1 SQL语句的分类
// 1 DQL:数据查询语言:凡是带有select关键字的都是 // 最常用// 2 DML:数据操作语言:对表中数据进行增(insert)删(delete)改(update)// 3 DDL:数据定义语言:对表的结构操作:create(创建),drop(删除),alter(修改)// 4 TCL:事务控制语言:事务提交(submit),事务回滚(rollback)// 5 DCL:数据控制语言:授权(grant),撤销权限revoke.
2 Mysql的架构介绍
1 Linux安装Mysql
[Linux中centos7数据库MySQL5.5]:https://blog.csdn.net/u012402177/article/details/82870433
[mysql5.5中文乱码]:https://developer.aliyun.com/article/41927

1.ntsysv -- 查看开机启动项2 ps -ef|grep mysql -- 查看有mysql字样的目录3 cp /usr/share/mysql/my-huge.conf /etc/my.cnf -- 转入数据

1. show variables like '%char%'; -- 查看可用的编码集
2.
mysql默认的两种存储引擎如下

3 索引优化分析
1 性能下降SQL慢,执行时间长,等待时间长
1 查询语句写的烂
2 索引失效
- 单值索引
create index idx_user_name on user(name); -- 为user表的name字段创建索引,索引名为idx_user_name
- 复合索引
3 关联查询太多的Join(设计缺陷或者不得已的需求)
4 服务器调优以及各个参数的配置(缓冲,线程数等)
2 常见通用的Join查询
- SQL执行顺序
- 机读

- 手写
- 机读
- SQL的Joins:(MySQL不支持FULL OUTER INNER这种语法,ORCLE支持,此时可以使用UNION来拼接两个查找结果)

3 索引简介
索引(Index)是一种帮助MySQK高效获取数据的数据结构(“排好序的快速查找数据结构”)
- 优势:
- 类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本
- 通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗
- 劣势:
- 索引也是一张表,该表保存了主键和索引字段,并指向实体表的记录.,所以索引列也是要占用空间的
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT,UPDATE,和DELETE,都会调整因为更新所带来的键值变化后的索引信息
- 索引只是提高效率的一个因素,如果你的MYSQL有大量的表,就需要花时间研究最优秀的索引或者是优化索引
- 索引类别
- 单值索引:一个索引只包含单个列,一个表可以有多个单列索引
- 唯一索引:索引列的值唯一,但允许空值
- 复合索引:一个索引只包含多个列
- 基本语法:

- MySQL索引结构:
- BTree索引(重要)
- 检索原理
- Hash索引(*)
- full-text全文索引(*)
- R-Tree索引(*)
- BTree索引(重要)
- 哪些情况下需要建立索引?

- 写
- 写
- 写
- 写
- 写
- 写
- 写
- 哪些情况不需要建立索引?

- 写
- 写
4 性能分析(!)
1 MySQL Query Optimizer

2 MySQL常见瓶颈
- CPU:CPU在饱和的时候一般发生在数据装入内存或者从磁盘上读取数据时
- IO:磁盘I/O瓶颈发生在装入数据远大于内存容量的时候
- 服务器硬件的性能瓶颈:top,free,ilstat和vmstat来查看系统的性能状态
3 EXPLAIN
- 是什么?
- 使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理SQL语句的,分析查询语句或是表结构的性能瓶颈
- 能干嘛?
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
- 怎么玩?
Explain + SQL语句 执行之后所包含的信息: id select_type table type possible_keys key key_len ref rows Extra
- 各字段解释
- id:select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
- 如果是同级查询,则id相同,执行顺序由上至下
- 如果是子查询,id序号会递增,id值越大优先级越高,越先被执行
- ID相同不同同时存在
- derived2:衍生出来的表(且id=2)
- id:select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序

- select_type
- table
- type
ALL index range ref eq_ref const,system NULL

2. 访问类型排列<br />
2. 显示查询使用了什么类型,从最好到最差:
- system > const > eq_ref > ref > range > index > ALL
- possible_keys
- 显示应用于与查询语句相关联的索引(一个或者多个),如果查询涉及字段存在索引,则该索引被列出,但是不一定被查询实际使用
- key
- 实际使用的索引,如果为NULL,则没有使用索引
- 查询中使用了覆盖索引,则该索引仅出现在key列表中
- key_len
- ref
- row
- 根据表统计信息以及索引选用情况,大致估算出找到所需的记录所需要读取的行数
- Extra:包含不适合在其他列中显示但是十分重要的额外信息
- 临时表创建拉性能

- 热身CASE
- 单表
- 双表
- 三表


5 索引优化
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上少计算,范围之后全失效;
Like百分写最右,覆盖索引不写星;
不等空值还有or,索引失效要少用;
VAR引号不可丢,SQL高级也不难!
4 查询截取分析
1 慢查询的开启并捕获
2 explain + 慢SQL分析


- 插入千万级别的数据
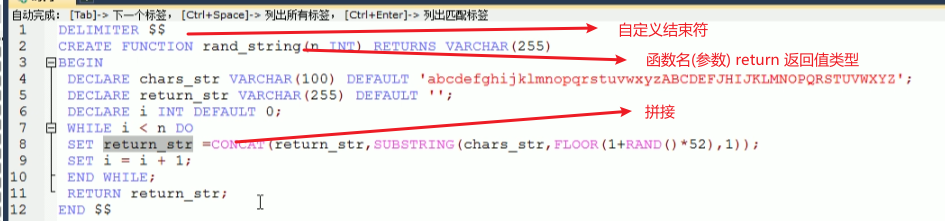
3 show profile查询SQL在MySQL服务器里面的执行细节和生命周期情况
4 SQL数据库服务器的参数调优

提高OrderBy


5 主从复制
6 MySQL锁机制

若有收获,就点个赞吧
0 人点赞
