一 MySQL性能
1.1 分析-数据库查询效率低下
我们进入公司进行项目开发往往关注的是业务需求和功能的实现,但是随着项目运行的时间增加,数据量也就增加了,这时会影响到我们数据库的查询性能
硬优化、软优化(重点)
1.2 分析-执行次数比较多的语句
* 查询密集型我们使用查询频率较高,8:2 左右我们就可以使用索引来进行优化* 修改密集型ES
-- 查询累计插入和返回数据条数show global status like 'Innodb_rows%';

1.3 查看-sql语句的执行效率
插入千万条记录
create database day22;use day22;-- 1. 准备表CREATE TABLE `user`(id INT,username VARCHAR(32),`password` VARCHAR(32),sex VARCHAR(6),email VARCHAR(50));-- 2. 创建存储过程,实现批量插入记录DELIMITER $$ -- 声明存储过程的结束符号为$$CREATE PROCEDURE auto_insert()BEGINDECLARE i INT DEFAULT 1;START TRANSACTION; -- 开启事务WHILE(i<=10000000)DOINSERT INTO `user` VALUES(i,CONCAT('jack',i),MD5(i),'male',CONCAT('jack',i,'@itcast.cn'));SET i=i+1;END WHILE;COMMIT; -- 提交END$$ -- 声明结束DELIMITER ; -- 重新声明分号为结束符号-- 3. 查看存储过程SHOW CREATE PROCEDURE auto_insert;-- 4. 调用存储过程CALL auto_insert();
**
慢查询日志
-- 查看慢查询日志开启情况show variables like '%slow_query_log%';-- 查看慢查询时间配置show variables like '%long_query_time%';

开启慢查询日志
set global slow_query_log = on;
设置慢查询sql的时间阈值
-- 全局配置(下次生效...)set global long_query_time=3;-- 临时(会话)配置(本次会话窗口生效)set session long_query_time=3;

测试慢查询日志

慢查询日志文件分析

二 MySQL索引
2.1 什么是索引
将数据进行排序整理的过程就称为索引
我们根据索引去查,提高效率

2.2 MySQL索引分类
* 主键(约束)索引主键约束+提高查询效率* 唯一(约束)索引唯一约束+提高查询效率* 普通索引仅提高查询效率* 组合(联合)索引多个字段组成索引* 全文索引solr、es* hash索引根据key-value 效率非常高
2.3 MySQL索引语法
2.3.1 创建索引
① 直接创建【了解】
-- 创建普通索引create index 索引名 on 表名(字段);-- 创建唯一索引create unique index 索引名 on 表名(字段);-- 创建普通组合索引create index 索引名 on 表名(字段1,字段2);-- 创建唯一组合索引create unique index 索引名 on 表名(字段1,字段2);
-- 创建学生表CREATE TABLE student(id INT,`name` VARCHAR(32),telephone VARCHAR(11));-- name字段适合设置什么索引?CREATE INDEX name_idx ON student(`name`);-- telephone适合设置什么索引?CREATE UNIQUE INDEX telephone_uni_idx ON student(telephone);
② 修改表时指定【了解】
-- 添加一个主键,这意味着索引值必须是唯一的,且不能为NULLalter table 表名 add primary key(字段); --默认索引名:primary-- 添加唯一索引(除了NULL外,NULL可能会出现多次)alter table 表名 add unique(字段); -- 默认索引名:字段名-- 添加普通索引,索引值可以出现多次。alter table 表名 add index(字段); -- 默认索引名:字段名
-- 指定id为主键索引ALTER TABLE student ADD PRIMARY KEY(id);-- 指定name为普通索引ALTER TABLE student ADD INDEX(`name`);-- 指定telephone为唯一索引ALTER TABLE student ADD UNIQUE(telephone);
③ 创建表时指定【掌握】
-- 创建教师表CREATE TABLE teacher(id INT PRIMARY KEY AUTO_INCREMENT, -- 主键索引`name` VARCHAR(32),telephone VARCHAR(11) UNIQUE, -- 唯一索引sex VARCHAR(5),birthday DATE,INDEX(`name`) -- 普通索引);
2.3.2 删除索引
-- 直接删除drop index 索引名 on 表名;-- 修改表时删除 【掌握】alter table 表名 drop index 索引名;
-- 删除name普通索引DROP INDEX name_idx ON student;-- 删除telephone唯一索引ALTER TABLE student DROP INDEX telephone_uni_idx;
2.4 千万表记录索引效果演示
先来测试没有索引情况下查询
-- 1.指定id查询select * from user where id = 8888888;-- 2.指定username精准查询select * from user where username = 'jack1234567';-- 3.指定email模糊查询select * from user where email like 'jack1234567%';

给这三个字段添加索引
-- 指定id为主键索引ALTER TABLE USER ADD PRIMARY KEY(id);-- 指定username为普通索引ALTER TABLE USER ADD INDEX(username);-- 指定email为唯一索引ALTER TABLE USER ADD UNIQUE(email);
再测试有索引情况下查询
-- 1.指定id查询select * from user where id = 8888888;-- 2.指定username精准查询select * from user where username = 'jack1234567';-- 3.指定email模糊查询select * from user where email like 'jack1234567%';

2.5 索引的优缺点
* 优点减少磁盘IO,提高查询效率* 缺点索引占用磁盘空间我们在进行增删改时,索引的维护会增加成本,可能会降低服务器性能
2.6 索引创建原则
1. 字段内容可识别度不能低于70%2. 经常使用where条件搜索的字段3. 经常使用表连接的字段(内连接、外连接)4. 经常排序的字段 order by* 注意:索引本身会占用磁盘空间,不是所有的字段都适合增加索引....
2.7 常见索引失效情况
-- 1.使用like模糊匹配,%通配符在最左侧使用时select * from user where email like '%jack1234567%';
-- 2.尽量避免使用or,如果条件有一个没有索引,那么会进行全表扫描select * from user where id = 88 or sex = 'male';
-- 3.在索引列上进行计算select * from user where id+1 = 88;
-- 4.使用 !=、 not in、is not null时select * from user where username != 'jack12';
2.8 索引的数据结构【了解】
2.8.1 概述
我们知道索引是帮助MySQL高效获取排好序的数据结构。
为什么使用索引后查询效率提高很多呢?接下来我们来了解下。

在没有索引的情况下我们执行一条sql语句,那么是表进行全局遍历,磁盘寻址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。
select * from user where col1=6;
为了加快的查找效率,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
select * from user where col2=89;
2.8.2 索引的数据结构
- 二叉树:左边的子节点比父节点小,右边的子节点比父节点大

- 红黑树:平衡二叉树(左旋、右旋)

- BTree:多路平衡搜索树
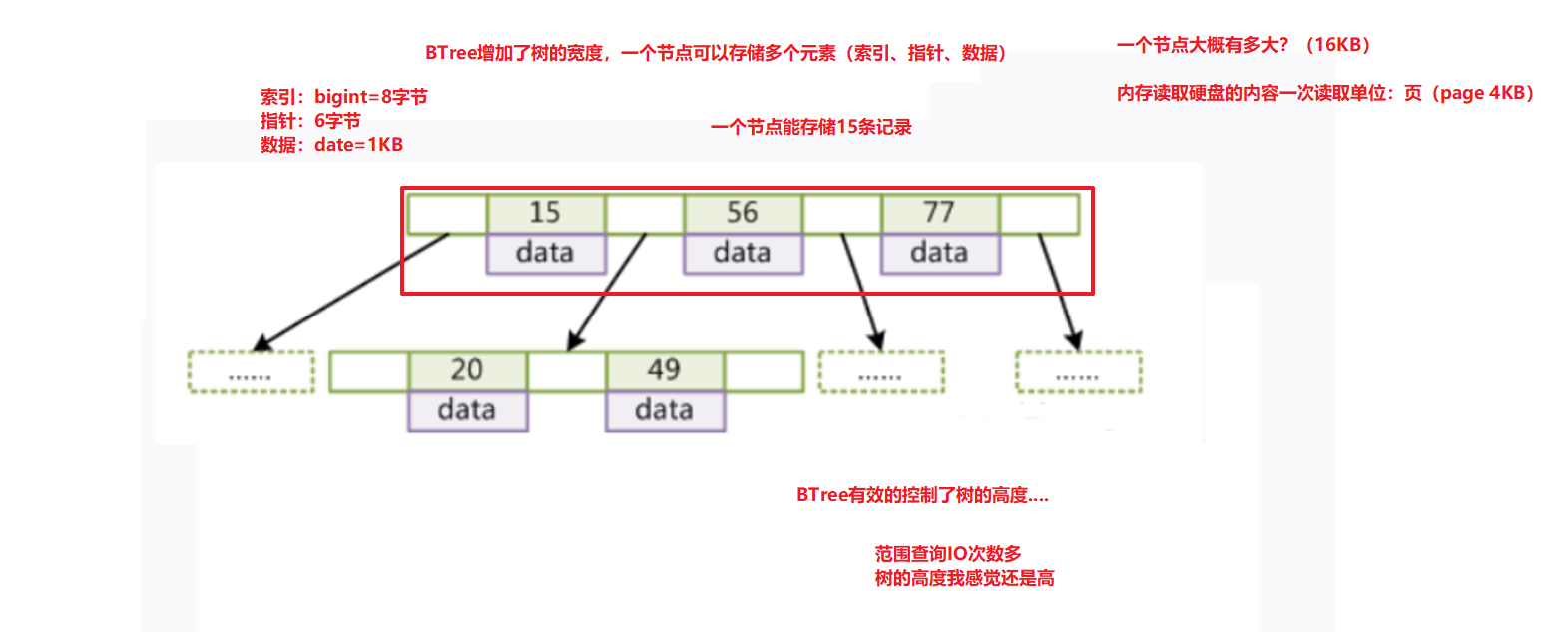
B+Tree:优化BTree(非叶子节点:索引+指针、叶子节点:索引+数据【地址】)

它可以做到减少树的高度(深度)/支持范围查询/支持排序
- Hash:通过散列算法,不支持范围查询(hash是无序的)
数据结构学习网站
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
2.8.3 MySQL中的B+Tree
-- 查看mysql索引节点大小show global status like 'innodb_page_size';
MySQL中的 B+Tree 索引结构示意图:
2.9 数据库的存储引擎
MySQL存储引擎的不同,那么索引文件保存的方式也有所不同,常见的有二种存储引擎MyISAM和InnoDB。
2.9.1 MyISAM(非聚集索引)
MySQL5.5版本之前默认存储引擎
特点:不支持事务、不支持外键约束
CREATE DATABASE day22_pro;USE day22_pro;-- 创建 myisam存储引擎表CREATE TABLE tab_myisam(id INT,`name` VARCHAR(32))ENGINE=MYISAM;

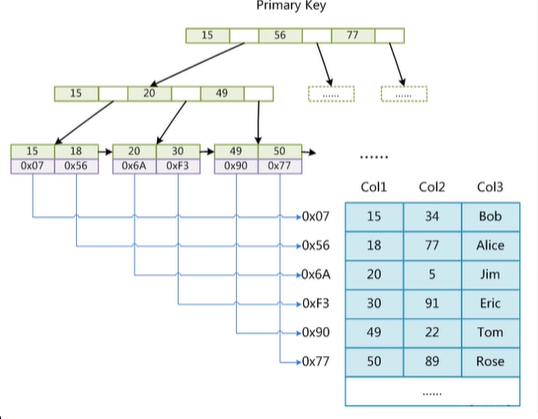
2.9.2 InnoDB(聚集索引)
MySQL5.5版本之后默认存储引擎
特点:支持事务、支持外键约束
-- 创建 innodb存储引擎表CREATE TABLE tab_innodb(id INT,`name` VARCHAR(32))ENGINE = INNODB;


innodb存储引擎必须要设置主键(整型),且自增类型….

若有收获,就点个赞吧
0 人点赞
