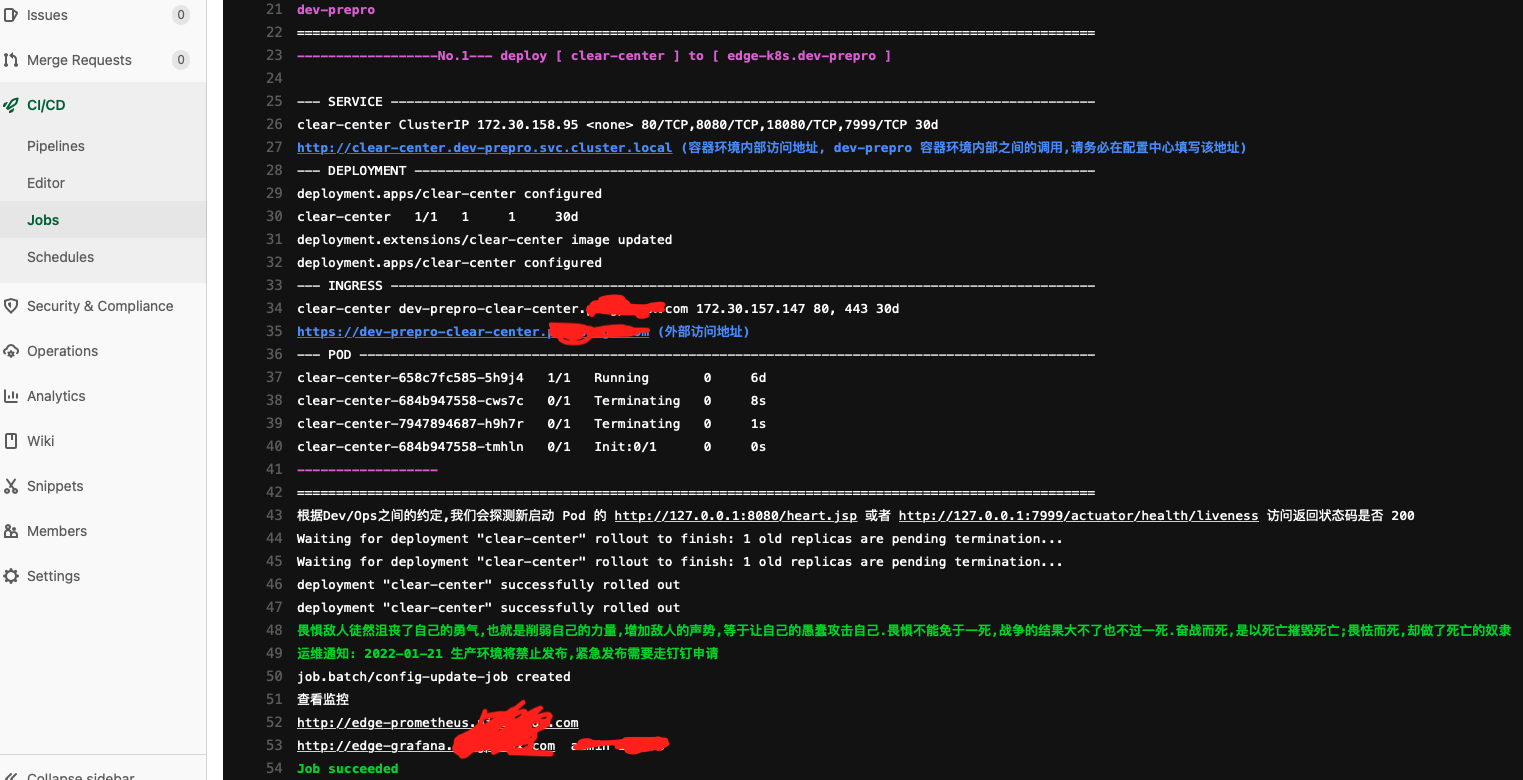
这就是 dev push 代码, 触发 ci / cd 后,先自动创建 service, deployment, ingress , 再完成健康检测, 最好执行 prometheus 更新监控采集对象的 job
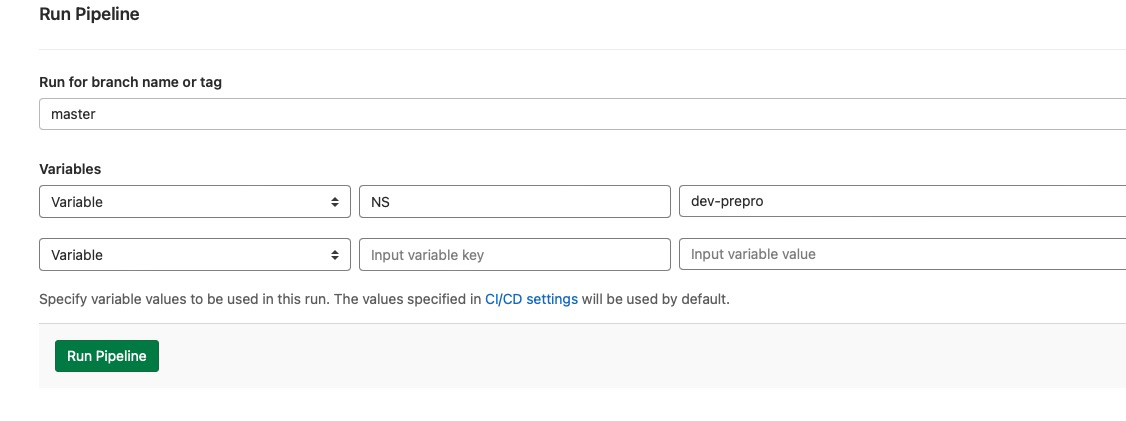
或者在 CI_COMMIT_MESSAGE 中带关键字: NS = xxx, 那么push 的时候就是自动触发
我们和 dev 约定了, 默认项目业务监控数据暴露在 7999 端口
所以我们每次发布后,新增动作 执行 一个 job 这个job 就探测 发布的 namespace 里面 service 7999 端口数据是否 200, 是,则更新 生成 监控采集配置文件,落盘在 挂载的 PV,这个PV 和 该 k8s 的 prometheus PV 一致
规划给每一个 k8s , 一个独立的 Namespace base-ops ,给予部署基础组件
比如目前我把 prometheus 体系部署在 base-ops
里面有
- node-exporter ( DaemonSet ) 这个会自动的把 node-exporter 分布在各个 Node 机器, 负责采集主机监控数据,然后上报给 prometheus 服务端; 我上面提到我们的业务启动的时候,同时也暴露了 7999 端口数据,也是一样的意思,
暴露数据,让 prometheus 定时采集
所以这里大家的核心痛点就是,如何全自动的配置监控对象 prometheus/conf/node/targets.yml 和 prometheus/conf/service/targets.yml - prometheus ( 监控系统的服务端,依照配置的监控对象文件,主动的定时拉取监控对象的监控数据)
- alertmanager (报警器,根据 prometheus 拉取的监控数据,匹配预设的报警规则,触发报警 —-> webhook —-> 钉钉/微信/电话 )
- grafana ( 这个相对比较独立,就是给 prometheus 套一个皮,然后配置一些可视化的监控图表)
上面组合方案,有很多动作
- CI/CD 的时候,根据发布的NS, 自动给予创建 PV/PVC
- 判断当前集群是否存在 base-ops , 没有则从源头复制模版,下发创建 base-ops/prometheus
- 业务发布的时候,最后一步,删除 config-update-job.yml 然后再 apply, 更新监控对象配置

若有收获,就点个赞吧
0 人点赞
