1.介绍
Cgroups是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO等等)的机制。
2.Cgroups的功能
限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。
进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。
记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间。
进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复。
基本概念:
任务(task)。在cgroups中,任务就是系统的一个进程。
控制族群(control group)。_控制族群就是一组按照某种标准划分的进程。_Cgroups中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用cgroups以控制族群为单位分配的资源,同时受到cgroups以控制族群为单位设定的限制。
层级(hierarchy)。控制族群可以组织成hierarchical的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。
子系统(subsytem)。一个子系统就是一个资源控制器,比如cpu子系统就是控制cpu时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
Rules
一个hierarchy可以有多个 subsystem (mount 的时候hierarchy可以attach多个subsystem)
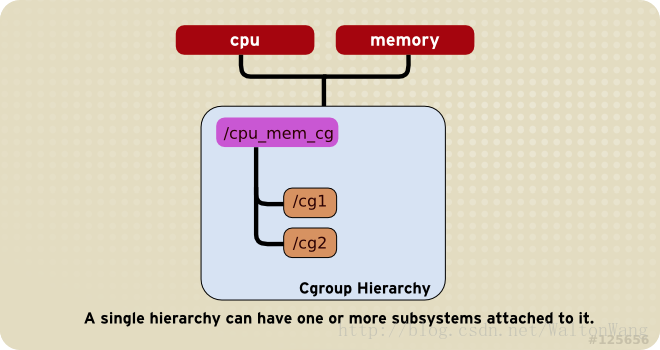
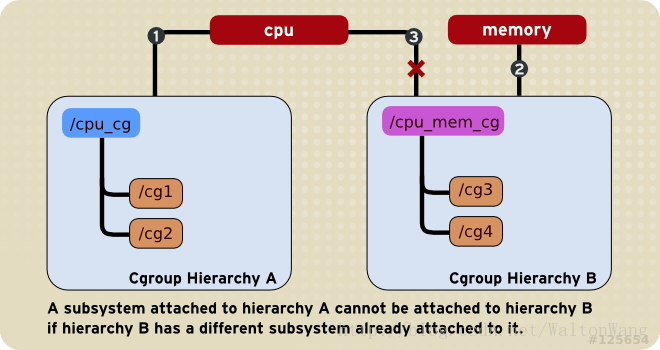
一个已经被挂载的 subsystem 只能被再次挂载在一个空的 hierarchy 上 (已经mount一个subsystem的hierarchy不能挂载一个已经被其它hierarchy挂载的subsystem)。
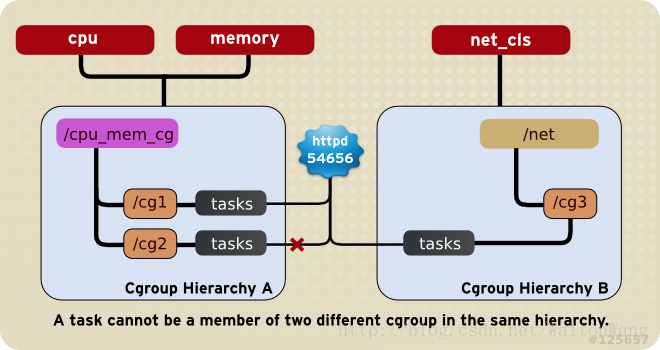
每个task只能在一同个hierarchy的唯一一个cgroup里(不能在同一个hierarchy下有超过一个cgroup的tasks里同时有这个进程的pid)。
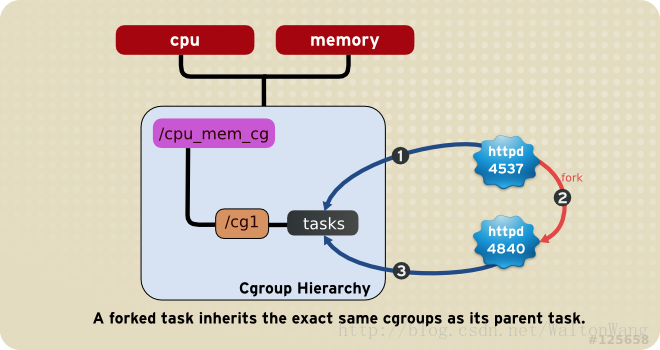
子进程在被fork出时自动继承父进程所在cgroup,但是fork之后就可以按需调整到其他cgroup。
其他
1. 限制一个task的唯一方法就是将其加入到一个cgroup的task里。
2.多个subsystem可以挂载到一个hierarchy里, 然后通过不同的cgroup中的subsystem参数来对不同的task进行限额。
3.如果一个hierarchy有太多subsystem,可以考虑重构 - 将subsystem挂到独立的hierarchy; 相应的, 可以将多个hierarchy合并成一个hierarchy。
4.因为可以只挂载少量subsystem, 可以实现只对task单个方面的限额; 同时一个task可以被加到多个hierarchy中,从而实现对多个资源的控制。
Cgroups层级结构
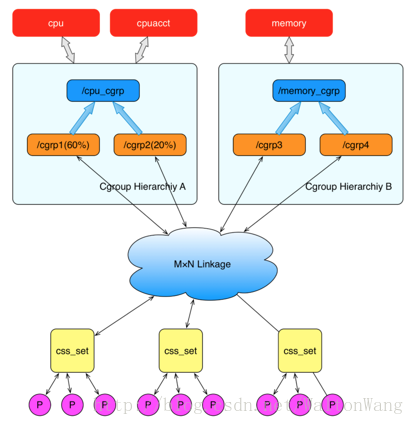
上图中的”M×N Linkage”说明的是css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups 的实现不允许css_set同时关联同一个cgroups层级结构下多个节点。 这是因为 cgroups 对同一种资源不允许有多个限制配置。
一个css_set关联多个 cgroups 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
典型的Cgroups子系统介绍
blkio – 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
cpu – 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
cpuacct – 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
cpuset – 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
devices – 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
freezer – 这个子系统挂起或者恢复 cgroup 中的任务。
memory – 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。
net_cls – 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
ns – 名称空间子系统。
源码分析
如同namespace一样,线程Task的结构体struct task_struct中,必定有cgroups信息:
linux-4.4.19/include/linux/sched.h #1668
struct task_struct{// ...#ifdef CONFIG_CGROUPS/* Control Group info protected by css_set_lock */struct css_set __rcu *cgroups;/* cg_list protected by css_set_lock and tsk->alloc_lock */struct list_head cg_list;#endif// ...}
RCU(Read-Copy Update)是一种linux内核中一种锁机制,顾名思义就是读-拷贝修改,它是基于其原理命名的。对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作。
每个进程中,都对应有一个css_set结构体,css_set其实就是cgroup_subsys_state对象的集合,而每个cgroup_subsys_state代表一个subsystem。下面是css_set结构体的定义:
linux-4.4.19/include/linux/cgroup-defs.h #154
struct css_set {/ Reference count /atomic_t refcount;/** List running through all cgroup groups in the same hash* slot. Protected by css_set_lock*/struct hlist_node hlist;/** Lists running through all tasks using this cgroup group.* mg_tasks lists tasks which belong to this cset but are in the* process of being migrated out or in. Protected by* css_set_rwsem, but, during migration, once tasks are moved to* mg_tasks, it can be read safely while holding cgroup_mutex.*/struct list_head tasks;struct list_head mg_tasks;/** List of cgrp_cset_links pointing at cgroups referenced from this* css_set. Protected by css_set_lock.*/struct list_head cgrp_links;/* the default cgroup associated with this css_set */struct cgroup *dfl_cgrp;/** Set of subsystem states, one for each subsystem. This array is* immutable after creation apart from the init_css_set during* subsystem registration (at boot time).*/struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];/** List of csets participating in the on-going migration either as* source or destination. Protected by cgroup_mutex.*/struct list_head mg_preload_node;struct list_head mg_node;/** If this cset is acting as the source of migration the following* two fields are set. mg_src_cgrp is the source cgroup of the* on-going migration and mg_dst_cset is the destination cset the* target tasks on this cset should be migrated to. Protected by* cgroup_mutex.*/struct cgroup *mg_src_cgrp;struct css_set *mg_dst_cset;/** On the default hierarhcy, ->subsys[ssid] may point to a css* attached to an ancestor instead of the cgroup this css_set is* associated with. The following node is anchored at* ->subsys[ssid]->cgroup->e_csets[ssid] and provides a way to* iterate through all css's attached to a given cgroup.*/struct list_head e_cset_node[CGROUP_SUBSYS_COUNT];/* all css_task_iters currently walking this cset */struct list_head task_iters;/* dead and being drained, ignore for migration */bool dead;/* For RCU-protected deletion */struct rcu_head rcu_head;};
struct cgroup_subsys_state *subsys[CGROUPSUBSYSCOUNT]:一个数组,每个元素指向一个cgroup_subsys_state,这个数组元素与subsystem的个数一一对应。
css_set的初始化发生在kernel boot,从如下代码可见:linux-4.4.19/init/main.c #666
asmlinkage visible void init start_kernel(void){// ...cpuset_init();cgroup_init();// ...}
具体cgroup_init()的实现定义在:linux-4.4.19/kernel/cgroup.c #5318
int __init cgroup_init(void){struct cgroup_subsys *ss;unsigned long key;int ssid;BUG_ON(percpu_init_rwsem(&cgroup_threadgroup_rwsem));BUG_ON(cgroup_init_cftypes(NULL, cgroup_dfl_base_files));BUG_ON(cgroup_init_cftypes(NULL, cgroup_legacy_base_files));mutex_lock(&cgroup_mutex);/* Add init_css_set to the hash table */key = css_set_hash(init_css_set.subsys);hash_add(css_set_table, &init_css_set.hlist, key);BUG_ON(cgroup_setup_root(&cgrp_dfl_root, 0));mutex_unlock(&cgroup_mutex);for_each_subsys(ss, ssid) {if (ss->early_init) {struct cgroup_subsys_state *css =init_css_set.subsys[ss->id];css->id = cgroup_idr_alloc(&ss->css_idr, css, 1, 2,GFP_KERNEL);BUG_ON(css->id < 0);} else {cgroup_init_subsys(ss, false);}list_add_tail(&init_css_set.e_cset_node[ssid],&cgrp_dfl_root.cgrp.e_csets[ssid]);/** Setting dfl_root subsys_mask needs to consider the* disabled flag and cftype registration needs kmalloc,* both of which aren't available during early_init.*/if (cgroup_disable_mask & (1 << ssid)) {static_branch_disable(cgroup_subsys_enabled_key[ssid]);printk(KERN_INFO "Disabling %s control group subsystem\n",ss->name);continue;}cgrp_dfl_root.subsys_mask |= 1 << ss->id;if (!ss->dfl_cftypes)cgrp_dfl_root_inhibit_ss_mask |= 1 << ss->id;if (ss->dfl_cftypes == ss->legacy_cftypes) {WARN_ON(cgroup_add_cftypes(ss, ss->dfl_cftypes));} else {WARN_ON(cgroup_add_dfl_cftypes(ss, ss->dfl_cftypes));WARN_ON(cgroup_add_legacy_cftypes(ss, ss->legacy_cftypes));}if (ss->bind)ss->bind(init_css_set.subsys[ssid]);}WARN_ON(sysfs_create_mount_point(fs_kobj, "cgroup"));WARN_ON(register_filesystem(&cgroup_fs_type));WARN_ON(!proc_create("cgroups", 0, NULL, &proc_cgroupstats_operations));return 0;}
下面,再看看cgroup结构体的定义:linux-4.4.19/include/linux/cgroup-defs.h #226
struct cgroup {/ self css with NULL ->ss, points back to this cgroup /struct cgroup_subsys_state self;unsigned long flags; /* "unsigned long" so bitops work *//** idr allocated in-hierarchy ID.** ID 0 is not used, the ID of the root cgroup is always 1, and a* new cgroup will be assigned with a smallest available ID.** Allocating/Removing ID must be protected by cgroup_mutex.*/int id;/** Each non-empty css_set associated with this cgroup contributes* one to populated_cnt. All children with non-zero popuplated_cnt* of their own contribute one. The count is zero iff there's no* task in this cgroup or its subtree.*/int populated_cnt;struct kernfs_node *kn; /* cgroup kernfs entry */struct cgroup_file procs_file; /* handle for "cgroup.procs" */struct cgroup_file events_file; /* handle for "cgroup.events" *//** The bitmask of subsystems enabled on the child cgroups.* ->subtree_control is the one configured through* "cgroup.subtree_control" while ->child_subsys_mask is the* effective one which may have more subsystems enabled.* Controller knobs are made available iff it's enabled in* ->subtree_control.*/unsigned int subtree_control;unsigned int child_subsys_mask;/* Private pointers for each registered subsystem */struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];struct cgroup_root *root;/** List of cgrp_cset_links pointing at css_sets with tasks in this* cgroup. Protected by css_set_lock.*/struct list_head cset_links;/** On the default hierarchy, a css_set for a cgroup with some* susbsys disabled will point to css's which are associated with* the closest ancestor which has the subsys enabled. The* following lists all css_sets which point to this cgroup's css* for the given subsystem.*/struct list_head e_csets[CGROUP_SUBSYS_COUNT];/** list of pidlists, up to two for each namespace (one for procs, one* for tasks); created on demand.*/struct list_head pidlists;struct mutex pidlist_mutex;/* used to wait for offlining of csses */wait_queue_head_t offline_waitq;/* used to schedule release agent */struct work_struct release_agent_work;};linux-4.4.19/include/linux/cgroup-defs.h #98/*Per-subsystem/per-cgroup state maintained by the system. This is thefundamental structural building block that controllers deal with.Fields marked with "PI:" are public and immutable and may be accesseddirectly without synchronization.*/struct cgroup_subsys_state {/ PI: the cgroup that this css is attached to /struct cgroup *cgroup;/ PI: the cgroup subsystem that this css is attached to /struct cgroup_subsys *ss;/* reference count - access via css_[try]get() and css_put() */struct percpu_ref refcnt;/ PI: the parent css /struct cgroup_subsys_state *parent;/ siblings list anchored at the parent's ->children /struct list_head sibling;struct list_head children;/*PI: Subsys-unique ID. 0 is unused and root is always 1. Thematching css can be looked up using css_from_id().*/int id;unsigned int flags;/*Monotonically increasing unique serial number which defines auniform order among all csses. It's guaranteed that all->children lists are in the ascending order of ->serial_nr andused to allow interrupting and resuming iterations.*/u64 serial_nr;/*Incremented by online self and children. Used to guarantee thatparents are not offlined before their children.*/atomic_t online_cnt;/ percpu_ref killing and RCU release /struct rcu_head rcu_head;struct work_struct destroy_work;}
linux-4.4.19/include/linux/cgroup-defs.h #312
/*A cgroup_root represents the root of a cgroup hierarchy, and may beassociated with a kernfs_root to form an active hierarchy. This isinternal to cgroup core. Don't access directly from controllers.*/struct cgroup_root {struct kernfs_root *kf_root;/ The bitmask of subsystems attached to this hierarchy /unsigned int subsys_mask;/ Unique id for this hierarchy. /int hierarchy_id;/ The root cgroup. Root is destroyed on its release. /struct cgroup cgrp;/ for cgrp->ancestor_ids[0] /int cgrp_ancestor_id_storage;/ Number of cgroups in the hierarchy, used only for /proc/cgroups /atomic_t nr_cgrps;/ A list running through the active hierarchies /struct list_head root_list;/ Hierarchy-specific flags /unsigned int flags;/ IDs for cgroups in this hierarchy /struct idr cgroup_idr;/ The path to use for release notifications. /char release_agent_path[PATH_MAX];/ The name for this hierarchy - may be empty /char name[MAX_CGROUP_ROOT_NAMELEN];};
Cgroup和Task的关联
一个task可以属于多个cgroup,一个cgroup也可以拥有多个task,这种M:N的关系,linux kernel中是通过cgrp_cset_link结构体表示的:linux-4.4.19/kernel/cgroup.c #571
/*A cgroup can be associated with multiple css_sets as different tasks maybelong to different cgroups on different hierarchies. In the otherdirection, a css_set is naturally associated with multiple cgroups.This M:N relationship is represented by the following link structurewhich exists for each association and allows traversing the associationsfrom both sides.*/struct cgrp_cset_link {/ the cgroup and css_set this link associates /struct cgroup *cgrp;struct css_set *cset;/ list of cgrp_cset_links anchored at cgrp->cset_links /struct list_head cset_link;/ list of cgrp_cset_links anchored at css_set->cgrp_links /struct list_head cgrp_link;};
这个结构其实就是一个link,cgrp就是这个link关联的cgroup,cset属于一个task,于是可以代表一个进程。
而cset_link是给struct cgroup查找struct cgrp_cset_link用的。那么怎么找呢?
我们首先来看如何把一个cgroup与一个css_set关联起来:linux-4.4.19/kernel/cgroup.c #969
/**link_css_set - a helper function to link a css_set to a cgroup@tmp_links: cgrp_cset_link objects allocated by allocate_cgrp_cset_links()@cset: the css_set to be linked@cgrp: the destination cgroup*// link_css_set函数的功能就是把一个css_set与一个cgroup通过struct /cgrp_cset_link联系起来。static void link_css_set(struct list_head tmp_links, struct css_set cset, struct cgroup *cgrp){struct cgrp_cset_link *link;BUG_ON(list_empty(tmp_links));if (cgroup_on_dfl(cgrp))cset->dfl_cgrp = cgrp;// 从已经分配好的一个cgrp_cset_link链表(表头为tmp_links)中拿一个出来,填上cgroup与css_set的指针link = list_first_entry(tmp_links, struct cgrp_cset_link, cset_link);link->cset = cset;link->cgrp = cgrp;// 把这个cgrp_cset_link从原来的链表中移出来,加入到cgrp(这个就是那个cgroup)的cset_links链表中list_move_tail(&link->cset_link, &cgrp->cset_links);// 把cgrp_cset_link的cgrp_link加入到cset的cgrp_links链表中list_add_tail(&link->cgrp_link, &cset->cgrp_links);if (cgroup_parent(cgrp))cgroup_get(cgrp);}
上面注释中提到,用于分配cgrp_cset_link(表头为tmp_links)的函数是allocate_cgrp_cset_links,其定义如下:
linux-4.4.19/kernel/cgroup.c #945
- ```objectivec /** allocate_cgrp_cset_links - allocate cgrp_cset_links @count: the number of links to allocate @tmp_links: list_head the allocated links are put on
Allocate @count cgrp_cset_link structures and chain them on @tmp_links through ->cset_link. Returns 0 on success or -errno. / static int allocate_cgrp_cset_links(int count, struct list_head tmp_links) { struct cgrp_cset_link *link; int i;
INIT_LIST_HEAD(tmp_links);
for (i = 0; i < count; i++) { link = kzalloc(sizeof(*link), GFP_KERNEL); if (!link) { free_cgrp_cset_links(tmp_links); return -ENOMEM; } list_add(&link->cset_link, tmp_links); } return 0; }
这个函数很简单,就是申请count个struct cgrp_cset_link,同时把它们一个个加到tmp_links这个链表里。这count的数据结构是通过struct cgrp_cset_link->cset_link连接起来的,但是前面说到这个变量是给struct cgroup用的。这是因为目前分配出来的这些个数据结构只是临时的,也就是说暂时借用一下这个变量,到后面会再来恢复这个变量的本来用途。这也是为什么link_css_set函数中cgrp_link成员用list_add,而cset_link用list_move。<br />于是,可以用下图来表示allocate_cgrp_cset_links的结果:<br />而link_css_set的结果则可以用下图来表示:<br />这张图也解释了linux代码中如何表现cgroup与subsystem之间多对多的关系。每个struct cgroup可以通过cgroup->cset_links和cgrp_cset_link->cset_link找到一串struct cgrp_cset_link,每个struct cgrp_cset_link都有着对应的css_set,这个css_set属于一个tast_struct(其实是多个),其中包含着subsystem。于是通过遍历链表就能找到这个cgroup对应的所有task(其实找到的是css_set,但是对于Cgroups这个模块来说,关心的并不是task_struct,而是这个css_set)。反之亦然,通过task_struct的cgroups变量(类型为struct css_set*)就能找到这个进程属于的所有cgroup。例如,给定一个task,我们想找到这个task在某个hierarchy中的cgroup,就可以调用如下函数:linux-4.4.19/kernel/cgroup.c #1194```objectivec/*Return the cgroup for "task" from the given hierarchy. Must becalled with cgroup_mutex and css_set_lock held.*/static struct cgroup task_cgroup_from_root(struct task_struct task,struct cgroup_root *root){/*No need to lock the task - since we hold cgroup_mutex thetask can't change groups, so the only thing that can happenis that it exits and its css is set back to init_css_set.*/return cset_cgroup_from_root(task_css_set(task), root);}
linux-4.4.19/kernel/cgroup.c #1163
/ look up cgroup associated with given css_set on the specified hierarchy /static struct cgroup cset_cgroup_from_root(struct css_set cset,struct cgroup_root *root){struct cgroup *res = NULL;lockdep_assert_held(&cgroup_mutex);lockdep_assert_held(&css_set_lock);if (cset == &init_css_set) {res = &root->cgrp;} else {struct cgrp_cset_link *link;list_for_each_entry(link, &cset->cgrp_links, cgrp_link) {struct cgroup *c = link->cgrp;if (c->root == root) {res = c;break;}}}BUG_ON(!res);return res;}
Cgroup与subsystem
linux-4.4.19/include/linux/cgroupsubsys.h中定义了所有的subsystem。
可以看到,共有cpuset, debug, cpu, cpuacct, memory, devices, freezer, netcls, blkio, perfevent, netprio, hugtlb等12个.
cpu subsystem
struct task_group就是cpu subsystem对应的子类, 代码见:linux-4.4.19/kernel/sched/sched.h #240
/ task group related information /struct task_group {struct cgroup_subsys_state css;#ifdef CONFIG_FAIR_GROUP_SCHED/ schedulable entities of this group on each cpu /struct sched_entity **se;/ runqueue "owned" by this group on each cpu /struct cfs_rq **cfs_rq;unsigned long shares;#ifdef CONFIG_SMPatomic_long_t load_avg;#endif#endif#ifdef CONFIG_RT_GROUP_SCHEDstruct sched_rt_entity **rt_se;struct rt_rq **rt_rq;struct rt_bandwidth rt_bandwidth;#endifstruct rcu_head rcu;struct list_head list;struct task_group *parent;struct list_head siblings;struct list_head children;#ifdef CONFIG_SCHED_AUTOGROUPstruct autogroup *autogroup;#endifstruct cfs_bandwidth cfs_bandwidth;};
Cgroups通过VFS来和用户打交道, 用户通过将各个subsystem mount到某个目录下之后, cgroup文件系统会自动创建一系列虚拟文件, 用户通过向不同的文件读写数据控制Cgroups的行为. 具体对CPU subsystem来说, 有一个tasks文件, 向其中写入一些进程的pid, 就能将这些进程加入到这个cgroup. 另外还有个cpu.shares的文件, 向其中写入一个数字后就能设置这个cgroup的进程的weight.
每个文件系统(包括Cgroups对应的cgroup文件系统)拥有一个数据结构, 其中有一系列函数指针, 当对这个文件系统进行读写操作时, 内核会调用这个文件系统的对应函数指针. 因此当向一个VFS的文件写入数据时, 可以在这个函数指针指向的函数做一些其他事情. 具体对于CPU subsystem, 当向cpu.shares写入一个数字时, 内核执行的函数干的事情是修改这个cgroup对应的struct task_group中的shares变量. 这个函数是:
linux-4.4.19/kernel/sched/core.c #8270
static int cpu_shares_write_u64(struct cgroup_subsys_state *css,struct cftype *cftype, u64 shareval){return sched_group_set_shares(css_tg(css), scale_load(shareval));}
其中, csstg函数是找到具体的subsystem子类, 这里就是struct taskcgroup. schedgroupset_shares这个函数的定义如下:
linux-4.4.19/kernel/sched/fair.c #8223
int sched_group_set_shares(struct task_group *tg, unsigned long shares){int i;unsigned long flags;/** We can't change the weight of the root cgroup.*/if (!tg->se[0])return -EINVAL;shares = clamp(shares, scale_load(MIN_SHARES), scale_load(MAX_SHARES));mutex_lock(&shares_mutex);if (tg->shares == shares)goto done;tg->shares = shares;for_each_possible_cpu(i) {struct rq *rq = cpu_rq(i);struct sched_entity *se;se = tg->se[i];/* Propagate contribution to hierarchy */raw_spin_lock_irqsave(&rq->lock, flags);/* Possible calls to update_curr() need rq clock */update_rq_clock(rq);for_each_sched_entity(se)update_cfs_shares(group_cfs_rq(se));raw_spin_unlock_irqrestore(&rq->lock, flags);}done:mutex_unlock(&shares_mutex);return 0;}
for_each_sched_entity(se)遍历这个task_group管理的所有进程的sched_entity, 然后在updatecfs_shares里, 经过层层函数调用, 最终执行了两句代码:linux-4.4.19/kernel/sched/fair.c #129
static inline void update_load_set(struct load_weight *lw, unsigned long w){lw->weight = w;lw->inv_weight = 0;}
附录:
subsystem配置
blkio - BLOCK IO限额
common
blkio.reset_stats - 重置统计信息,写int到此文件
blkio.time - 统计cgroup对设备的访问时间 - device_types:node_numbers milliseconds
blkio.sectors - 统计cgroup对设备扇区访问数量 - device_types:node_numbers sector_count
blkio.avg_queue_size - 统计平均IO队列大小(需要CONFIG_DEBUG_BLK_CGROUP=y)
blkio.group_wait_time - 统计cgroup等待总时间(需要CONFIG_DEBUG_BLK_CGROUP=y, 单位ns)
blkio.empty_time - 统计cgroup无等待io总时间(需要CONFIG_DEBUG_BLK_CGROUP=y, 单位ns)
blkio.idle_time - reports the total time (in nanoseconds — ns) the scheduler spent idling for a cgroup in anticipation of a better request than those requests already in other queues or from other groups.
blkio.dequeue - 此cgroup IO操作被设备dequeue次数(需要CONFIG_DEBUG_BLK_CGROUP=y) - device_types:node_numbers number
blkio.io_serviced - 报告CFQ scheduler统计的此cgroup对特定设备的IO操作(read, write, sync, or async)次数 - device_types:node_numbers operation number
blkio.io_service_bytes - 报告CFQ scheduler统计的此cgroup对特定设备的IO操作(read, write, sync, or async)数据量 - device_types:node_numbers operation bytes
blkio.io_service_time - 报告CFQ scheduler统计的此cgroup对特定设备的IO操作(read, write, sync, or async)时间(单位ns) - device_types:node_numbers operation time
blkio.io_wait_time - 此cgroup对特定设备的特定操作(read, write, sync, or async)的等待时间(单位ns) - device_types:node_numbers operation time
blkio.io_merged - 此cgroup的BIOS requests merged into IO请求的操作(read, write, sync, or async)的次数 - number operation
blkio.io_queued - 此cgroup的queued IO 操作(read, write, sync, or async)的请求次数 - number operation
Proportional weight division 策略 - 按比例分配block io资源
blkio.weight - 100-1000的相对权重,会被blkio.weight_device的特定设备权重覆盖
blkio.weight_device - 特定设备的权重 - device_types:node_numbers weight
I/O throttling (Upper limit) 策略 - 设定IO操作上限
每秒读/写数据上限
blkio.throttle.read_bps_device - device_types:node_numbers bytes_per_second blkio.throttle.write_bps_device - device_types:node_numbers bytes_per_second
每秒读/写操作次数上限
blkio.throttle.read_iops_device - device_types:node_numbers operations_per_second blkio.throttle.write_iops_device - device_types:node_numbers operations_per_second
每秒具体操作(read, write, sync, or async)的控制
blkio.throttle.io_serviced - device_types:node_numbers operation operations_per_second blkio.throttle.io_service_bytes - device_types:node_numbers operation bytes_per_second
cpu - CPU使用时间限额
CFS(Completely Fair Scheduler)策略 - CPU最大资源限制
cpu.cfs_period_us, cpu.cfs_quota_us - 必选 - 二者配合,前者规定时间周期(微秒)后者规定cgroup最多可使用时间(微秒),实现task对单个cpu的使用上限(cfs_quota_us是cfs_period_us的两倍即可限定在双核上完全使用)。
cpu.stat - 记录cpu统计信息,包含 nr_periods(经历了几个cfs_period_us), nr_throttled (cgroup里的task被限制了几次), throttled_time (cgroup里的task被限制了多少纳秒)
cpu.shares - 可选 - cpu轮转权重的相对值
RT(Real-Time scheduler)策略 - CPU最小资源限制
cpu.rt_period_us, cpu.rt_runtime_us
二者配合使用规定cgroup里的task每cpu.rt_period_us(微秒)必然会执行cpu.rt_runtime_us(微秒)
cpuacct - CPU资源报告
cpuacct.usage - cgroup中所有task的cpu使用时长(纳秒)
cpuacct.stat - cgroup中所有task的用户态和内核态分别使用cpu的时长
cpuacct.usage_percpu - cgroup中所有task使用每个cpu的时长
cpuset - CPU绑定
cpuset.cpus - 必选 - cgroup可使用的cpu,如0-2,16代表 0,1,2,16这4个cpu
cpuset.mems - 必选 - cgroup可使用的memory node
cpuset.memory_migrate - 可选 - 当cpuset.mems变化时page上的数据是否迁移, default 0
cpuset.cpu_exclusive - 可选 - 是否独占cpu, default 0
cpuset.mem_exclusive - 可选 - 是否独占memory,default 0
cpuset.mem_hardwall - 可选 - cgroup中task的内存是否隔离, default 0
cpuset.memory_pressure - 可选 - a read-only file that contains a running average of the memory pressure created by the processes in this cpuset
cpuset.memory_pressure_enabled - 可选 - cpuset.memory_pressure开关,default 0
cpuset.memory_spread_page - 可选 - contains a flag (0 or 1) that specifies whether file system buffers should be spread evenly across the memory nodes allocated to this cpuset, default 0
cpuset.memory_spread_slab - 可选 - contains a flag (0 or 1) that specifies whether kernel slab caches for file input/output operations should be spread evenly across the cpuset, default 0
cpuset.sched_load_balance - 可选 - cgroup的cpu压力是否会被平均到cpu set中的多个cpu, default 1
cpuset.sched_relax_domain_level - 可选 - cpuset.sched_load_balance的策略
-1 = Use the system default value for load balancing
0 = Do not perform immediate load balancing; balance loads only periodically
1 = Immediately balance loads across threads on the same core
2 = Immediately balance loads across cores in the same package
3 = Immediately balance loads across CPUs on the same node or blade
4 = Immediately balance loads across several CPUs on architectures with non-uniform memory access (NUMA)
5 = Immediately balance loads across all CPUs on architectures with NUMA
device - cgoup的device限制
设备黑/白名单
devices.allow - 允许名单
devices.deny - 禁止名单语法 - type device_types:node_numbers access type - b (块设备) c (字符设备) a (全部设备) access - r 读 w 写 m 创建
devices.list - 报告
freezer - 暂停/恢复 cgroup的限制
不能出现在root目录下
freezer.state - FROZEN 停止 FREEZING 正在停止 THAWED 恢复
memory - 内存限制
memory.usage_in_bytes - 报告内存限制byte
memory.memsw.usage_in_bytes - 报告cgroup中进程当前所用内存+swap空间
memory.max_usage_in_bytes - 报告cgoup中的最大内存使用
memory.memsw.max_usage_in_bytes - 报告最大使用到的内存+swap
memory.limit_in_bytes - cgroup - 最大内存限制,单位k,m,g. -1代表取消限制
memory.memsw.limit_in_bytes - 最大内存+swap限制,单位k,m,g. -1代表取消限制
memory.failcnt - 报告达到最大允许内存的次数
memory.memsw.failcnt - 报告达到最大允许内存+swap的次数
memory.force_empty - 设为0且无task时,清除cgroup的内存页
memory.swappiness - 换页策略,60基准,小于60降低换出机率,大于60增加换出机率
memory.use_hierarchy - 是否影响子group
memory.oom_control - 0 enabled,当oom发生时kill掉进程
memory.stat - 报告cgroup限制状态
cache - page cache, including tmpfs (shmem), in bytes
rss - anonymous and swap cache, not including tmpfs (shmem), in bytes
mapped_file - size of memory-mapped mapped files, including tmpfs (shmem), in bytes
pgpgin - number of pages paged into memory
pgpgout - number of pages paged out of memory
swap - swap usage, in bytes
active_anon - anonymous and swap cache on active least-recently-used (LRU) list, including tmpfs (shmem), in bytes
inactive_anon - anonymous and swap cache on inactive LRU list, including tmpfs (shmem), in bytes
active_file - file-backed memory on active LRU list, in bytes
inactive_file - file-backed memory on inactive LRU list, in bytes
unevictable - memory that cannot be reclaimed, in bytes
hierarchical_memory_limit - memory limit for the hierarchy that contains the memory cgroup, in bytes
hierarchical_memsw_limit - memory plus swap limit for the hierarchy that contains the memory cgroup, in bytes
net_cls
- net_cls.classid - 指定tc的handle,通过tc实现网络控制
net_prio 指定task网络设备优先级
net_prio.prioidx - a read-only file which contains a unique integer value that the kernel uses as an internal representation of this cgroup.
net_prio.ifpriomap - 网络设备使用优先级 -
其他
tasks - 该cgroup的所有进程pid
cgroup.event_control - event api
cgroup.procs - thread group id
release_agent(present in the root cgroup only) - 根据- notify_on_release是否在task为空时执行的脚本
notify_on_release - 当cgroup中没有task时是否执行release_agent

若有收获,就点个赞吧
0 人点赞
