概述:
为什么InnoDB引擎选用B+树作为存储结构
- 范围查询
- B+树所有真正的数据都在最底层,像链表一样相邻的可以很快找到,所以如果有类似大于小于之类的范围查询会非常容易
树的层数
B树的进阶版
- 与B树的差别:
- 不同层的节点会有重复,同时最低层拥有所有节点。
- 只有最底层的节点有数据。
- 最底层的数据是按索引顺序且连续的。
-
B树(B-树)
B树和B-树是一回事,名字不同。
- 每个节点存储各自的数据
- 节点不会重复。
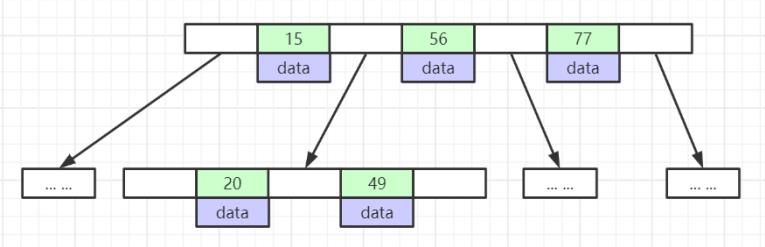
例:计算3层B+树索引能容纳的数据量
首先两个假设:

- 主键id,我们采用bigint,8字节
- 一条数据大小1KB
- 第一层
- 一个页16K,每一个索引键的大小8字节(bigint)+6字节(指针大小),因此第一层可存储16*1024/14=1170个索引键。
- 第二层
- 第二层只存储索引键,能存储多少个索引键呢?1170(这么多个页,有第一层延伸的指针)1170(每页的索引键个数,跟第一步计算一致)=1368900
- _如果第二层存储数据呢?1170(这么多个页,有第一层延伸的指针)_16(16KB的页大小/1KB的数据大小)=18720,也就是能存储一万多条数。
- 第三层
- 直接看三层能存储多少数据?
- 1170117016=21902400
- 3次IO就可以查询到2千多万左右的数据,也就是这么大的数据量如果通过主键索引来查找是很快,这就是explain一个sql时,type=const为什么性能是最优的。

若有收获,就点个赞吧
0 人点赞
