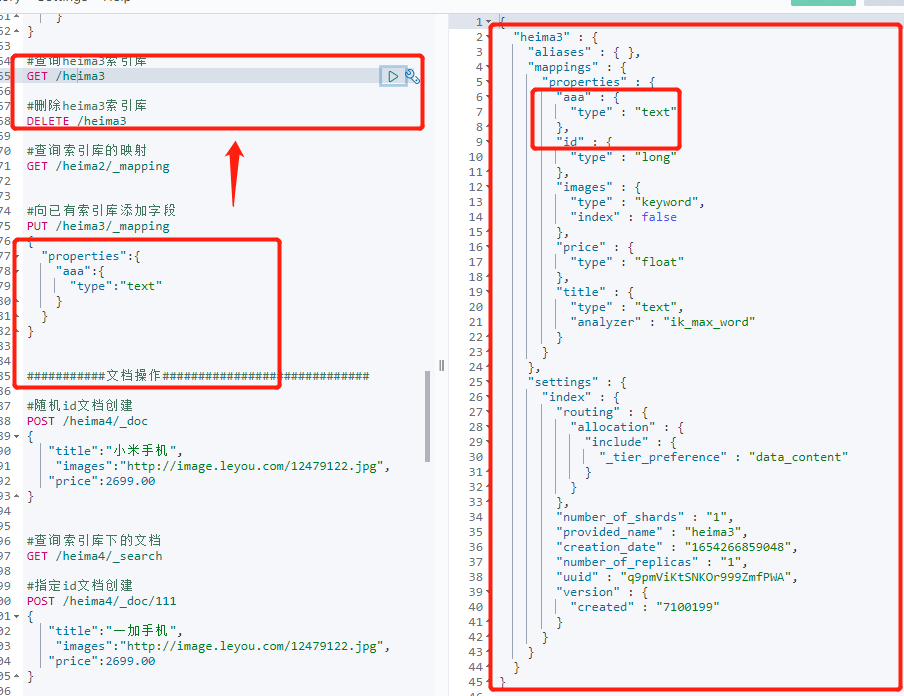
文档操作:
创建随机id的文档
语法
POST /{索引库名}/_doc
{
"key":"value"
}
创建随机id的文档
POST /heima4/_doc
{
"title":"小米手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":2699.00
}
创建随机id文档的结果
{
"_index" : "heima4",
"_type" : "_doc",
"_id" : "-A-aLIEBWHg4lMKTmCBO",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 19,
"_primary_term" : 1
}
#其中id的value值是随机生成的
查询指定索引库库名
GET /{索引库名}/_search
案例
GET /heima4/_search
创建指定id 文档
POST /{索引库名}/_doc/{id}
{
"key":"value"
}
案例
POST /heima4/_doc/111
{
"title":"一加手机",
"images":"http://image.leyou.com/12479122.jpg",
"price":2699.00
}
查询指定id文档的结果
{
"_index" : "heima4",
"_type" : "_doc",
"_id" : "111",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 20,
"_primary_term" : 1
}
查询指定id文档
GET /heima4/_doc/111
删除文档
只能根据id删除
DELETE /heima4/_doc/111
修改文档
增量修改
增量修改是只修改指定id匹配的文档中的部分字段。
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
全文修改
全量修改是覆盖原来的文档,其本质是:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
当不存在改id的文档时,相对于创建了该文档,但是当该id的文档存在时,相对于删了原来的文档重新创建
RestAPI
Elasticsearch在idea的操作注意事项:
(1)初始化RestClient需要引入依赖 ,因为版本问题,需要在
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.10.1</elasticsearch.version>
</properties>
(2)每一个功能的运行,都需要进行初始化和释放资源,所以使用单元测试的@@BeforeEach与@AfterEach注解,使代码简洁
private RestHighLevelClient client;
@BeforeEach
public void buildClient() {
client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://47.101.41.230:9200")));
}
@AfterEach
public void closeClient() throws IOException {
this.client.close();
}
(3)创建索引库映射
映射需要根据对应的索引库来进行编写,本索引库对应的mysql表为hotel,其中MySQL建表语句如下:
CREATE TABLE `tb_hotel` (
`id` bigint(20) NOT NULL COMMENT '酒店id',
`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',
`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',
`price` int(10) NOT NULL COMMENT '酒店价格;例:329',
`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',
`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',
`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',
`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',
`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',
`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',
`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',
`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
索引库映射:
PUT /hotel
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword",
"copy_to": "all"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
mapping映射的JSON字符串常量:
public class HotelConstants {
public static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"score\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"starName\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"business\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"location\":{\n" +
" \"type\": \"geo_point\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
查询图解

es查询常用步骤:
查询DSL语句
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
响应数据结构
//1、构建请求对象
SearchRequest request = new SearchRequest("hotel");
//2、构建查询源数据对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//3、构建查询方式
MatchAllQueryBuilder query = QueryBuilders.matchAllQuery();
//3、组装请求
sourceBuilder.query(query);
request.source(sourceBuilder);
//发送请求,获取响应数据
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析查询结果
//获取hits
SearchHits hits = response.getHits();
long total = hits.getTotalHits().value;
System.out.println("查询后的结果总条数:" + total);
//获取hit
for (SearchHit hit : hits) {
String id = hit.getId();
System.out.println("文档id:" + id);
//获取source
String jsonStr = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(jsonStr, HotelDoc.class);
System.out.println(hotelDoc);
System.out.println("====华丽分割线======");
}
删除索引库
索引库DSL语句
DELETE /hotel
代码
@Test
void testDeleteHotelIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
RestClient操作文档
新增文档
新增hotel映射
@Data
@TableName("tb_hotel")
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class Hotel {
@TableId(type = IdType.INPUT)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String longitude;
private String latitude;
private String pic;
}
新增文档映射
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
新增文档的DSL
POST /hotel/_doc/44771
{
"title":"一加手机"
}
代码实现:
@Test
public void testIndexDocRequest() throws IOException {
Hotel hotel = hotelService.getById(44771L);
HotelDoc hotelDoc = new HotelDoc(hotel);
String s = JSON.toJSONString(hotelDoc);
//创建请求对象--文档添加的请求对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
request.source(s, XContentType.JSON);
//通过客户端向es添加文档数据
client.index(request, RequestOptions.DEFAULT);
}
查询文档
DSL语句
GET /hotel/_doc/{id}
数据响应结构:
代码实现
//查询文档信息
@Test
public void testQueryIndexRequest() throws IOException {
//获取request
GetRequest request = new GetRequest("hotel", "44771");
//获取响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//解析响应结果
String source = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(source, HotelDoc.class);
System.out.println(hotelDoc);
}
删除文档
DSL语句
DELETE /hotel/_doc/{id}
代码实现
//删除文档
@Test
public void testDeleteIndexDocRequest() throws IOException {
DeleteRequest request = new DeleteRequest("heima4", "111");
DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);
System.out.println("delete = " + delete);
}
修改文档
DSL语句
POST /heima/_update/9g8ZKoEBWHg4lMKTgyAA
{
"doc": {
"title":"二加手机"
}
}
代码
@Test
public void testUpdateDocRequest() throws IOException {
UpdateRequest request = new UpdateRequest("heima", "9g8ZKoEBWHg4lMKTgyAA");
request.doc(
"title", "二加手机"
);
client.update(request, RequestOptions.DEFAULT);
}
批量添加文档
代码实现
//批量添加文档
@Test
public void testBulkRequest() throws IOException {
// 批量查询酒店数据
List<Hotel> hotels = hotelService.list();
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Hotel hotel : hotels) {
// 2.1.转换为文档类型HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSON.toJSONString(hotelDoc), XContentType.JSON));
}
//发送请求
client.bulk(request, RequestOptions.DEFAULT);
}
day7
day8


day 9
Sentinel:
作用:
雪崩:分布式架构中微服务之间相互调用,因为调用链中的一个服务故障,引起整个链路都无法访问的情况,称为服务雪崩(级联故障/失效)
解决雪崩的方案:
解决方案:
(1)超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待。缺点:该方案界定超时时间是一个很难的问题,无法精准制定超时时间
(2)仓壁模式:限定每个业务能使用的线程数,避免耗尽整个tomcat的资源,因此也叫线程隔离。缺点:需要创建大量线程,消耗系统资源,设备要求高
(3)断路器模式:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
情景:(1)慢调用:慢调用占用所有请求比重大于某一界定值时候,触发熔断机制
(2)异常比例:异常请求占用所有比例比重大于某一界定值时,触发熔断机制,后续所有请求不能够再成功访问
(3)触发熔断后,断路器会使用默认兜底方案响应请求,,默认返回一个结果
预防:
(4)限流:是对服务的保护,避免因瞬间高并发流量而导致服务故障,进而避免雪崩,属于预防措施
流量控制:限制业务访问的QPS,避免服务因流量的突增而故障
每秒查询率(QPS)=请求量/时间
平均响应时间(Rt):从客户端发起请求倒服务端接受倒请求并响应所有数据的时间差
Sentinel
与Hystrix区别:
| Sentinel | Hystrix | |
|---|---|---|
| 隔离策略 | 线程池隔离/信号量隔离 | 线程池隔离 |
| 熔断降级策略 | 基于慢调用比例或异常比例 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 有限的支持 |
| 流量整形 | 支持慢启动、匀速排队模式 | 不支持 |
| 系统自适应保护 | 支持 | 不支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
Sentinel的资源:
簇点链路中被监控的每一个接口就是一个资源。
Sentinel的链路:
当请求进入微服务时,首先会访问DispatcherServlet,然后进入Controller、Service、Mapper,这样的一个调用链就叫做簇点链路。
簇点链路:
流控模式:
(1)直接:统计当前资源的请求,触发阈值时对当前资源直接限流,也是默认的模式
(2)关联:统计与当前资源相关的另一个资源,触发阈值时,对当前资源限流
(3)链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
流控效果:
(1)快速失败
(2)Warm Up
(3)排队等待
Feigh整合Sentinel:
线程隔离方案:
熔断器的三种状态:
Sentinel支持的熔断规则:
授权规则:
设置授权规则:
规则管理模式:
自定义异常实现:
事务
本地数据库的事务
事务可以看做是一次大的活动,它由不同的小活动组成,这些活动要么全部成功,要么全部失败。
分布式事务
分布式系统中,多个服务操作多个数据库,不同服务参与同一个操作时,要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
理论基础
CAP定理
该理论由半部分构成
Consistency(一致性): 对某个指定的客户端来说,读操作能返回最新的数据。如果读操作时,正在进行写操作,此时读操作会等待,当写操作完后,读操作再进行并返回最新的数据。
Availability(可用性): 客户端的请求,服务端并会有响应,此动作不会关系数据有没有同步,所有客户端获得的数据可能不是最新的数据。
Partition tolerance(分区容错性): 在分布式系统中,由于网络等不稳定因素,导致系统服务间的数据没有同步,此时会出现数据上的错误,而这种数据上出错误是可以容忍存在。不稳定因素解决后,服务间的数据最终会同步。
CA:若不需要关注P,那么系统不是分布式系统,加强一致性和可用性,关系数据库按照CA进行设计。
CP : 强一致性,弱可用性(牺牲部分机器的可用性,保证数据一致性)
AP : 强可用性,弱一致性(牺牲一致性,保证可用性)
三个指标不可能同时做到。这个结论就叫做 CAP 定理。
分布式系統无法同时满足CAP三项,分布式系统中 P 永远存在。
BASE理论
BASE理论是对CAP理论的延伸,强调AP,满足BASE理论的事务,我们称之为“柔性事务”。BASE理论通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。
(1)Basically Available(基本可用):分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用
(2)Soft state(软状态):允许系统中存在中间状态,这个状态不影响系统可用性
(3)Eventually consistent (最终一致性):最终一致是指经过一段时间后,所有节点数据都将会达到一致
解决分布式事务的思路
借鉴CAP定理和BASE理论,有两种解决思路:
- AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
- CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。
分布式事务解决方案
2PC两阶段提交

两阶段提交协议(Two Phase Commitment Protocol)中,涉及到两种角色:
一个事务协调者(coordinator):负责协调多个参与者进行事务投票及提交(回滚)
多个事务参与者(participants):即本地事务执行者
两阶段提交:
prepare阶段:事务执行但不提交阶段
commit阶段:事务提交阶段
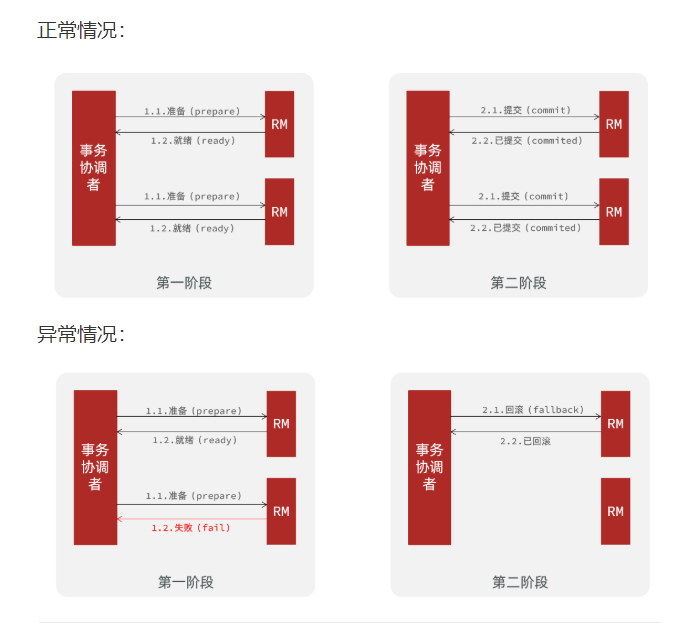
描述:
一阶段:
- 事务协调者通知每个事物参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务
TCC事务补偿
TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。三个阶段如下:
| 操作方法 | 含义 |
|---|---|
| Try | 预留业务资源/数据效验-尝试检查当前操作是否可执行 |
| Confirm | 确认执行业务操作,实际提交数据,不做任何业务检查。try成功,confirm必定成功 |
| Cancel | 执行业务出错时,需要回滚数据的状态下执行的业务逻辑 |
TCC事务流程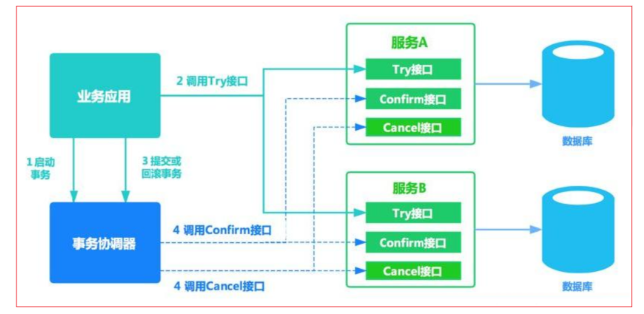

Seata
官网地址:http://seata.io/,其中的文档、播客中提供了大量的使用说明、源码分析。
Seata的架构
Seata事务管理中有三个重要的角色:
- TC (Transaction Coordinator) -事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) -事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) -资源管理器:管理分支事务处理的资源,与TC交谈以注册分支
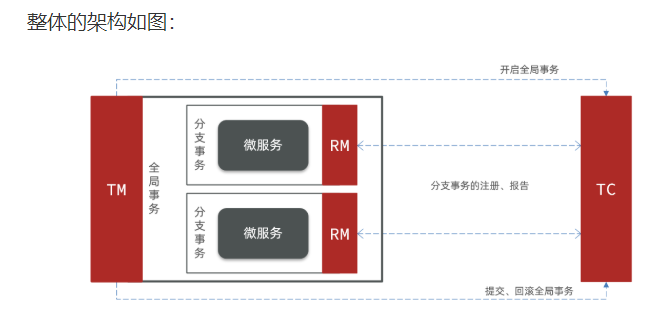
Seata基于上述架构提供了四种不同的分布式事务解决方案:
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- TCC模式:最终一致的分阶段事务模式,有业务侵入
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式
- SAGA模式:长事务模式,有业务侵入
无论哪种方案,都离不开TC,也就是事务的协调者。
部署TC服务
下拉容器和创建容器
#下拉镜像
docker pull seataio/seata-server:1.4.2
#创建容器
docker run \
-e SEATA_IP=192.168.94.129 \
-e SEATA_PORT=8091 \
--name seata-server \
-p 8091:8091 \
-d \
seataio/seata-server:1.4.2
#创建容器后可以进入到容器中
docker exec -it seata-server sh
#退出容器
exit
#查看运行的日志
docker logs -f seata-server
2.创建Seata的数据库和表
在mysql服务中添加数据库,导入day10/资料/seata/seata.sql” 文件到数据库中,导入后的结果:
3.配置seata的tc配置信息
在nacos中namespace下创建配置信息:seataServer.properties,选择
# 数据存储方式,db代表数据库
store.mode=db
store.db.datasource=druid
store.db.dbType=mysql
store.db.driverClassName=com.mysql.jdbc.Driver
store.db.url=jdbc:mysql://192.168.200.128:3306/seata?useUnicode=true&rewriteBatchedStatements=true
store.db.user=root
store.db.password=root
store.db.minConn=5
store.db.maxConn=30
store.db.globalTable=global_table
store.db.branchTable=branch_table
store.db.queryLimit=100
store.db.lockTable=lock_table
store.db.maxWait=5000
# 事务、日志等配置
server.recovery.committingRetryPeriod=1000
server.recovery.asynCommittingRetryPeriod=1000
server.recovery.rollbackingRetryPeriod=1000
server.recovery.timeoutRetryPeriod=1000
server.maxCommitRetryTimeout=-1
server.maxRollbackRetryTimeout=-1
server.rollbackRetryTimeoutUnlockEnable=false
server.undo.logSaveDays=7
server.undo.logDeletePeriod=86400000
# 客户端与服务端传输方式
transport.serialization=seata
transport.compressor=none
# 关闭metrics功能,提高性能
metrics.enabled=false
metrics.registryType=compact
metrics.exporterList=prometheus
metrics.exporterPrometheusPort=9898
配置Centos环境
先把文件放到虚拟机中

registry {
# tc服务的注册中心类,这里选择nacos,也可以是eureka、zookeeper等
type = "nacos"
nacos {
# seata tc 服务注册到 nacos的服务名称,可以自定义 spring.application.name
application = "seata-tc-server"
serverAddr = "192.168.200.128:8848"
group = "DEFAULT_GROUP"
namespace = ""
cluster = "DEFAULT"
username = "nacos"
password = "nacos"
}
}
config {
# 读取tc服务端的配置文件的方式,这里是从nacos配置中心读取,这样如果tc是集群,可以共享配置
type = "nacos"
# 配置nacos地址等信息
nacos {
serverAddr = "192.168.200.128:8848"
group = "DEFAULT_GROUP"
namespace = ""
username = "nacos"
password = "nacos"
dataId = "seataServer.properties"
}
}
微服务集成Seata
在三个服务中均要布置以下配置
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<!--版本较低,1.3.0,因此排除-->
<exclusion>
<artifactId>seata-spring-boot-starter</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<!--seata starter 采用1.4.2版本-->
<version>${seata.version}</version>
</dependency>
seata:
registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址
type: nacos # 注册中心类型 nacos
nacos:
server-addr: 192.168.94.129:8848 # nacos地址
namespace: "" # namespace,默认为空
group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP
application: seata-tc-server # seata服务名称
username: nacos
password: nacos
tx-service-group: seata-demo # 事务组名称
service:
vgroup-mapping: # 事务组与cluster的映射关系
seata-demo: DEFAULT
分布式事务解决方案的实现

XA模式
是seata对2PC两阶段模式的实现。
XA是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
一阶段:
- 事务协调者通知每个事物参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
事务协调者基于一阶段的报告来判断下一步操作
TC检测各分支事务执行状态
- a.如果都成功,通知所有RM提交事务
- b.如果有失败,通知所有RM回滚事务
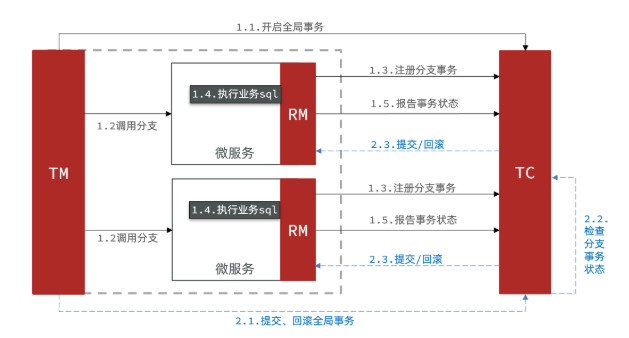
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则。
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差,效率低
- 依赖关系型数据库实现事务
注:ACID,是指数据库管理系统(DBMS)在写入或更新资料的过程中,为保证事务(transaction)是正确可靠的,所必须具备的四个特性:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
实现XA模式
每一个参与事务组的服务都添加以配置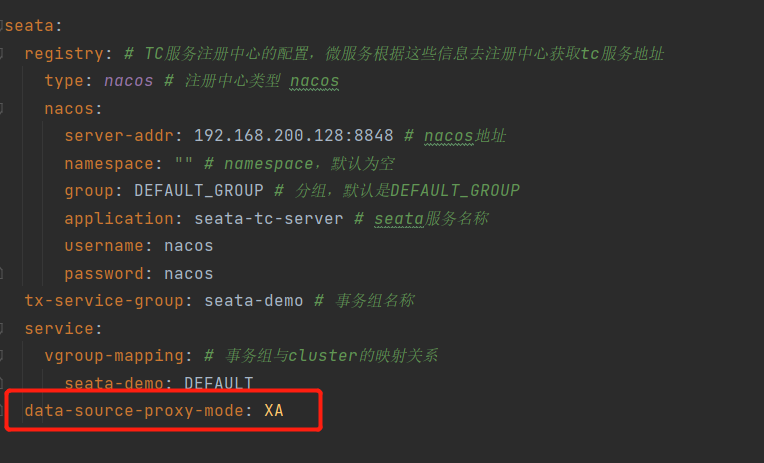
seata:
data-source-proxy-mode: XA
在入口服务处添加注解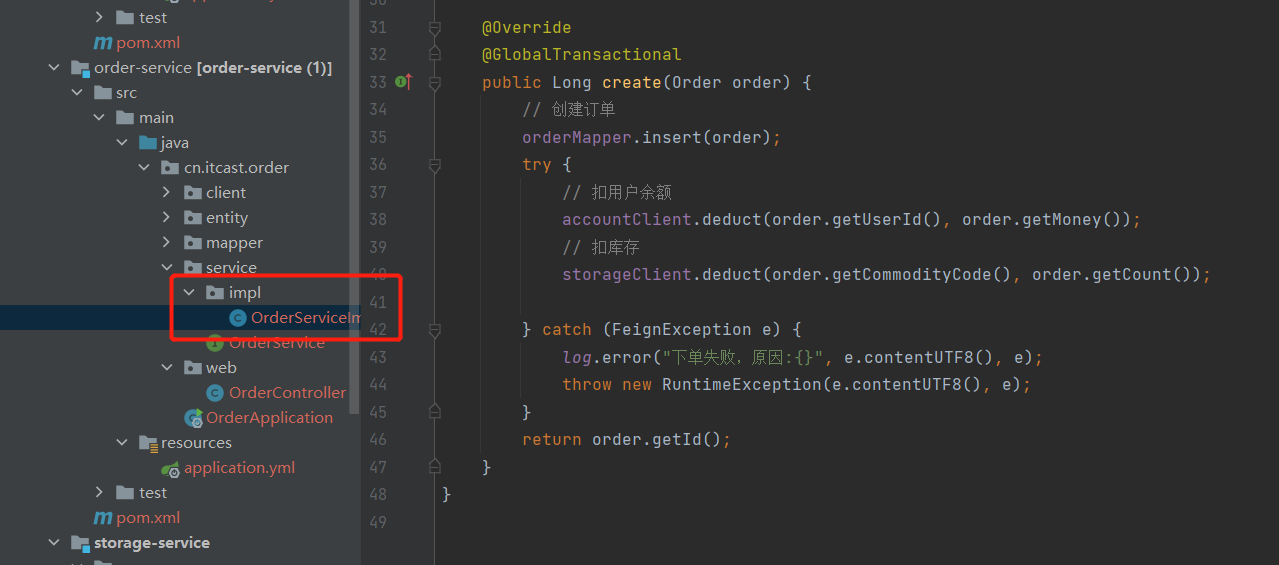
@Override
@GlobalTransactional
public Long create(Order order) {
// 创建订单
orderMapper.insert(order);
try {
// 扣用户余额
accountClient.deduct(order.getUserId(), order.getMoney());
// 扣库存
storageClient.deduct(order.getCommodityCode(), order.getCount());
} catch (FeignException e) {
log.error("下单失败,原因:{}", e.contentUTF8(), e);
throw new RuntimeException(e.contentUTF8(), e);
}
return order.getId();
}
AT模式

阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
TCC模式
day11
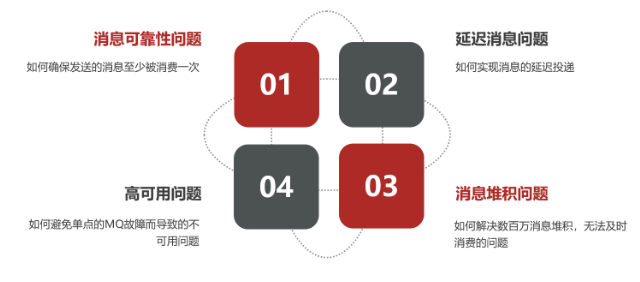
消息可靠性

问题描述:消息从发送,到消费者接收,每一步都可能导致消息丢失,常见的丢失原因包括:
- 发送时丢失:
- 生产者发送的消息未送达exchange
- 消息到达exchange后未到达queue
- MQ宕机,queue将消息丢失
- consumer接收到消息后未消费就宕机
针对这些问题,RabbitMQ分别给出了解决方案:
- 生产者确认机制
- mq持久化
- 消费者确认机制
- 失败重试机制
确实是否受到消息的方式
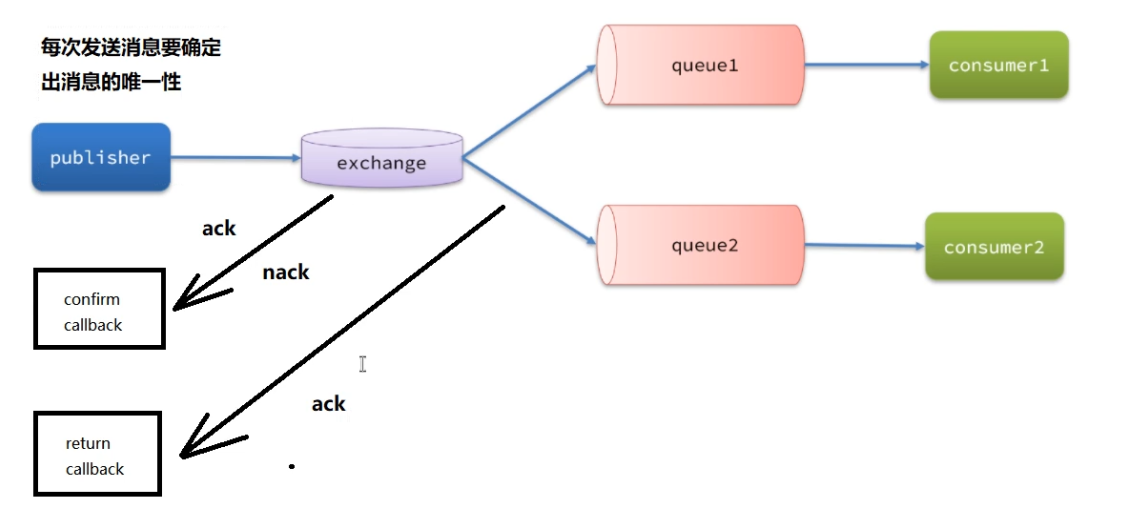
返回结果有两种方式:
- publisher-confirm,发送者确认
- 消息成功投递到交换机,返回ack
- 消息未投递到交换机,返回nack
- publisher-return,发送者回执
- 消息投递到交换机了,但是没有路由到队列。返回ACK,及路由失败原因。
生产者消息确认
修改配置
配置
spring:
rabbitmq:
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
说明:
- publish-confirm-type:开启publisher-confirm,这里支持两种类型:
- simple:同步等待confirm结果,直到超时
- correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback
- publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallback
- template.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false:则直接丢弃消息

若有收获,就点个赞吧
0 人点赞
