一、HashTable的原理
Hashtable容器内部是一个由Vector做成的Buckets,其中的每个bucket上都挂着一串类似List结构的链表,这个buckets的size依照经验是用质数来定义(像下图右上方的一些列表值就是给定的size选择)。如何确定哪一个元素应该在哪一个地方呢?hashtable有着自己独特的排序方式(key),以致Key值也是不能修改的,这里的排序方式,按照后面源码中的参数列表中的一个仿函数给出,一般按照取余数的规则,当依据仿函数确定每个元素的顺序值(一般叫做hashCode)后,会除以buckets的size取余确定挂在一个bucket下的链表上。
当然,因为list的结构特点,元素数过多会导致搜索变慢,所以hashtable的特殊之处就体现出来了:
它具有自动Rehash的功能,依照经验,如果某一个Bucket下面挂的List元素数超过了buckets的size,那么buckets就会拓展为另一个size(按照下面的质数表确定),然后重新排序重新按照:hashCode % buckets_size存放元素,这也是hashcode最耗时间的部分。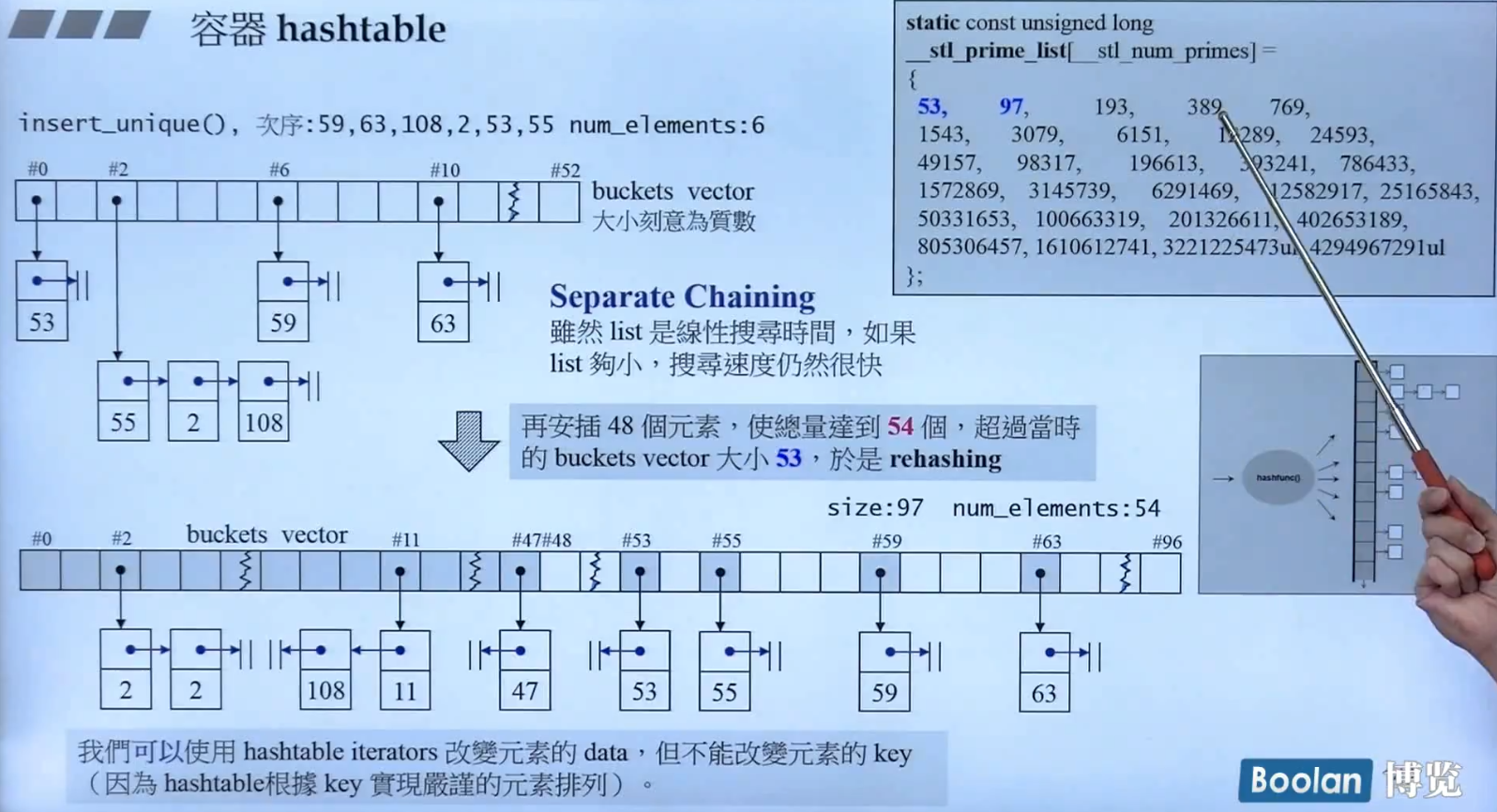
二、hashtable源码
HashTable的源码里面有六个入口参数,分别是键内容与键值、键值、确定元素存放位置的(计算HashCode)的仿函数、取键值的仿函数、确定键值相等的仿函数、分配器(vector用的)。
Hashtable共有五个成员data,前三个是仿函数各占据一个内存单位,后面是主bucket的Vector(本身占3个指针12个单位)和一个unsigned integer占四个单位,一共19个(取整后是20个)。
Hashtable的node结构是右上角所示的单向链表,然后hashtable的迭代器是一个带有两个指针的迭代器,它的实现形式很像deque,就是一个指针指向内部的当前元素,另一个就是指向的整个buckets,用来统筹规划整个vector的扩充。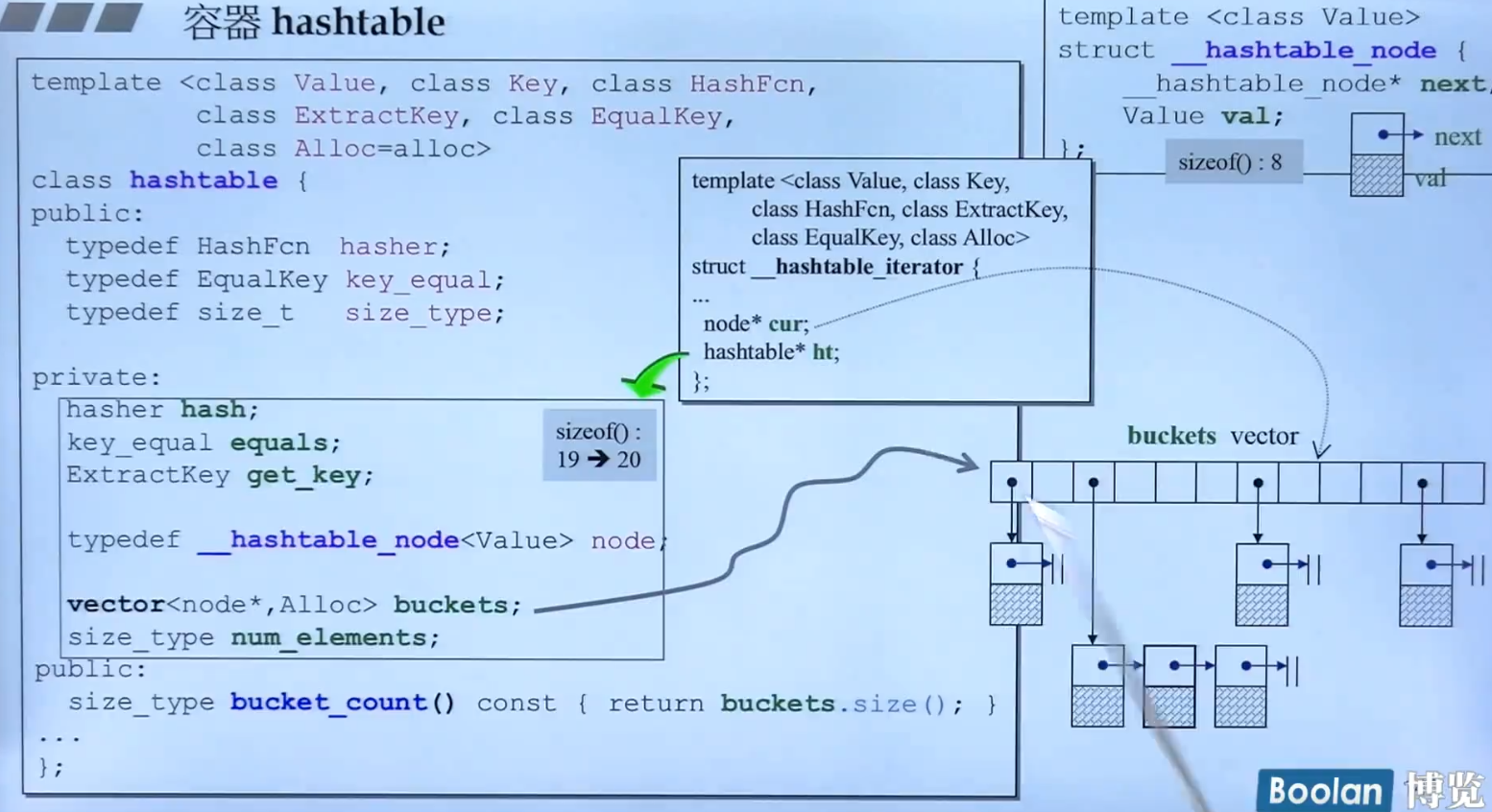
Hashtable实际应用
一般不会去直接使用Hashtable作为容器,但是要清楚里面具体要使用什么才能实现这样一个结构。
重要的三个入口参数一般是指那三个仿函数,一个是equalKay,这个是可以自己写的,但要求返回值只有bool形式,别的不被允许。
比较复杂的一个是hashCode的编码仿函数,这里一般是可以直接调用库里写好的,像下面这个hash
实际是下面实现的几种之一。
比如下面的char*偏特化,可以看到它的编码形式,实际上,这种编码形式毫无数学原理可谈,只是为了搞得尽量混乱(均布化)而写,所以一般一种机构有一种自己的编码方式。
关于取余运算的实现:如下面所示的那样,很多成员函数最终都指向了那一个取余的运算函数。
在C++11及后,hash系列容器更名了。

若有收获,就点个赞吧
0 人点赞
