group by gender

行转列SQL练习
题目
把图1转换成图2结果展示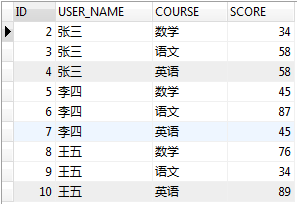
图1
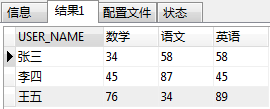
CREATE TABLE `TEST_TB_GRADE` (`ID` int(10) NOT NULL AUTO_INCREMENT,`USER_NAME` varchar(20) DEFAULT NULL,`COURSE` varchar(20) DEFAULT NULL,`SCORE` float DEFAULT '0',PRIMARY KEY (`ID`))insert into TEST_TB_GRADE(USER_NAME, COURSE, SCORE) values("张三", "数学", 34),("张三", "语文", 58),("张三", "英语", 58),("李四", "数学", 45),("李四", "语文", 87),("李四", "英语", 45),("王五", "数学", 76),("王五", "语文", 34),("王五", "英语", 89);
参考答案
selectUSER_NAME,sum(if(COURSE='数学',SCORE,0)) as '数学',sum(if(COURSE='英语',SCORE,0)) as '英语',sum(if(COURSE='语文',SCORE,0)) as '语文'from TEST_TB_GRADEgroup by USER_NAME;
求某ID的所有子结点
题目
给一个 表 , 有 ID 和 PARENT_ID 两个字段 , 然后求某ID的所有子结点
| ID | PARENT_ID |
|---|---|
| 900 | NULL |
| 9011 | 901 |
| 9012 | 901 |
| 9013 | 9012 |
| 9014 | 9013 |
比如 求 901 的所有子结点结果为:9011901290139014
参考
with temp as(select * from table_name where PARENT_ID = '901'union allselect t0.* from temp,table_name t0 where temp.ID=t0.PARENT_ID)select ID from temp;
用SQL求中位数
题目
在不使用现成的中位数函数情况下,统计男生和女生分别成绩的中位数是多少?
| name | gender | score |
|---|---|---|
| A | 男 | 2 |
| B | 男 | 3 |
| C | 女 | 2 |
| D | 女 | 3 |
| E | 女 | 2 |
参考
select gender,avg(score)from(select gender,score,row_number() over(partition by gender order by score) as rn,count(*) over(partition by gender) as nfrom tmp)as twhere rn in (floor(n/2)+1,if(mod(n,2) = 0,floor(n/2),floor(n/2)+1))group by gender;
selectgender,avg(score) scorefrom (selectgender,score,count(0) over (partition by gender) cnt_all ,row_number() over(partition by gender order by score) rnfrom test) twhere t.rn >= round(t.cnt_all/2.0) and t.rn <= round(t.cnt_all/2.0+0.5)group by gender ;
with tmp_d as (select 'A' name , '男' gender, '2' scorefrom dualunion allselect 'B', '男', '3'from dualunion allselect 'C', '女', '2'from dualunion allselect 'D', '女', '3'from dualunion allselect 'E', '女', '2'from dual)SELECT /*+parallel(t,4)*/ tc.gender,sum(tc.score)/count(*) 中位数from (SELECT /*+parallel(t,4)*/ t.name,t.gender,t.score,case when mod(count(*)over(partition by t.gender order by t.scorerows between unbounded preceding and UNBOUNDED FOLLOWING) ,2)=0 then 1 else 0 end if_o,count(*)over(partition by t.gender order by t.scorerows between unbounded preceding and UNBOUNDED FOLLOWING) counts,row_number() over(partition by t.gender order by t.score )rnnfrom tmp_d t)tc-- 则当N为奇数时 N/2,;当N为偶数时:N/2 + (N/2+1) 两个值相加/2where (tc.if_o = 1 and (tc.rnn =counts/2 or tc.rnn =counts/2 +1 ))or (tc.if_o = 0 and ceil(tc.counts/2) = tc.rnn)group by tc.gender
一分一段
题目
- 考生分数倒序(分数由高到低)。
- 一分一档次统计人数。
- 结果展示一分为一段累加人数(你可以理解大于等于这个分段的人数)。
注意点:
(1)分数相同的则为并列 与 累计人数。
(2)模拟数据少,需要考虑周全的是:中间不是连续递减分数,没有的需要补齐。
简单罗列字段
| 字段列 | 数据类型 | 描述 |
|---|---|---|
| id | bigint | 序号 |
| stu_no | string | 考生号 |
| score | int | 成绩 |
模拟数据
| id | stu_no | score |
|---|---|---|
| 1 | 100001 | 690 |
| 2 | 100002 | 690 |
| 3 | 100003 | 688 |
| 4 | 100004 | 687 |
| 5 | 100005 | 687 |
| 6 | 100006 | 686 |
| 7 | 100007 | 686 |
| 8 | 100008 | 686 |
| 9 | 100009 | 685 |
| 10 | 100010 | 689 |
| 11 | 100011 | 684 |
| 12 | 100012 | 684 |
目标的结果
| 分数 | 考生人数 |
|---|---|
| 690 | 2 |
| 689 | 3 |
| 688 | 4 |
| 687 | 6 |
| 686 | 9 |
| 685 | 10 |
| 684 | 12 |
| 683 | 12 |
| 682 | 13 |
| 681 | 13 |
| 680 | 14 |
| 679 | 15 |
参考
insert into henan_gaokao_scorevalues((1,'100001', 690),(2,'100002',690),(3 ,'100003',688),(4 ,'100004',687),(5 ,'100005',687),(6 ,'100006',686),(7 ,'100007', 686),(8,'100008',686),(9 ,'100009',685),(10 ,'100010',689),(11 ,'100011',684),(12 ,'100012',684),(13 ,'100013',682),(14 ,'100014',679));
初始化维表
这里需要初始化一张维表,模拟记录 0-750分的 751条数据,作为分数段。(考虑点:如果不借助维表,单表操作你怎么做?)
数据生成方式很多,我罗列以下几个:
insert into score_batch(id,score)values((1,690),(2,689),(3,688),(4,687),(5,686),(6,685),(7,684),(8,683),(9,682),(10,681),(11,680),(12,679),(13,678));
SQL
selectt.score 分数,sum(t.cnt) over(order by t.score desc rows between UNBOUNDED PRECEDING and current row) 位次from(selectsb.score score,NVL(sc.cnt,0) cntfrom score_batch sbleft join(selectscore,count(1) cnt,min(score) min_score,max(score) max_scorefrom henan_gaokao_scoregroup by score) sc on sc.score = sb.scoreand sb.score>=sc.min_scoreand sb.score<=sc.max_score) t;
连续升级多少次
题目
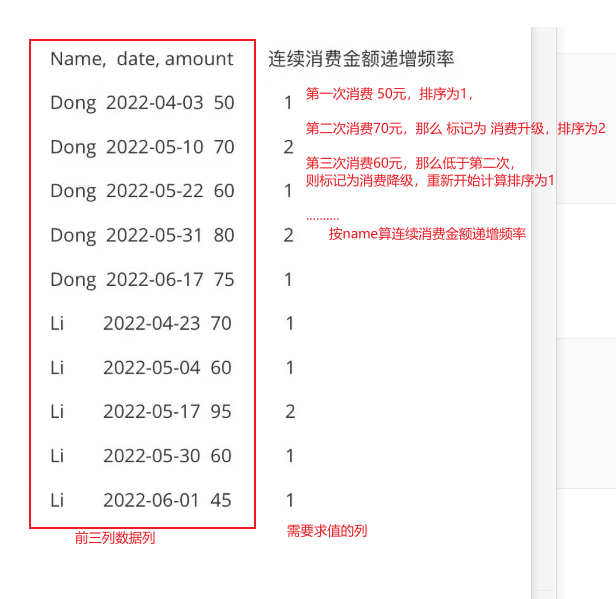
第一次消费 50元,排序为1,第二次消费70元,那么 标记为 消费升级,排序为2
第三次消费60元,那么低于第二次,则标记为消费降级,重新开始计算排序为1
模拟数据
CREATE TABLE consume(id bigint ,name STRING ,stat_date string,amount bigint)....;insert into table consume values(1,'dong','2022-04-03',50),(2,'dong','2022-05-10',70),(3,'dong','2022-05-22',60),(4,'dong','2022-05-31',80),(5,'dong','2022-06-17',75),(6,'wang','2022-04-23',70),(7,'wang','2022-05-04',60),(8,'wang','2022-05-17',95),(9,'wang','2022-05-31',60),(10,'wang','2022-06-17',55)(11,'dong','2022-05-20',80);
参考
select*,ROW_NUMBER() over (partition by name, row2 order by `date`) as row3from (select*,sum(lags) over(partition by name order by `date`) as row2from (select *,if((amount - lag(amount) over(partition by name order by `date`))<0,1,0) as lagsfrom consume) a) border by b.`date`;
驾驶车辆的风格
求 驾驶者的驾驶车辆风格
提示:从速度、加速度 的极值、均值 等方向 去答题描述
| user_id | record_time | distance |
|---|---|---|
| u1 | 2022-06-01 00:00:01 | 0 |
| u1 | 2022-06-01 00:00:06 | 50 |
| u1 | 2022-06-01 00:00:11 | 160 |
| u1 | 2022-06-01 00:00:16 | 700 |
| …. | …. | …. |
| u1 | 2022-06-01 00:25:01 | 192300 |
数据扩充
| a |
|---|
| 3 |
| 2 |
| 4 |
结果
| a | b |
|---|---|
| 3 | 3,2,1 |
| 2 | 2,1 |
| 4 | 4,3,21 |
转多行
| a | b | c |
|---|---|---|
| 001 | 3,2,1 | 1/3/5 |
| 002 | 2,1 |
结果
| a | d | e |
|---|---|---|
| 001 | type_b | A |
| 001 | type_c | B |
| 001 | type_c | 1 |
| 001 | type_c | 3 |
| 001 | type_c | 5 |
| 002 | type_b | B |
| 002 | type_b | C |
| 002 | type_b | D |
| 002 | type_c | 4 |
| 002 | type_c | 5 |

若有收获,就点个赞吧
0 人点赞
