安装elasticsearch
1. 下载
(同一安装包可以在windows下使用,也可在linux下使用)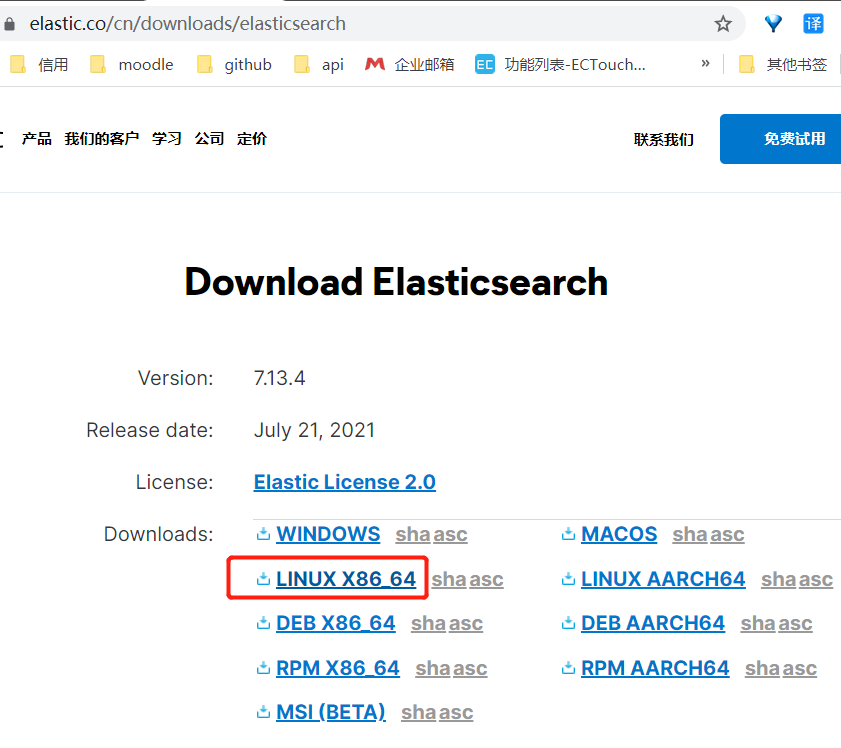
2. 新建elasticsearch用户
必须是普通用户,不能是root用户!!!
(否则,报错:java.lang.RunTimeException:can not run elasticsearch as root)
useradd新用户名 —新建用户
passwd用户名 —设置密码
su -l用户名 —切换用户
3. 解压:
tar -zxvf elasticsearch-7.13.4-linux-x86_64.tar.gz -C /usr/local/elastic/
修改文件权限:
chown -R elasticsearch:elasticsearch elasticsearch-7.13.4
4. 配置文件
# ======================== Elasticsearch Configuration =========================## NOTE: Elasticsearch comes with reasonable defaults for most settings.# Before you set out to tweak and tune the configuration, make sure you# understand what are you trying to accomplish and the consequences.## The primary way of configuring a node is via this file. This template lists# the most important settings you may want to configure for a production cluster.## Please consult the documentation for further information on configuration options:# https://www.elastic.co/guide/en/elasticsearch/reference/index.html## ---------------------------------- Cluster -----------------------------------## Use a descriptive name for your cluster:## 配置es的集群名称,默认是elasticsearch# es会自动发现在同一网段下的es,如果在同一网段下有多个集群,可用此属性来区分不同的集群。cluster.name: my-application## ------------------------------------ Node ------------------------------------## Use a descriptive name for the node:## 节点名node.name: node-1## Add custom attributes to the node:##node.attr.rack: r1##指定该节点是否有资格被选举成为master,默认是true,# es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。#node.master: true##指定该节点是否存储索引数据,默认为true。#node.data: true# ----------------------------------- Paths ------------------------------------##path.conf: /path/to/conf# 设置配置文件的存储路径,默认是es根目录下的config文件夹。#path.data: /path/to/data# 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例:path.data: /path/to/data1,/path/to/data2#path.work: /path/to/work# 设置临时文件的存储路径,默认是es根目录下的work文件夹。#path.logs: /path/to/logs# 设置日志文件的存储路径,默认是es根目录下的logs文件夹#path.plugins: /path/to/plugins# 设置插件的存放路径,默认是es根目录下的plugins文件夹## ----------------------------------- Memory -----------------------------------## Lock the memory on startup:##bootstrap.memory_lock: true## Make sure that the heap size is set to about half the memory available# on the system and that the owner of the process is allowed to use this# limit.## Elasticsearch performs poorly when the system is swapping the memory.## ---------------------------------- Network -----------------------------------## Set the bind address to a specific IP (IPv4 or IPv6):#network.host: 0.0.0.0## Set a custom port for HTTP:##http.port: 9200##使head插件可以访问eshttp.cors.enabled: truehttp.cors.allow-origin: "*"transport.host: 0.0.0.0#transport.tcp.port: 9201# ########### ########### ########### ########### ########### ############network.bind_host: 192.168.0.1# 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。#network.publish_host: 192.168.0.1# 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。#network.host: 192.168.0.1# 这个参数是用来同时设置bind_host和publish_host上面两个参数。#transport.tcp.port: 9300# 设置节点间交互的tcp端口,默认是9300。#transport.tcp.compress: true# 设置是否压缩tcp传输时的数据,默认为false,不压缩。#http.port: 9200# 设置对外服务的http端口,默认为9200。#http.max_content_length: 100mb# 设置内容的最大容量,默认100mb#http.enabled: false# 是否使用http协议对外提供服务,默认为true,开启。### For more information, consult the network module documentation.## --------------------------------- Discovery ----------------------------------## Pass an initial list of hosts to perform discovery when new node is started:# The default list of hosts is ["127.0.0.1", "[::1]"]##discovery.zen.ping.unicast.hosts: ["host1", "host2"]## Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):##discovery.zen.minimum_master_nodes:#discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"]# 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。#discovery.zen.minimum_master_nodes: 1# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)#discovery.zen.ping.timeout: 3s# 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。#discovery.zen.ping.multicast.enabled: false# 设置是否打开多播发现节点,默认是true。## For more information, consult the zen discovery module documentation.## ---------------------------------- Gateway -----------------------------------## Block initial recovery after a full cluster restart until N nodes are started:##gateway.recover_after_nodes: 3##gateway.type: local# gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,Hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说。#gateway.recover_after_nodes: 1# 设置集群中N个节点启动时进行数据恢复,默认为1。#gateway.recover_after_time: 5m# 设置初始化数据恢复进程的超时时间,默认是5分钟。#gateway.expected_nodes: 2# 设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。# For more information, consult the gateway module documentation.## ---------------------------------- Various -----------------------------------## Require explicit names when deleting indices:##action.destructive_requires_name: true#index.number_of_shards: 5# 设置默认索引分片个数,默认为5片。#index.number_of_replicas: 1# 设置默认索引副本个数,默认为1个副本。##cluster.routing.allocation.node_initial_primaries_recoveries: 4# 初始化数据恢复时,并发恢复线程的个数,默认为4。##cluster.routing.allocation.node_concurrent_recoveries: 2# 添加删除节点或负载均衡时并发恢复线程的个数,默认为4。##indices.recovery.max_size_per_sec: 0# 设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。##indices.recovery.concurrent_streams: 5# 设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。
5. 运行
切换用户:
su elasticsearch
运行:
sh /usr/local/elastic/elasticsearch-7.13.4/bin/elasticsearch -d
(-d:以后台进程方式启动es)
通过jps命令,可看到进程名为Elasticsearch
测试连接:
curl -XGET ‘http://127.0.0.1:9200‘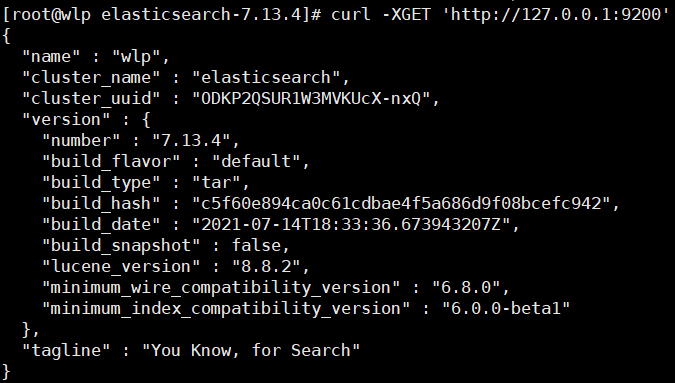
启动出错处理方法
错误[1]、[2],以下方式解决:
修改 /etc/security/limits.conf配置文件,添加如下内容(注意*和空格):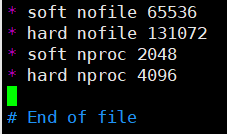
修改后退出(exit)重新登陆,查看配置是否生效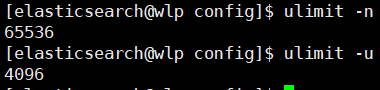
错误[3],以下方式解决:
修改/etc/sysctl.conf配置文件,添加如下内容:
执行 sysctl -p
错误[4],以下方式解决:
elasticsearch.yml中添加配置项:
cluster.initial_master_nodes: [“node-1”] #这里的node-1为node-name配置的值
错误[system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk],方式解决:
elasticsearch.yml中添加配置项:bootstrap.system_call_filter为false:
# —————————————————- Memory —————————————————-
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
出现错误的原因:是因为当前操作系统不支持SecComp,而elasticsearch默认bootstrap.system_call_filter为true进行检测,所以导致检测失败,导致ES不能启动
安装kibana
1. 解压
tar -zxvf kibana-7.13.4-linux-x86_64.tar.gz -C /usr/local/elastic/
修改文件权限:
chown -R elasticsearch:elasticsearch kibana-7.13.4-linux-x86_64
2. 修改配置文件
kibana-7.13.4-linux-x86_64 /config/kibana.yml
# 设置kibana端口server.port: 5601# 设置kubana IPserver.host: "192.168.1.14"# 设置kibana要连接的es地址elasticsearch.hosts: ["http://192.168.1.14:9200"]# 设置kibana为中文i18n.locale: "zh-CN"
3. 启动(非root账户)
前台启动
sh /kibana-7.13.4-linux-x86_64/bin/kibana
# 后台启动
sh /kibana-7.13.4-linux-x86_64/bin/kibana &
安装ik分词插件
- 停止es服务
jps |grep Elasticsearch|awk {‘print $1’}|xargs kill
- 确认es服务已停止,使用jps找不到Elsaticsearch进程则说明正确停止
jps |grep Elasticsearch
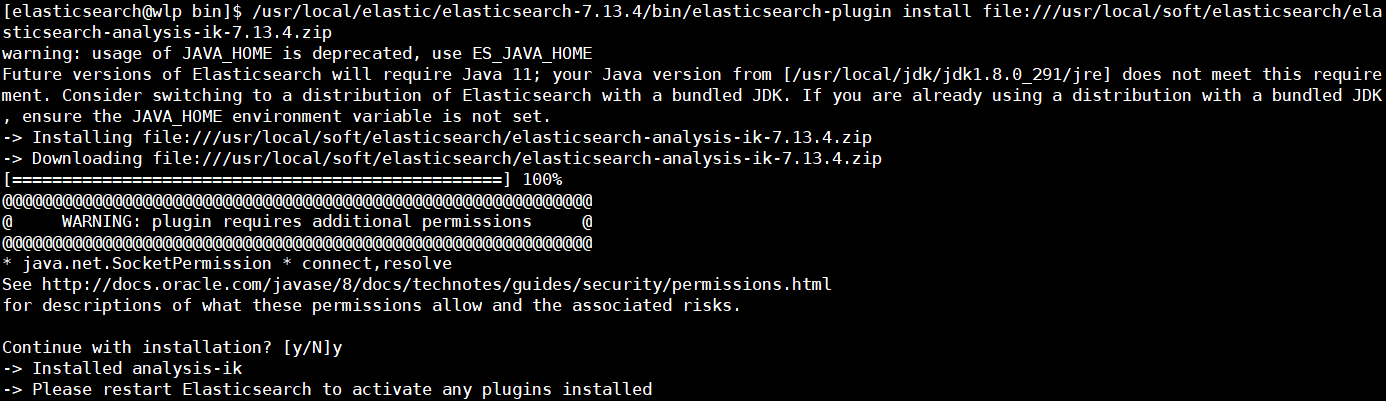
- 插件安装,执行以下命令进行安装,在提示时输入y,然后回车
/usr/local/elastic/elasticsearch-7.13.4/bin/elasticsearch-plugin install file:///usr/local/soft/elasticsearch/elasticsearch-analysis-ik-7.13.4.zip
查看已安装插件
/usr/local/elastic/elasticsearch-7.13.4/bin/elasticsearch-plugin list
使用:
本地词库:使用 ~/elasticsearch-7.13.4/config/analysis-ik/ 目录下的文件作为词典
本地词库配置:
# 创建一个自定义扩展词文
touch my_extra.dic
# 创建一个停用词文件
touch my_stopword.dic
# 编辑ik分词器配置文件
vim IKAnalyzer.cfg.xml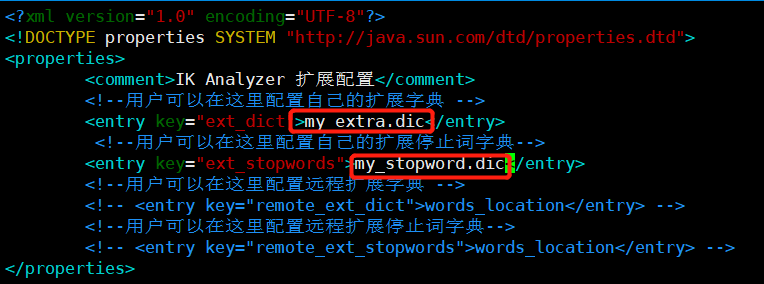
参考:
https://blog.csdn.net/huanqingdong/article/details/100186698
https://blog.csdn.net/huanqingdong/article/details/100412816

若有收获,就点个赞吧
0 人点赞
