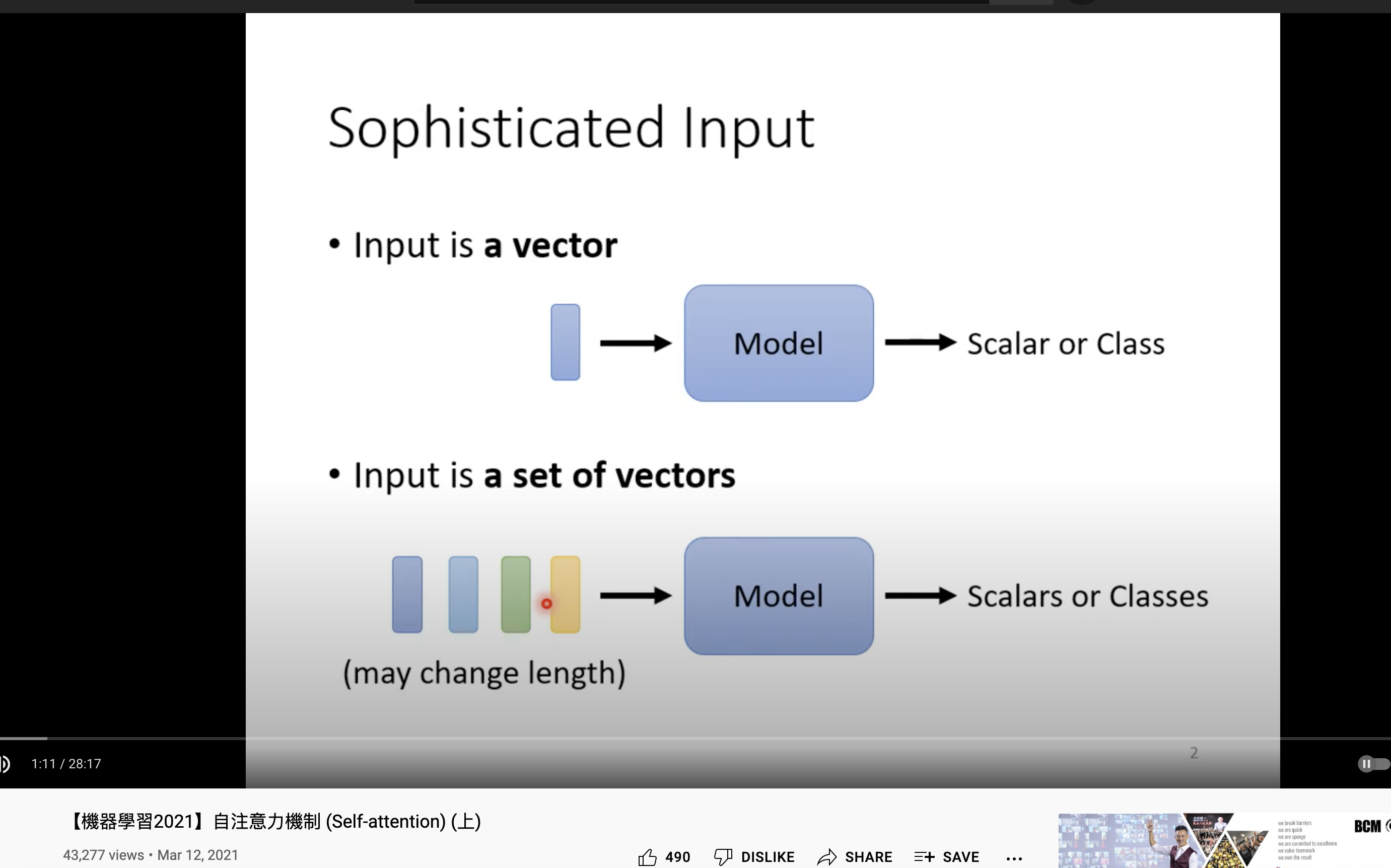
输入是一系列 vectors,长度、数量都不固定。输出是一个 标量(具体数值) 或者 分类。
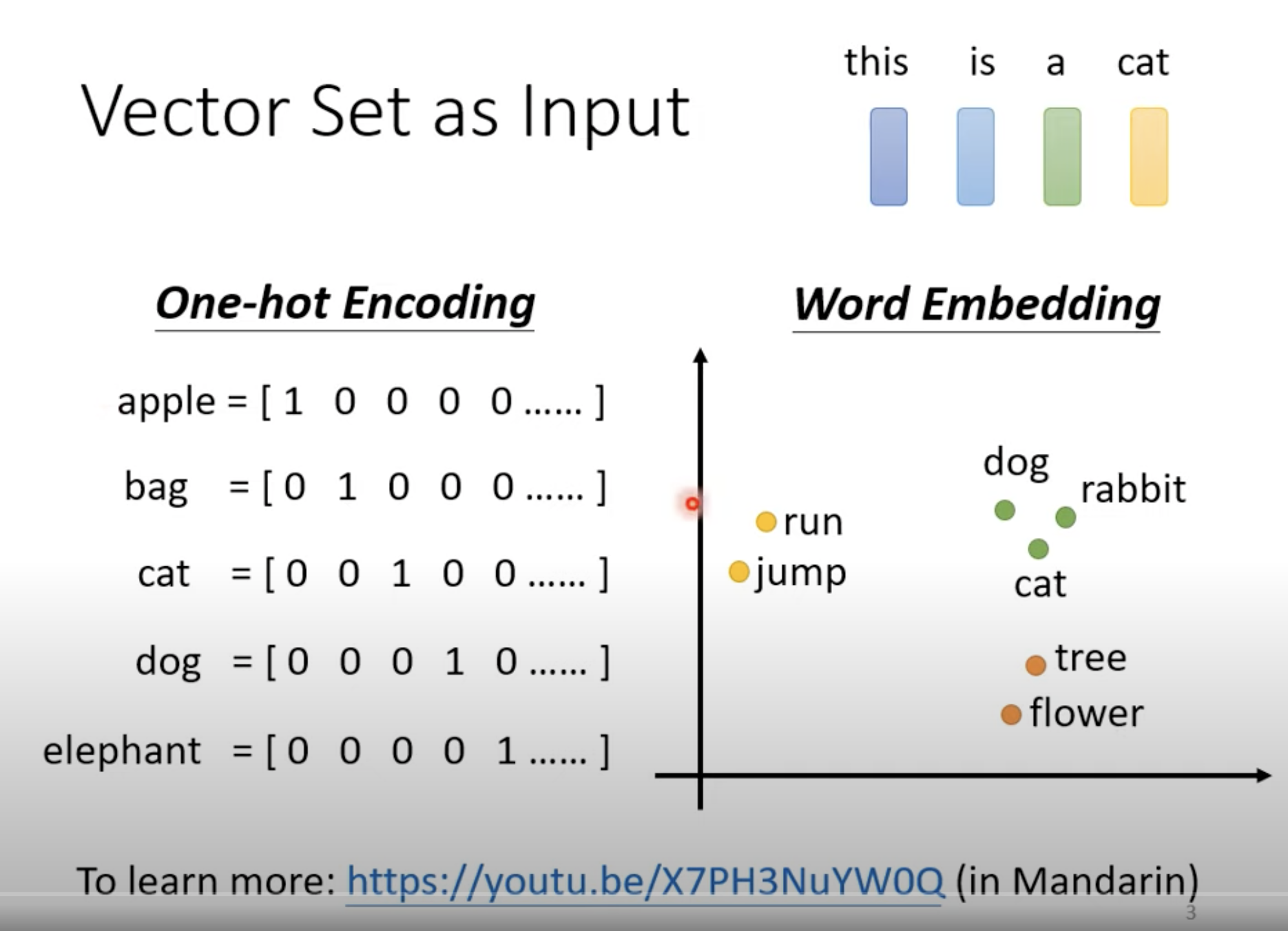
左边 one-hot 看不到词与词之间的关系,看不到相似度。比如 cat 和 dog,我们知道它们都是动物,但从 one-hot里看不出来。
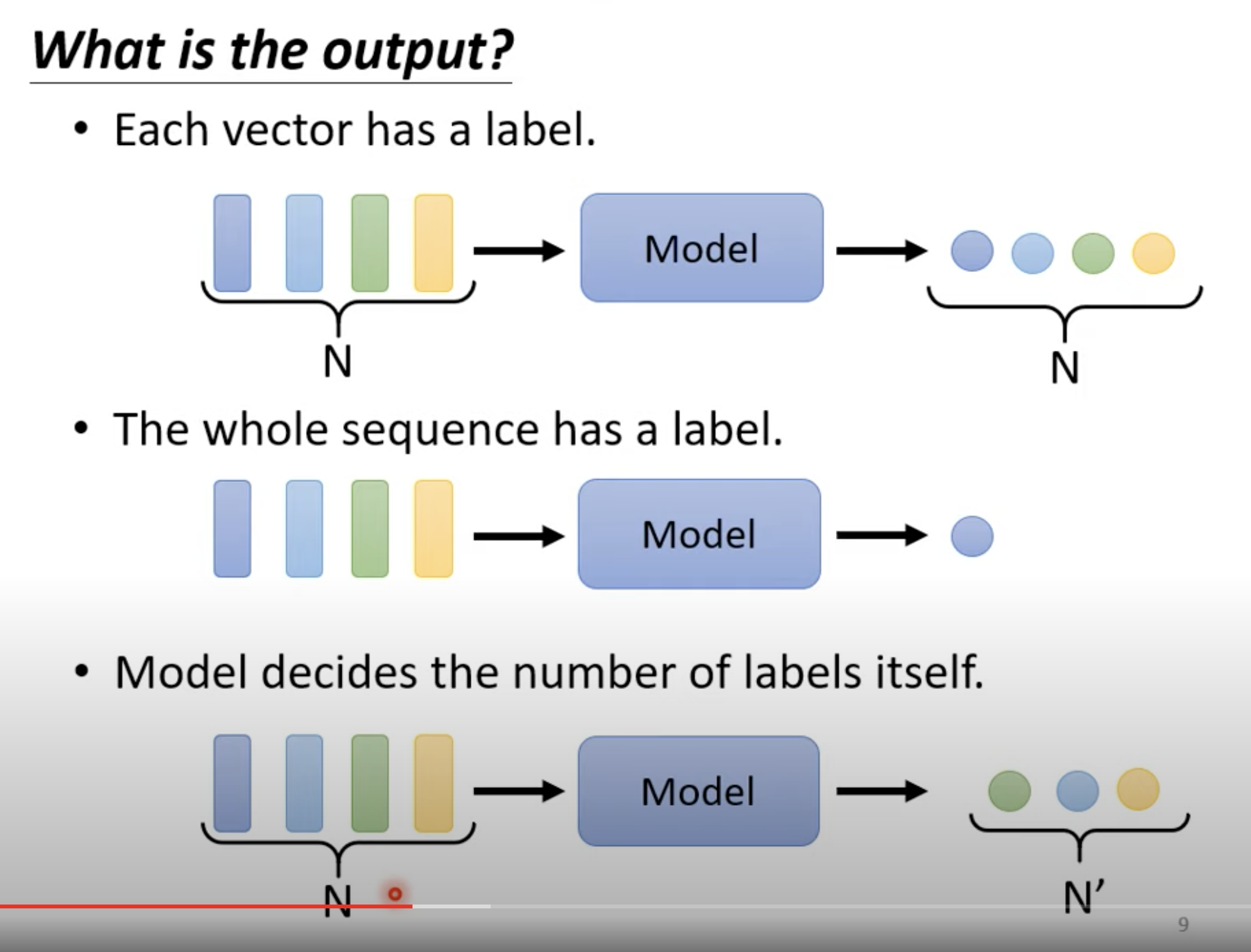
输出有三类:
- 每一个 vector 输出一个 labe,有多少输入,就有多少输出l;
- 整个 sequence 输出一个label;
- 模型 来决定输出多少个 label。
本文只关注第一个类型。
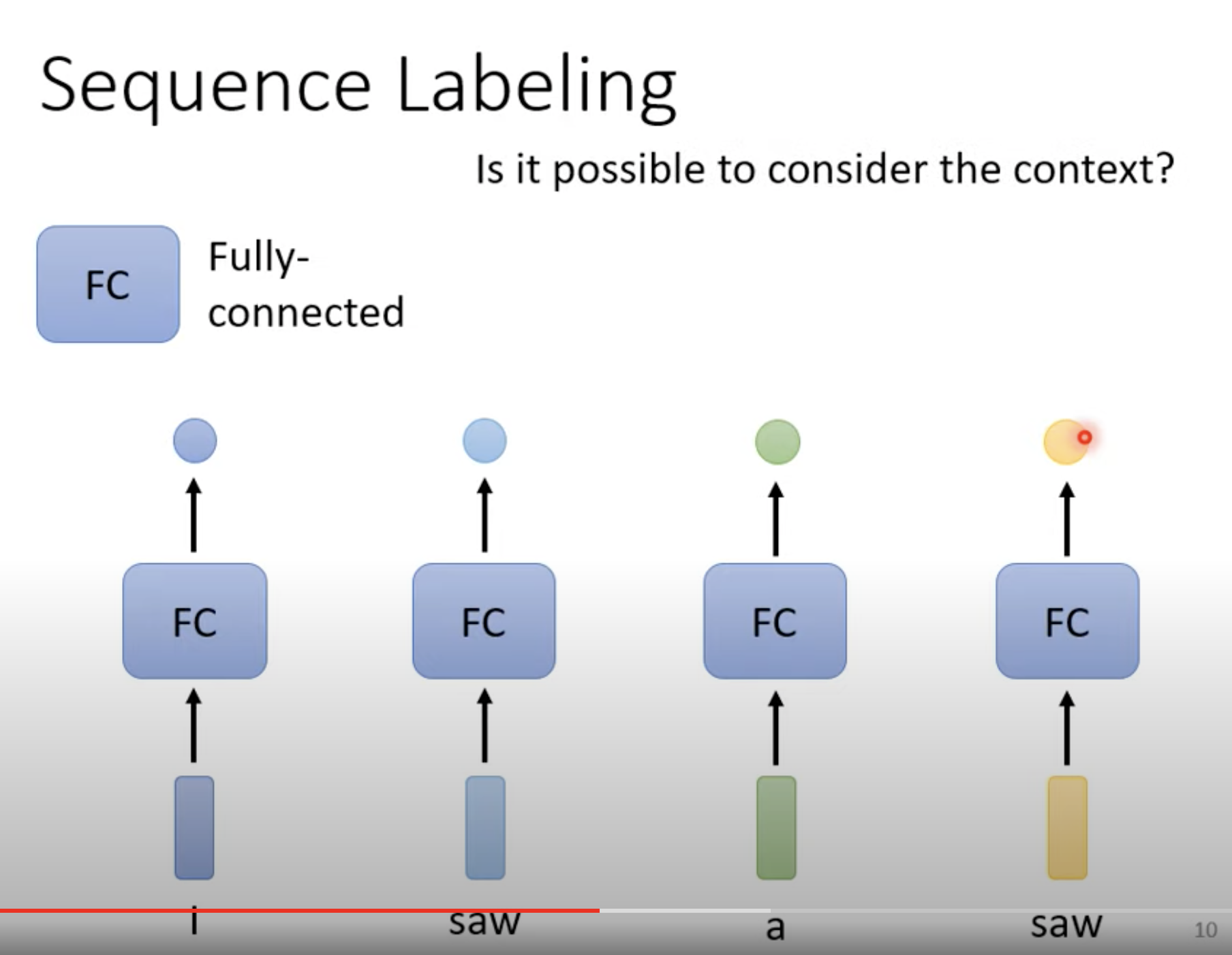
解决方案一:每个 vector 对应一个 FC layer,各个击破。第一个 saw 是名词,第二个 saw 是动词,但由于前后无关,模型将会很困惑。
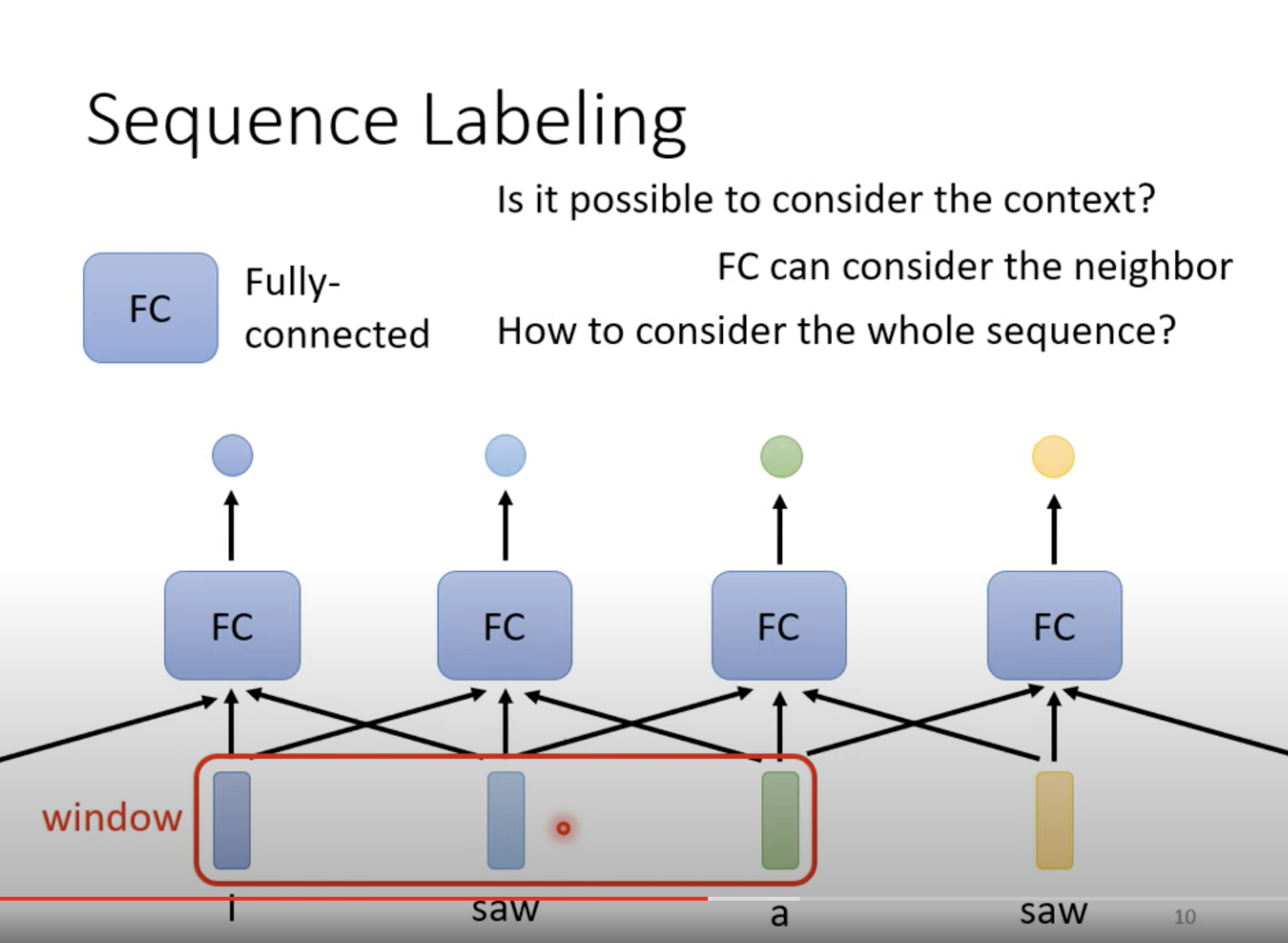
如果用一个把左右 neighbor 联系起来,可以考虑进去部分上下文。
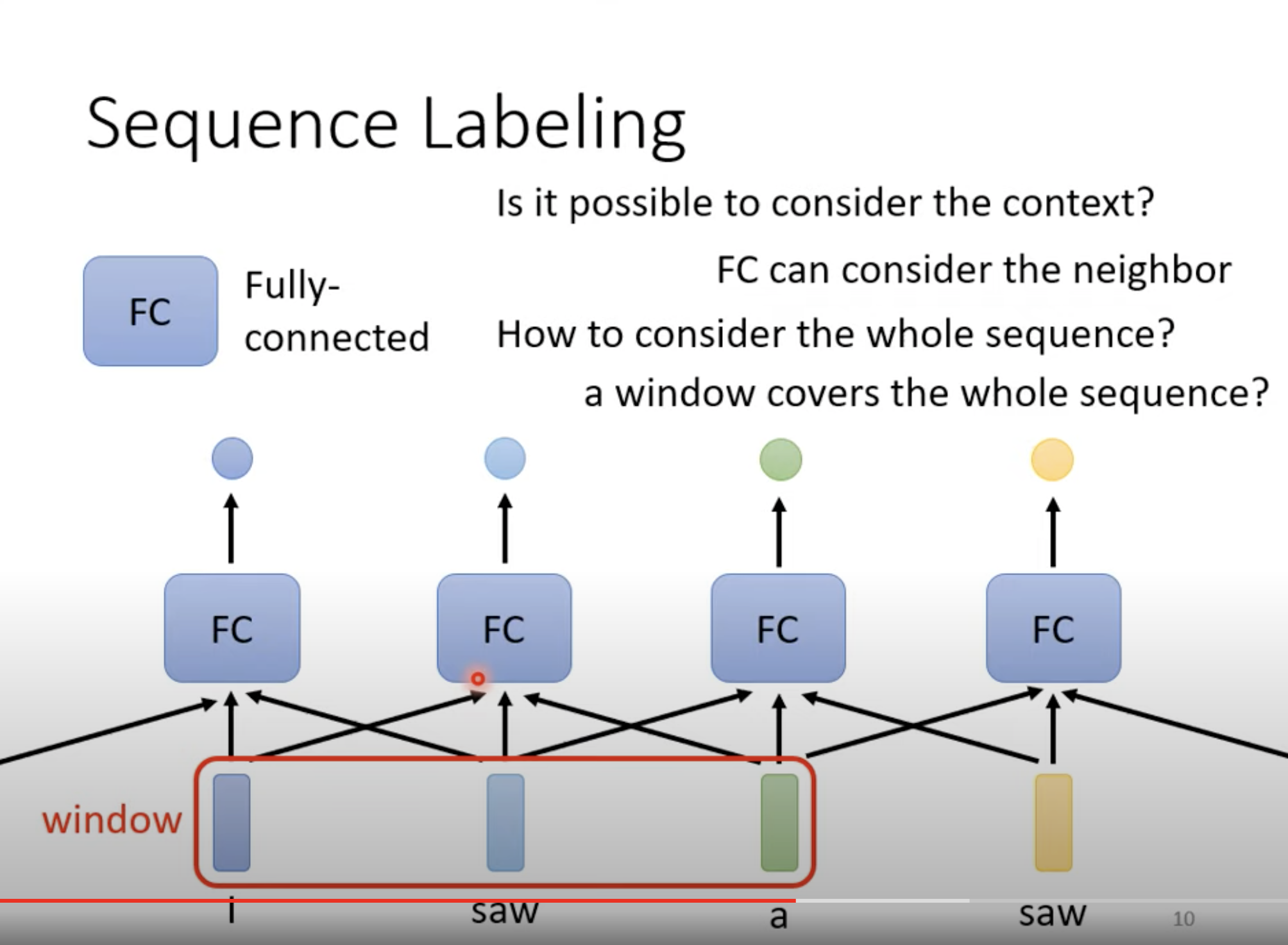
如果开一个非常大的 window 的话,不仅训练参数会增多,model 也有可能 over-fitting。
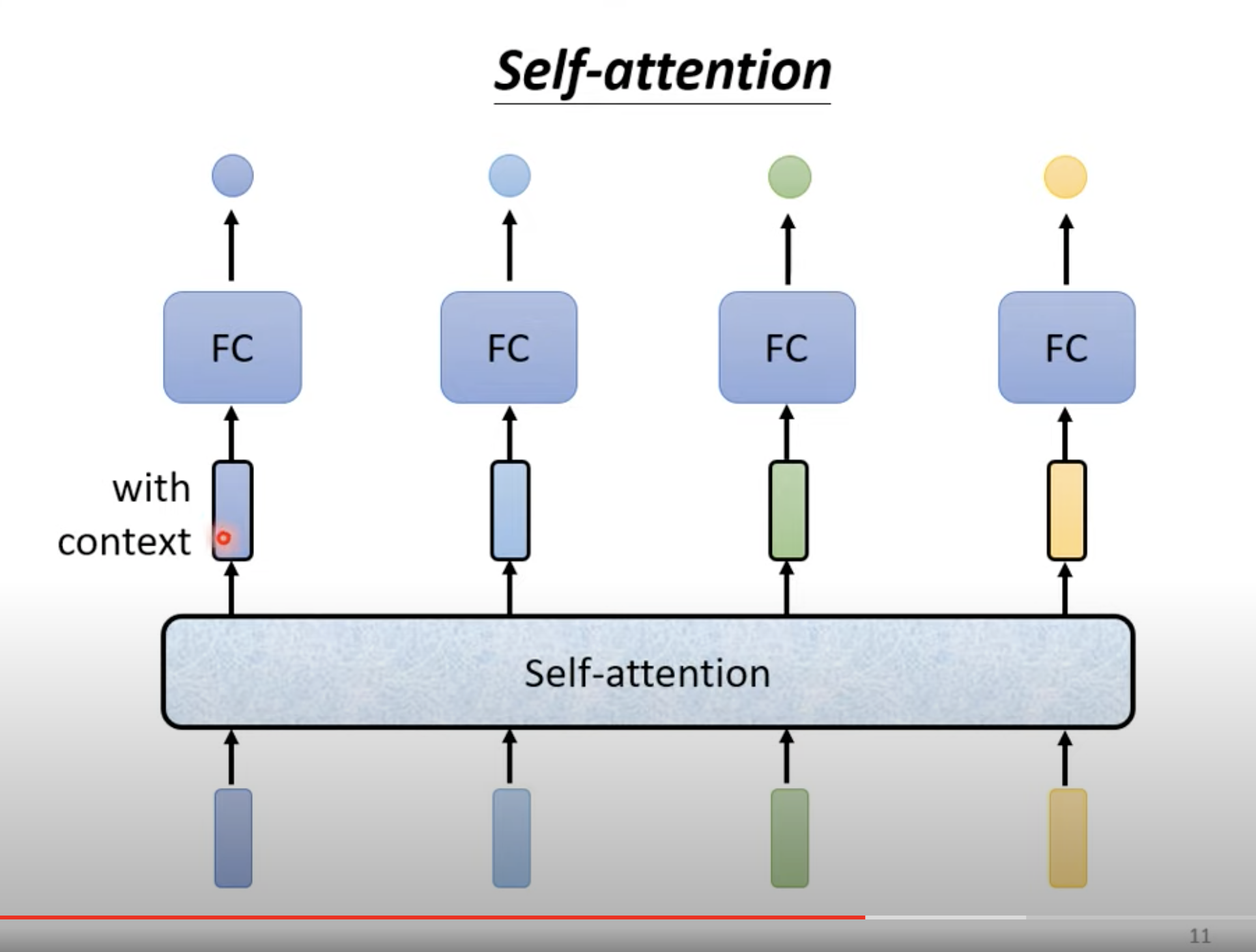
接下来到了本文重点:self - attention 考虑一整个 sequence。
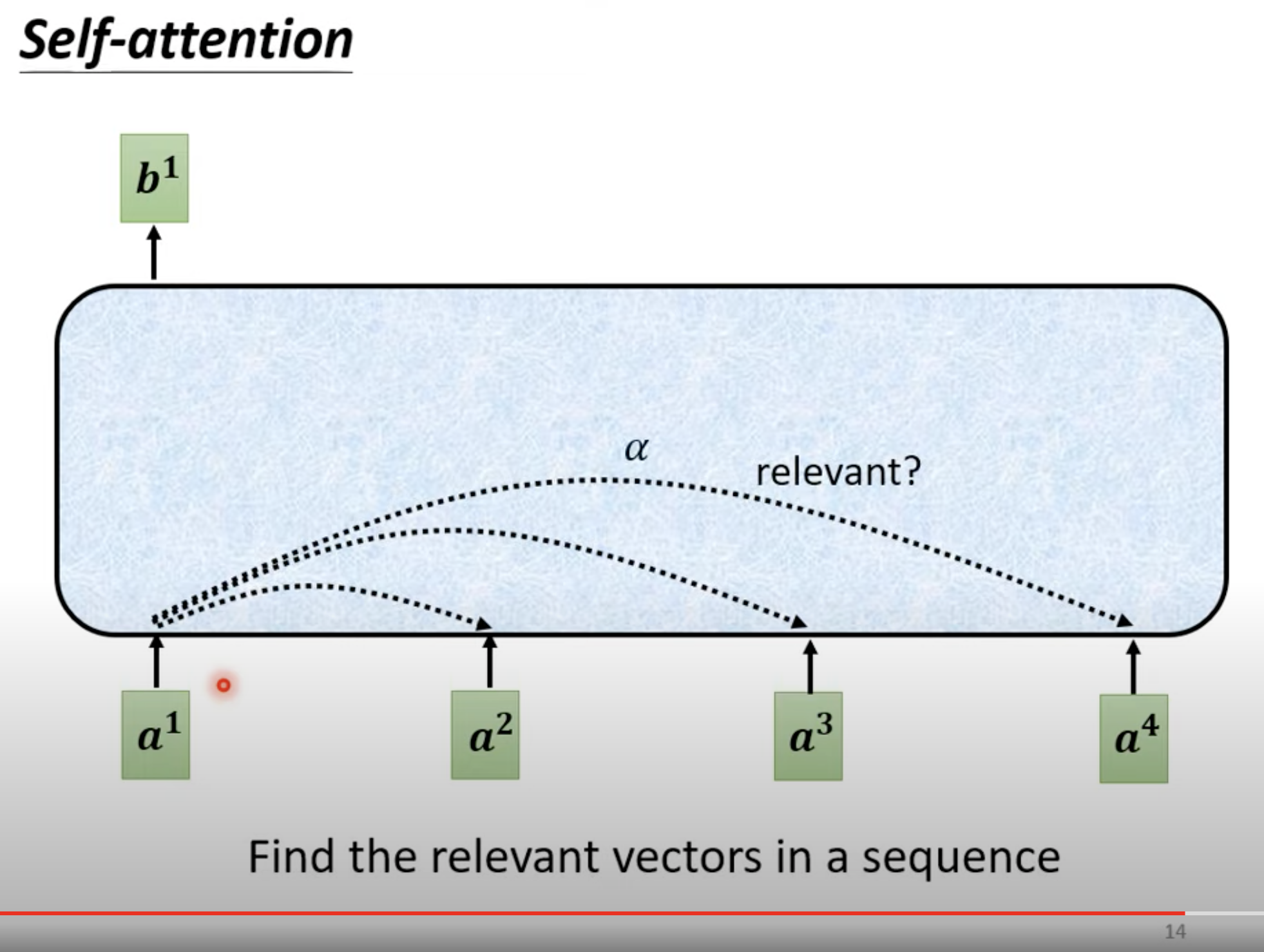
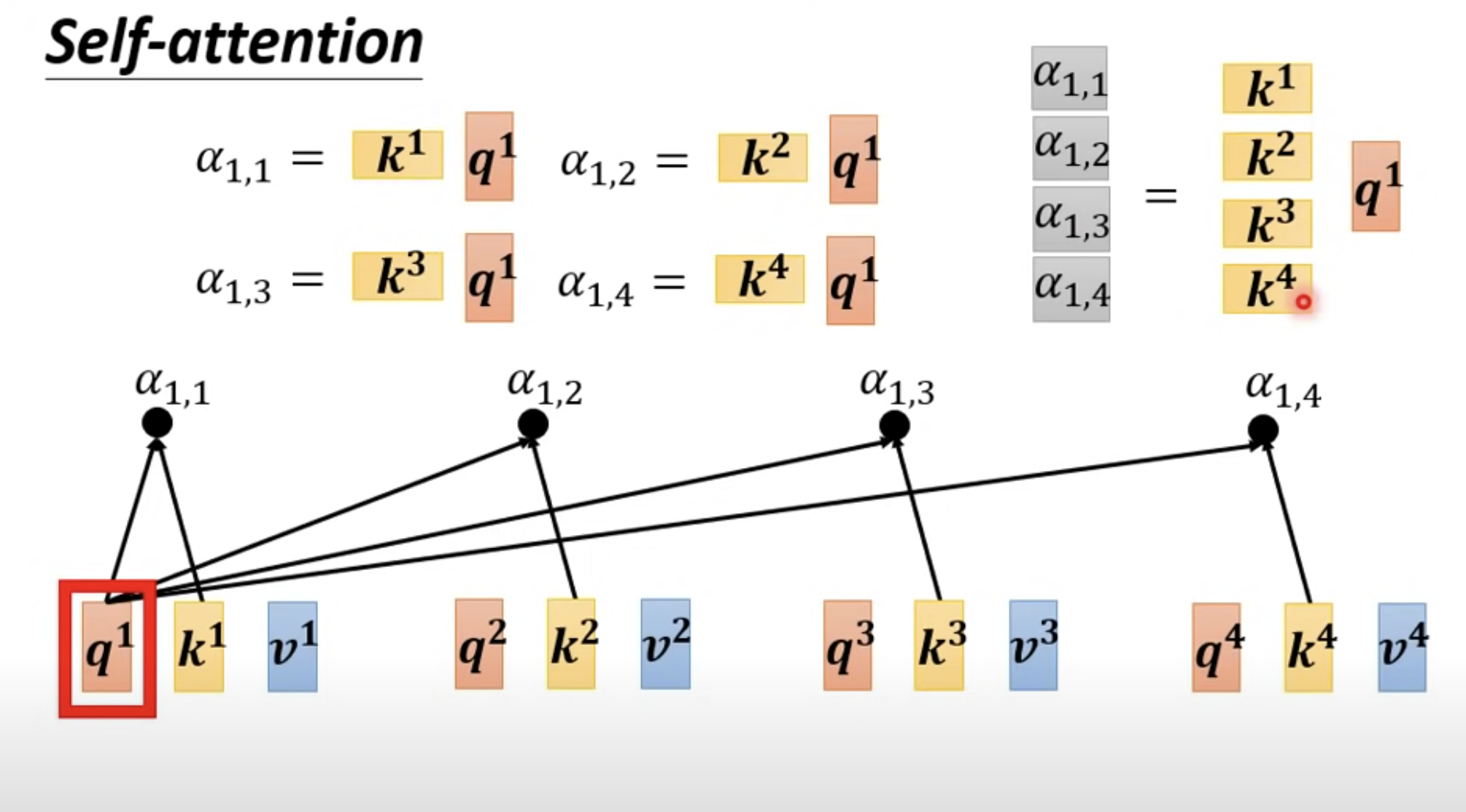
有 a1、a2、a3、a4 四个向量,如何找到 a1 和 a4 之间的关系(图中的阿尔法)呢? 阿尔法是一个标量。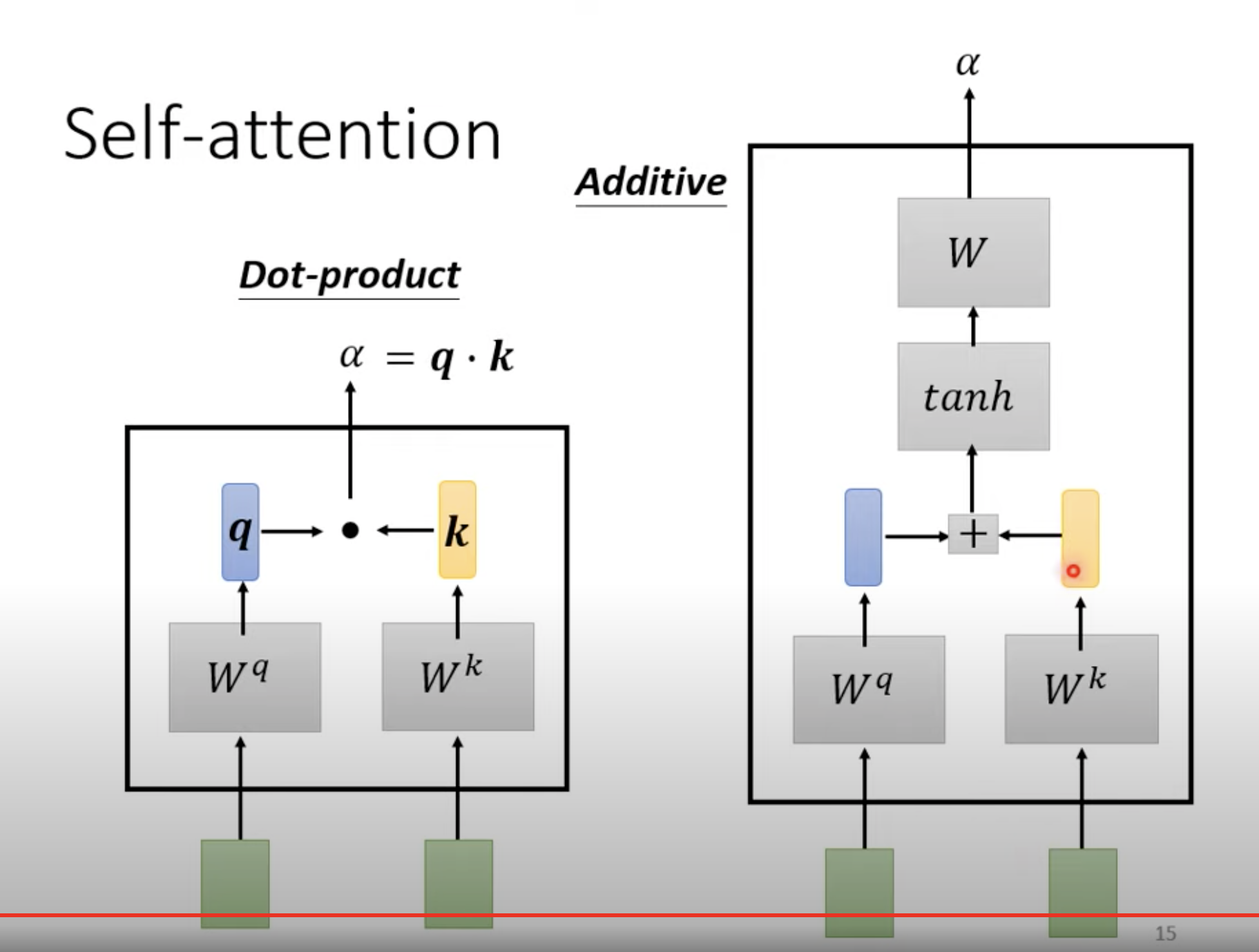
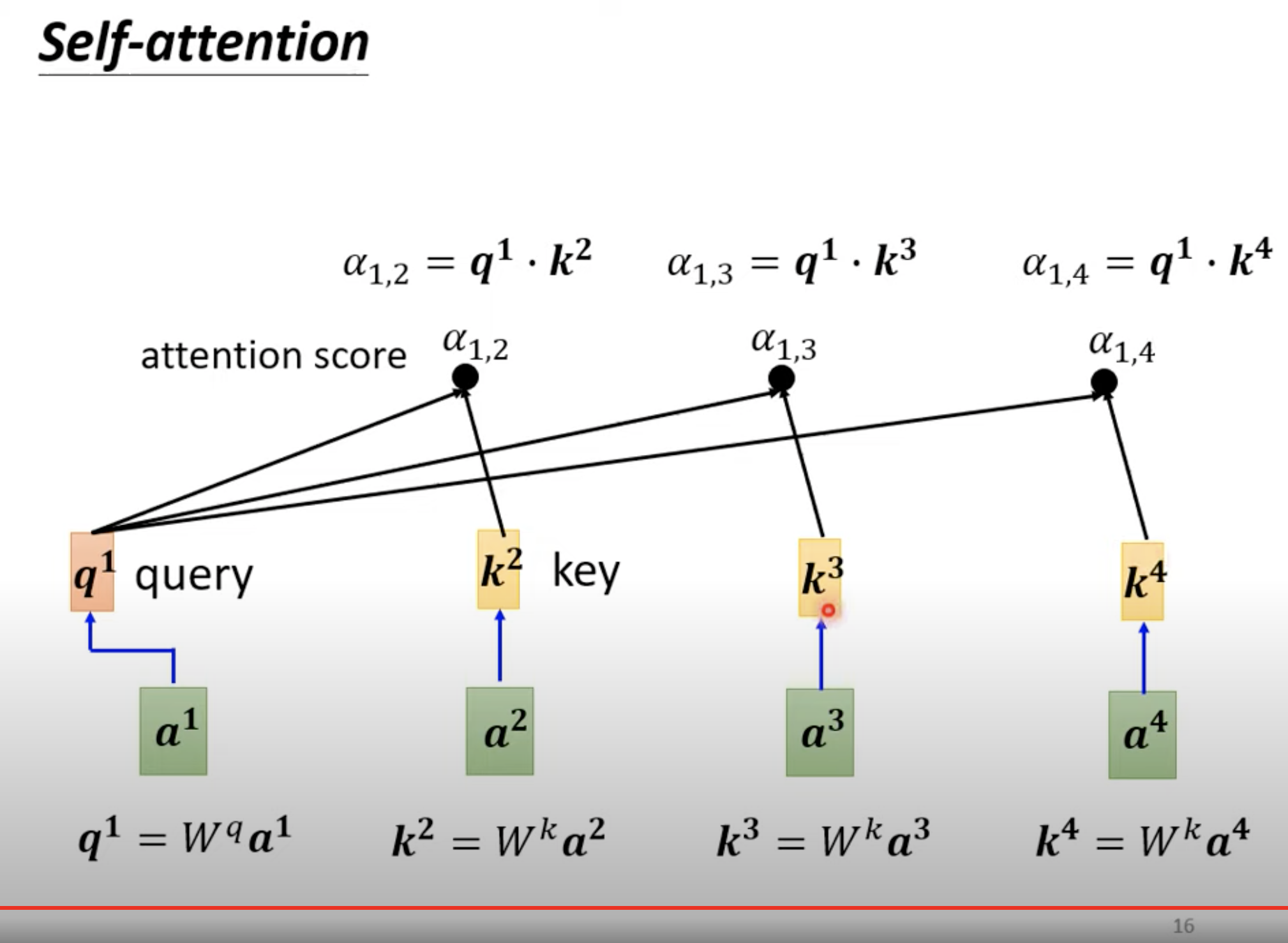
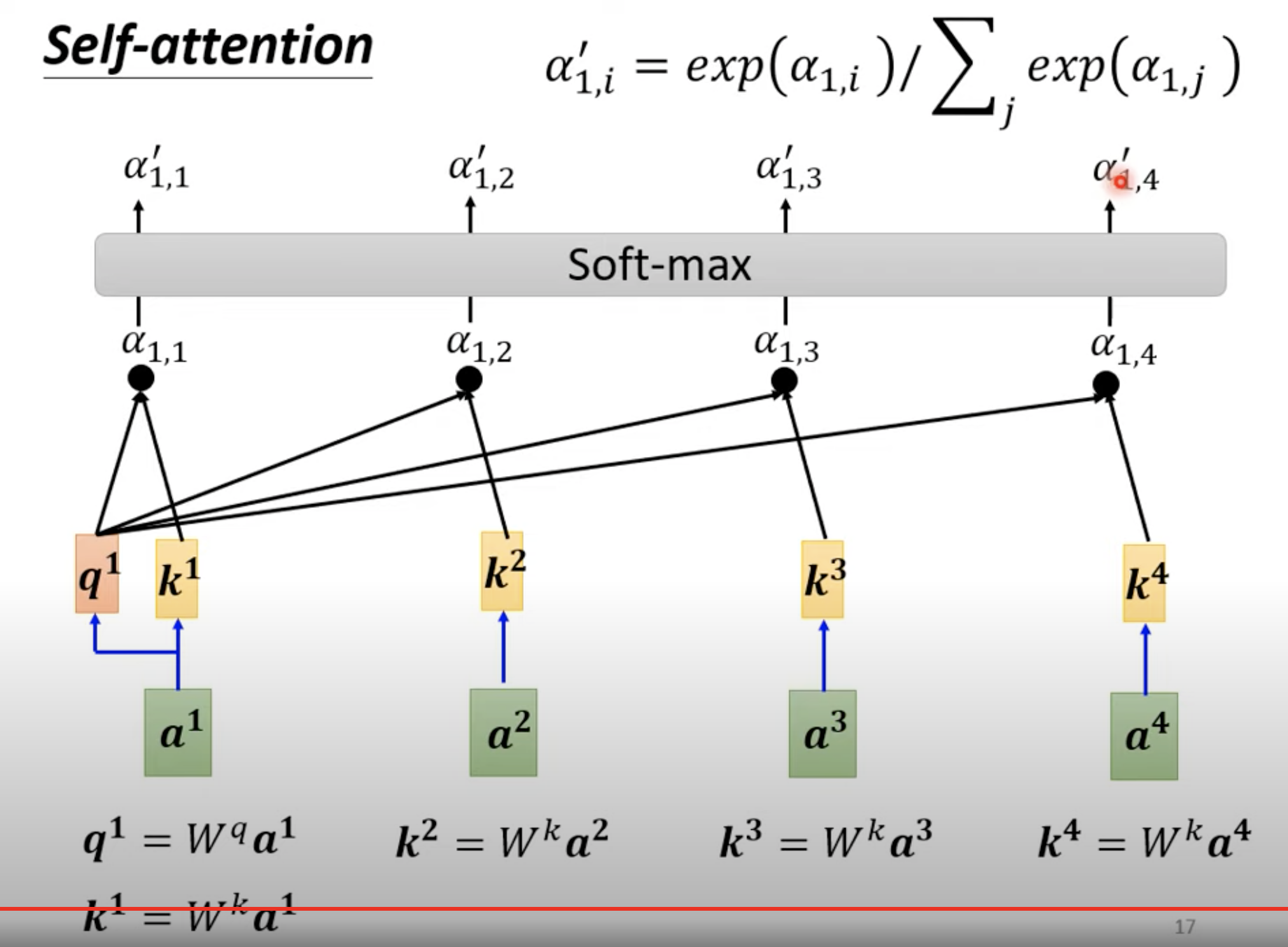
求完 阿尔法 后,再过一个 softmax。

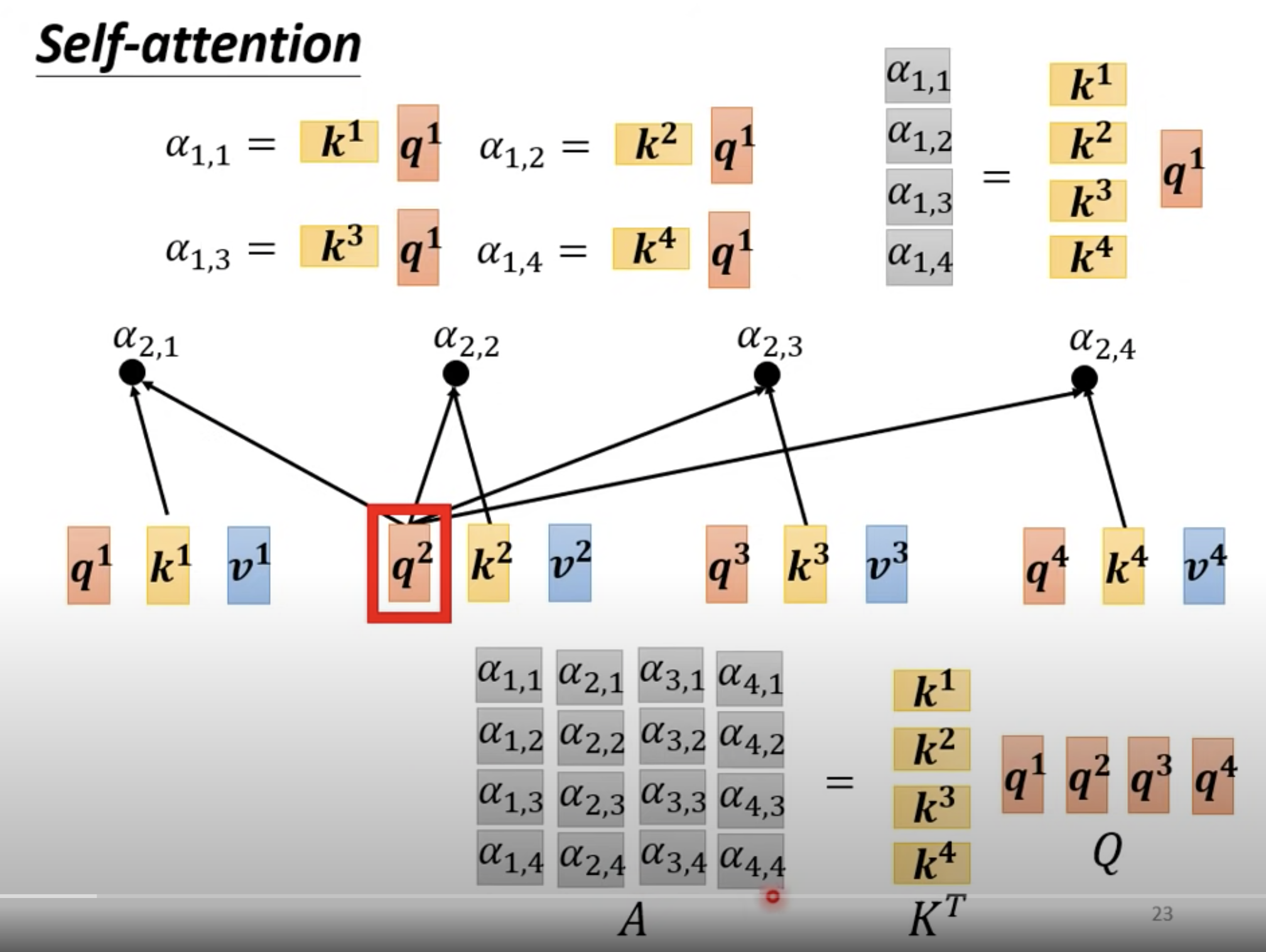
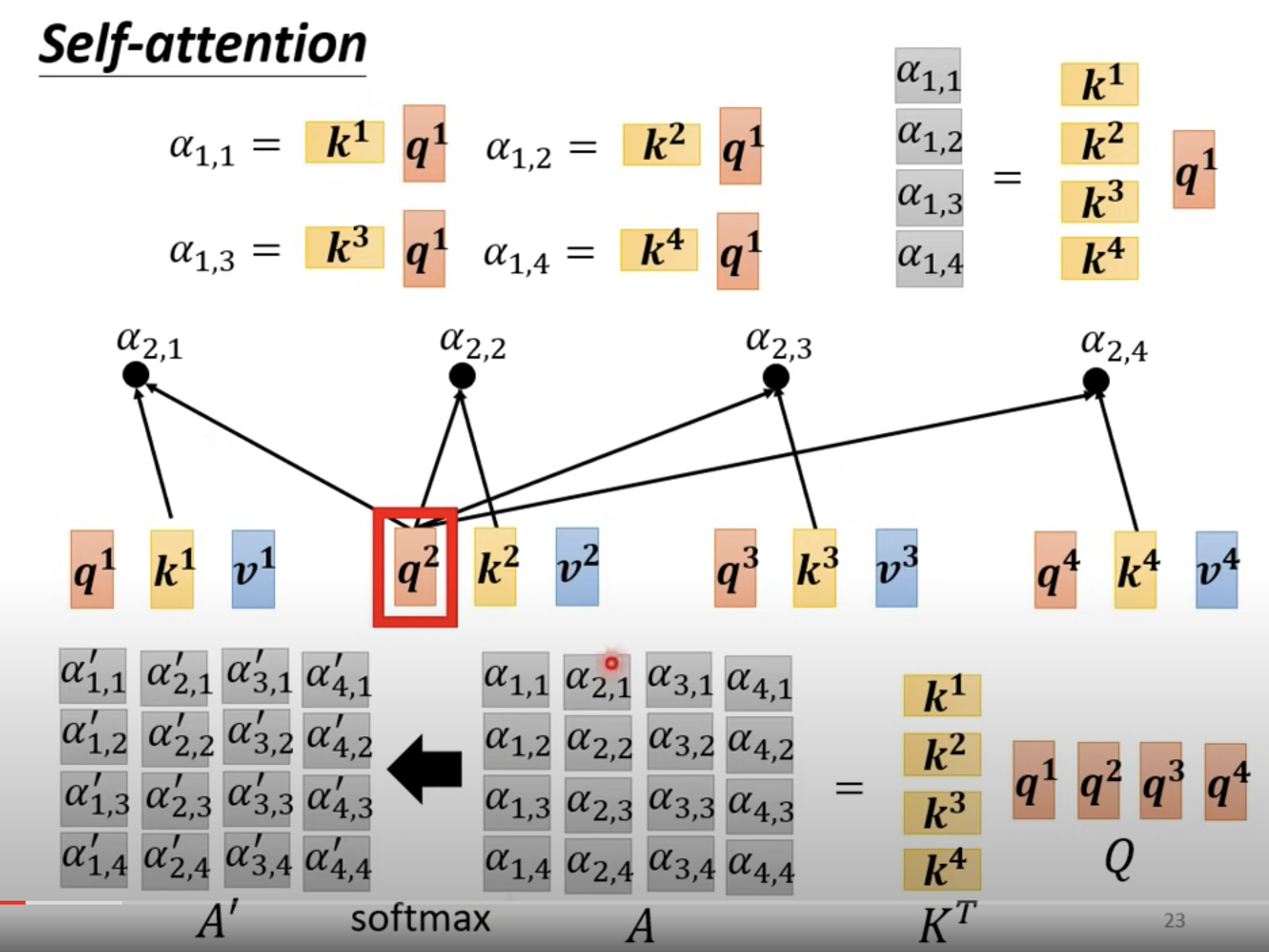

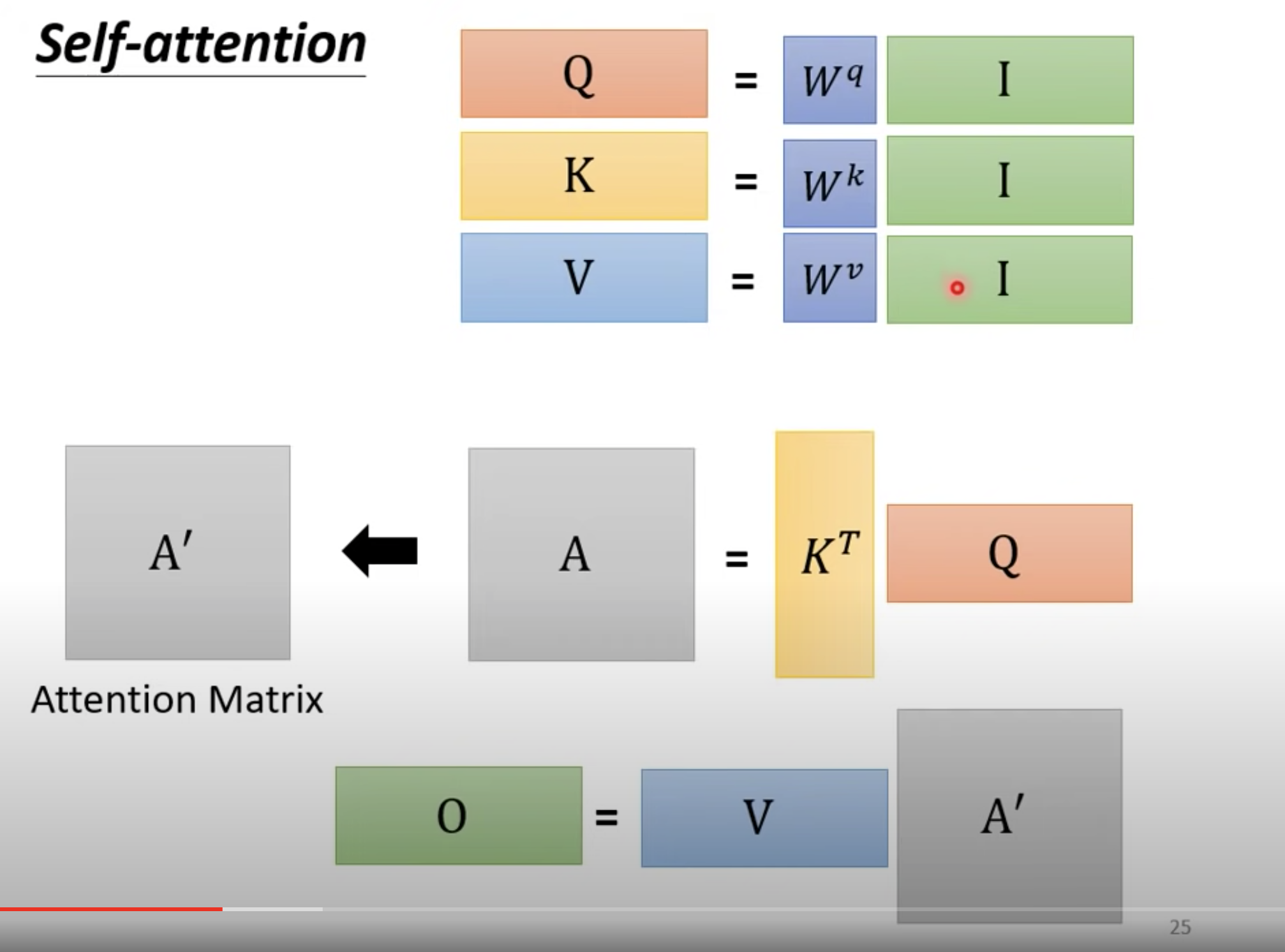
大写 I: Input
大写O: Output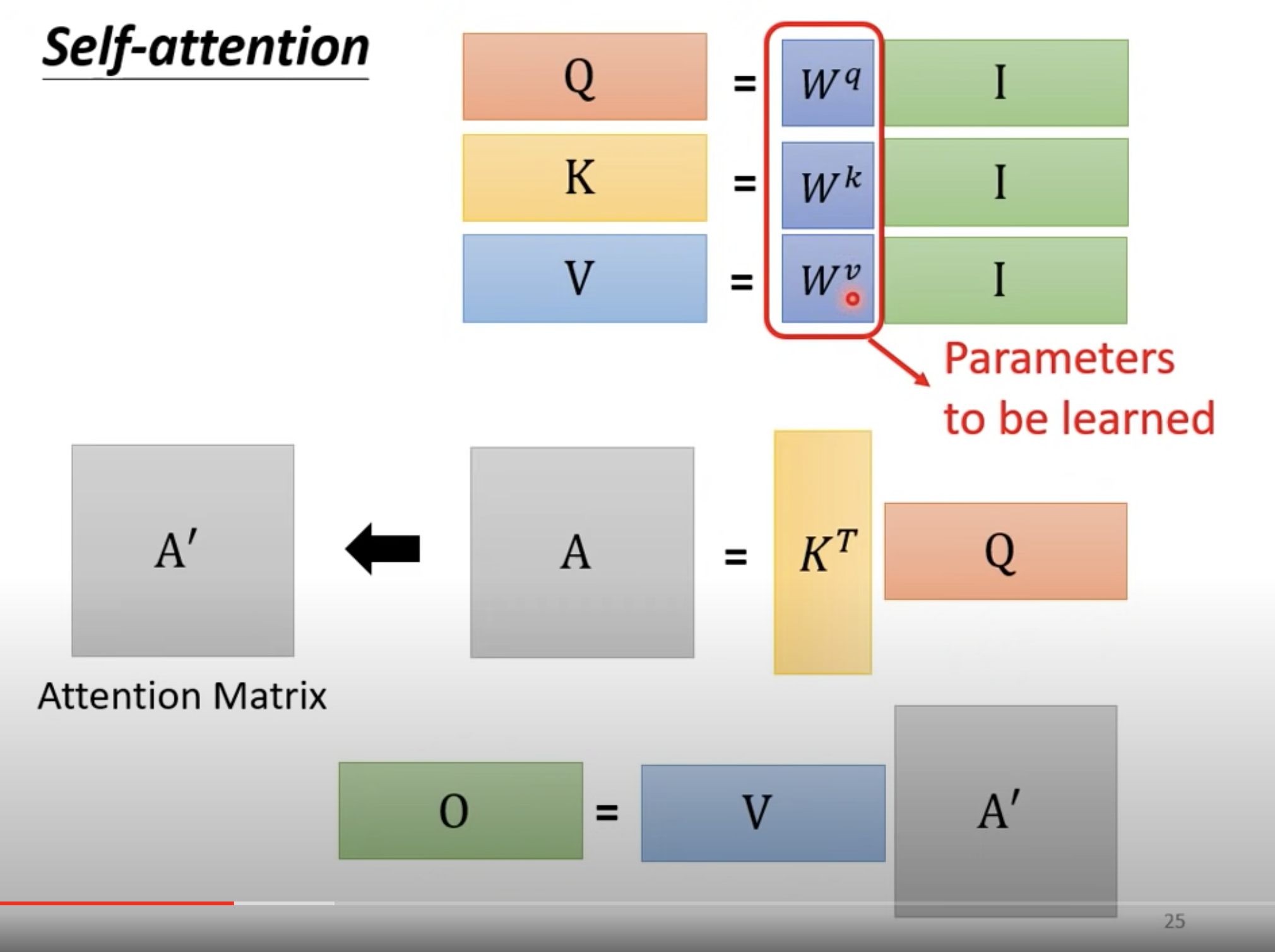

需要多少个 Head 也是一个需要调的 hyper- parameter。一般做翻译的model要用多个 head。
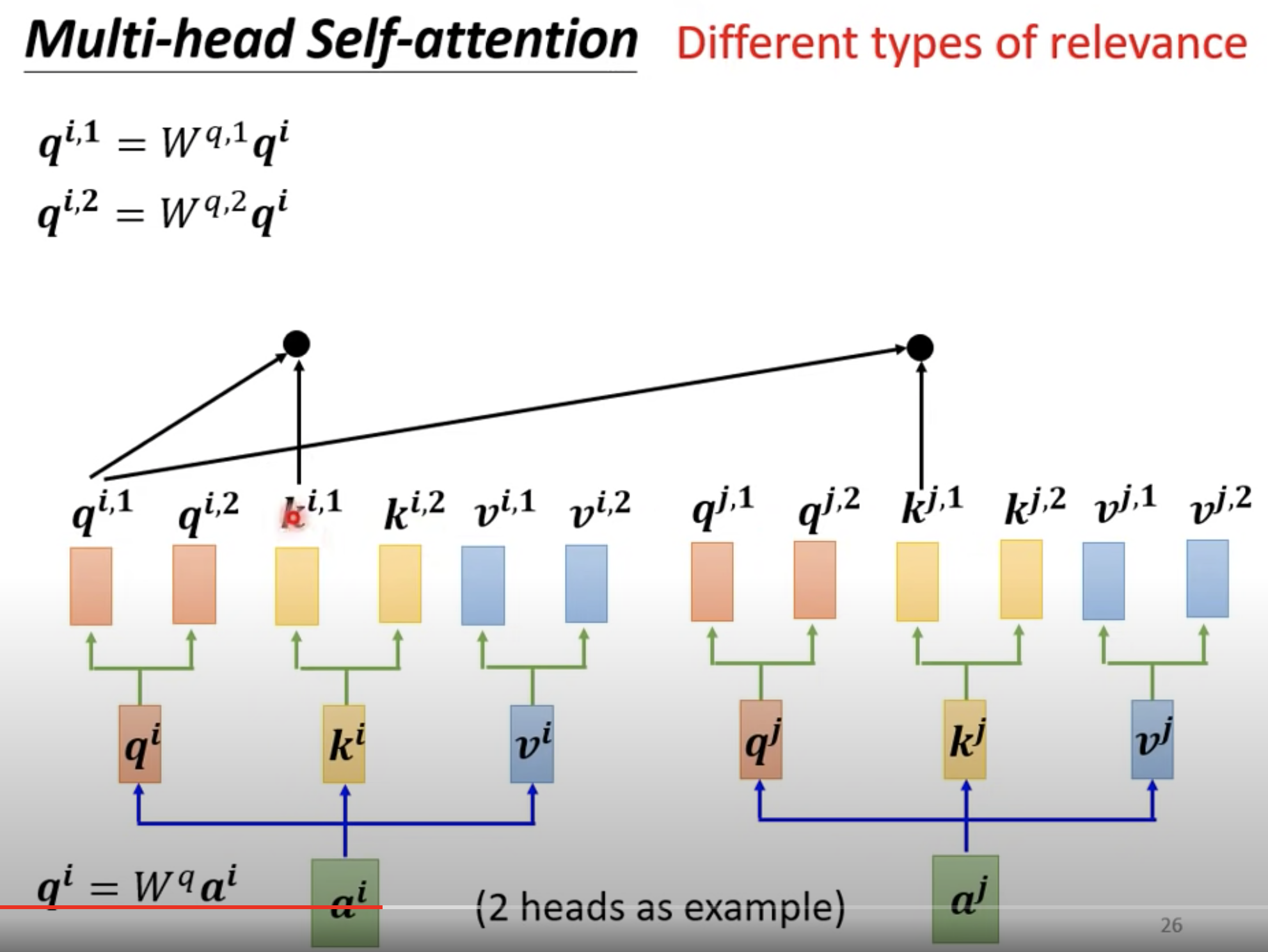
多个 head,也即是在算完 q^i 之后,再乘以两个不同的 W^q ,得到两个 qi,1 和 qi,2 然后每个 Head 分开算。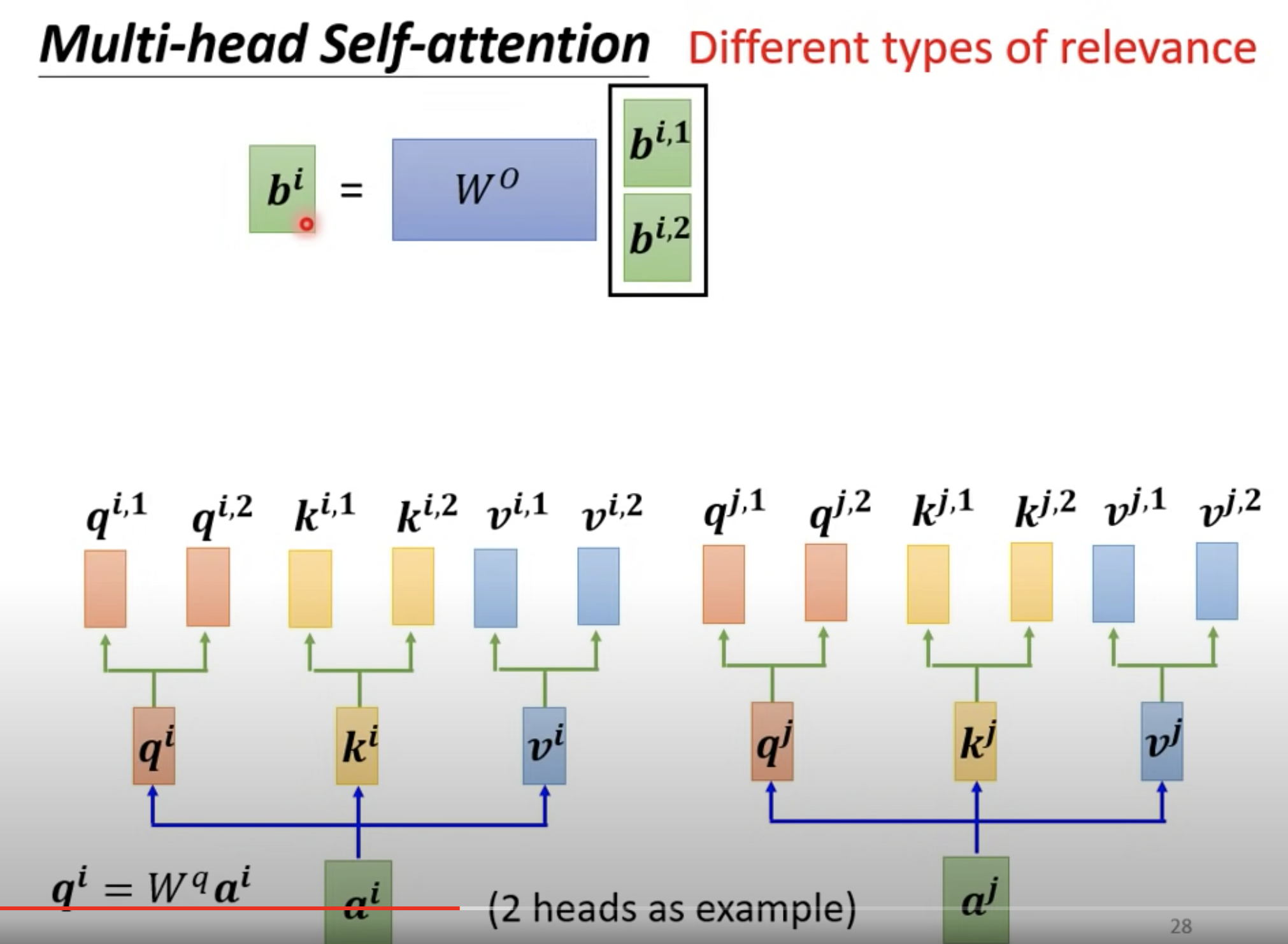
到目前为止,a1、a2、a3、a4是不包含位置信息的。(笔者猜测,前后顺序改变之后,对学习到的3个 W 应该没有影响)
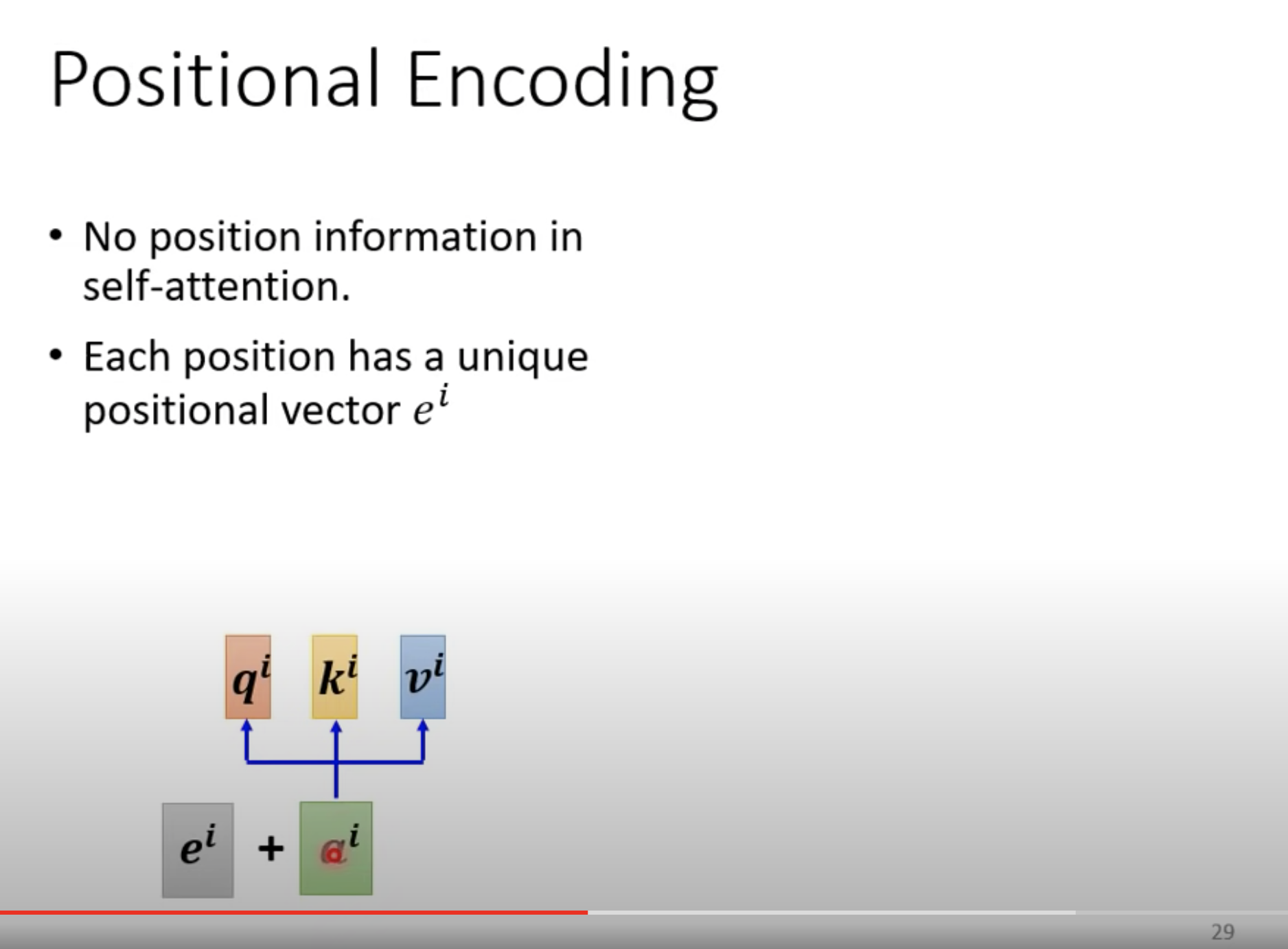
如果要加位置信息,可以 把位置信息 和 a 拼接到一起。


CNN 可以看作是简化版的 self-attention,一个 filter 只考虑周边的 pixels。
反之,self- attention 可以看作是复杂版的 CNN。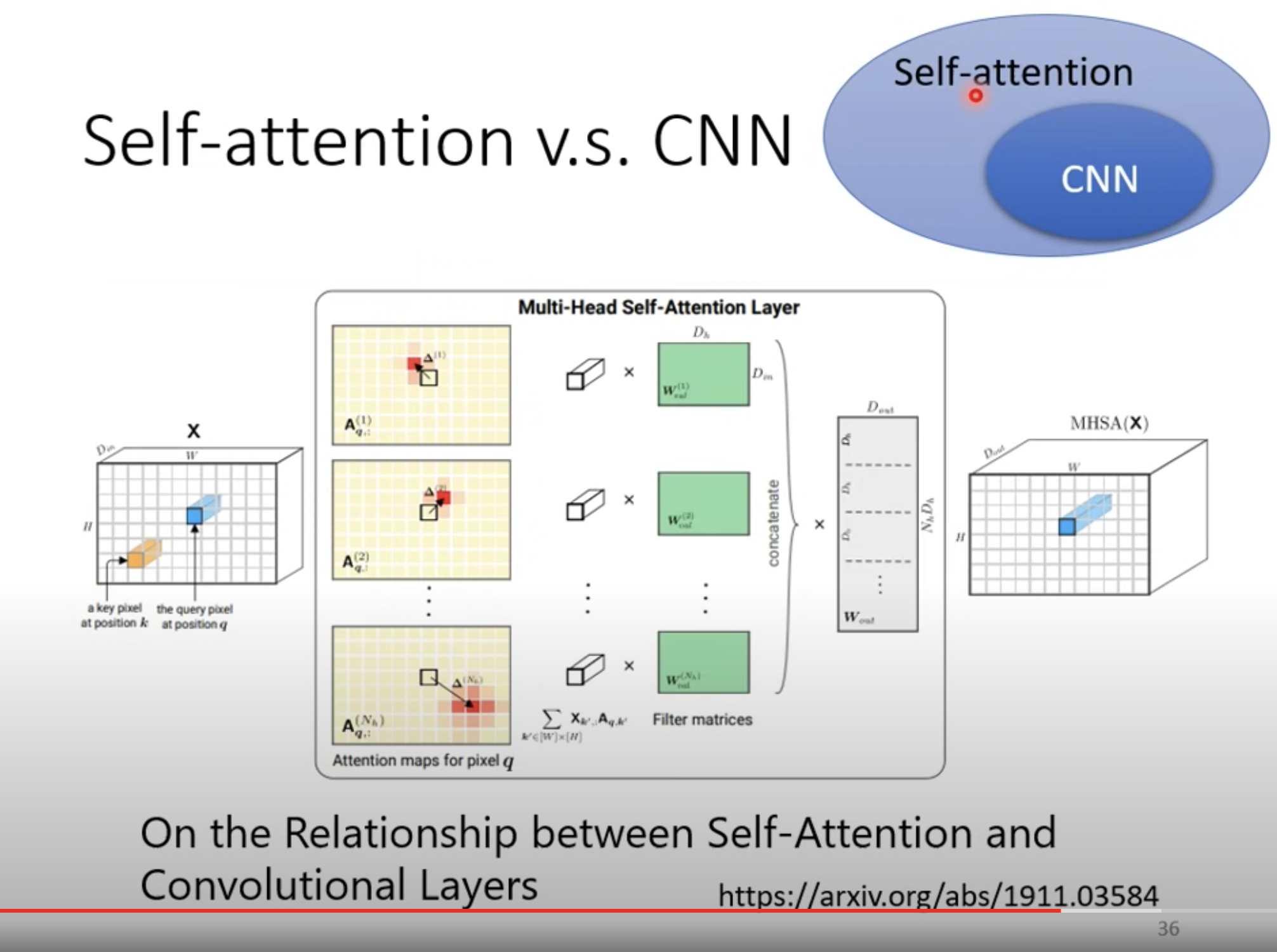
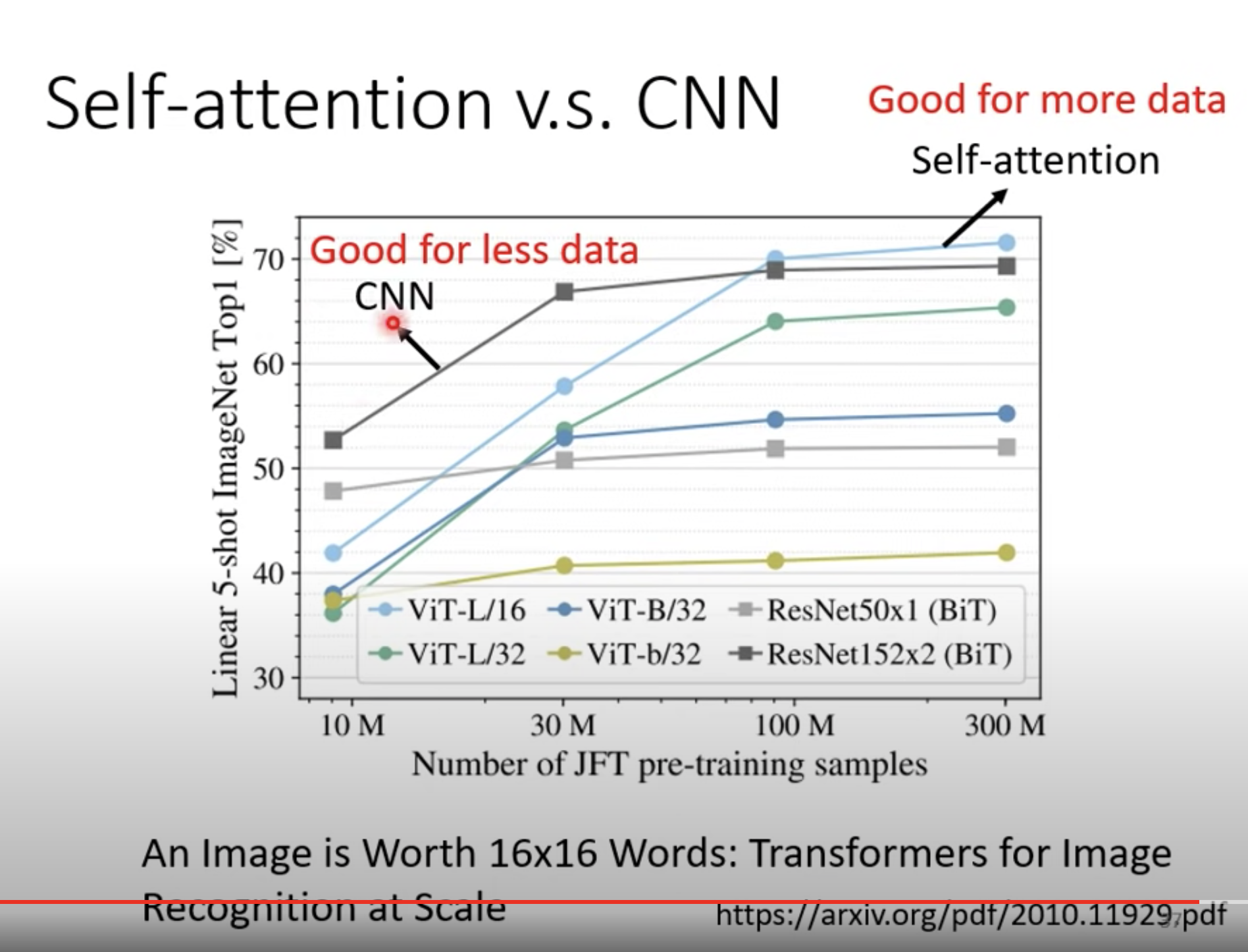
self- attention弹性比较大,在训练资料比较少的时候,会 over fitting。
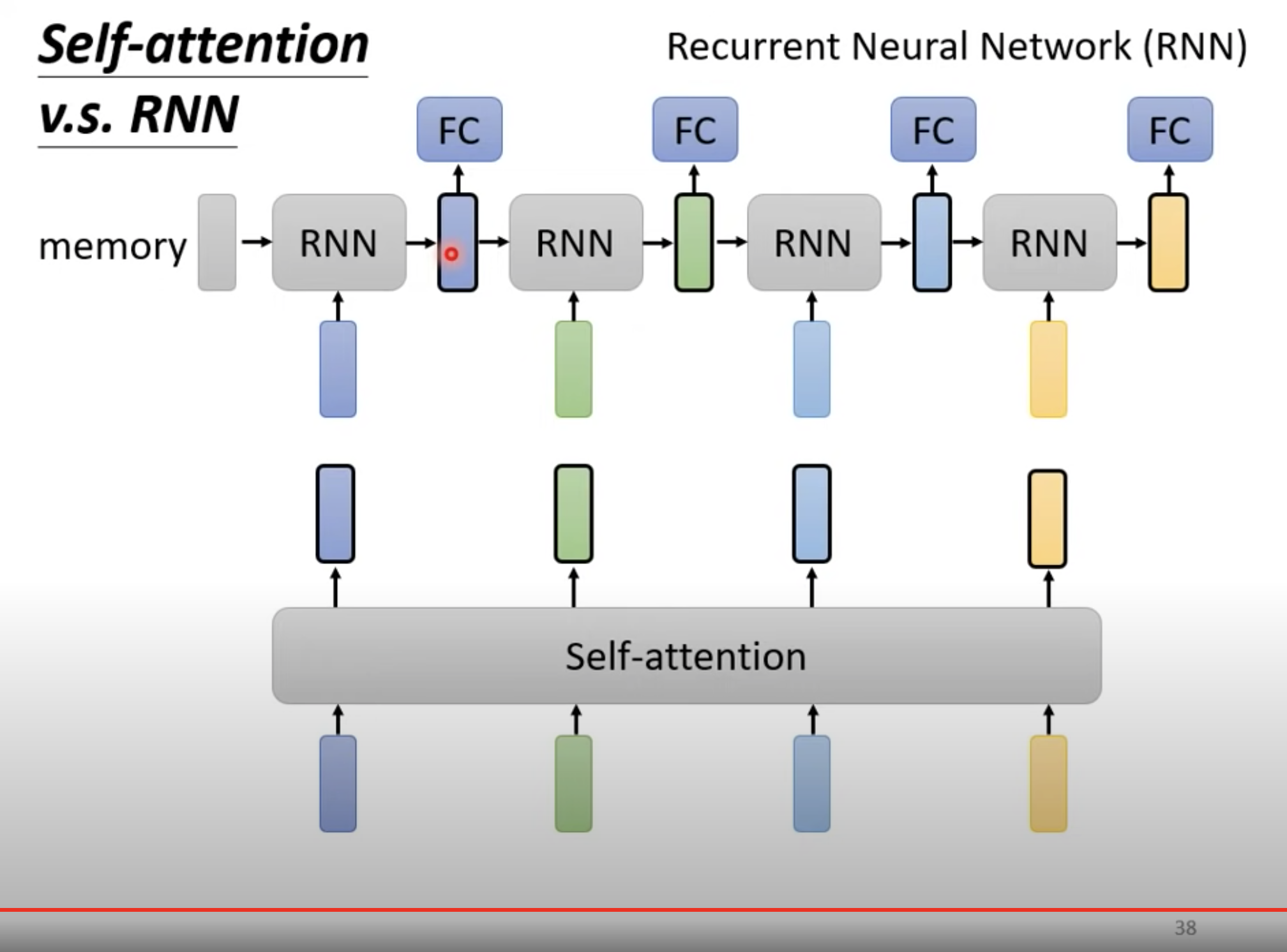
上图的RNN是一个单向的 RNN,只考虑了左边的 sequence。当然现在也有双向的 RNN。
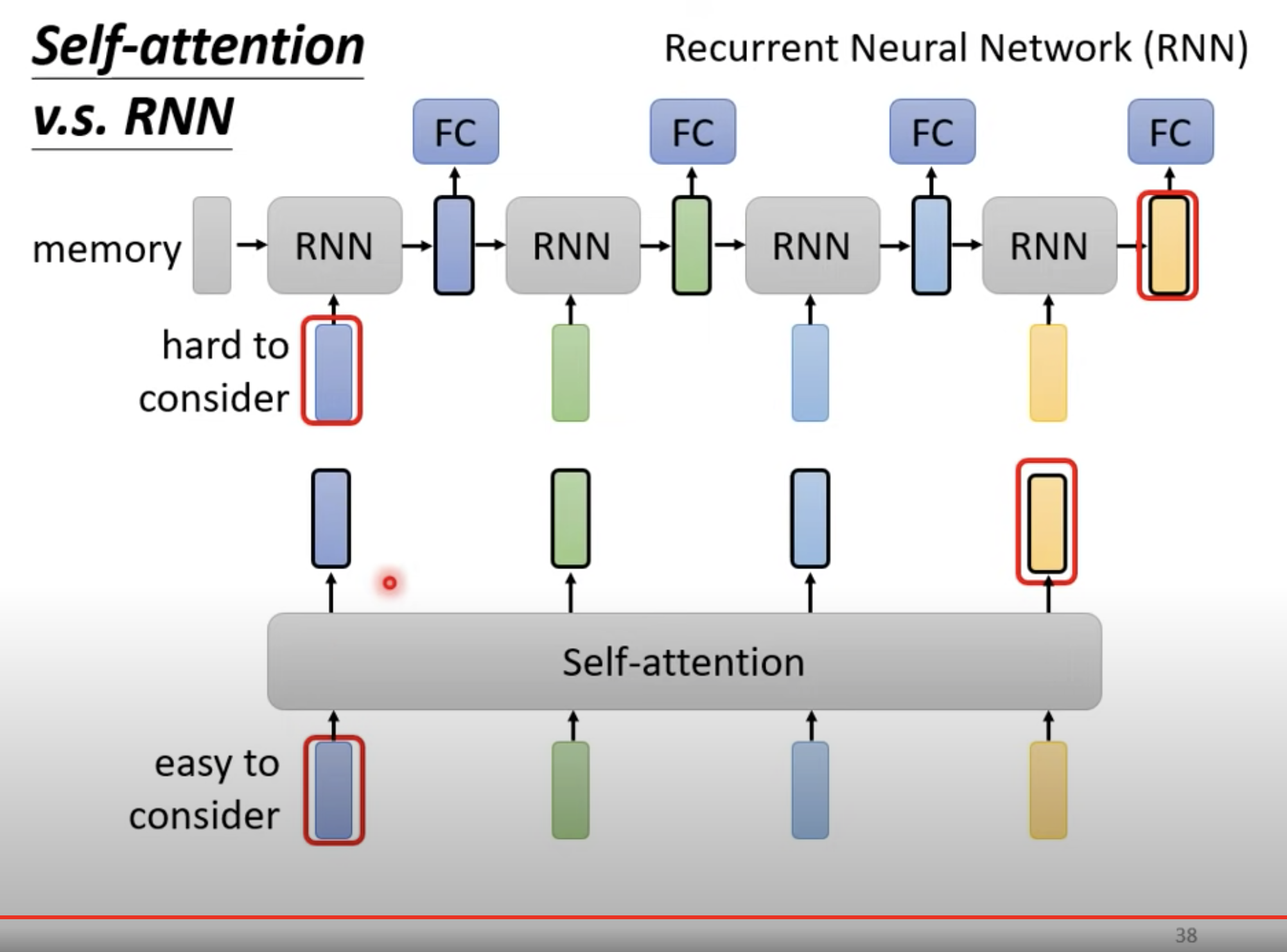
但 RNN 在距离较远的时候,是比较难以考虑彼此的信息的。以上图为例,因为你需要把左边蓝色的ouput一路带到右边,交给黄色处理。
而 self-attention ,是没有考虑位置信息的,天涯若比邻。
还有,RNN 无法并行计算,但 self- attention 可以。
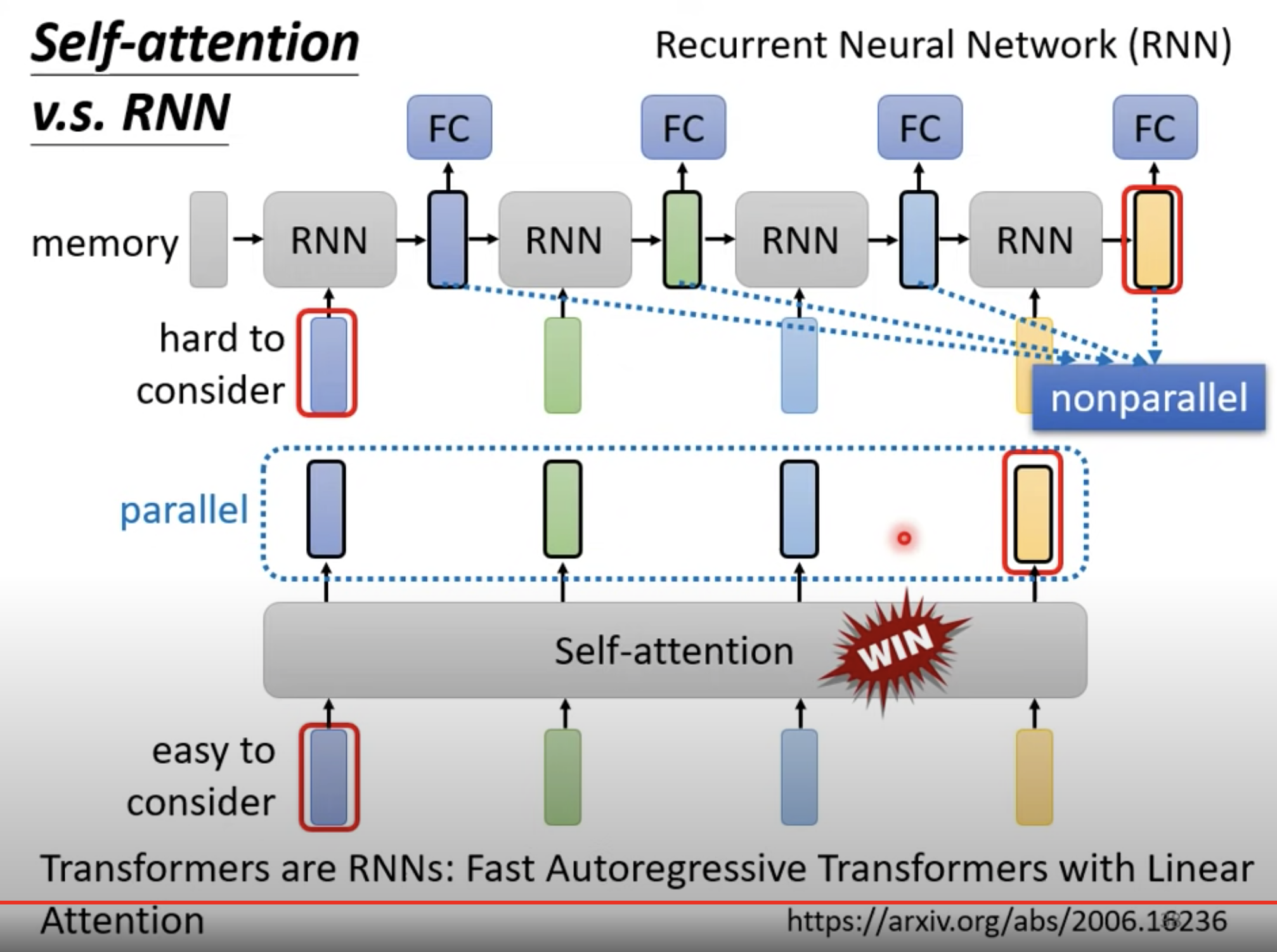
因此,许多基于 RNN 的架构,都在逐渐改成 self- attention。
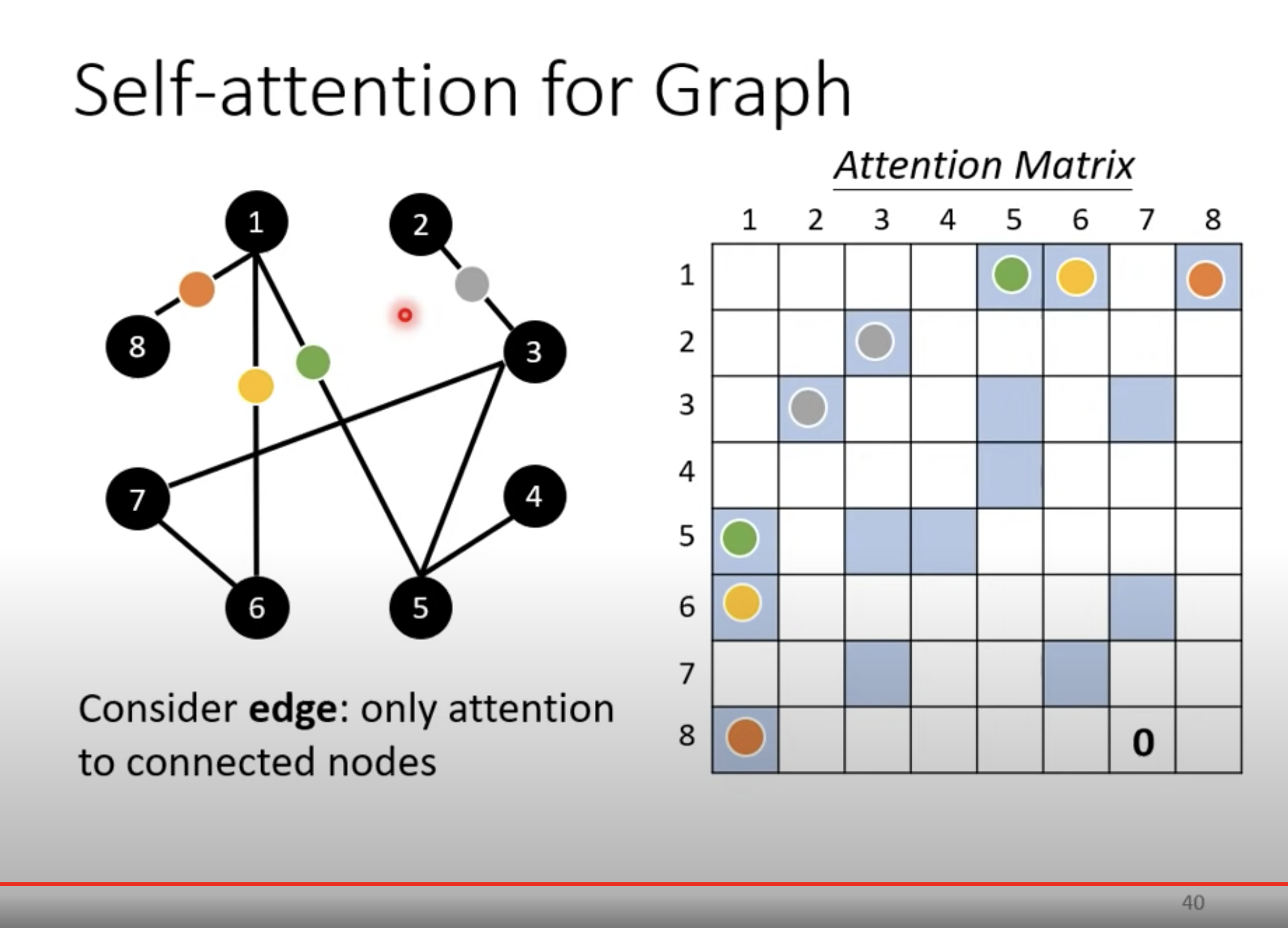
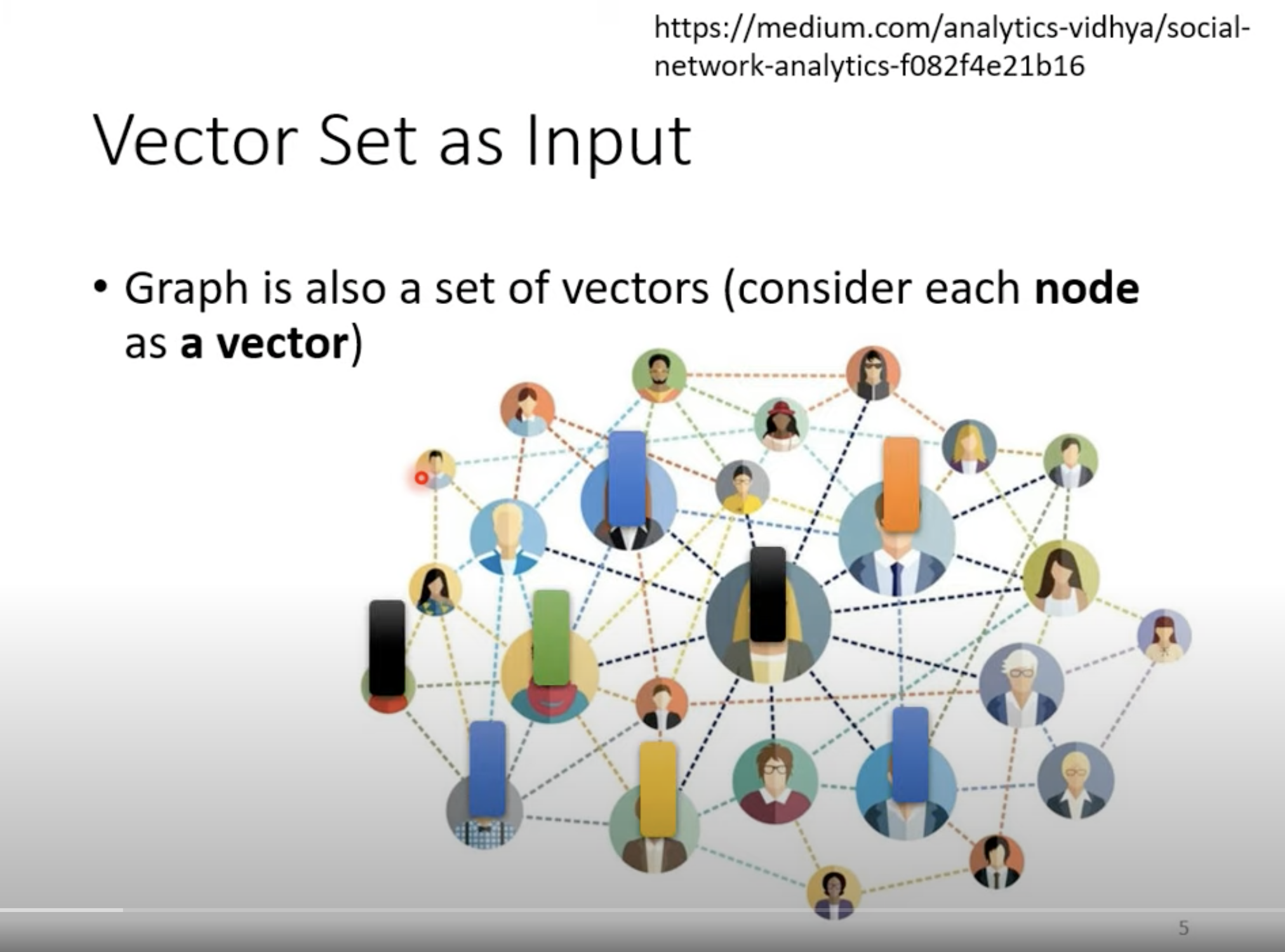
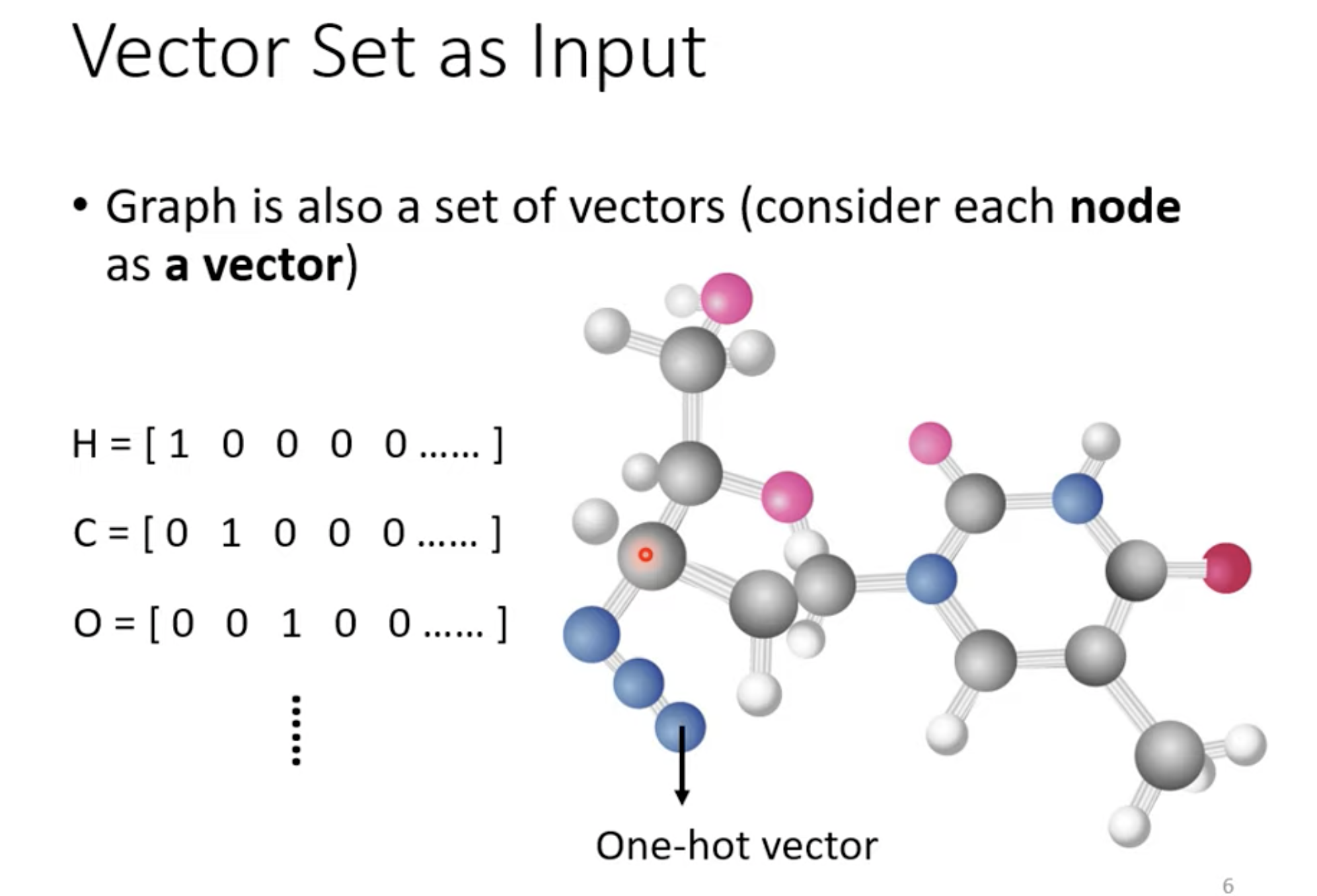
图也可以看做是一个 sequence。比如上图可以是由domain knowledge 生成的,如果两个点之间没有边,我们就不需要计算它俩之间的 attention,直接标记为 0 即可。
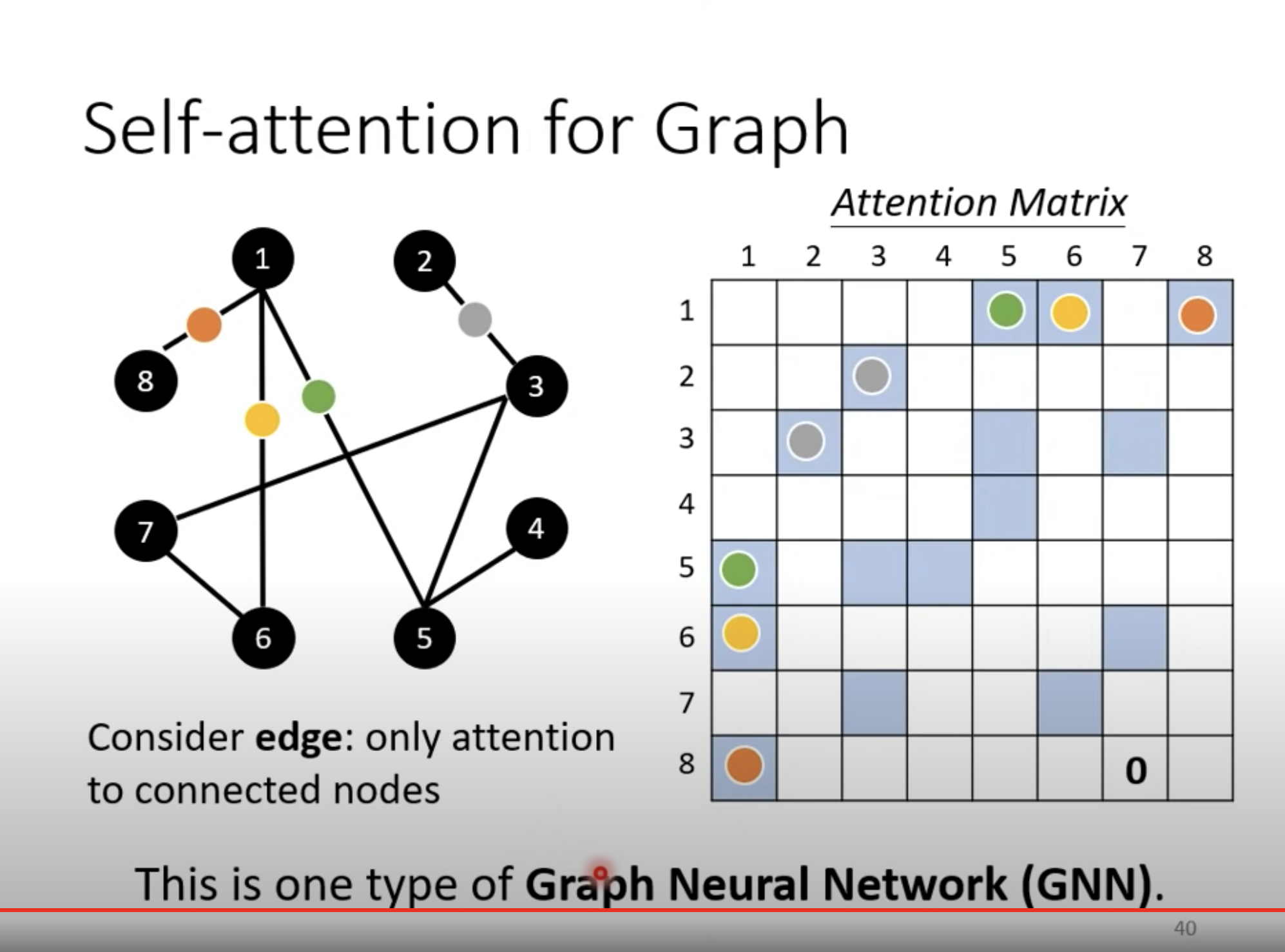
这就是一种 GNN。
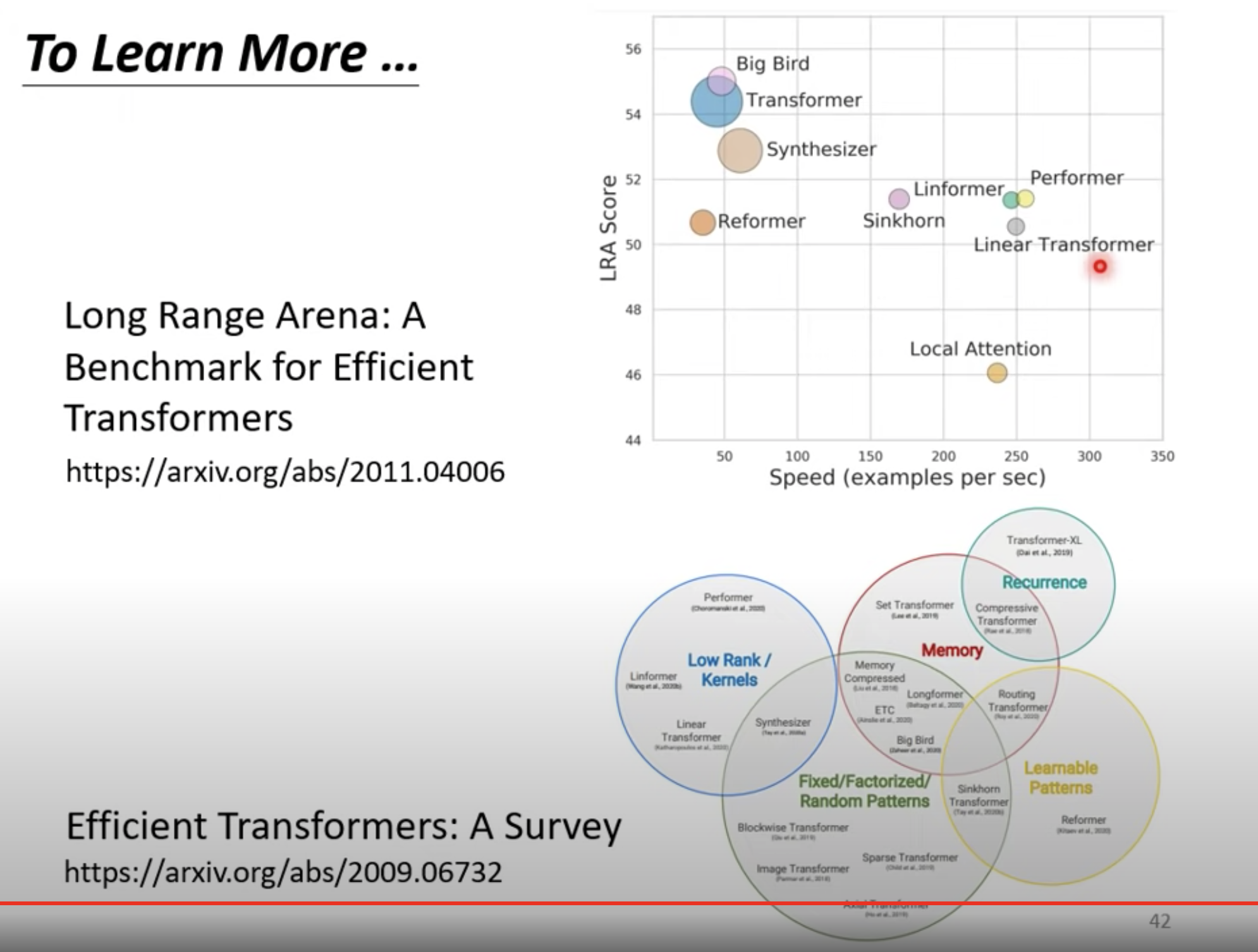
Transformer 也是 self- attention的变形。现在流行的变形普遍叫做 XXformer。

若有收获,就点个赞吧
0 人点赞
