

点击查看【bilibili】
https://www.yuque.com/books/share/f4031f65-70c1-4909-ba01-c47c31398466/mkn2fh
https://mp.weixin.qq.com/s/MavdyZS1HX1GnWXypdDu4w
线性回归原理
将价格和面积、厅室数量的关系,模型建立为:
使得 ,这就是一个直观的线性回归的样式。
,这就是一个直观的线性回归的样式。
基本原理
假设数据集为:

后面记为:
所有向量表示默认为列向量。
 分别表示一个列向量,转置后
分别表示一个列向量,转置后 每一行是一个样本,维度是
每一行是一个样本,维度是 。
。
Y是N行1列
w是p维的向量
线性回归假设:
最小二乘法



两种角度理解几何意义:
- 把总误差平均分散在每个样本上
- 把总误差分散在每个维度
点击查看【bilibili】
点击查看【bilibili】
MAP:最大后验的角度解释岭回归



学习策略
- 损失函数
度量单个样本预测的错误程度。损失函数越小,模型就越好。
- 0-1损失函数
- 平方损失函数
- 绝对损失函数
- 对数损失函数
- 代价函数
度量全部样本集的平均误差。
- 均方误差
- 均方根误差
- 平均绝对误差
- 目标函数
代价函数和正则化函数,最终要优化的函数。
- 思考
既然代价函数已经可以度量样本集的平均误差,为什么还要设定目标函数?
答:当模型复杂度增加时,有可能对训练集可以模拟的很好,但是预测测试集的效果不好,出现过拟合现象,这就出现了所谓的“结构化风险”。结构风险最小化即为了防止过拟合而提出来的策略。
通常,随着模型复杂度的增加,训练误差会减少;但测试误差会先增加后减小。我们的最终目的是测试误差达到最小,这就是我们为什么需要选取适合的目标函数的原因。
梯度下降法
设定初始参数 ,不断迭代,使得最小化:
,不断迭代,使得最小化:


其缺点是,因为每次只针对一个样本更新参数,未必找到最快路径达到最优值,甚至有时候会出现参数在最小值附近徘徊而不是立即收敛。但当数据量很大的时候,随机梯度下降法经常优于批梯度下降法。
当为凸函数时,梯度下降法相当于让参数不断向的最小值位置移动。梯度下降法的缺陷:如果函数为非凸函数,有可能找到的并非全局最优值,而是局部最优值。
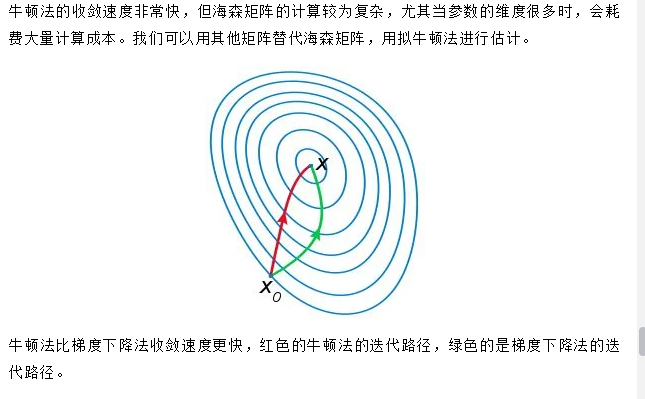
牛顿法







#生成数据import numpy as np#生成随机数np.random.seed(1234)x = np.random.rand(500,3)#构建映射关系,模拟真实的数据待预测值,映射关系为y = 4.2x1 + 5.7*x2 + 10.8*x3,可自行设置值进行尝试y = x.dot(np.array([4.2,5.7,10.8]))import numpy as npfrom sklearn.linear_model import LinearRegressionimport matplotlib.pyplot as plt%matplotlib inlinelr = LinearRegression(fit_intercept=True)# 默认即可#训练modellr.fit(x, y)print("估计的参数值:%s"%(lr.coef_))print("估计的截距:%s"%(lr.intercept_))#计算R方print('R2:',(lr.score(x,y)))#测试x_test = np.array([4,5,7]).reshape(1,-1)y_hat = lr.predict(x_test)print('真实值为:',x_test.dot(np.array([4.2,5.7,10.8])))print('预测值为:',y_hat)
最小二乘法
class LR_LS():def __init__(self):self.w = Nonedef fit(self, X, y):# 最小二乘法矩阵求解#============================= show me your code =======================self.w = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)#============================= show me your code =======================def predict(self, X):# 用已经拟合的参数值预测新自变量#============================= show me your code =======================y_pred = X.dot(self.w)#============================= show me your code =======================return y_predif __name__ == "__main__":lr_ls = LR_LS()lr_ls.fit(x,y)print("估计的参数值:%s" %(lr_ls.w))x_test = np.array([4,5,7]).reshape(1,-1)print('真实值为:',x_test.dot(np.array([4.2,5.7,10.8])))print("预测值为: %s" %(lr_ls.predict(x_test)))
梯度下降法
class LR_GD():def __init__(self):self.w = Nonedef fit(self,X,y,alpha=0.002,loss = 1e-10): # 设定步长为0.002,判断是否收敛的条件为1e-10y = y.reshape(-1,1) #重塑y值的维度以便矩阵运算[m,d] = np.shape(X) #自变量的维度self.w = np.zeros((d)) #将参数的初始值定为0tol = 1e5#============================= show me your code =======================while tol > loss:h_f = X.dot(self.w).reshape(-1,1)theta = self.w + alpha*np.mean(X*(y - h_f),axis=0) #计算迭代的参数值tol = np.sum(np.abs(theta - self.w))self.w = theta#============================= show me your code =======================def predict(self, X):# 用已经拟合的参数值预测新自变量y_pred = X.dot(self.w)return y_predif __name__ == "__main__":lr_gd = LR_GD()lr_gd.fit(x,y)print("估计的参数值为:%s" %(lr_gd.w))x_test = np.array([4,5,7]).reshape(1,-1)print('真实值为:',x_test.dot(np.array([4.2,5.7,10.8])))print("预测值为:%s" %(lr_gd.predict(x_test)))
4. 测试
在3维数据上测试sklearn线性回归和最小二乘法的结果相同,梯度下降法略有误差;又在100维数据上测试了一下最小二乘法的结果比sklearn线性回归的结果更好一些。
连续值—回归
离散值—分类
回归这个名词怎么来的:生物学上来的,孩子的身高会在父母双亲的一定波动区间浮动。
线性回归:
- 高斯分布
- 最大似然估计MLE
- 最小二乘法的本质
logistic回归
- 分类问题的首选算法(实际应用中)
工具
- 梯度下降算法
- 极大似然估计
代码消化(去微信收藏Datawhale)
计算机中没有真正的随机数。一般都是伪随机数。
随机数种子,指定后每次随机的结果一致。
特征多,模型结果不一定好。不相关的特征,可以考虑去除
Ridge:岭回归,加入l2正则化,这个正则化需要一个权重参数,
如何确定这个参数,确定参数alpha_can的搜索空间,然后使用交叉验证确定参数。
一般来说,ridge会更好一些
高阶曲线拟合,加入l2正则,确实能够降低过拟合风险(实验证明)
lasso:会帮助得到更稀疏的模型,也就是模型参数是很小的数、甚至是0。
特征其实相比模型选择,更重要。
y = theta_1 x_1 + theta_2 x_2 + b
假定独立同分布
中心极限定理
最小二乘法成立,是假设了样本服从高斯分布
面试问题
1. 线性回归的损失函数为什么用最小二乘不用似然函数?
答:
最小二乘法以估计值与观测值的平方和作为损失函数,在误差服从正态分布的前提下,与极大似然估计(极大化数据集的对数似然函数)的思想在本质上是相同。我们通常认为ε服从正态分布,通过对极大似然公式的推到,结果真是最小二乘的式子。

若有收获,就点个赞吧
0 人点赞
