关于零拷贝的概念,需要先了解一下操作系统层面是如何处理IO的,当发送一段数据时,数据在操作系统中又是如何流转的呢。
用户态和内核态
Linux操作系统的体系架构分为用户态(用户空间)和内核态(内核)。内核从本质上是一种软件:控制计算机的硬件资源,并为上层应用程序提供运行环境。
用户态即上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口,即系统调用。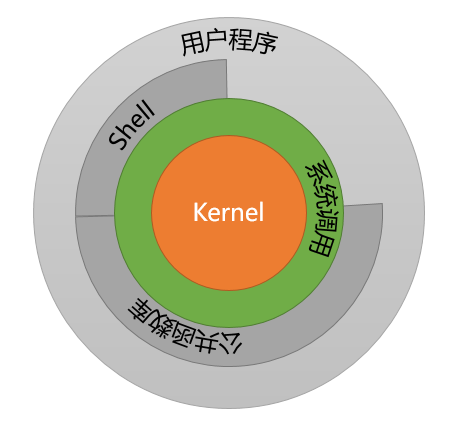
系统的资源是有限的,如果不加以管理,必然造成资源过多消耗和访问冲突。为了控制关键资源的访问,Linux把程序划分为不同的执行等级,即特权的概念。x86架构的CPU提供了0到3四个特权级,数字越小,特权越高,Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态和用户态。
用户态的进程可以执行的操作和访问的资源都会受到限制;内核态的进程则可以执行任何操作并且在资源的使用上没有限制。用户程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,就需要通过系统调用把系统从用户态切换到内核态。比如C语言的内存分配函数malloc(),是通过sbrk()系统调用来分配内存,从malloc到sbrk()的调用就涉及从用户态到内核态的切换,类似函数printf()调用的是wirte()系统调用。
标准I/O(BufferIO)
标准IO又被称作缓存IO,是大多数文件系统的默认IO操作。在Linux的缓存IO机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。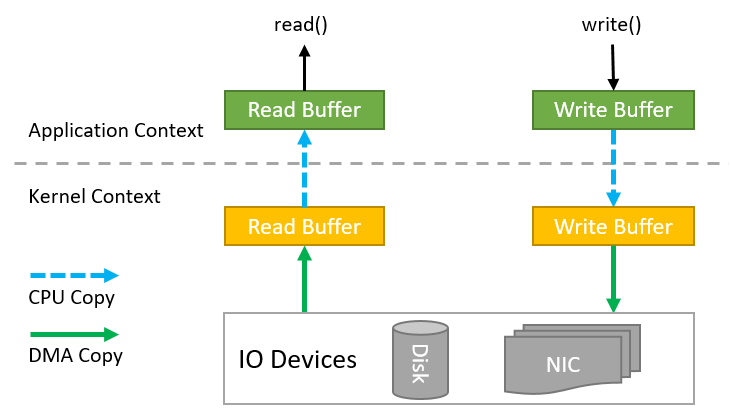
读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从内核换成拷贝到用户程序换成,并返回;否则从磁盘中读取,先缓存在内核缓存区,再返回。
写操作:将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
缓存IO的优点:
- 在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全
- 可以减少读盘的次数,从而提高性能
缓存IO的缺点: 在缓存IO机制中,DMA方式可以将数据直接从磁盘读到内核缓存中,或者将数据从缓存直接写回到磁盘上,但不能直接在应用程序地址空间和磁盘之间进行数据传输。因此,数据在传输过程中需要在应用程序地址空间和内核缓存空间之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
直接内存访问(DMA)
传统的IO操作,由CPU进行控制,CPU通过系统总线与其他部件连接并进行数据传输。CPU需要暂停正在执行的程序,去处理IO操作,待数据传输处理完后,再继续执行之前被暂停的工作,此方式IO过程中消耗大量CPU时间,效率低,适合少量数据传输。
DMA(Direct Memory Access,直接内存访问)技术主要是为了解决批量数据输入输出问题,是指外部设备不需要通过CPU而直接与系统内存交互数据的接口技术。DMA工作模式下,在数据准备开始传输时,CPU把总线控制权交给DMA控制器,由DMA控制器完成数据的传输工作,再把总线控制器交还给CPU。
传统IO文件拷贝
有了以上概念,我们再来看下IO操作的流程,以应用程序(用户态)从磁盘中拷贝一个文件为场景进行说明。
手到擒来,Java代码如下:
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(inFile));BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(outFile))){byte[] buf = new byte[1024];while ((bis.read(buf)) != -1) {bos.write(buf);}
数据流程图如下: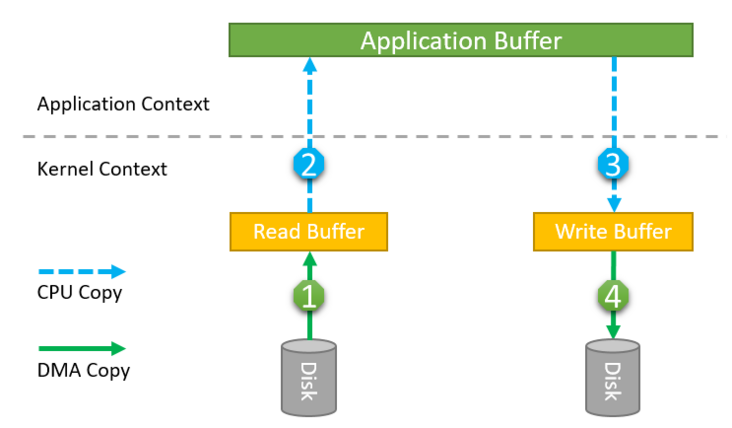
- 应用程序调用read()系统调用,系统切换到Kernel上下文,底层采用DMA读取磁盘的文件,把内容保存到Kernel地址空间读缓存区。
- 由于应用程序无法访问Kernel地址空间,如果应用程序要访问数据,需要把内容从Kernel地址空间拷贝到用户缓存区地址中,Kernel完成数据拷贝后,read()方法返回,系统切换回用户上下文,此时数据位于应用程序缓存区。
- 应用程序再调用write()系统调用,把数据写入文件。调用write()后,系统切换到Kernel上下文,并把用户缓存区的数据拷贝到Kernel中的写入缓存区。
- write()方法返回,系统再次切换回用户上下文。此后由DMA控制器把数据写入磁盘设备,完成数据写入。
在上述过程中,发生了4次数据拷贝和4次系统上下文切换,其中第1次和第4次数据拷贝由DMA控制,不需要CPU参与,第2次和第3次需要CPU的参与。
NIO文件拷贝
由于在上述过程中,应用程序并不修改传输的数据,所以数据在Kernel和用户缓存间的来回拷贝以及系统上下文的多次切换,是可否可以进行优化,去掉第2、3两次数据拷贝,是否存在一种“管道”把Read Buffer和Write Buffer直接接在一起?
当然有,NIO中的FileChannel.transferTo()方法给我们提供了这种实现,Java Doc描述如下(有删减):
/*** Transfers bytes from this channel's file to the given writable byte* channel.** <p> An attempt is made to read up to <tt>count</tt> bytes starting at* the given <tt>position</tt> in this channel's file and write them to the* target channel.*/public abstract long transferTo(long position, long count,WritableByteChannel target)throws IOException;
从Java Doc可知,上述方法就是把两个Channel对接起来,文件拷贝的具体实现代码如下:
FileChannel inputChannel = new FileInputStream(inFile).getChannel();FileChannel outChannel = new FileOutputStream(outFile).getChannel();//Transfers bytes from this channel's file to the given writable byte channelinputChannel.transferTo(0, fileChannelInput.size(), outChannel);
数据流程图如下: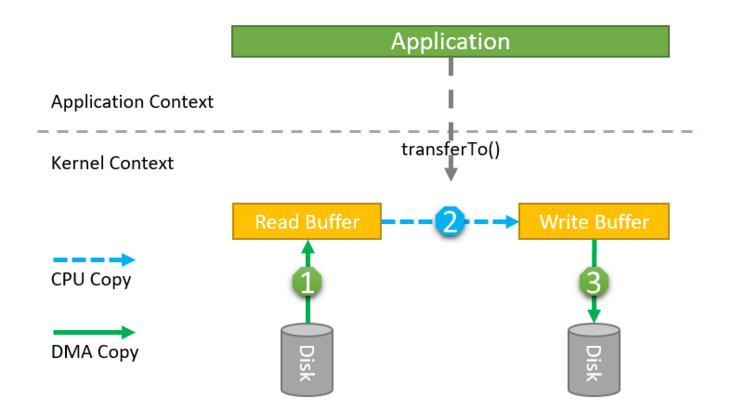
通过FileChannel的transferTo()方法,实现了把数据中一个可读的文件管道直接传输到另一个可写管道,消除了Kernel和用户缓存间的数据拷贝和系统上下文切换。在Linux底层,方法被传递到sendfile()系统调用,实现把数据从一个文件描述符传输到了另一个文件描述符。
Socket IO内存零拷贝
在Linux 2.4以及更高版本的内核中,Socket缓冲区描述符支持gather操作。内核只向Socket传递数据的FD(File Descriptor),而不实际拷贝数据,这种方式不但减少上下文切换,同时消除了需要CPU参与的数据拷贝过程。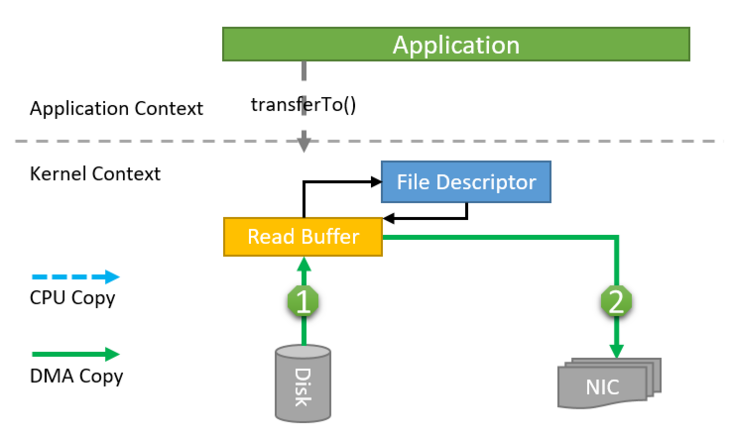
此模式下,用户侧还是调用FileChannel.transferTo()方法,但是Kernel内部实现发生了变化:
- transferTo方法调用触发DMA引擎将文件上下文信息拷贝到内核缓冲区。
- 数据不会被拷贝到Socket缓冲区,只有数据的描述符被拷贝到Socket缓冲区。
- DMA引擎直接根据FD把数据从内核缓冲区拷贝到NIC缓存,减少了最后一次需要消耗CPU的拷贝操作。
Netty的底层就是基于NIO实现的,所以在这一怪它也实现了零拷贝。另外,Netty在JVM内存中的操作,也封装了一些类,减少了数据的来回复制:
- Netty提供CompositeByteBuf类, 可以将多个ByteBuf合并为一个逻辑上的ByteBuf, 避免了各个ByteBuf之间的拷贝。
- 通过wrap操作, 我们可以将byte[]数组、ByteBuf、ByteBuffer等包装成一个Netty ByteBuf对象, 进而避免拷贝操作。
- ByteBuf支持slice操作,可以将ByteBuf分解为多个共享同一个存储区域的ByteBuf, 避免内存的拷贝。
参考链接
https://segmentfault.com/a/1190000021448694
https://developer.ibm.com/articles/j-zerocopy/

若有收获,就点个赞吧
0 人点赞
