day3
爬取指定url中所有图片:
在指定url右键—>检查元素—>network—>XHR—>name(左侧文件会随页面向下拉去显示更多)—>headers抓取cookie、user-agent及当前图片页面的url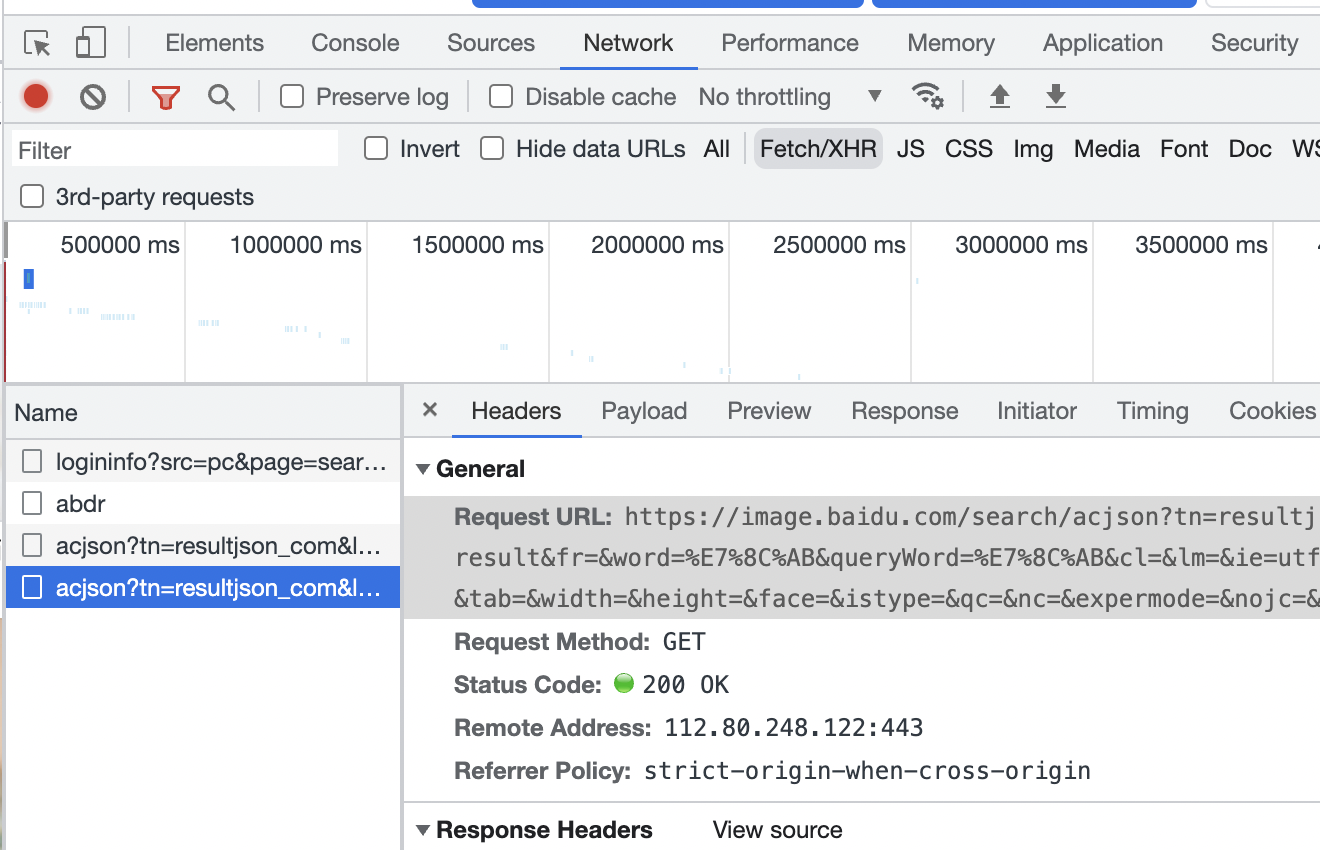
在指定url的XHR中找下一级url并进行相同的身份伪造操作
源码:
import requests,jsonfrom faker import Fakerfrom urllib import requestfake = Faker(locale = 'zh_CN')headers = {"Cookie":'''BDqhfp=%E7%8C%AB%26%26NaN%26%260%26%261; BIDUPSID=BB53A6DDC9F7BA5782320D71FFD89911; PSTM=1644676835; BAIDUID=BB53A6DDC9F7BA579591DB130C95E10E:FG=1; __yjs_duid=1_e335e53b7dd5b5505fa8e3dc4fca37bc1644676872577; BDSFRCVID_BFESS=dCLOJeC62GzRBsnD3FI-h_5rWkngKp3TH6aow3oSM89su-fJVgadEG0P5x8g0KCM3_9PogKKymOTHuKF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tb-eoKPhfI03HJRxM-Laq4kVMMjHKD62aKDs0pO1BhcqEIL4Qn6CLRtHQablBCr3XbTH-bv85hv2hUbSj4Qo5Tte0PFOqRJtHCcZ-J3q5p5nhMtG257JDMPdXHbdqlOy523iXR6vQpnhOpQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xb6_0-nDSHHL8q68f3j; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDUSS=0dqOXJ1bzBabnFCQkk5NDJGTHc4ZEFwQ3F3amp1d0NyN3FwcWl2VEtZT0RmREJpRVFBQUFBJCQAAAAAAAAAAAEAAAAt0ZgrcXExMTk1MTQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIPvCGKD7whiV; BDUSS_BFESS=0dqOXJ1bzBabnFCQkk5NDJGTHc4ZEFwQ3F3amp1d0NyN3FwcWl2VEtZT0RmREJpRVFBQUFBJCQAAAAAAAAAAAEAAAAt0ZgrcXExMTk1MTQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIPvCGKD7whiV; BAIDUID_BFESS=B0764AA678B20ED4DD62AA2238FC0959:FG=1; RT="z=1&dm=baidu.com&si=yy8mp011d7&ss=l0ghv5r2&sl=3&tt=1f8&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=2bt&ul=fi7k&hd=fi8u"; H_PS_PSSID=35839_35105_31253_34584_35948_35931_35955_35320_26350_35882_35879_35940; delPer=0; PSINO=2; BA_HECTOR=258g0l810ha081817l1h2d9ps0q; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=www.baidu.com; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; firstShowTip=1; ab_sr=1.0.1_OTNmMGMzNDQzOWFhYWEzMTgzZjBlMjIxMzljYjE1M2U0ZDc2ZjBmMDdkMmI0NzlmNDMzZjM0ZmVhNDY4MjYxYjhmZTJkNmVkYjVmMTM0YjczMzZjYTI5MGZkMThiNjdmZWYyMDg2NjRlZjdlZTUzZjhmY2NiYjE0NWMyNjgxMTE3YzllNmI5NDE2M2JlZjkwZmNhYjRmOWQ1YWJmZmZiZDFkMDgxMTU1NGYwZjNjNDVhMWU3NzliYjA2NmU4YjU3''',"User-Agent":'''Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'''}for page in range(10):url = "https://image.baidu.com/search/acjson?tn=resultjson_com&logid=8219497008628442405&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E7%8C%AB&queryWord=%E7%8C%AB&cl=&lm=&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&expermode=&nojc=&isAsync=&pn={}&rn=30&gsm=3c&1646700946829=".format(page*30)response = requests.get(url,headers=headers) #定义response并赋值为用requests库的get方法取得的url以及headers的参数response.encoding = response.apparent_encoding #设置编码格式,使用更加精准的编码代替以前的编码#print(response.text) #输出response主体的text文本res = response.textjson1 = json.loads(res) #把请求出的字符串 变成字典,方便提取信息try:for i in json1['data']: #for-in循环提取img_url = i['thumbURL']img_name = fake.password(length = 10,special_chars=False)request.urlretrieve(img_url,'./图片url/{}.jpg'.format(img_name))print(img_url)print(img_name)except:pass #try-execpt方法执行报错时处理,pass可用作占位符
其中:
json库 | json.dumps | 将 Python 对象编码成 JSON 字符串 | | —- | —- | | json.loads | 将已编码的 JSON 字符串解码为 Python 对象 |
for-in
- try-except:处理报错

对页面图片张数以及页数的控制:

部分代码:.....&isAsync=&pn={}&rn=30&gsm=3c&1646700946829=".format(page*30)#page*30是因为观察到两页面间相差30
�for page in range(10):
……程序体
json库中loads方法部分:
print(response.text)print(type(response.text)) #此时输出为str类型res = response.textjson1 = json.loads(res)print(type(json1)) #此时输出为dict字典类型
原本提取的response.text为str类型,使用json.loads方法将json字符串解码为python对象,此处解码为dict字典类型
for-in循环遍历部分:
for i in json1['data']: #for-in循环提取img_url = i['thumbURL']img_name = fake.password(length = 10,special_chars=False)request.urlretrieve(img_url,'./图片url/{}.jpg'.format(img_name))print(img_url)print(img_name)
json1中部分代码,其中包含了图片的url,因此可进行遍历提取
"data":[{ "adType":"0", "hasAspData":"0","thumbURL":"https://img0.baidu.com/it/u=2661215205,1705894127&fm=26&fmt=auto","commodityInfo":null, "isCommodity":0,
在输出的json1中可以分析出,可观察到图片的url包含在json1中的data键值对中,所以对json1字典进行for-in遍历提取键为data的值,进一步缩小所提取数据的范围
try-except处理错误部分:
try:for i in json1['data']: #for-in循环提取print(i['thumbURL'])except:pass #try-execpt方法执行报错时处理,pass可用作占位符
在 try 尝试执行时,若出现错误则跳转到except部分,可在except部分自定义对错误的处理,此处使用pass跳过,pass可用作占位使用
提取出当前url中所有图片的信息

图片的下载及format格式匹配函数:
通过urllib中的request:from urllib import requestrequest.urlretrieve('下载地址','下载路径')�
(需提前创建好存放的文件夹)
下载部分:(源码在for-in部分)
- 将图片url存入img_url中
- 使用fake函数对图片名字进行随记命名
- 调用下载函数对其img_url中的图片进行下载,同时用format()函数进行每张图片的命名
format():
使用 { } 进行格式匹配,
例如>>>”{} {}”.format(“hello”, “world”)# 不设置指定位置,按默认顺序’hello world’
faker模块补充:
用来生成随机数据
- 实例化
- 方法调用
例如生成一些人物信息:
from faker import Fakerfake = Faker(locale='zh_CN')#实例化对象并设置中文 默认为en——USfor i in range(10):print(fake.name()," ",fake.job())print(fake.phone_number())print(fake.address())

time()模块:
对程序做延迟处理,以防网站按访问速度判断爬虫并封掉ip
import timeprint("12345")time.sleep(4)print("56789")
(实战1)爬取指定url中的城市名
url = "[https://www.lagou.com/lbs/getAllCitySearchLabels.json"](https://www.lagou.com/lbs/getAllCitySearchLabels.json)
- 先将json格式文件使用json库函数的loads方法转化为dict类型
- 层层爬取 ```python import requests,json
headers = { “Cookie”:’’’JSESSIONID=ABAAAECAAEBABII434323570AA1B7355F8C1D28472A4EDE’’’, “User-Agent”:’’’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36’’’ } url = “https://www.lagou.com/lbs/getAllCitySearchLabels.json“ response = requests.get(url,headers=headers) response.encoding = response.apparent_encoding res =response.text json = json.loads(res)[‘content’][‘data’][‘allCitySearchLabels’] for key,value in json.items(): json1 = value for i in json1: print(i[‘name’])
也可以用```pythonjson1=json.loads(res)content = json1['content']['data']['allCitySearchLabels']for i in content:for city in content[i]:print(city['name'])
(实战2)爬取指定url的标题
url:http://www.fjwomen.org.cn/dqgz/
要注意,源码中的url要用在检查元素—>XHR中找的url
没有cookie则不写
import timeimport requests,jsonheaders = {"User-Agent":'''Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'''}for page in range(1,20):url = "http://www.fjwomen.org.cn/dqgz/api.aspx?act=bindData&PageIndex={}".format(page)print("第{}页:".format(page))response = requests.get(url,headers=headers)response.encoding = response.apparent_encodingres =response.textjson1 = json.loads(res)['rows']for i in json1:print(i["Title"])time.sleep(2)
效果图:

若有收获,就点个赞吧
0 人点赞
