通过前面的文章,目前我已经了解到了单一所有权、Move语义、Copy语义、可变和不可变借用以及引用计数。突然回首可以发现,Move语义和Copy语义保证了值的单一所有权;而可变和不可变借用又可以避免对象在作为函数参数进行传递时造成额外的内存开销;引用计数提供了一种突破值的单一所有权限制的手段,得以实现多线程操作同一块内存和实现DAG等操作,使得 rust 和其他语言一样的灵活。
而上述的这些场景我们可以发现最终都是为了合理的管理内存,它希望在生命周期内就可以确定值内存的释放时机,而不必像Java和Go一样需要引入垃圾回收,也不必需要像C一样需要手动维护内存的申请和释放。
显然,对于栈变量,其内存管理和维护与函数的堆栈密切相关,我们无需特别关心,其在编译期间就已经确定了创建、存放和销毁时机地点。而对于堆上创建的变量,由于其容量大小和生命周期都是动态的,所以管理和维护相对较为复杂。
如何管理堆内存?
Rust 的创造者们,重新审视了堆内存的生命周期,发现大部分堆内存的需求在于动态大小,小部分需求是更长的生命周期。所以它默认将堆内存的生命周期和使用它的栈内存的生命周期绑在一起,并留了个小口子 leaked 机制(想起了上一篇文章里面的Rc::new方法),让堆内存在需要的时候,可以有超出帧存活期的生命周期。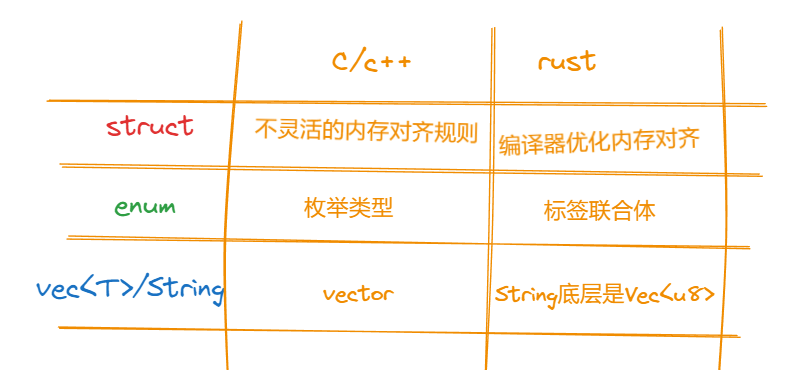
结构体内存对齐
C语言的对齐规则如下,而 rust在编译器层面进行了优化:
- 首先确定每个域的长度和对齐长度,原始类型的对齐长度和类型的长度一致。
- 每个域的起始位置要和其对齐长度对齐,如果无法对齐,则添加 padding 直至对齐。
- 结构体的对齐大小和其最大域的对齐大小相同,而结构体的长度则四舍五入到其对齐的倍数。
use std::mem::{align_of, size_of};struct S1 {a: u8,b: u16,c: u8,}struct S2 {a: u8,c: u8,b: u16,}fn main() {// sizeof S1: 4, S2: 4println!("sizeof S1: {}, S2: {}", size_of::<S1>(), size_of::<S2>());// alignof S1: 2, S2: 2println!("alignof S1: {}, S2: {}", align_of::<S1>(), align_of::<S2>());}
上面的代码如果翻译成C语言就会发现 s1 的 size 是 6,而 s2 的 size 是 4, 这说明c语言在编译器层面并没有进行进一步的优化,为节省内存空间,程序员需要手动对结构体里面的字段排序。
enum
Rust 下它是一个标签联合体(tagged union),它的大小是标签的大小,加上最大类型的长度。通过<font style="color:rgb(51, 51, 51);">size_of</font>方法可以很方便的实验出不同平台下,不同类型enum的大小:
use std::collections::HashMap;use std::mem::size_of;fn main() {println!("{:<28} {:>4}", "Type", "T");println!("{:<28} {:4}", stringify!(u8), size_of::<u8>());println!("{:<28} {:4}", stringify!(String), size_of::<String>());println!("{:<28} {:4}", stringify!(Vec<u8>), size_of::<Vec<u8>>());println!("{:<28} {:4}", stringify!(HashMap<String, String>), size_of::<HashMap<String, String>>());}
最终输出结果如下所示:
Type Tu8 1String 24Vec < u8 > 24HashMap < String, String > 48
有关具体的使用方法请参考官方文档,和 Java 等其他语言 enum 一个比较大的区别是, Rust enum 内部的每一个枚举可以是不同的类型。此外 Rust enum 的内存设计也和其他语言有较大不同,可以参考这个链接进行学习。
vec 和 String
从上面输出可以看到 String 和 Vec学习资料

若有收获,就点个赞吧
0 人点赞
