思考
什么是分库分表?
分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中
分表:从单张表拆分成多张表的过程,将数据散落在多张表内
为什么要分库分表?
从性能上看随着单库中的数据量越来越大、数据库的查询QPS越来越高,相应的对数据库的读写所需要的时间也越来越多。数据库的读写性能可能会成为业务发展的瓶颈。对应的,就需要做数据库性能方面的优化。本文中我们只讨论数据库层面的优化,不讨论缓存等应用层优化的手段。
如果数据库查询的QPS过高,就需要考虑拆库,通过分库来分担单个数据库的连接压力。比如,如果查询QPS为3500,假设单库可以支撑1000个连接数的话,那么就可以考虑拆分为4个库,来分散查询压力。如果单标数据量过大,当数据量超过一定量级后,无论是对于数据查询还是数据更新,在经过索引优化等出数据库层面的穿透优化手段之后,还是可能会存在性能问题。这时候就需要换个思路去解决问题,比如:从数据生产源头来解决问题,既然数据量大,那我们就来个分而治之,化整为零。这就产生了分表,把数据按照一定的规则拆分成多张表,来解决单表环境下无法解决的存取性能问题。
从可用性上看单个数据库如果发生意外,很可能会丢失所有的数据。除了传统的Master-Slave,Master-Master等部署层面解决可靠性问题外,我们也可以从数据拆分层面解决此问题。
- 单库部署情况下,如果数据库宕机,那么故障影响就是100%,而且恢复可能耗时很长
- 如果我们拆分成2个库,分别部署在不同的机器上,此时其中一个库宕机,那么故障影响就是50%,还有50%的数据可以继续服务
- 如果我们拆分成4个库,那么故障影响就是25%
当然,我们也不能无限制的拆库,这也是牺牲存储资源来提升性能、可用性的方式,毕竟资源总是有限的。
如何分库分表
| 切分方案 | 解决的问题 |
|---|---|
| 只分库 | 数据库读/写QPS过高,数据库连接数不足 |
| 只分表 | 单表数据量过大,存储性能遇到瓶颈 |
| 既分库又分表 | 连接数不足+数据量过大引起的存储性能瓶颈 |
如何选择切分方案
所有的技术都是为业务服务的,那么我们就先从数据方面回顾一下业务背景
比如,我们这个业务系统是为了解决会员的咨询诉求,通过我们的Xspace客服平台系统来服务会员,目前主要以同步的离线工单数据作为我们的数据源来构建自己的数据。
假设,每一笔离线工单都会产生对应一笔会员的咨询问题,如果:
在线渠道:每天产生3w笔聊天会话,其中50%的的会话会生成一笔离线工单,那么每天可以生成1.5w笔工单
热线渠道:每天产生2.5w通电话,其中80%会产生一笔工单,那么每天可以生成2W笔
离线渠道:离线渠道每天直接生成3W笔
合计共8.5w笔/天,考虑到以后可能继续覆盖的新的业务场景,需要提前预留部分拓展空间,这里我们假设为每天产生8w笔问题单。
分表
除问题单外,还有另外2张常用的业务表,用户操作日志表、用户提交日志的表单数据表。其中,每笔问题单大约会产生8条操作日志,我们预留一部分空间,假设每个问题单平均产生约10条用户操作日志。如果系统使用年限为5年的话,那么问题单数据量大约为 1.46亿,按单表500W来算,则问题单表大约需要29.2张表,我们就按32张表来切分,则操作日志则需要512张表。
分库
分库的时候除了要考虑平时的业务峰值读写QPS外,还需要考虑到诸如双11大促期间可能达到的峰值,根据实际的业务场景问题单的数据查询来源主要来自阿里小蜜首页。因此,可以根据历史QPS、RT等数据评估,假设我们只需要3500数据库的连接数,如果单库可以承担最高1000个数据库连接,那么我们就可以拆分成4个库。
如何对数据进行切分
根据行业惯例,通常按照水平切分、垂直切分两种方式切分。当然,有些复杂业务场景也可能选择两者结合的方式进行切分。
水平切分
这是一种横向按业务纬度切分的方式,比如常见的按会员维度切分,根据一定规则把不同的会员相关的数据散落在不同的库表中。由于我们的业务场景决定都是从会员视角进行数据读写。所以,我们就选择按照水平方式进行数据库切分
垂直切分
垂直切分可以简单的理解为,把一张表的不同字段拆分到不同的表中。
比如:假设有一个小型电商业务,把一个订单相关的商品信息、买卖家信息、支付信息都放在一张大表里。可以考虑通过垂直切分的方式,把商品信息、买家信息、卖家信息、支付信息都单独拆分成独立的表,并通过订单号基本信息关联起来。
也有一种情况,如果一张表有10个字段,其中只有3个字段需要频繁修改,那么就可以考虑把这3个字段拆分成子表。避免在修改这3个数据时,影响到其余7个字段的查询行锁定。
分库分表带来的新问题
分库分表后,如何让数据均匀散落在各个分库分表内
比如,当热点事件出现后,怎么避免热点数据集中存取到某个特定库/表,造成各分库表读写压力不均的问题。
其实,细思之下可以发现这个问题其实跟负载均衡的问题很相似,所以我们可以借鉴下负载均衡的解法来解决问题。
| 负载均衡算法 | 优点 | 缺点 |
|---|---|---|
| 轮询(Round-Robin) 加权轮询(Weighted Round-Robin) |
算法简单、依次轮询 | 适合像网关、反向代理这种请求与服务没有关联的场景;不适合数据库这种请求数据与分库路由绑定的场景 |
| ID取模 | 实现简单,分库路由公式:id%分库数量 | 对业务ID过分依赖,仍然存在不均衡问题。比如:双11压测时,往往创建少量测试用户轮询发起请求,那就会造成压测流量大部分集中在少数分库、分表中,无法实现均匀负载 |
| Hash取模 | 实现简单,分库路由公式:hash(id)%分库数量,比ID取模分布式分布更均匀 | 后期扩容、数据迁移不方便,每次扩容都需要按2的倍数裂变,迁移50%的数据 |
| 一致性Hash | 分布更为均匀,扩容容易,增加分库时,只需要迁移最多1/N的数据,N为分库数量,且不受2的倍数扩容限制 | 实现略复杂,不过相对于提供的优势,这点复杂可以忽略不计 |
我们的选择:基于一致性Hash算法裁剪,相较于一致性Hash算法,我们裁剪后的算法主要区别在以下几点:
Hash环节点数量不同
一致性Hash有2-1个节点,考虑到我们按照buyerId切分,而BuyerId基数就很庞大,整体已经具备一定的均匀度,所以把Hash环的数量降低到4096个
DB索引算法的不同
一致性Hash通过类似hash(DB的IP)%2公式计算DB在Hash环的位置。如果DB数量较少,需要通过增加虚拟节点来解决Hash环偏斜问题,而且DB的位置可能会随着IP的变动而变化。
分库分表环境下,如何解决分库后主键ID的唯一性问题
在单库环境下,我们问题单主表的ID采用MySQL自增的方式。但分库之后如果还继续使用数据库自增的方式就很容易出现主键ID重复问题。对于这种情况,有很多解决方案,比如采用UUID的方式,不过UUID过长,查询性能太差,占用空间也大,而且主键的类型也变长了,也不利于应用平滑迁移。
其实我们可以对ID进行继续拆分,比如对ID进行分段,不同的库表使用不同的ID段,但也会产生新的问题,这个ID段要多长才合适?如果ID段分配完了,那可能会占用第二库的ID段,产生ID不唯一问题。但是如果我们让所有的分库使用的ID段按照等差数列进行分隔,每次ID段用完之后,再按照固定的步长比例递增的话,就可以解决这个问题了。
比如,像下面这样,假设每次分配的ID间隔为1000,也就是步长1000,那么每次分配的ID段起止索引则可以按照下面的公式计算得出:
第X库、第Y次分配的ID段起始索引就是:X 步长 + (Y-1) (库数量 步长) 第X库 、第Y次分配的ID段结束索引就是:X 步长 + (Y-1) (库数量 步长)+(1000-1)
分库分表环境下,事务问题如何解决
由于分布式环境下,一个事务可能跨多个分库,所以处理相对复杂,目前常见的两种解决方案:
使用分布式事务
- 优点:由应用服务器/数据库去管理事务,实现简单
缺点:性能代价较高,尤其是涉及到分库数据量较多时尤为明显。而且,还依赖于一些铁定的应用服务器/数据库提供的分布式事务实现方案
由应用程序+数据库共同控制
原理:大事化小,将多个大事务拆分成可由单个分库处理的小事务,由应用程序去控制这些小事务
- 优点:性能良好,少了一个分布式事务协调处理层
- 缺点:需要从应用程序自身上做事务控制的灵活设计。从业务应用上做处理,应用改造成本高
分库分表后,现有数据如何扩容
升级从库

线上数据库,我们为了保持其高可用,一般都会每台主库配一台从库,读写在主库,然后主从同步到从库。如下,A,B是主库,A0和B0是从库,此时,当需要扩容的时候,我们把A0和B0升级为新的主库节点,如此由2个分库变为4个分库。同时在上层的分片配置,做好映射,规则如下:uid%4=0和uid%4=2的分别指向A和A0,也就是之前指向uid%2=0的数据,分裂为uid%4=0和uid%4=2 uid%4=1和uid%4=3的指向B和B0,也就是之前指向uid%2=1的数据,分裂为uid%4=1和uid%4=3
因为A和A0库的数据相同,B和B0数据相同,所以此时无需做数据迁移即可。只需要变更一下分片配置即可,通过配置中心更新,无需重启。
由于之前uid%2的数据分配在2个库里面,此时分散到4个库中,由于老数据还存在(uid%4=0,还有一半uid%4=2的数据),所以需要对冗余数据做一次清理。
而这个清理,不会影响线上数据的一致性,可是随时随地进行。
处理完成以后,为保证高可用,以及下一步扩容需求。可以为现有的主库再次分配一个从库。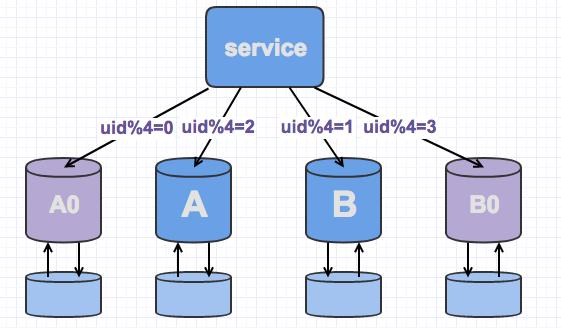
修改分片配置,做好新库和老库的映射。 同步配置,从库升级为主库 解除主从关系 冗余数据清理 为新的数据节点搭建新的从库
双写迁移
双写的方案,更多的是针对线上数据库迁移来用的,当然了,对于分库的扩展来说也是要迁移数据的,因此,也可以来协助分库扩容的问题。
原理和上述相同,做分裂扩容,只是数据的同步方式不同了。
增加新库写链接
双写的核心原理,就是对需要扩容的数据库上,增加新库,并对现有的分片上增加写链接,同时写两份数据。
因为新库的数据为空,所以数据的CRUD对其没有影响,在上层的逻辑层,还是以老库的数据为主。
新老库数据迁移
通过工具,把老库的数据迁移到新库里面,此时可以选择同步分裂后的数据(1/2)来同步,也可以全同步,一般建议全同步,最终做数据校检的时候好处理。
数据校检
按照理想环境情况下,数据迁移之后,因为是双写操作,所以两边的数据是一致的,特别是insert和update,一致性情况很高。但真实环境中会有网络延迟等情况,对于delete情况并不是很理想,比如:A库删除数据a的时候,数据a正在迁移,还没有写入到C库中,此时C库的删除操作已经执行了,C库会多出一条数据。此时就需要做好数据校检了,数据校检可以多做几遍,直到数据几乎一致,尽量以旧库的数据为准。
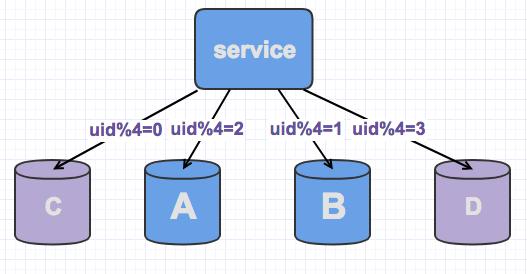
分片配置修改
数据同步完毕,就可以把新库的分片映射重新处理了,还是按照老库分裂的方式来进行
u之前uid%2=0,变为uid%4=0和uid%4=2的 uid%2=1,变为uid%4=1和uid%4=3的。

若有收获,就点个赞吧
0 人点赞
