编译过程首先就是对模板做解析,生成 AST,它是一种抽象语法树,是对源代码的抽象语法结构的树状表现形式。在很多编译技术中,如 babel 编译 ES6 的代码都会先生成 AST
这个过程是比较复杂的,它会用到大量正则表达式对字符串解析
例子
<ul :class="bindCls" class="list" v-if="isShow"><li v-for="(item,index) in data" @click="clickItem(index)">{{item}}:{{index}}</li></ul>
经过 parse 过程后,生成的 AST 如下
ast = {'type': 1,'tag': 'ul','attrsList': [],'attrsMap': {':class': 'bindCls','class': 'list','v-if': 'isShow'},'if': 'isShow','ifConditions': [{'exp': 'isShow','block': // ul ast element}],'parent': undefined,'plain': false,'staticClass': 'list','classBinding': 'bindCls','children': [{'type': 1,'tag': 'li','attrsList': [{'name': '@click','value': 'clickItem(index)'}],'attrsMap': {'@click': 'clickItem(index)','v-for': '(item,index) in data'},'parent': // ul ast element'plain': false,'events': {'click': {'value': 'clickItem(index)'}},'hasBindings': true,'for': 'data','alias': 'item','iterator1': 'index','children': ['type': 2,'expression': '_s(item)+":"+_s(index)''text': '{{item}}:{{index}}','tokens': [{'@binding':'item'},':',{'@binding':'index'}]]}]}
生成的 AST 是一个树状结构,每一个节点都是一个 ast element,除了它自身的一些属性,还维护了它的父子关系,如 parent 指向它的父节点,children 指向它的所有子节点
整体流程
parse定义在src/compiler/parser/index.js中
/*** Convert HTML string to AST.*/export function parse (template: string,options: CompilerOptions): ASTElement | void {warn = options.warn || baseWarnplatformIsPreTag = options.isPreTag || noplatformMustUseProp = options.mustUseProp || noplatformGetTagNamespace = options.getTagNamespace || noconst isReservedTag = options.isReservedTag || nomaybeComponent = (el: ASTElement) => !!(el.component ||el.attrsMap[':is'] ||el.attrsMap['v-bind:is'] ||!(el.attrsMap.is ? isReservedTag(el.attrsMap.is) : isReservedTag(el.tag)))transforms = pluckModuleFunction(options.modules, 'transformNode')preTransforms = pluckModuleFunction(options.modules, 'preTransformNode')postTransforms = pluckModuleFunction(options.modules, 'postTransformNode')delimiters = options.delimitersconst stack = []const preserveWhitespace = options.preserveWhitespace !== falseconst whitespaceOption = options.whitespacelet rootlet currentParentlet inVPre = falselet inPre = falselet warned = falsefunction warnOnce (msg, range) {if (!warned) {warned = truewarn(msg, range)}}function closeElement (element) {trimEndingWhitespace(element)if (!inVPre && !element.processed) {element = processElement(element, options)}// tree managementif (!stack.length && element !== root) {// allow root elements with v-if, v-else-if and v-elseif (root.if && (element.elseif || element.else)) {if (process.env.NODE_ENV !== 'production') {checkRootConstraints(element)}addIfCondition(root, {exp: element.elseif,block: element})} else if (process.env.NODE_ENV !== 'production') {warnOnce(`Component template should contain exactly one root element. ` +`If you are using v-if on multiple elements, ` +`use v-else-if to chain them instead.`,{ start: element.start })}}if (currentParent && !element.forbidden) {if (element.elseif || element.else) {processIfConditions(element, currentParent)} else {if (element.slotScope) {// scoped slot// keep it in the children list so that v-else(-if) conditions can// find it as the prev node.const name = element.slotTarget || '"default"';(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element}currentParent.children.push(element)element.parent = currentParent}}// final children cleanup// filter out scoped slotselement.children = element.children.filter(c => !(c: any).slotScope)// remove trailing whitespace node againtrimEndingWhitespace(element)// check pre stateif (element.pre) {inVPre = false}if (platformIsPreTag(element.tag)) {inPre = false}// apply post-transformsfor (let i = 0; i < postTransforms.length; i++) {postTransforms[i](element, options)}}function trimEndingWhitespace (el) {// remove trailing whitespace nodeif (!inPre) {let lastNodewhile ((lastNode = el.children[el.children.length - 1]) &&lastNode.type === 3 &&lastNode.text === ' ') {el.children.pop()}}}function checkRootConstraints (el) {if (el.tag === 'slot' || el.tag === 'template') {warnOnce(`Cannot use <${el.tag}> as component root element because it may ` +'contain multiple nodes.',{ start: el.start })}if (el.attrsMap.hasOwnProperty('v-for')) {warnOnce('Cannot use v-for on stateful component root element because ' +'it renders multiple elements.',el.rawAttrsMap['v-for'])}}parseHTML(template, {warn,expectHTML: options.expectHTML,isUnaryTag: options.isUnaryTag,canBeLeftOpenTag: options.canBeLeftOpenTag,shouldDecodeNewlines: options.shouldDecodeNewlines,shouldDecodeNewlinesForHref: options.shouldDecodeNewlinesForHref,shouldKeepComment: options.comments,outputSourceRange: options.outputSourceRange,start (tag, attrs, unary, start, end) {// check namespace.// inherit parent ns if there is oneconst ns = (currentParent && currentParent.ns) || platformGetTagNamespace(tag)// handle IE svg bug/* istanbul ignore if */if (isIE && ns === 'svg') {attrs = guardIESVGBug(attrs)}let element: ASTElement = createASTElement(tag, attrs, currentParent)if (ns) {element.ns = ns}if (process.env.NODE_ENV !== 'production') {if (options.outputSourceRange) {element.start = startelement.end = endelement.rawAttrsMap = element.attrsList.reduce((cumulated, attr) => {cumulated[attr.name] = attrreturn cumulated}, {})}attrs.forEach(attr => {if (invalidAttributeRE.test(attr.name)) {warn(`Invalid dynamic argument expression: attribute names cannot contain ` +`spaces, quotes, <, >, / or =.`,{start: attr.start + attr.name.indexOf(`[`),end: attr.start + attr.name.length})}})}if (isForbiddenTag(element) && !isServerRendering()) {element.forbidden = trueprocess.env.NODE_ENV !== 'production' && warn('Templates should only be responsible for mapping the state to the ' +'UI. Avoid placing tags with side-effects in your templates, such as ' +`<${tag}>` + ', as they will not be parsed.',{ start: element.start })}// apply pre-transformsfor (let i = 0; i < preTransforms.length; i++) {element = preTransforms[i](element, options) || element}if (!inVPre) {processPre(element)if (element.pre) {inVPre = true}}if (platformIsPreTag(element.tag)) {inPre = true}if (inVPre) {processRawAttrs(element)} else if (!element.processed) {// structural directivesprocessFor(element)processIf(element)processOnce(element)}if (!root) {root = elementif (process.env.NODE_ENV !== 'production') {checkRootConstraints(root)}}if (!unary) {currentParent = elementstack.push(element)} else {closeElement(element)}},end (tag, start, end) {const element = stack[stack.length - 1]// pop stackstack.length -= 1currentParent = stack[stack.length - 1]if (process.env.NODE_ENV !== 'production' && options.outputSourceRange) {element.end = end}closeElement(element)},chars (text: string, start: number, end: number) {if (!currentParent) {if (process.env.NODE_ENV !== 'production') {if (text === template) {warnOnce('Component template requires a root element, rather than just text.',{ start })} else if ((text = text.trim())) {warnOnce(`text "${text}" outside root element will be ignored.`,{ start })}}return}// IE textarea placeholder bug/* istanbul ignore if */if (isIE &¤tParent.tag === 'textarea' &¤tParent.attrsMap.placeholder === text) {return}const children = currentParent.childrenif (inPre || text.trim()) {text = isTextTag(currentParent) ? text : decodeHTMLCached(text)} else if (!children.length) {// remove the whitespace-only node right after an opening tagtext = ''} else if (whitespaceOption) {if (whitespaceOption === 'condense') {// in condense mode, remove the whitespace node if it contains// line break, otherwise condense to a single spacetext = lineBreakRE.test(text) ? '' : ' '} else {text = ' '}} else {text = preserveWhitespace ? ' ' : ''}if (text) {if (!inPre && whitespaceOption === 'condense') {// condense consecutive whitespaces into single spacetext = text.replace(whitespaceRE, ' ')}let reslet child: ?ASTNodeif (!inVPre && text !== ' ' && (res = parseText(text, delimiters))) {child = {type: 2,expression: res.expression,tokens: res.tokens,text}} else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') {child = {type: 3,text}}if (child) {if (process.env.NODE_ENV !== 'production' && options.outputSourceRange) {child.start = startchild.end = end}children.push(child)}}},comment (text: string, start, end) {// adding anything as a sibling to the root node is forbidden// comments should still be allowed, but ignoredif (currentParent) {const child: ASTText = {type: 3,text,isComment: true}if (process.env.NODE_ENV !== 'production' && options.outputSourceRange) {child.start = startchild.end = end}currentParent.children.push(child)}}})return root}
从options中获取方法和配置
parse函数的输入是template和options(和平台相关的一些配置),输出是AST的根节点(模板字符串)
定义在src/platforms/web/compiler/options中
放到这个目录是因为它们在不同的平台(web和weex)的实现是不同的
import {isPreTag,mustUseProp,isReservedTag,getTagNamespace} from '../util/index'import modules from './modules/index'import directives from './directives/index'import { genStaticKeys } from 'shared/util'import { isUnaryTag, canBeLeftOpenTag } from './util'export const baseOptions: CompilerOptions = {expectHTML: true,modules,directives,isPreTag,isUnaryTag,mustUseProp,canBeLeftOpenTag,isReservedTag,getTagNamespace,staticKeys: genStaticKeys(modules)}
实现
warn = options.warn || baseWarnplatformIsPreTag = options.isPreTag || noplatformMustUseProp = options.mustUseProp || noplatformGetTagNamespace = options.getTagNamespace || noconst isReservedTag = options.isReservedTag || nomaybeComponent = (el: ASTElement) => !!(el.component ||el.attrsMap[':is'] ||el.attrsMap['v-bind:is'] ||!(el.attrsMap.is ? isReservedTag(el.attrsMap.is) : isReservedTag(el.tag)))transforms = pluckModuleFunction(options.modules, 'transformNode')preTransforms = pluckModuleFunction(options.modules, 'preTransformNode')postTransforms = pluckModuleFunction(options.modules, 'postTransformNode')delimiters = options.delimiters
解析 HTML 模板
对template模板的解析主要是通过parseHTML函数
定义在src/compiler/parser/html-parser中
export function parseHTML (html, options) {const stack = []const expectHTML = options.expectHTMLconst isUnaryTag = options.isUnaryTag || noconst canBeLeftOpenTag = options.canBeLeftOpenTag || nolet index = 0let last, lastTagwhile (html) {last = html// Make sure we're not in a plaintext content element like script/styleif (!lastTag || !isPlainTextElement(lastTag)) {let textEnd = html.indexOf('<')if (textEnd === 0) {// Comment: 注释节点和文档类型节点// 对于注释节点和文档类型节点的匹配,如果匹配到做前进即可if (comment.test(html)) {const commentEnd = html.indexOf('-->')if (commentEnd >= 0) {if (options.shouldKeepComment) {options.comment(html.substring(4, commentEnd), index, index + commentEnd + 3)}// 对于注释节点,前进至它们的末尾位置advance(commentEnd + 3)continue}}// http://en.wikipedia.org/wiki/Conditional_comment#Downlevel-revealed_conditional_commentif (conditionalComment.test(html)) {const conditionalEnd = html.indexOf(']>')if (conditionalEnd >= 0) {// 对于条件注释节点,前进至它们的末尾位置advance(conditionalEnd + 2)continue}}// Doctype:const doctypeMatch = html.match(doctype)if (doctypeMatch) {// 对于文档类型节点,则前进它自身长度的距离advance(doctypeMatch[0].length)continue}// End tag: 结束标签const endTagMatch = html.match(endTag) // 通过正则endTag匹配到闭合标签if (endTagMatch) {const curIndex = indexadvance(endTagMatch[0].length) // 前进到闭合标签末尾parseEndTag(endTagMatch[1], curIndex, index) // 对闭合标签做解析continue}// Start tag: 开始标签const startTagMatch = parseStartTag() // 解析开始标签if (startTagMatch) {handleStartTag(startTagMatch)if (shouldIgnoreFirstNewline(startTagMatch.tagName, html)) {advance(1)}continue}}// 文本let text, rest, nextif (textEnd >= 0) { // 满足则说明从当前位置到textEnd位置都是文本rest = html.slice(textEnd)while (!endTag.test(rest) &&!startTagOpen.test(rest) &&!comment.test(rest) &&!conditionalComment.test(rest)) {// < in plain text, be forgiving and treat it as text// 如果 < 是纯文本的字符就继续找到真正的文本结束的位置next = rest.indexOf('<', 1)if (next < 0) breaktextEnd += nextrest = html.slice(textEnd)}text = html.substring(0, textEnd) // 前进到结束的位置}if (textEnd < 0) { // 满足则说明整个template解析完毕了,把剩余的html都赋值给了texttext = html}if (text) {advance(text.length)}// 调用options.chars回调函数并传text参数if (options.chars && text) {options.chars(text, index - text.length, index)}} else {let endTagLength = 0const stackedTag = lastTag.toLowerCase()const reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([\\s\\S]*?)(</' + stackedTag + '[^>]*>)', 'i'))const rest = html.replace(reStackedTag, function (all, text, endTag) {endTagLength = endTag.lengthif (!isPlainTextElement(stackedTag) && stackedTag !== 'noscript') {text = text.replace(/<!\--([\s\S]*?)-->/g, '$1') // #7298.replace(/<!\[CDATA\[([\s\S]*?)]]>/g, '$1')}if (shouldIgnoreFirstNewline(stackedTag, text)) {text = text.slice(1)}if (options.chars) {options.chars(text)}return ''})index += html.length - rest.lengthhtml = restparseEndTag(stackedTag, index - endTagLength, index)}if (html === last) {options.chars && options.chars(html)if (process.env.NODE_ENV !== 'production' && !stack.length && options.warn) {options.warn(`Mal-formatted tag at end of template: "${html}"`, { start: index + html.length })}break}}// Clean up any remaining tagsparseEndTag()function advance (n) {index += nhtml = html.substring(n)}// 解析开始标签function parseStartTag () {// 通过正则匹配到开始标签const start = html.match(startTagOpen)if (start) {// 定义match对象const match = {tagName: start[1],attrs: [],start: index}advance(start[0].length)let end, attr// 循环去匹配开始标签中的属性并添加到match.attrs中,直到匹配的开始标签的闭合符结束while (!(end = html.match(startTagClose)) && (attr = html.match(dynamicArgAttribute) || html.match(attribute))) {attr.start = indexadvance(attr[0].length)attr.end = indexmatch.attrs.push(attr)}// 匹配到闭合符则获取一元斜线符,前进到闭合符尾,并把当前索引赋值给match.endif (end) {match.unarySlash = end[1]advance(end[0].length)match.end = indexreturn match}}}// 对match处理function handleStartTag (match) {const tagName = match.tagNameconst unarySlash = match.unarySlashif (expectHTML) {if (lastTag === 'p' && isNonPhrasingTag(tagName)) {parseEndTag(lastTag)}if (canBeLeftOpenTag(tagName) && lastTag === tagName) {parseEndTag(tagName)}}// 判断开始标签是否是一元标签,类似<img>、<br />const unary = isUnaryTag(tagName) || !!unarySlash// 对match.attrs遍历并做了一些处理const l = match.attrs.lengthconst attrs = new Array(l)for (let i = 0; i < l; i++) {const args = match.attrs[i]const value = args[3] || args[4] || args[5] || ''const shouldDecodeNewlines = tagName === 'a' && args[1] === 'href'? options.shouldDecodeNewlinesForHref: options.shouldDecodeNewlinesattrs[i] = {name: args[1],value: decodeAttr(value, shouldDecodeNewlines)}if (process.env.NODE_ENV !== 'production' && options.outputSourceRange) {attrs[i].start = args.start + args[0].match(/^\s*/).lengthattrs[i].end = args.end}}// 非一元标签,则往stack里push一个对象,并且把tagName赋值给lastTagif (!unary) {stack.push({ tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs: attrs, start: match.start, end: match.end })lastTag = tagName}// 调用options.start回调函数并传入一些参数if (options.start) {options.start(tagName, attrs, unary, match.start, match.end)}}// 对闭合标签做解析// 倒序stack,就是找到第一个和当前endTag匹配的元素function parseEndTag (tagName, start, end) {let pos, lowerCasedTagNameif (start == null) start = indexif (end == null) end = index// Find the closest opened tag of the same typeif (tagName) {lowerCasedTagName = tagName.toLowerCase()for (pos = stack.length - 1; pos >= 0; pos--) {if (stack[pos].lowerCasedTag === lowerCasedTagName) {break}}} else {// If no tag name is provided, clean shoppos = 0}if (pos >= 0) {// Close all the open elements, up the stackfor (let i = stack.length - 1; i >= pos; i--) {if (process.env.NODE_ENV !== 'production' &&(i > pos || !tagName) &&options.warn) {options.warn(`tag <${stack[i].tag}> has no matching end tag.`,{ start: stack[i].start, end: stack[i].end })}if (options.end) {options.end(stack[i].tag, start, end)}}// Remove the open elements from the stackstack.length = poslastTag = pos && stack[pos - 1].tag} else if (lowerCasedTagName === 'br') {if (options.start) {options.start(tagName, [], true, start, end)}} else if (lowerCasedTagName === 'p') {if (options.start) {options.start(tagName, [], false, start, end)}if (options.end) {options.end(tagName, start, end)}}}}
循环解析 template ,用正则做各种匹配,对于不同情况分别进行不同的处理,直到整个 template 被解析完毕。 在匹配的过程中会利用 advance 函数不断前进整个模板字符串,直到字符串末尾
advance 函数
function advance (n) {index += nhtml = html.substring(n)}

advance(4)

匹配的过程中主要利用了正则表达式
// Regular Expressions for parsing tags and attributes// 匹配文档类型节点const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/const dynamicArgAttribute = /^\s*((?:v-[\w-]+:|@|:|#)\[[^=]+?\][^\s"'<>\/=]*)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/const ncname = `[a-zA-Z_][\\-\\.0-9_a-zA-Z${unicodeRegExp.source}]*`const qnameCapture = `((?:${ncname}\\:)?${ncname})`// 匹配开始闭合标签const startTagOpen = new RegExp(`^<${qnameCapture}`)const startTagClose = /^\s*(\/?)>/const endTag = new RegExp(`^<\\/${qnameCapture}[^>]*>`)const doctype = /^<!DOCTYPE [^>]+>/i// #7298: escape - to avoid being passed as HTML comment when inlined in page// 匹配注释节点const comment = /^<!\--/const conditionalComment = /^<!\[/
闭合标签
对于非一元标签(有 endTag)我们都把它构造成一个对象压入到 stack 中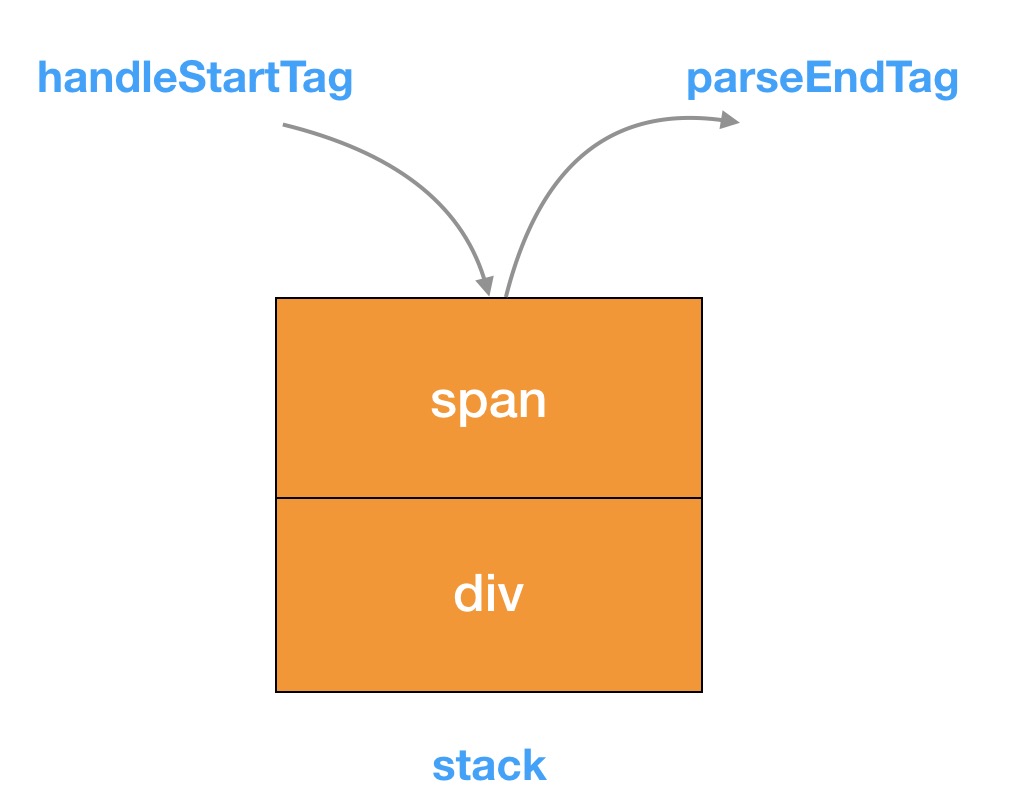
对于闭合标签的解析,就是倒序 stack,找到第一个和当前 endTag 匹配的元素
如果是正常的标签匹配,那么 stack 的最后一个元素应该和当前的 endTag 匹配
考虑到如下错误情况
<div><span></div>
当 endTag 为 的时候,从 stack 尾部找到的标签是 ,就不能匹配,因此这种情况会报警告。匹配后把栈到 pos 位置的都弹出,并从 stack 尾部拿到 lastTag
处理开始标签
当解析到开始标签的时候,最后会执行 start 回调函数,函数主要就做 3 件事情
- 创建 AST 元素
- 处理 AST 元素
- AST 树管理
创建AST元素
```javascript // check namespace. // inherit parent ns if there is one const ns = (currentParent && currentParent.ns) || platformGetTagNamespace(tag)
// handle IE svg bug / istanbul ignore if / if (isIE && ns === ‘svg’) { attrs = guardIESVGBug(attrs) } // 通过createASTElement方法去创建一个AST元素,并添加namespace let element: ASTElement = createASTElement(tag, attrs, currentParent) if (ns) { element.ns = ns }
每一个AST元素就是一个普通的JavaScript对象```javascriptexport function createASTElement (tag: string,attrs: Array<ASTAttr>,parent: ASTElement | void): ASTElement {return {type: 1, // AST元素类型tag, // 标签名attrsList: attrs, // 属性列表attrsMap: makeAttrsMap(attrs), // 属性映射表rawAttrsMap: {}, // 初始的属性映射表parent, // 父的AST元素children: [] // 子AST元素集合}}
处理AST元素
if (isForbiddenTag(element) && !isServerRendering()) {
element.forbidden = true
process.env.NODE_ENV !== 'production' && warn(
'Templates should only be responsible for mapping the state to the ' +
'UI. Avoid placing tags with side-effects in your templates, such as ' +
`<${tag}>` + ', as they will not be parsed.',
{ start: element.start }
)
}
// apply pre-transforms
// 对模块preTransforms调用
for (let i = 0; i < preTransforms.length; i++) {
element = preTransforms[i](element, options) || element
}
// 判断element是否包含各种指令通过processXXX做相应处理,处理的结果就是扩展AST元素的属性
if (!inVPre) {
processPre(element)
if (element.pre) {
inVPre = true
}
}
if (platformIsPreTag(element.tag)) {
inPre = true
}
if (inVPre) {
processRawAttrs(element)
} else if (!element.processed) {
// structural directives
processFor(element)
processIf(element)
processOnce(element)
}
processFor
export function processFor (el: ASTElement) {
let exp
// 从元素中拿到v-for指令的内容
if ((exp = getAndRemoveAttr(el, 'v-for'))) {
const res = parseFor(exp)
if (res) {
extend(el, res)
} else if (process.env.NODE_ENV !== 'production') {
warn(
`Invalid v-for expression: ${exp}`,
el.rawAttrsMap['v-for']
)
}
}
}
export const forAliasRE = /([\s\S]*?)\s+(?:in|of)\s+([\s\S]*)/
export const forIteratorRE = /,([^,\}\]]*)(?:,([^,\}\]]*))?$/
const stripParensRE = /^\(|\)$/g
// 分别解析出for、alias、iterator1、iterator2等属性的值添加到AST的元素上
// v-for="(item,index) in data" 而言,解析出的的 for 是 data,alias 是 item,iterator1 是 index,没有 iterator2
export function parseFor (exp: string): ?ForParseResult {
const inMatch = exp.match(forAliasRE)
if (!inMatch) return
const res = {}
res.for = inMatch[2].trim()
const alias = inMatch[1].trim().replace(stripParensRE, '')
const iteratorMatch = alias.match(forIteratorRE)
if (iteratorMatch) {
res.alias = alias.replace(forIteratorRE, '').trim()
res.iterator1 = iteratorMatch[1].trim()
if (iteratorMatch[2]) {
res.iterator2 = iteratorMatch[2].trim()
}
} else {
res.alias = alias
}
return res
}
processIf
function processIf (el) {
// 从元素中拿v-if指令的内容
const exp = getAndRemoveAttr(el, 'v-if')
// 给AST元素添加if属性和ifConditions属性
if (exp) {
el.if = exp
addIfCondition(el, {
exp: exp,
block: el
})
} else { // 尝试拿v-else指令及v-else-if指令的内容
// 拿到则给AST元素分别添加else和elseif属性
if (getAndRemoveAttr(el, 'v-else') != null) {
el.else = true
}
const elseif = getAndRemoveAttr(el, 'v-else-if')
if (elseif) {
el.elseif = elseif
}
}
}
export function addIfCondition (el: ASTElement, condition: ASTIfCondition) {
if (!el.ifConditions) {
el.ifConditions = []
}
el.ifConditions.push(condition)
}
AST树管理
在处理开始标签的时候为每一个标签创建了一个 AST 元素,在不断解析模板创建 AST 元素的时候,也要为它们建立父子关系,就像 DOM 元素的父子关系那样
AST 树管理的目标是构建一颗 AST 树,本质上它要维护 root 根节点和当前父节点 currentParent
为了保证元素可以正确闭合,这里也利用了 stack栈的数据结构
function checkRootConstraints (el) {
if (el.tag === 'slot' || el.tag === 'template') {
warnOnce(
`Cannot use <${el.tag}> as component root element because it may ` +
'contain multiple nodes.',
{ start: el.start }
)
}
if (el.attrsMap.hasOwnProperty('v-for')) {
warnOnce(
'Cannot use v-for on stateful component root element because ' +
'it renders multiple elements.',
el.rawAttrsMap['v-for']
)
}
}
function closeElement (element) {
trimEndingWhitespace(element)
if (!inVPre && !element.processed) {
element = processElement(element, options)
}
// tree management
if (!stack.length && element !== root) {
// allow root elements with v-if, v-else-if and v-else
if (root.if && (element.elseif || element.else)) {
if (process.env.NODE_ENV !== 'production') {
checkRootConstraints(element)
}
addIfCondition(root, {
exp: element.elseif,
block: element
})
} else if (process.env.NODE_ENV !== 'production') {
warnOnce(
`Component template should contain exactly one root element. ` +
`If you are using v-if on multiple elements, ` +
`use v-else-if to chain them instead.`,
{ start: element.start }
)
}
}
// 处理开始标签时判断如果有currentParent就把当前AST元素push到currentParent.children中,同时把AST元素的parent指向currentParent
if (currentParent && !element.forbidden) {
if (element.elseif || element.else) {
processIfConditions(element, currentParent)
} else {
if (element.slotScope) {
// scoped slot
// keep it in the children list so that v-else(-if) conditions can
// find it as the prev node.
const name = element.slotTarget || '"default"'
;(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element
}
currentParent.children.push(element)
element.parent = currentParent
}
}
// final children cleanup
// filter out scoped slots
element.children = element.children.filter(c => !(c: any).slotScope)
// remove trailing whitespace node again
trimEndingWhitespace(element)
// check pre state
if (element.pre) {
inVPre = false
}
if (platformIsPreTag(element.tag)) {
inPre = false
}
// apply post-transforms
for (let i = 0; i < postTransforms.length; i++) {
postTransforms[i](element, options)
}
}
stack 和 currentParent 除了在处理开始标签的时候会变化,在处理闭合标签的时候也会变化,因此整个 AST 树管理要结合闭合标签的处理逻辑看
处理闭合标签
当解析到闭合标签时会执行end回调函数
end (tag, start, end) {
const element = stack[stack.length - 1]
// pop stack
stack.length -= 1
currentParent = stack[stack.length - 1] // 把stack最后一个元素赋值给currentParent,保证当遇到闭合标签时可以正确更新stack的长度以及currentParent的值,这样来维护整个AST树
if (process.env.NODE_ENV !== 'production' && options.outputSourceRange) {
element.end = end
}
closeElement(element)
},
closeElement(element):更新一下 inVPre 和 inPre 的状态,以及执行 postTransforms 函数
function closeElement (element) {
trimEndingWhitespace(element)
if (!inVPre && !element.processed) {
element = processElement(element, options)
}
// tree management
if (!stack.length && element !== root) {
// allow root elements with v-if, v-else-if and v-else
if (root.if && (element.elseif || element.else)) {
if (process.env.NODE_ENV !== 'production') {
checkRootConstraints(element)
}
addIfCondition(root, {
exp: element.elseif,
block: element
})
} else if (process.env.NODE_ENV !== 'production') {
warnOnce(
`Component template should contain exactly one root element. ` +
`If you are using v-if on multiple elements, ` +
`use v-else-if to chain them instead.`,
{ start: element.start }
)
}
}
if (currentParent && !element.forbidden) {
if (element.elseif || element.else) {
processIfConditions(element, currentParent)
} else {
if (element.slotScope) {
// scoped slot
// keep it in the children list so that v-else(-if) conditions can
// find it as the prev node.
const name = element.slotTarget || '"default"'
;(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element
}
currentParent.children.push(element)
element.parent = currentParent
}
}
// final children cleanup
// filter out scoped slots
element.children = element.children.filter(c => !(c: any).slotScope)
// remove trailing whitespace node again
trimEndingWhitespace(element)
// check pre state
if (element.pre) {
inVPre = false
}
if (platformIsPreTag(element.tag)) {
inPre = false
}
// apply post-transforms
for (let i = 0; i < postTransforms.length; i++) {
postTransforms[i](element, options)
}
}
处理文本内容
文本构造的 AST 元素有 2 种类型,一种是有表达式的,type 为 2,一种是纯文本,type 为 3
chars (text: string, start: number, end: number) {
if (!currentParent) {
if (process.env.NODE_ENV !== 'production') {
if (text === template) {
warnOnce(
'Component template requires a root element, rather than just text.',
{ start }
)
} else if ((text = text.trim())) {
warnOnce(
`text "${text}" outside root element will be ignored.`,
{ start }
)
}
}
return
}
// IE textarea placeholder bug
/* istanbul ignore if */
if (isIE &&
currentParent.tag === 'textarea' &&
currentParent.attrsMap.placeholder === text
) {
return
}
const children = currentParent.children
if (inPre || text.trim()) {
text = isTextTag(currentParent) ? text : decodeHTMLCached(text)
} else if (!children.length) {
// remove the whitespace-only node right after an opening tag
text = ''
} else if (whitespaceOption) {
if (whitespaceOption === 'condense') {
// in condense mode, remove the whitespace node if it contains
// line break, otherwise condense to a single space
text = lineBreakRE.test(text) ? '' : ' '
} else {
text = ' '
}
} else {
text = preserveWhitespace ? ' ' : ''
}
if (text) {
if (!inPre && whitespaceOption === 'condense') {
// condense consecutive whitespaces into single space
text = text.replace(whitespaceRE, ' ')
}
let res
let child: ?ASTNode
if (!inVPre && text !== ' ' && (res = parseText(text, delimiters))) {
child = {
type: 2,
expression: res.expression,
tokens: res.tokens,
text
}
} else if (text !== ' ' || !children.length || children[children.length - 1].text !== ' ') {
child = {
type: 3,
text
}
}
if (child) {
if (process.env.NODE_ENV !== 'production' && options.outputSourceRange) {
child.start = start
child.end = end
}
children.push(child)
}
}
},
表达式调用parseText(text, delimiters)对文本解析
定义在src/compiler/parser/text-parser.js中
const defaultTagRE = /\{\{((?:.|\r?\n)+?)\}\}/g
const regexEscapeRE = /[-.*+?^${}()|[\]\/\\]/g
export function parseText (
text: string,
delimiters?: [string, string]
): TextParseResult | void {
// 根据分隔符(默认是{{}})构造了文本匹配的正则表达式
const tagRE = delimiters ? buildRegex(delimiters) : defaultTagRE
if (!tagRE.test(text)) {
return
}
const tokens = []
const rawTokens = []
let lastIndex = tagRE.lastIndex = 0
let match, index, tokenValue
// 循环匹配文本
while ((match = tagRE.exec(text))) {
index = match.index
// push text token
// 遇到普通文本就push到rawTokens和tokens中
if (index > lastIndex) {
rawTokens.push(tokenValue = text.slice(lastIndex, index))
tokens.push(JSON.stringify(tokenValue))
}
// tag token
// 遇到表达式就转换成_s(${exp}) push到tokens中 转换成{@binging:exp} push到rawTokens中
const exp = parseFilters(match[1].trim())
tokens.push(`_s(${exp})`)
rawTokens.push({ '@binding': exp })
lastIndex = index + match[0].length
}
if (lastIndex < text.length) {
rawTokens.push(tokenValue = text.slice(lastIndex))
tokens.push(JSON.stringify(tokenValue))
}
return {
expression: tokens.join('+'),
tokens: rawTokens
}
}
对于例子
tokens 就是 [_s(item),’”:”‘,_s(index)];rawTokens 就是 [{‘@binding’:’item’},’:’,{‘@binding’:’index’}]
return {
expression: '_s(item)+":"+_s(index)',
tokens: [{'@binding':'item'},':',{'@binding':'index'}]
}
流程图

AST 元素节点总共有 3 种类型,type 为 1 表示是普通元素,为 2 表示是表达式,为 3 表示是纯文本

若有收获,就点个赞吧
0 人点赞
