参考
「Apache Flink 管理大型状态之增量 Checkpoint 详解」
https://ververica.cn/developers/manage-large-state-incremental-checkpoint/
「Apache Flink 官方文档-checkpoint」
https://ci.apache.org/projects/flink/flink-docs-master/zh/ops/state/checkpoints.html
「Apache Flink 官方文档-checkpointing」
https://ci.apache.org/projects/flink/flink-docs-master/zh/dev/stream/state/checkpointing.html
「Flink Checkpoint 问题排查实用指南」
https://ververica.cn/developers/flick-checkpoint-troubleshooting-practical-guide/
「Apache Flink 零基础入门(七):状态管理及容错机制」
https://ververica.cn/developers/state-management/
Flink Checkpoint
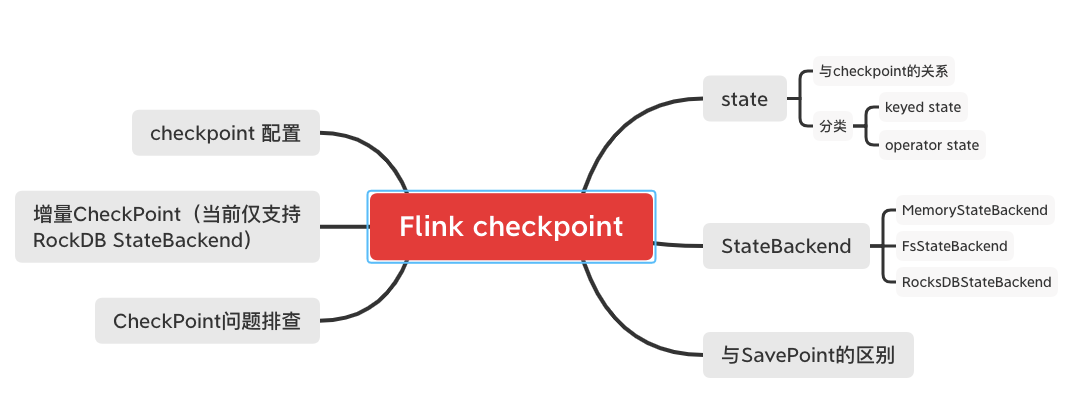
配置Checkpoint
参数说明
enableCheckpointing
是否开启checkpoint,将checkpoint时间间隔作为参数传入,默认为-1,表示不开启
配置方法:environment.enableCheckpointing(_duration);_
👇 checkpointInterval 的默认值为 -1,代表 checkpoint 不开启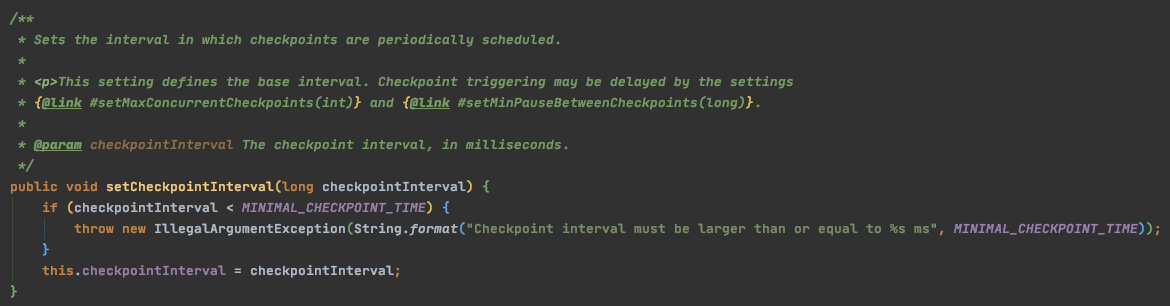
checkpointMode
设置 checkpoint的模式,分为 ATLEAST_ONCE 和 EXACTLY_ONCE,默认使用 _EXACTLY_ONCE
配置方法:environment.getCheckpointConfig().setCheckpointingMode(mode);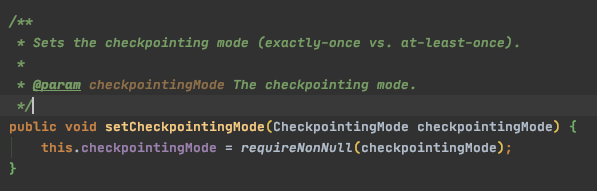
minPauseBetweenCheckpoints
设置 checkpoint 之间的时间,默认值为 0
配置方法:environment.getCheckpointConfig().setMinPauseBetweenCheckpoints(_duration)_;
**
checkpointTimeout
设置 checkpoint 执行时间,如果超过这个时间,那么checkpoint会被抛弃,默认值为10 60 1000(10分钟)
配置方法:environment.getCheckpointConfig().setCheckpointTimeout(_duration)_;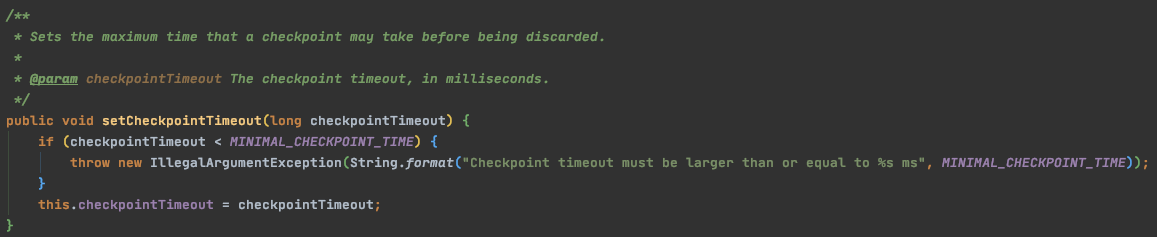
maxConcurrentCheckpoints
设置同一时间有多少 checkpoint 进行,默认值为 1
配置方法:environment.getCheckpointConfig().setMaxConcurrentCheckpoints(_maxConcurrentCheckpoints)_;
preferCheckpointForRecovery
有更近 savepoint 时是否回退到 checkpoint,默认是 false
配置方法:environment.getCheckpointConfig().setPreferCheckpointForRecovery(_preferCheckpointForRecovery)_;
tolerableCheckpointFailureNumber
设置容忍 checkpoint 失败数阀值,默认值是 -1,表示未定义容忍值,会抛出异常,设置为 0,表示对 checkpoint 失败零容忍
配置方法:environment.getCheckpointConfig().setTolerableCheckpointFailureNumber(_tolerableCheckpointFailureNumber)_;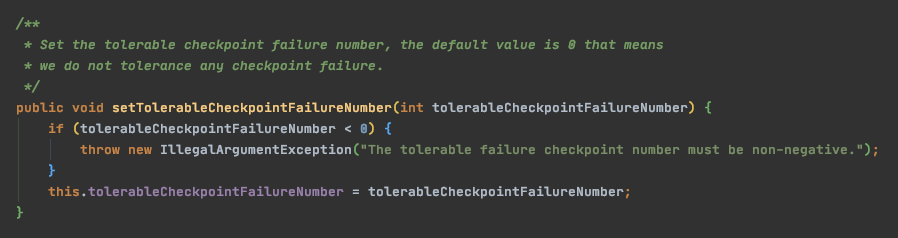
cleanupMode
配置任务结束时 checkpoint 的清理策略,默认程序取消时 checkpoint 不保留,会被删除
配置方法:environment.getCheckpointConfig().enableExternalizedCheckpoints(mode);
说明:
默认程序取消时 checkpoint 不保留,会被删除ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:
当作业取消时,保留作业的 checkpoint。注意,这种情况下,需要手动清除该作业保留的 checkpoint。
ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:
当作业取消时,删除作业的 checkpoint。仅当作业失败时,作业的 checkpoint 才会被保留。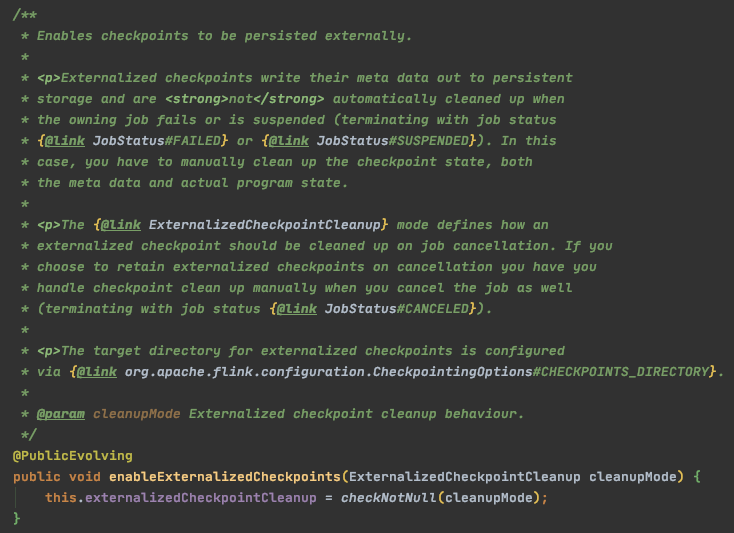
defaultStateBackend
配置状态存储模式,有MemoryStateBackend、FsStateBackend、RocksDBStateBackend 三种可选
配置方法:environment.setStateBackend(_stateBackend)_;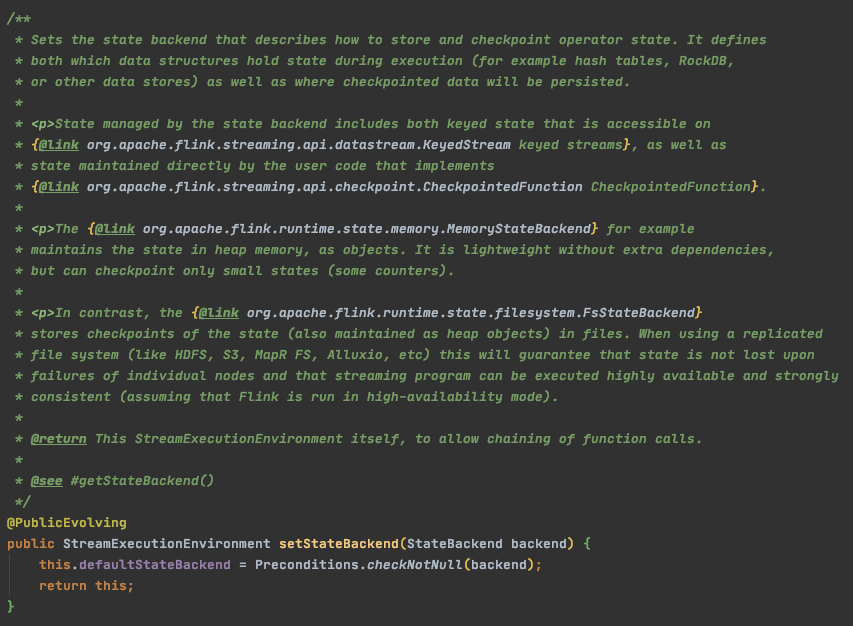
Demo
github地址:https://gitee.com/wtz4680/FlinkApplication/tree/master/flinkDemoCheckpoint
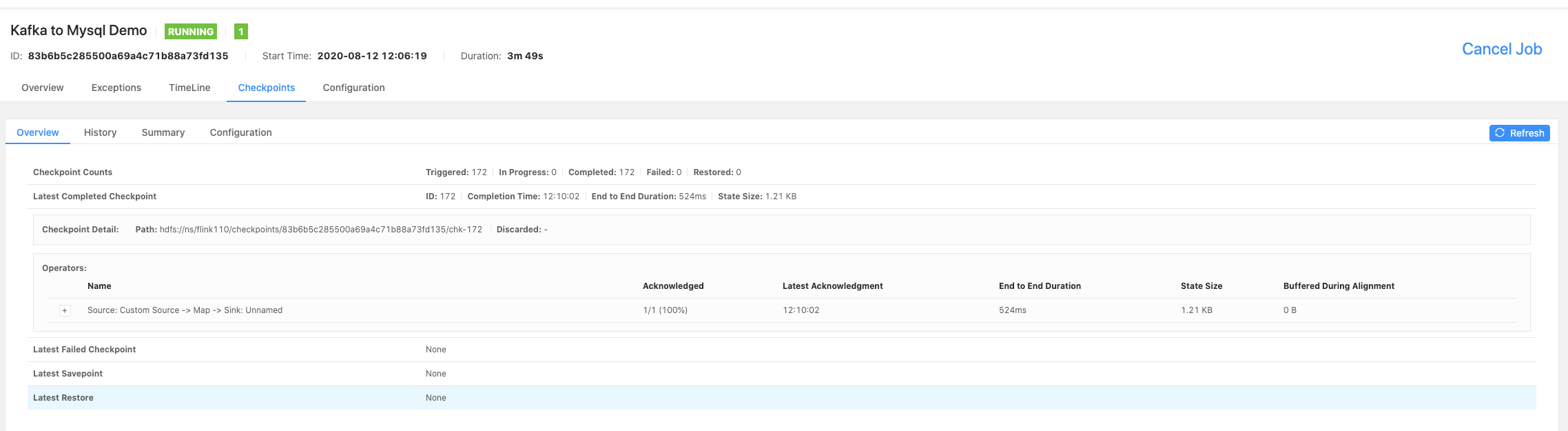
1.checkpoint 页面结果
1.1 结果
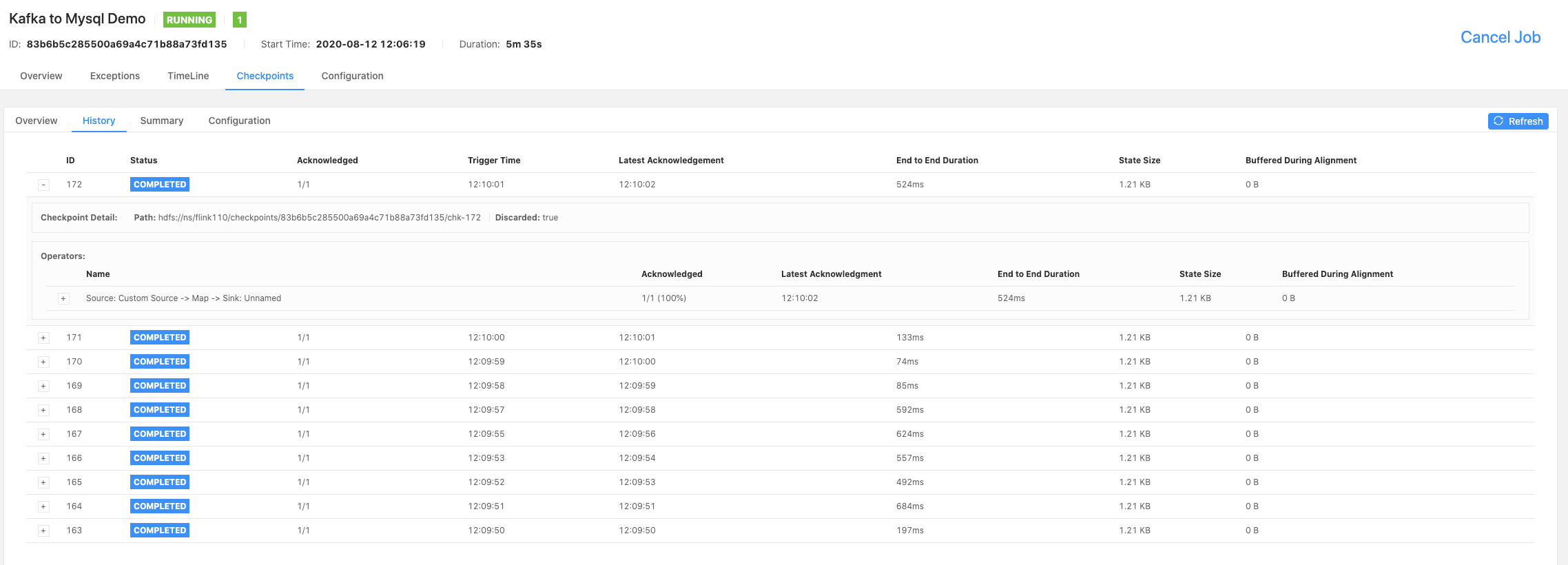
1.2 history
 1.3 检查配置
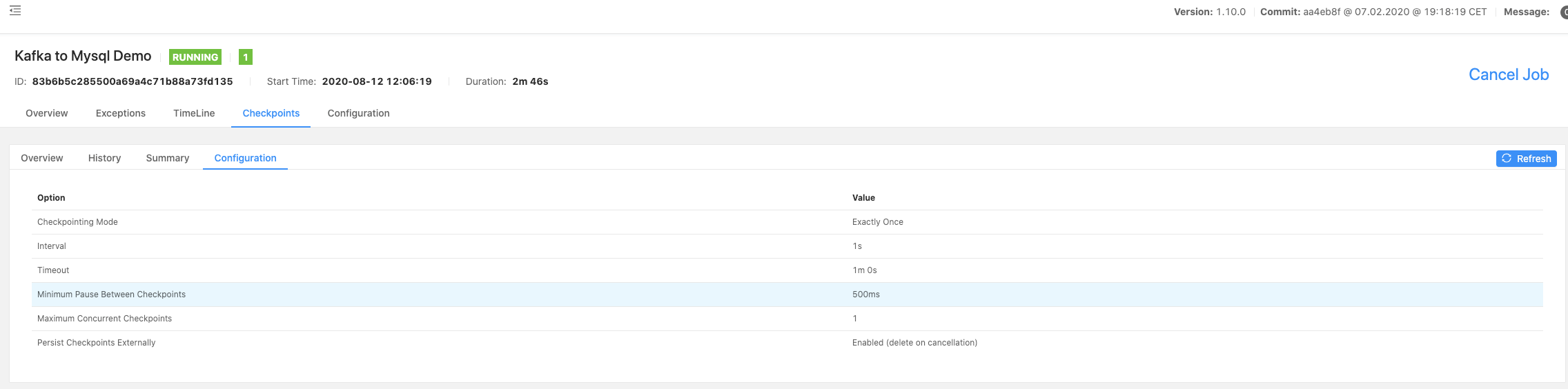
1.3 检查配置
2.HDFS文件检查
2.1 任务运行时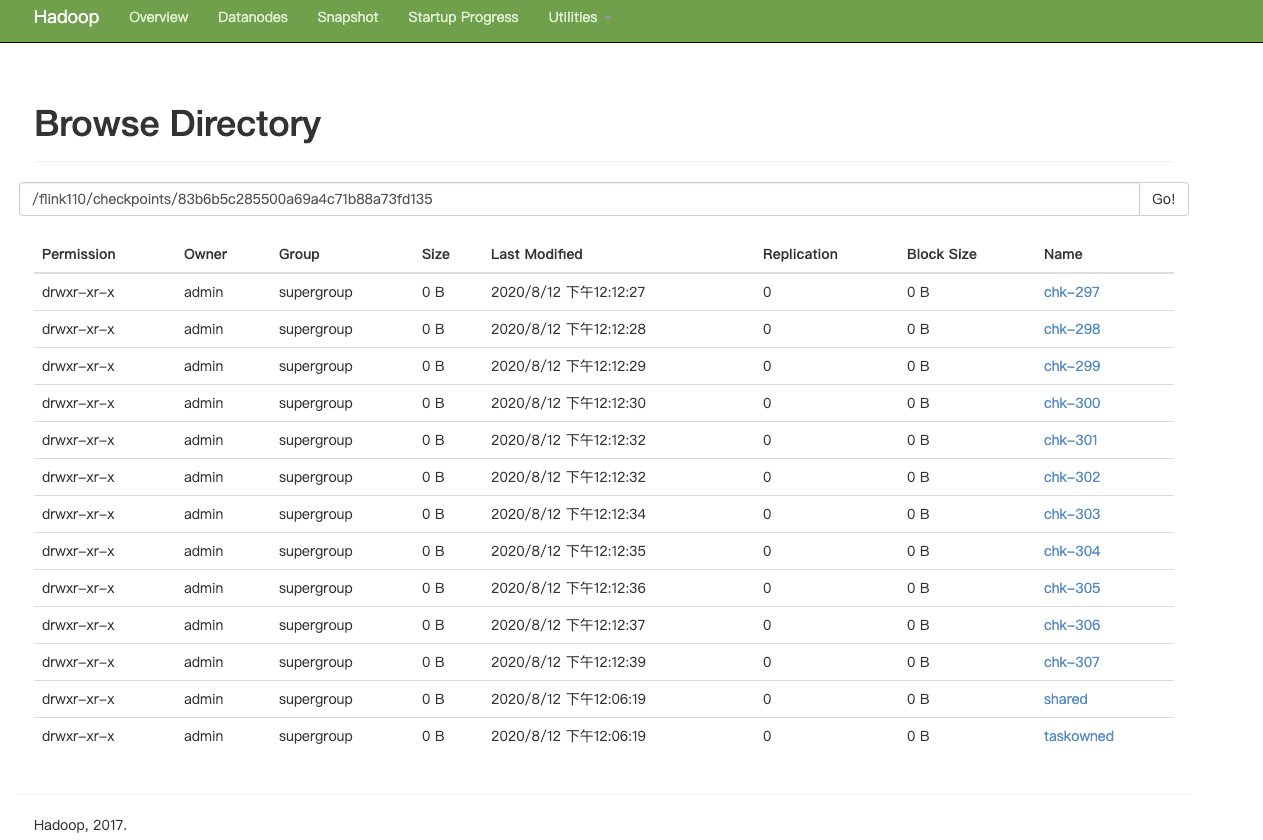
这些文件在任务运行时保留,当任务取消停止时,这些checkpoint文件将会被删除,如果需要保留,可以通过配置checkpoint的 enableExternalizedCheckpoints 参数
从保留的 checkpoint 中恢复状态
与 savepoint 一样,作业可以从 checkpoint 的元数据文件恢复运行。注意,如果元数据文件中信息不充分,那么 jobmanager 就需要使用相关的数据文件来恢复作业。
bin/flink run -s :checkpointMetaDataPath [:runArgs]
如何在数栈平台使用checkpoint
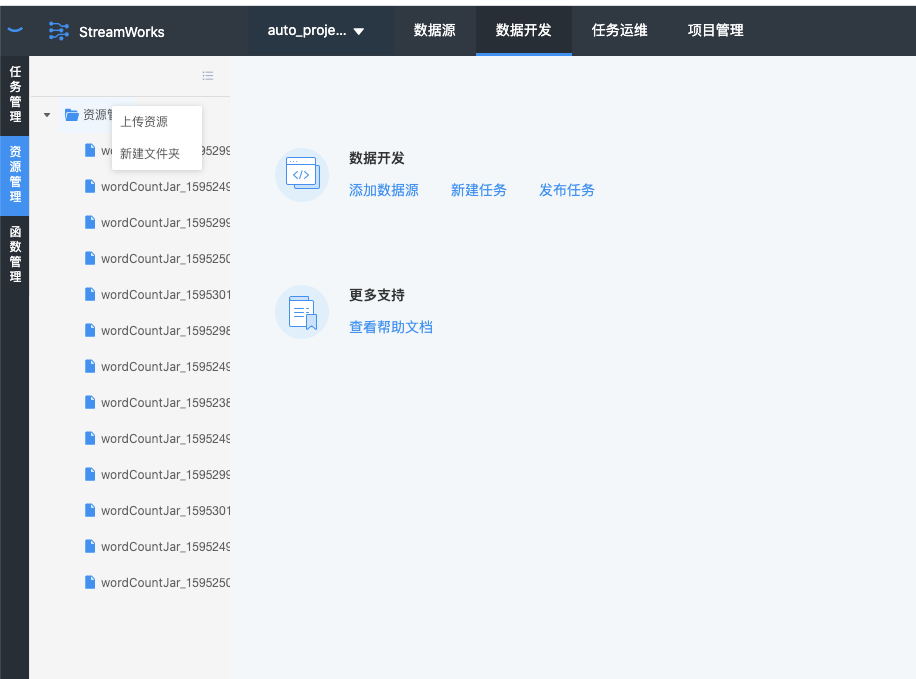
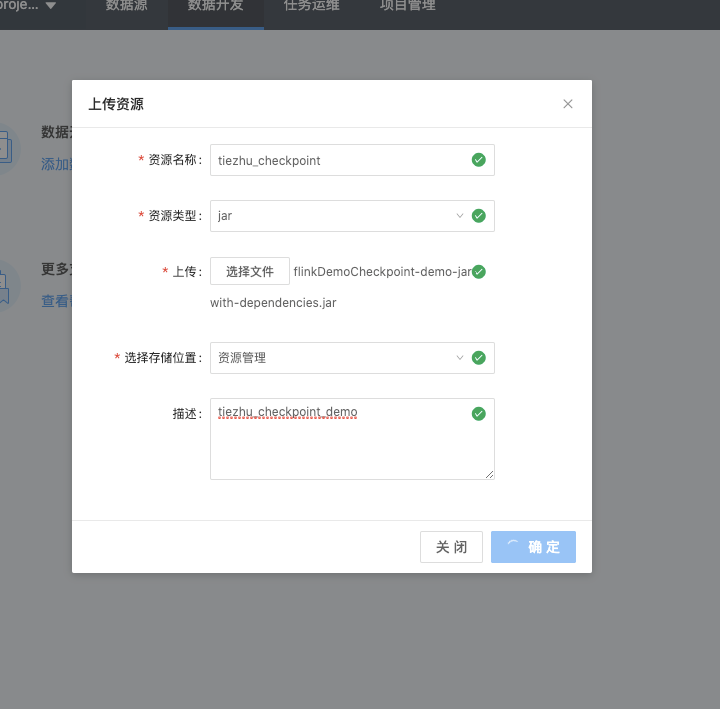
1.上传资源
1.1 将打包好的jar包上传到平台资源中,右键资源管理(可自定义文件夹存储jar包资源),点击上传资源
1.2 填写资源相关信息,等待上传,上传成功后可在左侧资源列表中查看已上传的资源
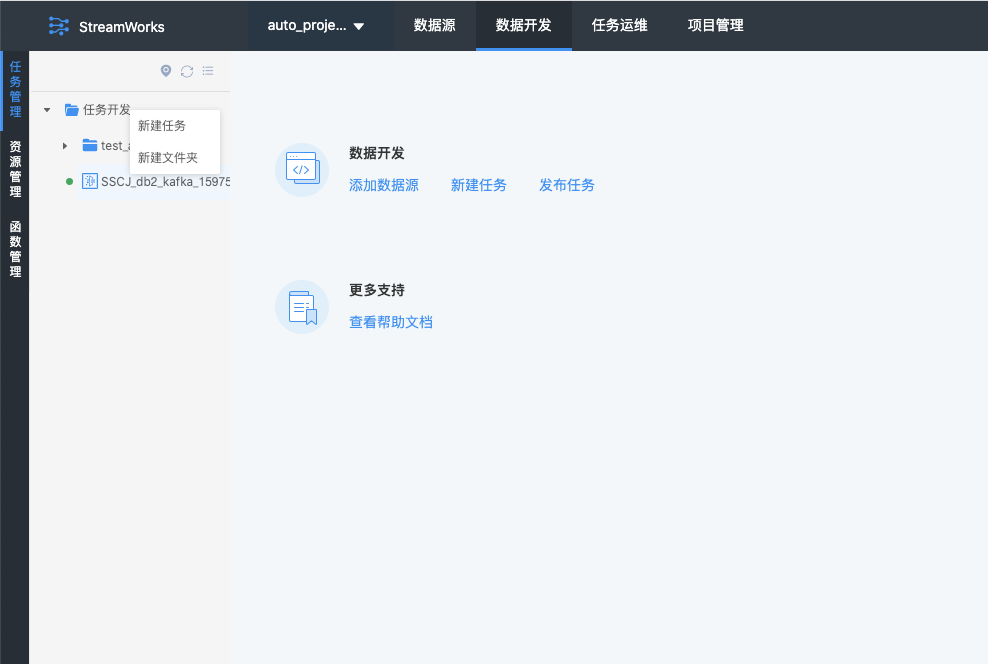
2.设置任务
2.1 新建任务
2.2 填写任务参数,等待任务创建完成
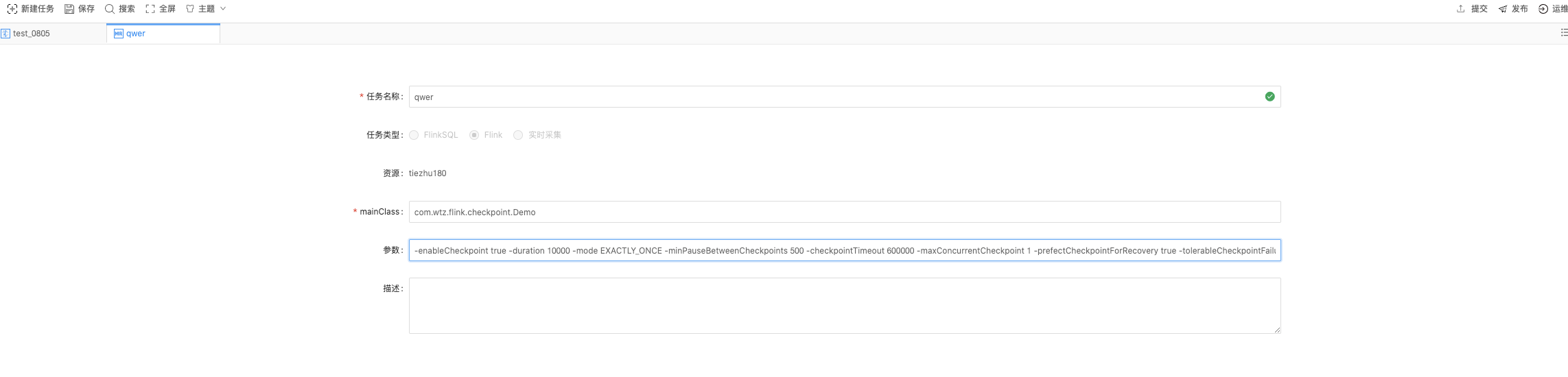
这里需要注意的是,在写完了任务自身的配置之外,还需要在页面右侧的环境参数中,额外配置平台的checkpoint参数
2.3 创建完成后,提交任务至平台运行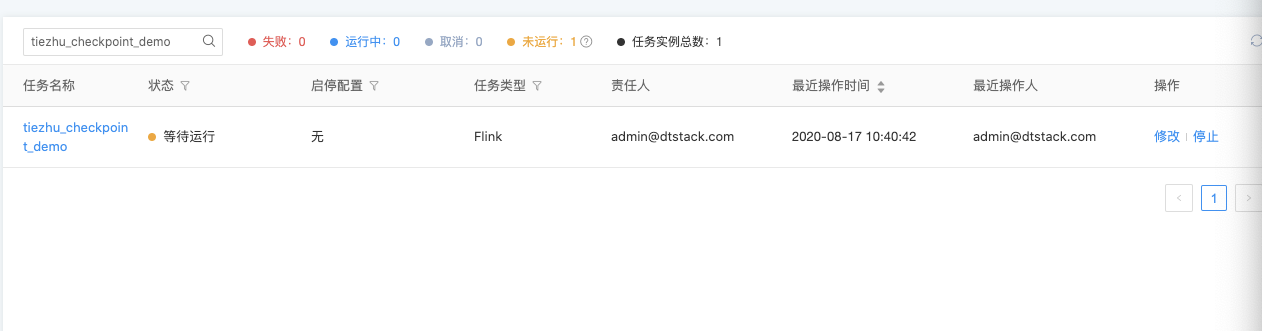
3.查看checkpoint
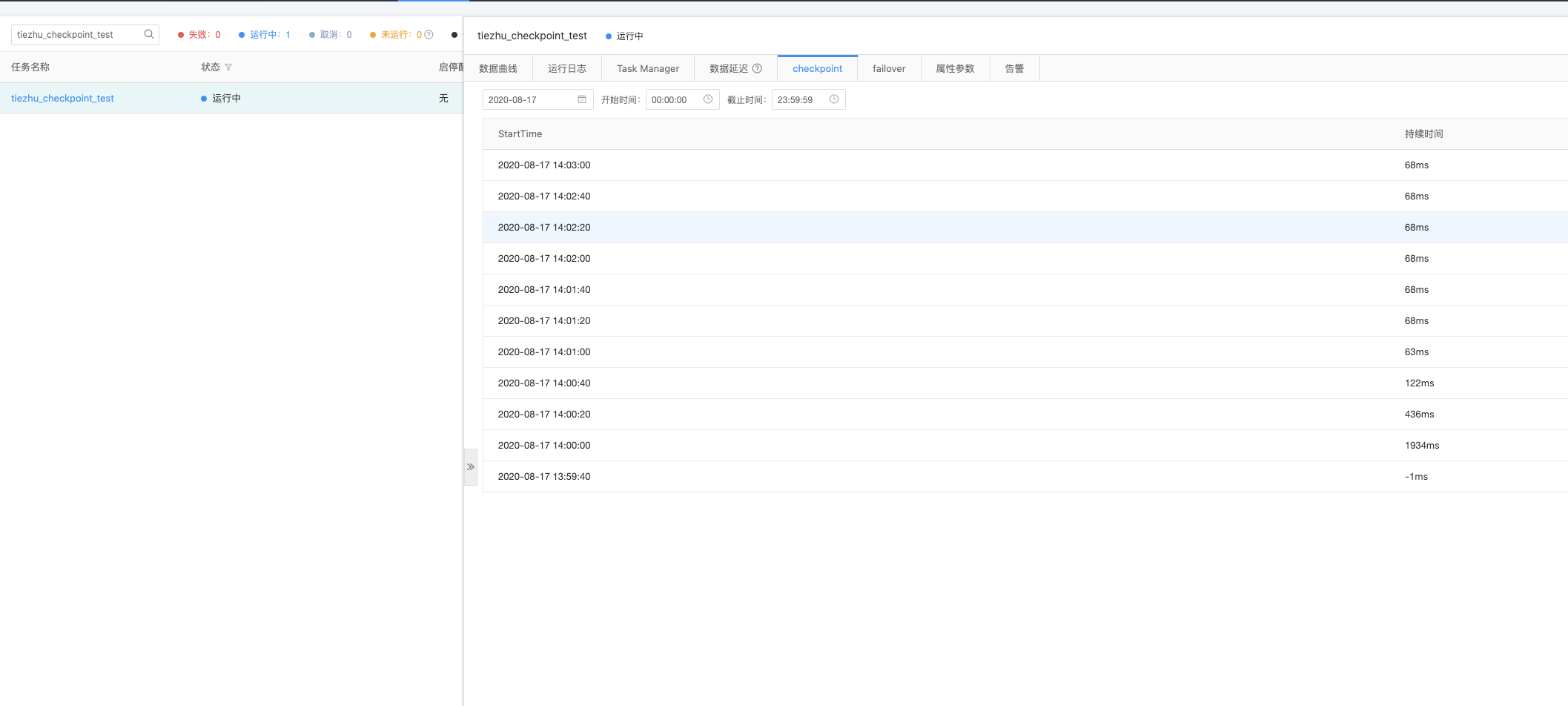
4.从checkpoint中恢复任务

4.1 DELETE_ON_CANCELLATION 策略下续跑
因为程序中设置的checkpoint策略是 DELETE_ON_CANCELLATION,checkpoint在任务失败后会被保留,但是在任务取消后自动删除,所以平台获取不到任务的checkpoint,修改策略为RETAIN_ON_CANCELLATION即可在任务取消后也自动保留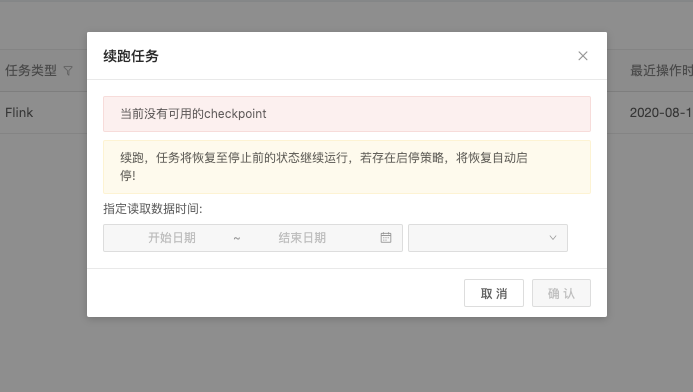
4.2 RETAIN_ON_CANCELLATION策略下续跑
策略为RETAIN_ON_CANCELLATION 会在任务取消后保留checkpoint,可以在续跑选项中选择指定的时间点生成的checkpoint续跑。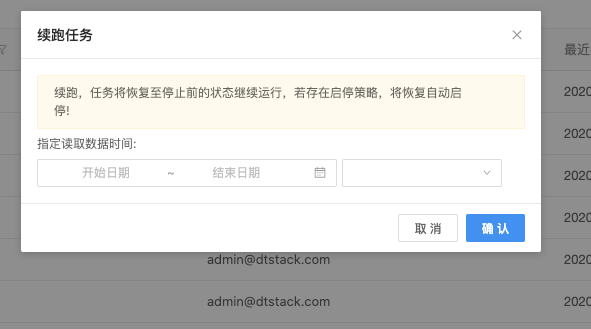
选择checkpoint的时间区间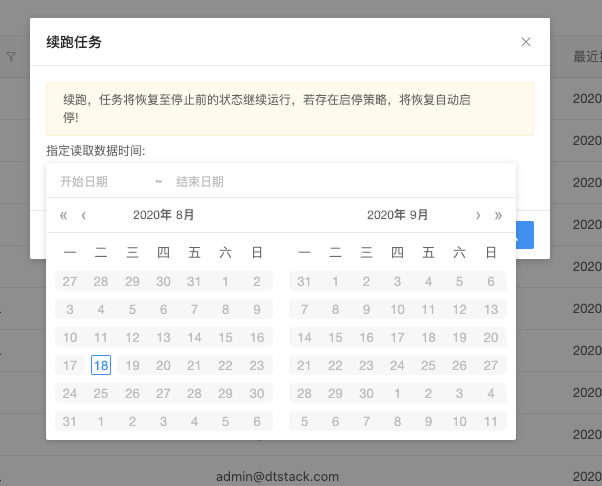
选择checkpoint时间点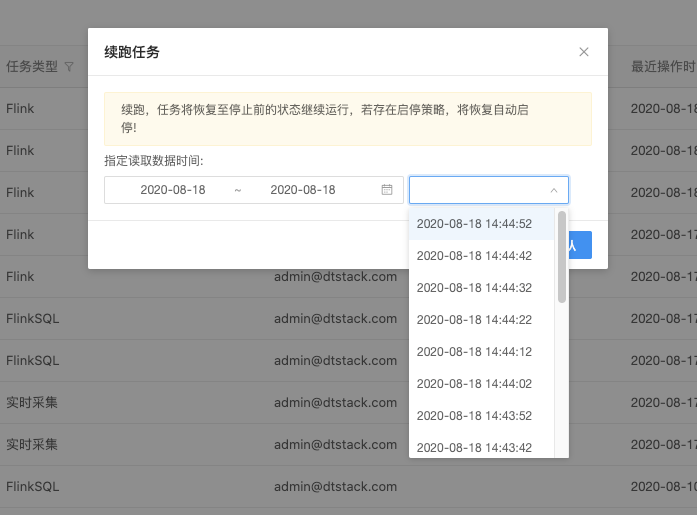
点击确定,续跑操作成功,等待任务续跑成功。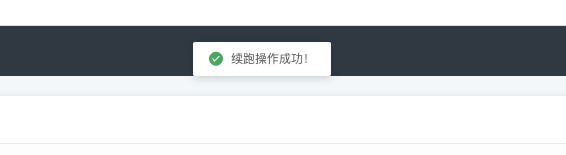

若有收获,就点个赞吧
0 人点赞
