1. 介绍
缓存就是内存中的数据,常常来自对数据库查询结果的保存,使用缓存可以避免与数据库频繁的交互,提高响应速度。mybaits的缓存分为一级缓存和二级缓存。
(1)一级缓存:是sqlsession级别的缓存,在操作数据库时需要构造sqlsession对象,在对象中有一个数据结构 (HashMap)来存储缓存数据。不同的sqlsession之间的缓存域(HashMap)是互不干扰的。
(2)二级缓存:是mapper级别的缓存,多个sqlsession去操作同一个Mapper的sql语句,多个sqlsqssion可以共 用二级缓存,二级缓存是跨sqlsession的。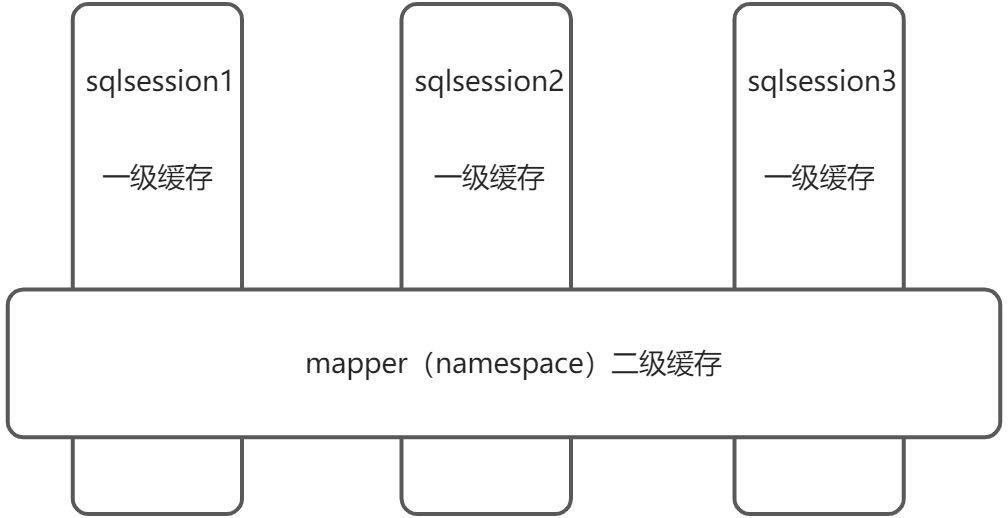
2. 一级缓存
2.1 测试一级缓存
@Testpublic void firstLevelCache() {InputStream resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");SqlSessionFactory build = new SqlSessionFactoryBuilder().build(resourceAsStream);SqlSession sqlSession = build.openSession(true);UserDao userMapper = sqlSession.getMapper(UserDao.class);// 第一步:首先查询一级缓存,有则直接返回,没有则去数据库查询,同时将查询出来的结果放入一级 // 缓存User user1 = userMapper.findUserById(1);// 中间进行了增删改的操作并进行事务提交后,就会刷新一级缓存;或者可以用clearCache()手动刷新 // 缓存,避免出现脏读// 第二步:首先查询一级缓存,有则直接返回,没有则去数据库查询,同时将查询出来的结果放入一级 // 缓存User user2 = userMapper.findUserById(1);// 如果没有刷新缓存则为true,刷新了缓存为falsesystem.out.println(user1 == user2)}
2.2 一级缓存原理与源码分析
- 问题分析
- 一级缓存到底是什么?(HashMap)
- 一级缓存什么时候被创建?(在Executor类的query方法中,如果cacheKey值在缓存中不存在则创建)
- 一级缓存的工作流程是怎样的?(查询时判断cacheKey存不存在,存在直接返回缓存数据,不存在则向数据库查询,得到的结果再存进一级缓存)
- 源码分析过程
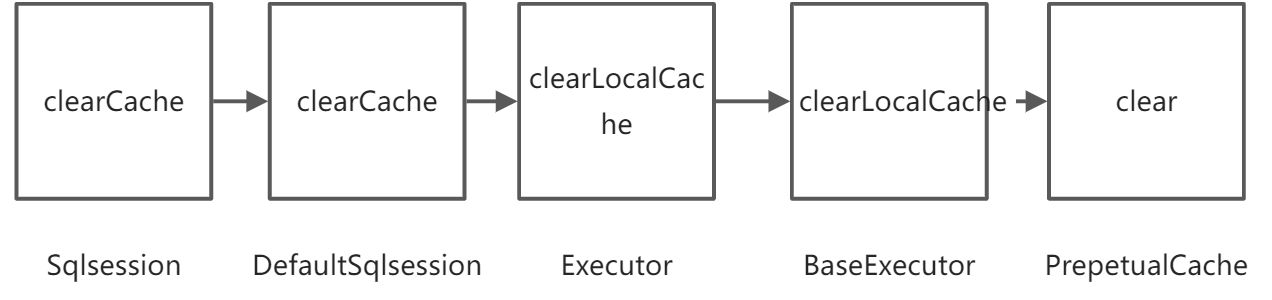
- Sqlsession.clearCache():一级缓存是在sqlsession中的,所以就从sqlsession的类开始研究,找遍sqlsession的方法,只有一个clearCache()是和缓存相关的,所以就从clearCache方法入手。
- DefaultSqlsession.clearCache():选择SqlSession的实现类DefaultSqlsession,发现clearCache()方法的实现执行了executor.clearLocalCache()。
- Executor.clearLocalCache():点进该方法发现是一个接口,所以选择它的实现类BaseExecutor。
- BaseExecutor.clearLocalCache() :该方法调用的是localCache.clear(),继续看该方法。
- PrepetualCache.clear():该方法调用的是cache.clear(),点进cache发现是一个Map,所以cache.clear()实际上就是Map.clear()。由此可知,一级缓存的数据结构就是HashMap。
- Executor.createCacheKey():在Executor中找创建一级缓存的方法。
- BaseExecutor.createCacheKey():createCacheKey方法的实现,生成cacheKey,需要的参数分别为statementId,params(参数),boundSql(sql语句),rowBounds(分页)。
- 然后查找Executor中调用createCacheKey方法的地方,发现在query方法中,调用createCacheKey(ms, parameter, rowBounds, boundSql)创建了cacheKey,然后通过localCache.getObject(key)来判断该key存不存在,如果存在则直接返回缓存中的值,如果不存在,调用方法queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql),在该方法中,先向数据库查询,得到的结果存入一级缓存中localCache.putObject(key, list),此时,是一级缓存创建的时候。
3. 二级缓存
3.1 二级缓存介绍
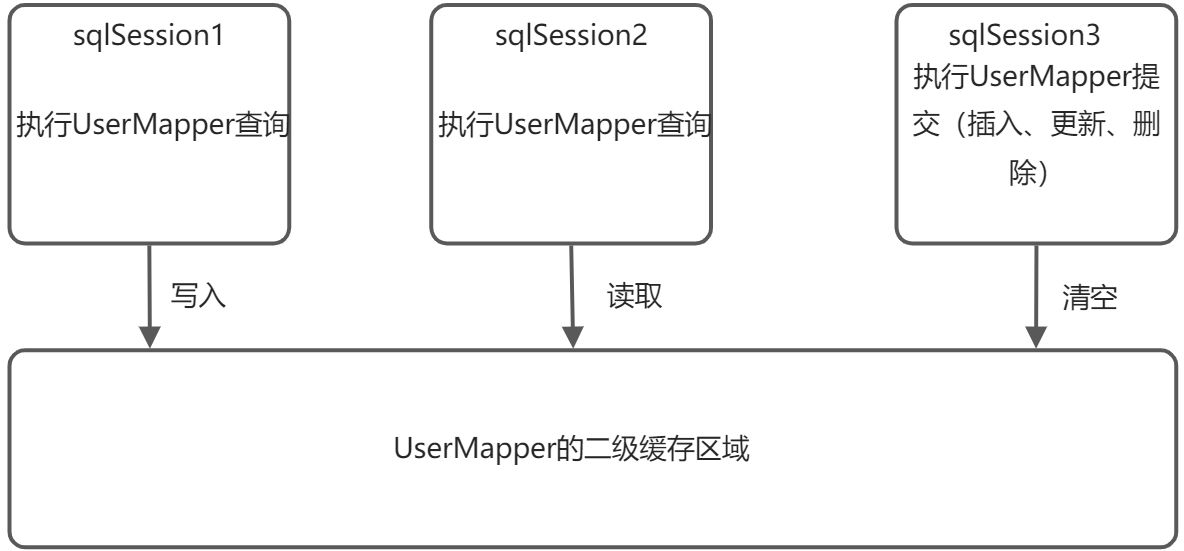
- 二级缓存的原理跟一级缓存一样,第一次查询会把数据放入缓存中,第二次查询就会去缓存中取,但是一级缓存是基于sqlSesion,二级缓存是基于mapper文件的namespace的,使用同一个mapper的多个sqlSession共用一个二级缓存区域,如果两个mapper的namespace相同,即使是不同的mapper文件也共享二级缓存
3.2 如何使用二级缓存
- 开启二级缓存
和一级缓存的默认开启不同,二级缓存需要手动开启,首先在全局配置文件sqlMapperConfig.xml中加入如下代码:
<!--开启二级缓存--><settings><setting name="cacheEnabled" value="true" /></settings>
其次在userMapper.xml文件开启缓存
<!--开启二级缓存--><cache></cache>
- 测试二级缓存的方法跟测试一级缓存差不多,只是把一个sqlSession变为多个sqlSession。二级缓存存储的不是对象本身,而是对象的数据,所以两次查询的对象地址是不一样的。
3.3 使用redis来实现二级缓存
- mybatis默认的二级缓存的实现类是PerpetualCache,这个实现类可以通过Mapper.xml中的
标签来配置,例如 ,默认就是PerpetualCache,也可以去实现Cache接口来自定义缓存实现类。 - 在PerpetualCache类中可以看到mybatis默认的二级缓存底层数据结构也是HashMap。
- mybatis自带的二级缓存只能用于单服务器,如果要实现分布式缓存,就要整合其它的缓存实现,比如redis。
mybatis整合redis
pom文件
<dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-redis</artifactId><version>1.0.0-beta2</version></dependency>
配置文件 ```xml <?xml version=”1.0” encoding=”UTF-8”?> <!DOCTYPE mapper PUBLIC “-//mybatis.org//DTD Mapper 3.0//EN” “http://mybatis.org/dtd/mybatis-3-mapper.dtd">
3. redis.properties```propertiesredis.host=127.0.0.1redis.port=6379redis.connectionTimeout=5000redis.password=redis.database=0

若有收获,就点个赞吧
0 人点赞
