数组、链表、跳表的基本实现和特性
Array(数组)
- Java,C++:int a[100];
- Python:list = []
- JavaScript:let x = [1, 2, 3]
- 内存管理器(Memory Controller)
- 申请数组时,实际上是计算机在内存中开辟了一段连续的地址
- 按下标随机访问的时间复杂度是 O(1)
- 数组增加、删除元素的时间复杂度为 O(n)
- 时间复杂度
- prepend O(1)
- append O(1)
- lookup O(1)
- insert O(n)
- delete O(n)
Linked List(链表)
- Node
- value(值)
- next(指针)
- 单链表、双链表、循环链表
- 时间复杂度
- prepend O(1)
- append O(1)
- lookup O(n)
- insert O(1)
- delete O(1)
Skip List(跳表)
- 注意:跳表只能用于链表里的元素有序的情况下
- 所以,跳表对标的是二叉搜索树中的平衡树(AVL Tree)和二分查找,是一种 插入/删除/搜索 都是 O(log n) 的数据结构。(空间复杂度O(n))
小结
- 数组、链表、跳表的原理和实现
- 三者的时间复杂度、空间复杂度
- 工程运用
- 跳表:升维思想 + 空间换时间
参考链接
- Java 源码分析 ArrayList
- Linked List 的标准实现代码
- Linked List 示例代码
- Java 源码分析 LinkedList
- LRU Cache - Linked List
- Redis - Skip List
实战题目解析
移动零
爬楼梯
懵逼的时候:
- 先不要想的很复杂,先看基本的情况
- 能不能暴力?
- 最基本的情况怎么解决?
- n = 1?
- n = 2?
- n = 3?
- …
- 递推,数学归纳法的思想
- 找 最近 重复 子问题
- 重复性!!
- n = 3 时,你只能从第一级台阶走过来,或者从第二级台阶走过来,没有其他的办法(n - 1) 或 (n - 2)
- n = 3 时,f(1) + f(2) (第一级台阶的走法 + 第二级台阶的走法)
链表
- 经典应用场景:LRU 缓存淘汰算法
- 缓存淘汰策略:
- 先进先出策略:FIFO(First In, First out)
- 最少使用策略:LFU(Least Frequently Used)
- 最近最少使用策略:LRU(Least Recently Used)
- 数组与链表的区别
- 数组需要 一块连续的内存空间;链表不需要,通过“指针”将一组 零散的内存块串联起来
- 常见的链表结构:
- 单链表
- 结点存储数据与下一个结点的地址
- 单链表
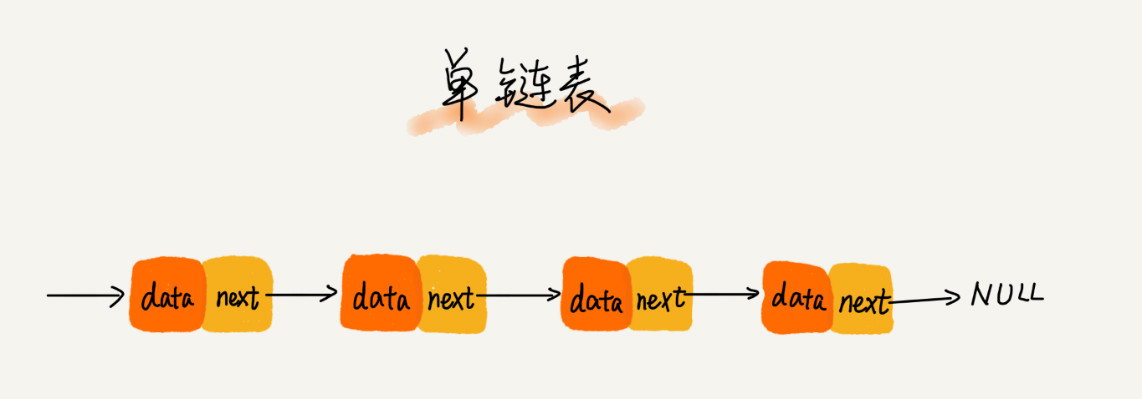
- 针对链表的插入和删除操作,对应时间复杂度为 O(1)
- 链表随机访问的时间复杂度为 O(n)
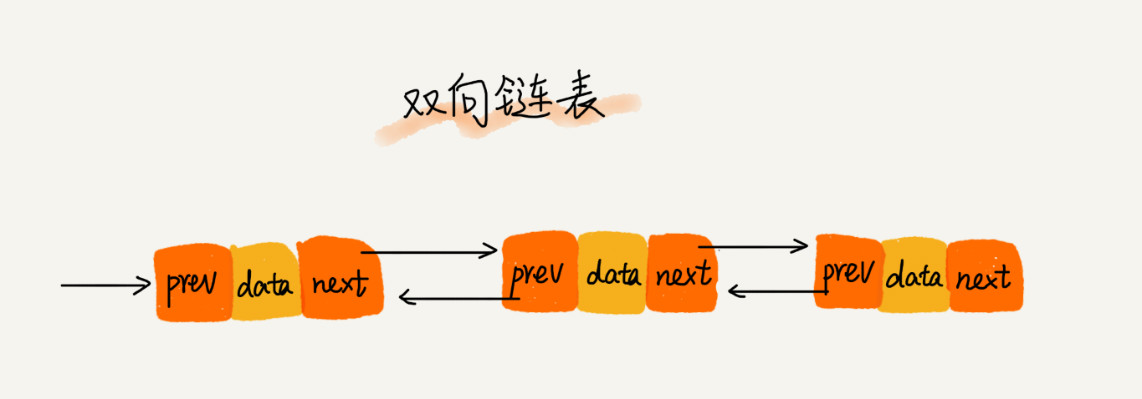
- 双向链表
- 不仅有后继指针,也有前驱指针
- 循环链表
- 尾结点指针指向头结点
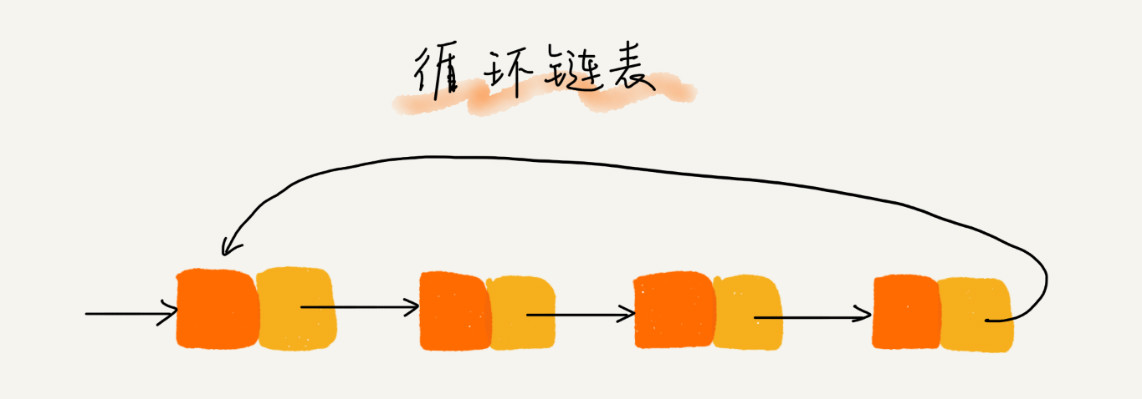
- 适合处理具有环形结构的数据:如约瑟夫问题
如何正确写出链表代码
技巧一:理解指针或引用的含义
无论“指针”还是“引用”,他们的意思都是:存储所指对象的内存地址。
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
p->next = q
// p 结点中的 next 指针存储了 q 结点的内存地址
p->next = p->next->next
// p 结点的 next 指针存储了 p 结点的下下一个结点的内存地址
技巧二:警惕指针丢失和内存泄漏
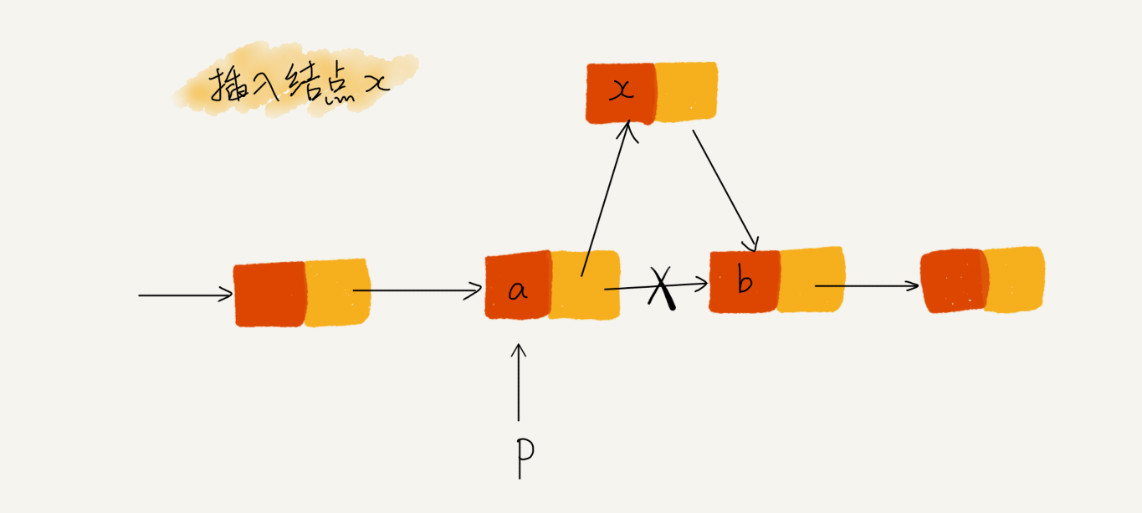
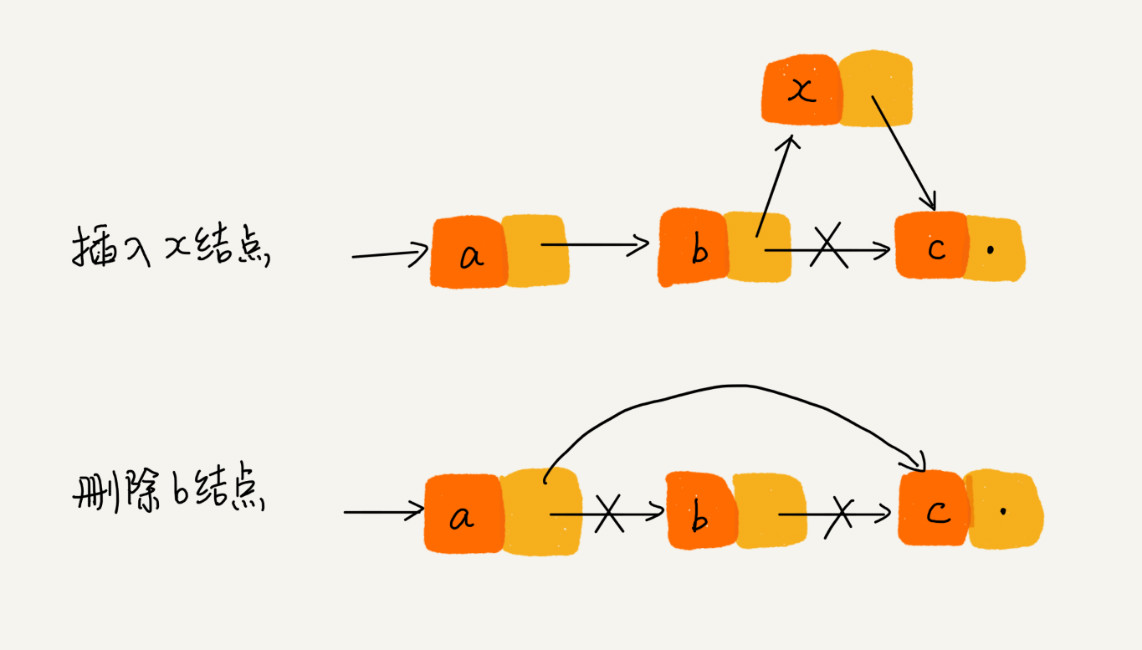
我们希望在结点 a 和相邻的结点 b 之间插入结点 x,假设当前指针 p 指向结点 a。
如果将代码变成下面这样,就会发生指针丢失和内存泄漏
p->next = x // 将 p 的 next 指针指向 x 结点;
x->next = p->next // 将 x 的结点的 next 指针指向 b 结点;
将 p 的 next 指向 x ,p 的 next 已经不是 b 了。
所以, 插入结点时,一定要注意操作顺序。 先将 x 的 next 指向 b 结点,再把结点 a 的 next 指向 x,这样才不会丢失指针,造成内存泄漏。
同理, 删除链表结点时,也一定要记得手动释放内存空间。
技巧三:利用哨兵简化实现难度
单链表的插入和删除操作,如果在结点 p 后插入一个元素,只需要
new_node->next = p->next
p->next = new_node
但是要向一个空链表中插入第一个结点,刚才的逻辑就不成立了。对于单链表的插入和删除操作,第一个结点和其他结点的插入逻辑是不一样的。
if (head == null) {
head = new_node
}
要删除结点 p 后继结点,只需要:
p->next = p->next->next
但是要删除最后一个结点,上面的代码就不行了
if (head.next == null) {
head = null
}
针对链表的插入、删除操作,需要对插入第一个结点,删除最后一个结点的情况进行特殊处理。
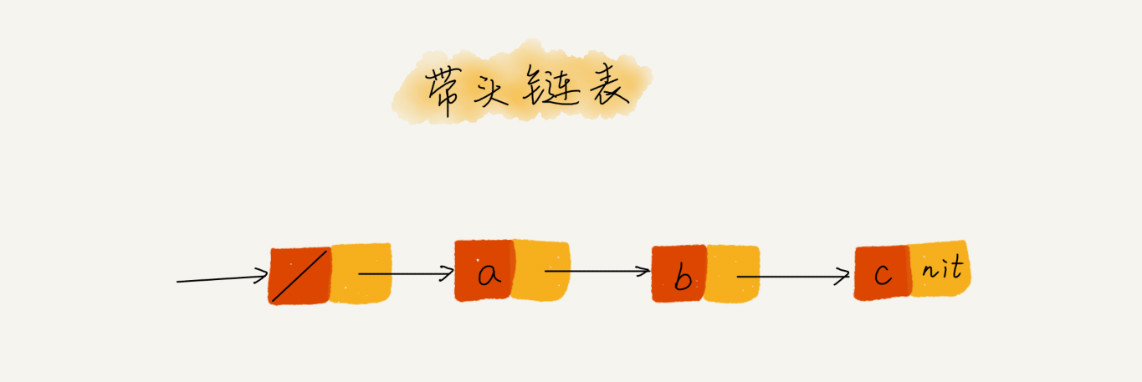
“哨兵”就可以解决“边界问题”,而不直接参与业务逻辑。
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结点。我们把这种带有哨兵结点的链表叫 带头链表 。哨兵结点不存储任何数据。
// 在数组a中,查找key,返回key所在的位置
// 其中,n表示数组a的长度
int find(char* a, int n, char key) {
// 边界条件处理,如果a为空,或者n<=0,说明数组中没有数据,就不用while循环比较了
if(a == null || n <= 0) {
return -1;
}
int i = 0;
// 这里有两个比较操作:i<n和a[i]==key.
while (i < n) {
if (a[i] == key) {
return i;
}
++i;
}
return -1;
}
// 在数组a中,查找key,返回key所在的位置
// 其中,n表示数组a的长度
// 我举2个例子,你可以拿例子走一下代码
// a = {4, 2, 3, 5, 9, 6} n=6 key = 7
// a = {4, 2, 3, 5, 9, 6} n=6 key = 6
int find(char* a, int n, char key) {
if(a == null || n <= 0) {
return -1;
}
// 这里因为要将a[n-1]的值替换成key,所以要特殊处理这个值
if (a[n-1] == key) {
return n-1;
}
// 把a[n-1]的值临时保存在变量tmp中,以便之后恢复。tmp=6。
// 之所以这样做的目的是:希望find()代码不要改变a数组中的内容
char tmp = a[n-1];
// 把key的值放到a[n-1]中,此时a = {4, 2, 3, 5, 9, 7}
a[n-1] = key;
int i = 0;
// while 循环比起代码一,少了i<n这个比较操作
while (a[i] != key) {
++i;
}
// 恢复a[n-1]原来的值,此时a= {4, 2, 3, 5, 9, 6}
a[n-1] = tmp;
if (i == n-1) {
// 如果i == n-1说明,在0...n-2之间都没有key,所以返回-1
return -1;
} else {
// 否则,返回i,就是等于key值的元素的下标
return i;
}
}
技巧四:重点留意边界条件处理
- 如果链表为空,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点时,是否能正常工作?
- …
技巧五:举例画图,辅助思考
比如单链表中插入一个数据:

技巧六:多写多练,没有捷径
5 个常见的链表操作
- 单链表反转 - 206
- 链表中环的检测 - 141
- 两个有序的链表合并 - 21
- 删除链表倒数第 n 个结点 - 19
- 求链表的中间结点 - 876

若有收获,就点个赞吧
0 人点赞
