本文结构
1.如何选择正确的实验指标
2.AB测试中的常见问题
(1)新奇效应-实验时间对统计显著性的影响
(2)以偏概全-实验周期是否覆盖产品高低频用户
(3)辛普森悖论-实验流量分割比例改变带来的结果错误
(4)正交实验-如何同时进行多个实验,保证流量的高可用
3.如何分析实验结果背后的原因
对于AB测试一些原理知识与落地细节,例如用到的检验方法与数据分布,样本量和实验时间的计算,统计功效与显著性等问题可以参考这个系列的第一篇文章。
一.如何选择正确的实验指标
1.1 案例:亚马逊中国购物车的A/B测试
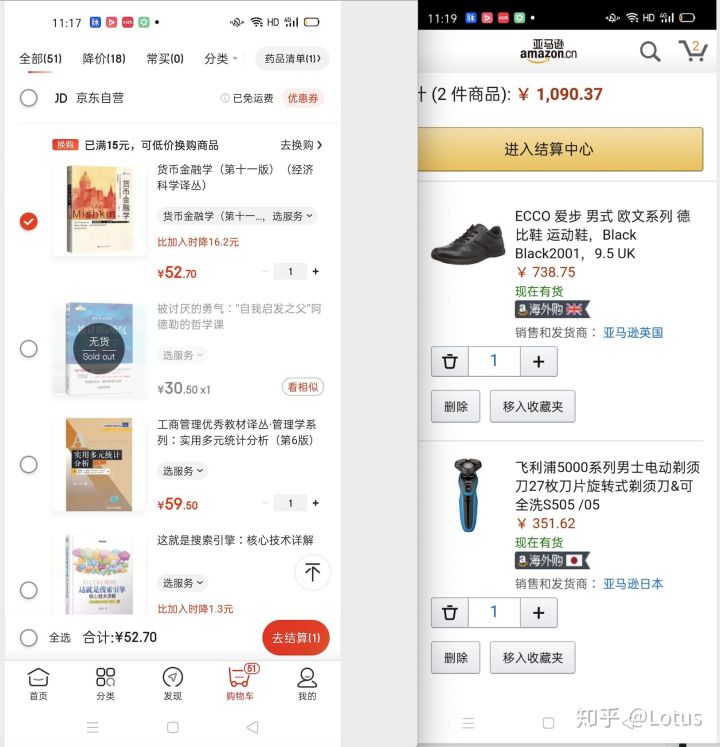
左图是京东购物车页面,右图是亚马逊中国的购物车页面
因为中国用户的购物习惯是”部分结账”,不买的会留在车里,所以购物车里有复选框
而国外用户习惯是”全部结账”,默认全部下单,不买的移出去。
(注:这是以前的设计对比,现在亚马逊中国的购物车页面也加入了复选框)
实验假设:将”全部结账”购物车改成中国用户更习惯的”部分结账”购物车,会提升下单转化率。
实验组:允许部分结账,加入复选框
对照组:全部结账,没有复选框,不想购买的直接删除或者移入收藏夹
那么如果是你,该怎么选择实验指标来验证这个方案的有效性呢?
亚马逊中国分析团队第一次设定的指标是销售额
第一次实验结果是实验组销售额相比对照组,显著下降,那么我们能得出这次改动无用的结论吗?
团队进一步分析,发现了以下几个现象:
1.如果是新用户,他刚接触”全部结账”版本的时候,因为不符合习惯,有可能一不小心买多了。
2.全部结账版本,也就是对照组,用户在买多之后,只有部分用户会退货,因此对销售额影响不大,但长期满意度会下降
3.购买之后,用户保留”部分结账”购物车里的产品,其实仍有潜在销售机会,但不会在短期内复购,会延迟。
所以如果对比更多的实验指标,可能发现
对照组(全部结账):短期销售额高,退货率高,长期满意度低
实验组(部分结账):长期复购率和销售额高
所以第二次实验指标在选择上进行的增加,包括综合销售额,复购率,下单频次,结账转化率,退货率等等。
第二次实验证明实验组综合销售额和下单频次都显著提升,通过A/B测试,最后成功上线。
总结:
一般A/B实验指标体系需要三类实验指标
(1)核心指标:这种指标是决定实验成败的关键指标
(2)辅助指标:用于辅助判断实验对其他因素的影响
(3)反向指标:实验可能产生负面影响的指标
1.2 如何选择核心指标
这个其实需要具体的业务理解,需要明白这个实验的目标,这里举个例子,避免选择虚荣指标作为核心指标(参考精益数据分析)。
某APP做首页”新手引导”板块的改版:
实验目标:能让更多的新用户了解产品功能,完成初始设置。
实验假设:通过让用户阅读新手文章,可以教育产品功能,并让新用户完成初始设置。
对照组A:新手引导文章呈卡片式排列
实验组B:新手引导文章呈清单式排列
实验发现:标题点击率 A组:20%,B组50%,但是新手设置完成率A组:10%,B组:7%。
其中应该选新手设置完成率为核心指标,这也是产品改动的最终目标,而标题点击率就是虚荣指标。
1.3 如何找到辅助指标
(1)漏斗细分步骤转化率:结账转化率
(2)重要下游指标:复购率
(3)其他关键用户指标,例如影响用户体验的指标,滑动比例,回跳率等等
以电商网站”加入购物车”按钮实验为例子:
核心指标是产品页”加入购物车”按钮点击率
辅助指标可参考转化漏斗,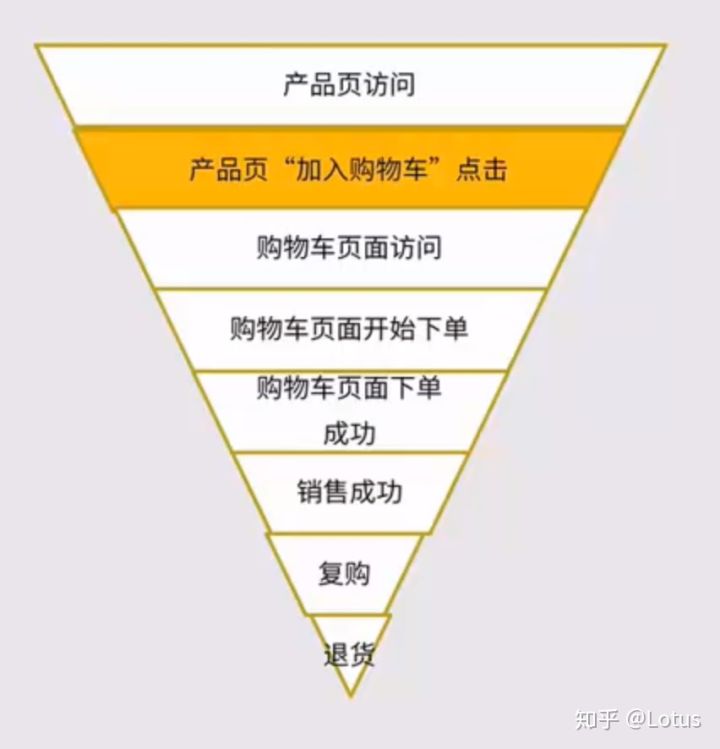
辅助指标可以是:
平均”加入购物车按钮”点击次数
购物车页面访问数
购物车页面下单成功率
销售额
复购率
等等
反向指标:退货率
1.4 如何找到反向指标
反向指标的作用是提示实验可能的负面影响,如果负面影响太高,即使其他指标通过,也可以否决实验结果.
常见反向指标:
退货率,页面退出率,其他按钮点击率
应用删除率,Push退订率,订单取消率,邮件退订率等等。
二.AB测试中的常见问题
2.1 新奇效应-实验时间对统计显著性的影响
新奇效应,也是均值回归,在统计学上指的是对于概率事件的结果,随着试验次数的增加,结果往往趋近于均值。举个例子,假设让一个人回答若干个历史问题,这些问题是从庞大的题目数据库里随机抽取的,那么这个人一次测试的分数很有可能高于他自身能力获得的分数(超常发挥),也可能低于,但是测试若干次,分数会接近他的真实平均水平。
在AB测试中,试验早期用户因为新奇会关注新改动,但是往往前期显著的提升在之后几天或者几周的测试中会逐渐消失。
案例:Airbnb的搜索价格过滤器测试
Airbnb将搜索页上的价格过滤器上限从300美元调大到1000美元,想知道预定数是否会增加。
实验7天新版本提升显著,但是继续运行30天后却发现最终和对照组差别不大。
2.2 以偏概全-实验周期是否覆盖产品高低频用户
如果实验时间跑的太短,没有让高频用户和低频用户都包含在实验里,那么实验结果就只考虑了高频用户的行为。
案例:某健身App对选择课程页面进行A/B测试
高频用户 = 每天(30%)
中频用户 = 每周来至少1次(50%)
低频用户 = 每双周来至少1次(20%)
这个实验时常为3天,并且结果统计显著,但是很明显,三天可能只覆盖了高频用户,得出的结论是以偏概全地。
3.3 辛普森悖论-实验流量分割比例改变带来的结果错误
辛普森悖论(Simpson’s Paradox)是英国统计学家E.H.辛普森(E.H.Simpson)于1951年提出的悖论,即在某个条件下的两组数据,分别讨论时都会满足某种性质,可是一旦合并考虑,却可能导致相反的结论。
举一个辛普森悖论的简单小例子:
男生点击率增加,女生点击率增加,总体为何减少?
因为男女的点击率可能有较大差异,同时低点击率群体的占比增大。 如原来男性20人,点击1人;女性100人,点击99人,总点击率100/120。 现在男性100人,点击6人;女性20人,点击20人,总点击率26/120。
这个诡异(Counter intuitive)的现象在现实生活中经常被忽略,毕竟只是一个统计学现象,一般情况下都不会影响我们的行动。但是对于使用科学的AB测试进行试验的企业决策者来说,如果不了解辛普森悖论,就可能会错误的设计试验,盲目的解读试验结论,对决策产生不利影响。
那么,如何才能在AB测试的设计,实施,以及分析的时候,规避辛普森悖论造成的各种大坑呢?
最重要的一点是,要得到科学可信的AB测试试验结果,就必须合理的进行正确的流量分割,保证试验组和对照组里的用户特征是一致的,并且都具有代表性,可以代表总体用户特征。
案例:微软实验的流量改变
某个周五,微软实验人员为测试中的某版本分配了1%流量,到周六那天,又将流量增加到了50%。
现象:该网站每天有100W访客,虽然在周五和周六这两天,新版本的转化率都高于对照组,但是当数据被汇总时,该版本的总体转化率反而变低了,具体数值如下。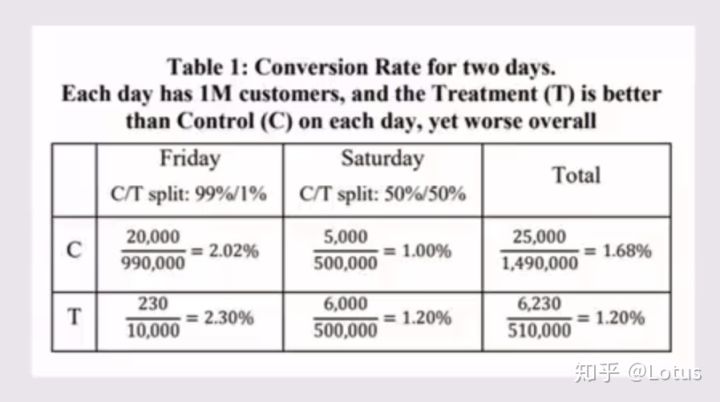
3.4 正交实验-如何同时进行多个实验,保证流量的高可用
此部分参考
推荐系统衡量:ABtest 框架-InfoQwww.infoq.cn
在试验版本的设计过程中还需要考虑线上进行多个试验相互间的影响,譬如在电商的购买流程中我们同时对搜索算法和商品详情页的UI进行优化,这两个变动贯穿在用户的购物流程中,相互之间可能是有影响的,我们需要区分试验中这两种改动带来的影响分别是怎样的。
A/B实验的抽样流量架构需要利用流量分层分流机制来保证流量的高可用,例如如果一个公司需要同时进行十个实验,那么每个实验平均只能分配10%的流量。
流量分层分流机制主要涉及两个概念:正交和互斥,如下图所示
正交示意图: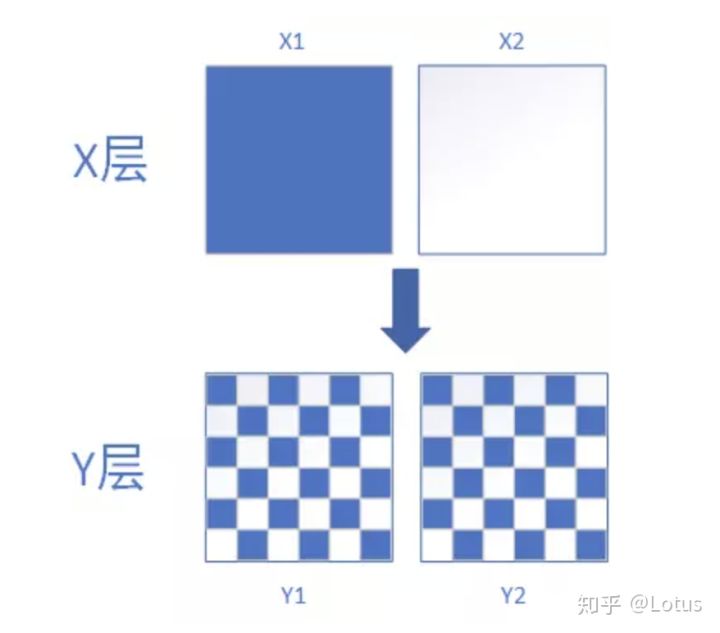
可以看到X层的两份流量,到了Y层会被随机打散。这样层与层之间的流量被称为正交关系。
互斥示意图: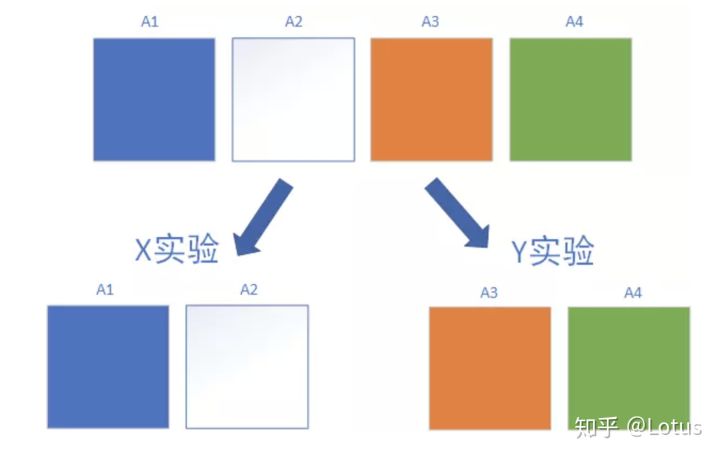
互斥与正交的概念分别对应流量分层分流机制中的域和层的概念,如下图所示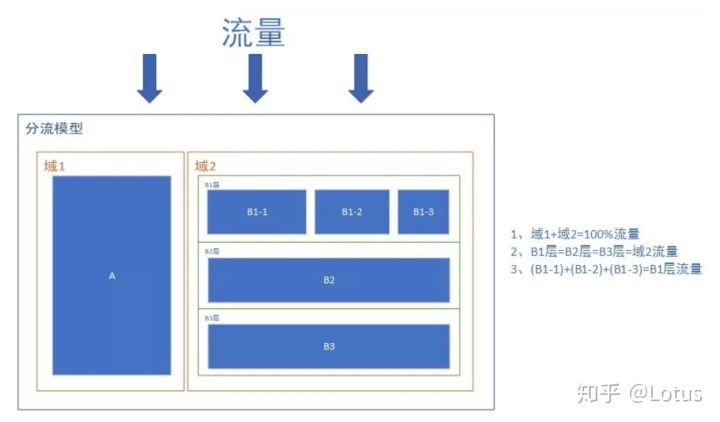
规则解释:
域 1 和域 2 拆分流量,此时域 1 和域 2 是互斥的。
流量流过域 2 中的 B1 层、B2 层、B3 层时,B1 层、B2 层、B3 层的流量都是与域 2 的流量相等(流量的复用)。此时 B1 层、B2 层、B3 层的流量是正交的。
流量流过域 2 中的 B1 层时,又把 B1 层分为了 B1-1 ,B1-2 ,B1-3 ,此时 B1-1 ,B1-2 ,B1-3 之间又是互斥的。
根据以上规则我们可以不断的在此模型中增加域、层,并且可以互相嵌套。这要与实际的业务相匹配,拆分过多的结构可能会把简单的业务复杂化,拆分过少的结构又可能不满足实际业务。
使用场景:
例 1:B1 层、B2 层、B3 层可能分别为:UI 层、搜索结果层、广告结果层,这几层基本上是没有任何的业务关联度的,即使共用相同的流量 ( 流量正交 ) 也不会对实际的业务造成结果。但是如果不同层之间所进行的试验互相关联,如 B1 层是修改的一个页面的按钮文字颜色,B2 层是修改的按钮的颜色,当按钮文字颜色和按钮颜色一样时,该按钮已经是不可用的了。因此同一类型的实验在同一层内进行,并且需要考虑到不同实验互相的依赖。
总结:
流量正交让业务关联度很小的实验有足够的流量同时进行(实现流量的高可用)
流量互斥让业务关联度较大的实验流量分开,避免干扰,保证实验结果的可信度
例 2:域 1 的此种分流的意义在于,当我们做一个实验,并且希望其他任何实验都不能对我实验进行干扰,保证最后实验的可信度。
ps:正交实验也是统计的一个知识点,关于其统计理论以及GoogleA/B实验架构的论文,后续有时间会学习下,作为这个系列第3篇文章的内容。
三.如何分析实验结果背后的原因
如果预期改动的可以提升的某个指标,但是反而降了,该怎么办呢?
这个问题仍是需要具体的业务场景去做分析,这里仅仅介绍下分析思路
1.细分漏斗:看具体是漏斗转化路径上的哪一步与假设不符
2.分维度拆分:
(1)用户分群,对实验结果进行分群分析,看总体实验结果在用户群分解之后是否一致,是否某一个版本在某一类用户表现好,而在另外一类用户里表现差?
(2)分位置拆分:对于点击率实验,可以把页面总体点击率拆分为分位置点击率,然后针对页面内容与用户需求,做一一对应分析
3.用户调研
4.后续实验:针对结果形成新的假设,进行后续实验,验证假设

若有收获,就点个赞吧
0 人点赞
