相关课程:Shell-进阶课程,作者:骏马金龙(https://www.junmajinlong.com/)
1. Bash 解释器
1.1 一个命令的生命
- 读取命令行
- bash解析命令行:引号、命令替换、重定向、创建管道等 (对应于 1.2.1)
- 启动进程:fork()子bash进程
- exec 加载程序替换fork出来的子bash进程(搜索命令路径)
- 命令开始执行:
- 解析命令选项、参数(对应于1.2.2)
- 执行主代码逻辑
- 退出:退出状态码
- bash接收状态码,为命令子进程收尸
1.2 注意
- shell需要解析的部分:特殊符号(
'' 、 "" 、$()、 > 、 < 、 |) - 命令自身需要解析的部分:选项、参数、特殊符号
- 特殊符号有可能会出现冲突,如果这个特殊符号,想要被shell解析,则不应该使用双引号、单引号包围,也不能使用反斜线转义。如果这些特殊符号想要被程序自身解析,则必须得使用引号包围,或者反斜线转义。
//例: ls * 与 grep “a.*”//ls 中的*代表 通配符,用来匹配文件//grep中的*代表正则表达式中的 * 的含义//所以grep中的*需要使用引号包裹起来,防止被shell的解析
1.3 解释器解释语句
解释型语言:Python 、Shell 、Perl、AWK
解释特点:
- 读一句 解释一句 忘记一句
- 读一段 解释一段(函数、代码段) 忘记一段
- 先定义再调用
1.4 shell与bash的关系
- shell是一门语言,bash只是其中一种
- shell是一种解释器,bash只是其中一种
- sh指向某种shell
- 除了bash之外还有csh、dash、ksh、powershell、cmd等
2. bash交互式、登录式
交互式与登录式不对立,交互式对立的是非交互式
2.1 什么时候会启动bash:
- 登录系统时
- 执行命令时(内置命令除外)
2.2 bash配置文件
- /etc/profile(全局)
- ~/.bash_profile
- ~/.bashrc
- /etc/bashrc
- **/etc/profile.d/.sh(全局)
2.3 判断交互式、登录式:
- 交互式:
echo $-:结果返回包含了字母i,则为交互式echo $PS1:结果返回 非空值,则为交互式,空值则为非交互式
- 登录式:
shopt login_shell:返回 on 则为登录式shell,返回 off 则为非登录式
2.4 常见的bash启动方式:
- 正常登录(ssh登录、虚拟终端):交互式 && 登录式
su:交互式 && 非登录式;su --login(su -):交互式 && 登录式bash命令(创建子bash):交互式 && 非登录式bash --login:交互式 && 登录式- ssh执行远程命令(不登录):非交互 && 非登录
- shell脚本:非交互 && 非登录
如果sh中加了--login:非交互 && 登录式 - 图形终端:(默认是)交互式 && 非登录式,但是可以更改为登录式
2.5 bash如何读取配置文件:(不同的启动方式,读取的配置文件不同)
- 登录式(无论是否交互):终端登录、带有—login的su、bash和shell脚本:读取全部文件
- 交互式 && 非登录式 :仅读取 ~/.bashrc 、/etc/bashrc 、/etc/profile.d/*.sh
- 非交互 && 非登录式 :不带 —login 的脚本、(远程 shell 方式除外):什么文件都不读取
- 远程shell的非交互非登录:读取:~/.bashrc、 /etc/bashrc 、 /etc/profile.d/*.sh(这个会把结果定向到空)


2.6 定义一个命令别名
如果要定义一个命令别名,那应该定义到哪个配置文件中?
- 如果是全局的(任何用户都可以使用),则应该定义到 /etc/profile 或 /etc/profile.d下的sh文件,若要定义在sh文件中,那么可以考虑创建一个alish.sh
- 如果是某个用户可用的,则建议 定义在 用户家目录下的 ~/.bash_profile和 ~/.bashrc文件中,不建议定义在 /etc/bashrc 中
3. 进程基础
若想深究进程,建议阅读系统编程的书籍
3.1 基本概念
- fork() 创建一个子进程,请求内核创建(内核将其信息保存在内核的进程表中)
- 子进程拷贝父进程几乎所有东西(写时复制),但共享(只读)正文段(指令)
- fork后,将有两个进程分支,一个分支是子进程分支,另一个分支是原有的父进程分支
- 两个pid:一次调用两个返回值
- 对子进程来说,fork()的返回值为0
- 对父进程来说,fork()的返回值为子进程的pid(进程的属性,用来标识唯一的每一个进程)
- 在创建子进程之后,父子进程的调度是没有顺序保证的
- 子shell(子bash)与普通子进程的区别:
- 子shell是一个子进程
- 子bash在启动时会加载配置文件完成bash环境的配置
- shell是一个交互式的解释器进程,它可以继续创建交互式解释器进程
3.2 伪代码演示说明
伪代码:(不可执行)
# she11创建子进程伪代码#创建子进程#现在有两个进程分支:新子进程和原有的父进程pid=`fork`#一次调用两个返回值#对于父进程来说,pid变量的值为新建子进程的pid(进程的属性)#对于子进程来说,pid变量的值为0# 目标# 子进程执行子进程代码# 父进程执行父进程代码# 显然,这个代码 没有这个效果# pid = 0的表示子进程分支if [[ $pid -eq 0 ]]; then#子进程echo "I'm Child Process"fi#父进程/子进程都会执行echo "I'm Parent Process"

#上一个代码的修改版(可实现目标)# shell 创建子进程伪代码#创建子进程#现在有两个进程分支:新的子进程和原有的父进程pid=`fork`# pid = 0的表示子进程分支if [[ $pid -eq 0I]];then#子进程echo "I'm child Process"else#父进程echo "I'm Parent Process"fi
shell中的内置命令exec
- 加载指定命令替换当前shell,执行完后退出进程
- 设置重定向操作,使之生效于当前shell
3.3 僵尸进程
- 为子进程收尸(reap):wait()/waitpid()
- 孤儿进程:对shell来说,能成为孤儿的进程将脱离终端
僵尸进程:
(概括:子进程消失了,父进程没有对子进程进行处理(收尸),就会出现僵尸进程)。
每个子进程在退出时,操作系统都会保留它们的退出状态信息(包括退出想状态码和其他一些信息),并在内核维护的进程表中保留子进程项(内核还会在子进程退出的时候发送SIGCHLD信号给父进程)。对于进程的退出状态信息,只有在父进程读走之后或者收走(reap)之后才会被清除。退出状态信息没有被父进程读走的子进程将成为僵尸进程。
任何子进程,在退出的那一刻,都属于僵尸进程。一瞬间也是。
wait()/waitpid() 处理子进程退出状态信息后,子进程才从僵尸进程完全退出。
如果没有通过wait()/waitpid() 处理子进程退出状态信息,那么子进程将永远成为僵尸进程,除非父进程也退出了。(pid=1的init/systemd。会定期为僵尸进程收尸)
shell伪代码模拟僵尸进程:
# 创建子进程# 现在有两个进程分支:新的子进程和原有的父进程pid=`fork`# pid = 0的表示子进程分支if [[ $pid -eq 0 ]];then#子进程echo "I'm Child Processexitfi#父进程sleep 2ps -o pid, ppid, state, command
对于编程语言来说,可以使用wait()/waitpid()来收尸,他们会处理子进程的退出状态信息
# shell伪代码# 创建子进程# 现在有两个进程分支:新的子进程和原有的父进程pid=`fork`# pid = 0的表示子进程分支if [[ $pid -eq 0 ]];then#子进程sleep 1exec 'echo "'m Child Process"'fi#父进程echo "I'm Parent Process"waitecho "Chile exited or terminated"
对于shell来说,无需我们手动收尸,因为在shell下执行的所有命令都是shell的子进程,shell会帮我们做好收尸工作。但是对于脱离shell的或脱离终端的进程(比如daemon类进程、nohup打开的进程), 它们会挂在pid=1的init/systemd进程下,这些脱离shell或脱离终端的进程的子进程可能会成为永久的僵尸进程(除非它们的父进程死了,就会被系统处理)。
3.4 孤儿进程
父进程死了,子进程还在:子进程成为孤儿进程, 会挂靠到pid=1的init/systemd进程下。
shell伪代码模拟孤儿进程:
# she11伪代码#创建子进程#现在有两个进程分支:新的子进程和原有的父进程pid=`fork`# pid = 0的表示子进程分支if [[ $pid -eq 0 ]];then#子进程echo "I'm Child Process'sleep 5echo "I'm orphan Process"fi#父进程echo "I'm Parent Process"sleep 1
shell 中直接产生孤儿进程:在子shell 中执行后台命令 (sleep 30 &)(注意带括号)
4. 管道
4.1 (匿名)管道特性
- 进程间通信(FIFO):数据一边进一边出(左写右读,左进右出)
- 管道是最先创建出来的,然后才fork管道两边的进程

- 管道左右两边进程没有先后顺序:
ps aux | grep ‘ps aux’测试 - 开启一个进程组(
ps -o ppid,pid,pgid,tpgid,sid,cmd/ps j) - 数据传递是实时读、写的
- 管道是一个字节流
- 有序性
- 读写任意字节大小的数据块
- 数据写端在管道buffer满时阻塞
数据读端在管道buffer空时阻塞- pipe buffermore字节为65536 字节(64k)
- 测试:
dd if=/dev/zero bs=1 | sleep 3 & sleep 1 && pkill -INT -x dd
4.2 管道实例
- 陷阱(作用域):
echo "hello" | while read line;do i=$line;done- while是bash可以认识的语句,其他的不认识
- 上面命令,管道右边的while语句,是在当前shell进程下,创建了一个新的子shell进程。(只要使用管道,就会创建子进程)
- 子shell进程的变量不会影响父shell进程。所以变量 i 只在子shell进程中有效
- 如果此时再执行 echo $i ,则输出结果为空。
- 管道buffer 示例:
- 终端1执行:
while true;do echo $RANDOM >> /tmp/a.log;sleep 1 ;done - 终端2执行:
tail -f /tmp/a.log | grep "[0-9]" - 终端2第二次执行:
tail -f /tmp/a.log | grep "[0-9]" | grep "[0-9]" - 第3步无效果,那就试第四步:
tail -f /tmp/a.log | stdbuf -oL grep "[0-9]" | grep "[0-9]" - 解决第三步的其他方法,就是将输出定向到标准错误,此时就是直接将数据按照行缓冲模式输出到 io buffer:
tail -f /tmp/a.log | grep "[0-9]" >&2 | grep "[0-9]"
- 终端1执行:
4.3 IO buffer 的缓冲类型
- 行缓冲(line buffer):
- io buffer,当进程向io buffer中写入了一个换行符的时候,将直接刷出io buffer中的数据
- 当进程的输出连接至交互式终端时,使用行缓冲模式
- 块缓冲(block buffer/full buffer):
- 进程产生的数据先积累在io buffer中,只有积累满io buffer后,才将io buffer中的数据刷出去
- 默认使用块缓冲模式
- 写向文件系统文件、写向管道、写向套接字
- 无缓冲(unbuffer):
- 不使用io buffer,只要进程产生数据,就立即输出。
- (stderr):错误直接输出(标准错误输出 &2)
4.4 IO buffer的层次
注意:文件描述符是用户空间层维护的内容,不是内核维护的,因为文件描述符仅仅是一些整数变量,不需要交给内核维护。
对 4.2 管道示例中 终端2 第一次执行的解析:

对 4.2 管道示例中 终端2 第二次执行的解析:

对 4.2 管道示例中 终端2 第三次执行的解析:

注意:stdbuf是创建了一个进程,-oL参数是使io buffer按照行缓冲模式处理。它上面的grep是它的子进程,共享数据,所以可以完成工作(都是缓冲模式搞的鬼。。。)
4.5 IO buffer 与 kernel buffer 的层次

4.6 命名管道的特性和用法
创建:mkfifo
- 有名称的管道,所以具有一部分匿名管道的特性
- 数据传输在内存中进行,所以完全没有磁盘 IO 的消耗,高效
- 能够协调任何进程间的通信,这是普通
|所不具备的 - 任何进程(命令)都能向命名管道写入数据,同样,任何进程都能从命名管道中读取数据
- 命名管道的阻塞性:只有读写双方都打开了命名管道,才能读、写数据,否则读、写操作被阻塞
- 完全实现 “协程” coproc的功能
- 实现进程池的作用
- 还具有很多妙用,特别是结合tee、重定向以及 后台进程 的时候,用法更灵活
- ….
- 当你通过普通文件、匿名管道无法实现自己的需求的时候,请考虑使用命名管道,不会让你失望
但是,shell下绝大多数的操作都有更直观、更简便的方式来实现,所以理性使用命名管道。
4.6.1 命名管道用法入门
mkinfo /tmp/a.fifo //创建## 终端1echo "hello world" > /tmp/a.fifo ## 因读取未打开,写被阻塞## 终端2cat /tmp/a.fifo ## 此时 管道的读取打开,刚才的写就会解除阻塞## 终端1while true;dodate +"%T" > /tmp/a.fifosleep 1done## 终端2while read line < /tmp/a.fifo;do ## 有多少读多少echo $linedone# while read line;do echo $line;done < /tmp/a.fifo 只读一行
对于while的一个注意点:当需要读取源源不断的数据时,不要将数据源放在while结构的后面,而是放在读取命令(如 read)后。
对于重定向操作的一个注意点:重定向操作是在命令行解析的阶段(fork子bash之前)进行的,如果重定向行为被阻塞(比如这里的命名管道),那么将一直不会创建进程。
4.6.2 双命名管道的妙用
双命名管道可以实现cmd1 | cmd2 | cmd3 的功能,虽然要复杂些,但是更灵活
mkfifo /tmp/in.fifo /tmp/out.fifogrep "a" </tmp/in.fifo >/tmp/out.fifo &echo "abcde" >/tmp/in.fifocat /tmp/out.fiform -rf /tmp/{in,out}.fifo
mkfifo /tmp/{in,out}.fifo# 筛选处理 cmd2进程while grep ':' </tmp/in.fifo >/tmp/out.fifo; do:done# 上面的:代表空语句# 写while true;dodate +"%T" >/tmp/in.fifosleep 1done# 读while true;docat /tmp/out.fifodonerm -rf /tmp/{in,out}.fifo
4.6.3 避免临时文件导致的多余IO
经典的示例是 MySQL 导入 .gz文件
下面直接通过匿名管道导入导出数据,避免了磁盘IO,直接使用内存,更高效
# export:mysqldump -uXXX -pOOO db_name | gzip > data.gz# import:gzip -d <data.gz | mysql -uXXX -pOOO db_name
但是,如果使用load data infile呢?
mkfifo /tmp/data.sql.fifogzip -d <data.gz >/tmp/data.sql.fifo &mysql -uXXX -pOOO -e "load data infile '/tmp/data.sql.fifo' into table table_name" db_name
4.6.4 共享终端会话
mkfifo /tmp/share.fifo# 终端1:分享端script -f /tmp/share.fifo# 终端2:接收端cat /tmp/share.fifoexit 退出
4.6.5 不知道叫什么功能的功能
f(){mkfifo p{i,o}{1,2,3}tr a b <pi1 >po1 &sed 's/./&&/g' <pi2 >po2 &cut -c2- <pi3 >po3 &tee pi{1,2} > pi3 &cat po{1,2,3}rm -rf p{i,o}{1,2,3}}printf '%s \n' foo bar | f

4.6.6 结合nc工具做代理功能
参考: https://en.wikipedia.org/wiki/Netcat
nc -l 12345 | nc www.baidu.com 80
mkfifo backpipemv -l 12345 <backpipe | nc www.baidu.com 80 >backpipe
5. shell 内置结构的陷阱
注意:!!!!! 内置结构自身是属于bash的,当内置结构想要运行起来,需要有专门一个bash进程取负责执行,为他们提供运行环境。
5.1 while 使用管道后的变量作用域
部分讲解看 4.2 管道实例 陷阱。
5.2 重定向操作是谁的?(复合命令)
- 输入:输入重定向放在整个while的后面 && 输入重定向放在 read 后面
while read line;do echo $line; done </tmp/a.log## 输出结果:输出一部分就结束了,中途会停止,并不会一直等待着数据while read line </tmp/a.log; do echo $line; done## 输出结果:一直会输出(按照我们想要的效果),不会中途停止
- 输出:
while true;do date +"%T"; sleep 1; done >/tmp/x.log## 输出结果:# 数据会有很多,因为在整个while的后面,重定向不在循环里,所以只打开了一次文件,后面的事情就是一直向里面写数据。没有再次打开,没有被再次清空。结果显示多条数据。while true;do date +"%T" >/tmp/x.log;sleep 1; done## 输出结果:# 只会有一行,因为放在了循环里,所以每次都会重新打开文件,以覆盖的方式打开文件时,一瞬间,文件的内容就被清空了,然后写一次数据,再打开(清空),再写。所以只会有一条数据。
原因解释:放在bash内置结构后面的重定向,只打开一次文件(重定向没有放在循环里),覆盖/追加是在打开(open)文件的时候决定并进行的,那一刻决定了的文件的数据要不要清除。
5.3 谁放入后台?
while true;do sleep 100;done &# 将整个while放入后台,因为整个while放入了后台,所以while不能使用当前bash进程,因此创建了一个临时的新子bash进程,当把当前bash杀掉时,新子bash进程会成为孤儿进程独自挂载在pid=init/system(1)上,进程不停止,使用pstree -p | grep sleep 查看pid,再使用kill -9 pid杀掉。while true;do sleep 100 & sleep 1;done## 每秒产生一个sleep后台进程,将当前bash杀掉后,创建的sleep进程都会直接挂载到pid=init/system(1)下,并没有产生任何新子bash进程,注意与上面的将整个while放入后台区分。(sleep 30 &)# 使用括号,也会创建一个子进程来运行当前命令,只是括号结束时,子进程会被瞬间杀掉,但sleep不会被杀掉,所以sleep成为孤儿进程。结果与第二个类似

# |-bash(3847)---sleep(3893) #第一个将整个while放入后台后杀掉的结果# |-sleep(3894) ## 第二个分别放入后台并杀掉的结果# |-sleep(3896) ## 第二种的孤儿进程最后会被系统杀掉,# |-sleep(3898) ## 但是第一种创建了子bash的进程不会被系统杀掉# |-sleep(3900)# |-sleep(3902)# |-sleep(3904)# |-sleep(3906)# |-sleep(3908)
原因解释:当后台命令运行在 子shell 中时,子shell退出,后台命令就成为了孤儿进程,而且会脱离终端,就像nohup功能。
特别的是,如果后台命令是for/while的话,那么将不断的循环,不会退出(即第一种while不会被系统杀掉)
注意第一个整个while放入后台的解释,与第二个分别放入后台的解释。
解决方法:killall bash / killall -9 bash
6 命令替换、进程替换、后台进程
6.1 命令替换
将一个命令运行,把产生的数据插入到命令行当中的某个地方。
- $(cmd) :但命令替换中包含了特殊符号时,建议使用这个括号的形式
- 反引号 ``
- 命令替换,默认会将产生的换行符压缩成空格,可以使用双引号还原。
- 命令替换是先执行的
echo `echo haha`$(echo "haha")echo `echo "\a"`echo `echo "\\a"`echo `echo "\\\a"`echo `echo "\\\\a"`echo $(echo "\a")echo $(echo "\\a")echo $(echo "\\\a")echo $(echo "\\\\a")## 两种方式对于转义反斜线的替换不同,建议使用$()这一个。于平时对反斜线的理解一样。echo `echo -e "a\nb"` ## 换行符压缩成空格echo "`echo -e "a\nb"`" ## 再套一层双引号进行还原,就不会被压缩成空格了
6.2 后台进程 &
多进程异步执行 &
6.3 进程替换
- 进程替换是通过虚拟文件来进行数据交互的,不是直接插入到某个地方。
- 进程替换也是先执行的,也是 多进程异步执行。
(cmd) 是输入进程替换,<(cmd) 是输出进程替换
>(cmd) <(cmd):使用输出重定向符号的其实是输入进程替换,使用输入重定向符号的其实是输出进程替换。重定向符号加上括号才是进程替换,不然就只是重定向
(别人产生的数据输出给我们,从我们角度看就是输入数据,所以输出重定向符号是输入进程替换,看方向,指向我们,所以是输入给我们;
我们产生的数方向给别人,从我们角度看就是输出数据,所以输入重定向符号是输出进程替换,看方向,指向别人,所以是输出)注意:符号都放在命令左侧再加括号
echo "abcde" | tee >(grep "a") >/dev/null | cat -# 这一句同时实现了 cmd1 | cmd2 & | cmd3 协程的功能:grep等价于cmd2 &echo "abcde" | tee >(grep "a") >/dev/null #去掉后面的内容可以证明是异步执行echo <(cat /etc/fstab)cat <(cat /etc/fstab)cat /etc/fstab | tee >(grep -i "UUID") >/dev/null
6.4 协程(coproc)
协程(coproc)和协同子程序(coroutine),协同函数
作用:cmd(->) | cmd & | (->)cmd
取代协程:1.命名管道、2.tee + 进程替换
7. 命令组合
- 命令组合都是bash的内置结构,需要专门的bash提供运行环境
- 其他的组合:
for、if、while、until、case、select、[[]]、(())、{} ():在子shell中执行命令组合,括号被当前bash解析,结果就是创建子bash,但是如果命令组合中,只有一个命令,那么这个命令就会直接覆盖子shell进程。{}:在 当前shell 中执行命令组合
注意:- 大括号左右两边留有空格
- 所有命令以分号结尾,除非换行
(echo $BASEPID) ## BASHPID 的结果返回执行该语句的bash进程的pid(sleep 2 | ps -H) ## ps -H 可以显示出进程的继承关系{sleep 2 | ps -H} ## 对比来看,一目了然
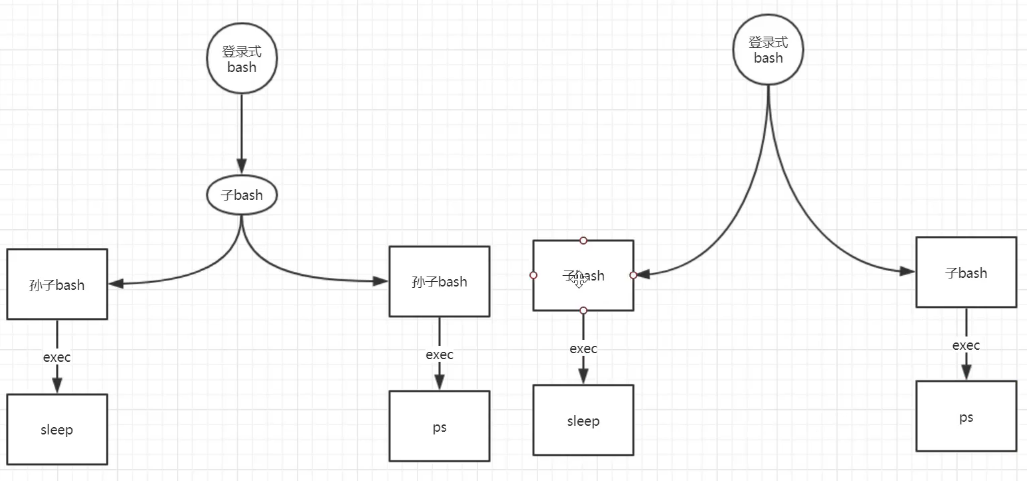
8. shell read读取文件和read替换管道
8.1 read 基本用法
- read -p :从终端中读取数据(交互式),读取的数据可以保存到多个变量中
read -p "输入你的名字:" name:提示你输入名字,保存在 $name变量中read -p "输入你的名字:":不指定name变量,那么默认保存在 $REPLY变量中
- read </etc/hosts :可以从标准输入中(管道、输入重定向)读取数据,默认读取一行。结果保存在$REPLY 中。如果后面写了多个变量,则会默认按空格分隔每个变量的赋值.
read -d ‘a’ </etc/hosts:指定a作为行分隔符,读取一行(a前面的)read -a arr </etc/hosts:读取数据,并将结果保存在名为arr的数组中
- read 在读取完一次数据之后,会在读取到的位置打上标记(文件指针),表示这次已经读取到了这里,下次将继续从这里开始向下读取。
- 如果多次执行
read </etc/hosts,会发现与我们说的不同,这是因为每执行一次重定向,就相当于重新打开一次文件,文件指针就会被初始化到一开始的位置。 - 解决重定向导致的问题:(一次重定向,多次读取)
{read;echo $REPLY; read ; echo $REPLY;} </etc/hosts - https://www.cnblogs.com/f-ck-need-u/p/7402149.html
- 如果多次执行
read var1 var2 var3 </etc/hosts# var1 :127.0.0.1# var2 :localhost# var3 :localhost.localdomain localhost4 localhost4.localdomain4read -a arr </etc/hostsecho ${arr[@]} # 查看数组全部数据echo ${arr[0]} # 查看第一个数据echo ${arr[1]}echo ${arr[2]}echo ${arr[3]}
8.2 在shell中指定输入(数据)源的方式
- 直接给文件:命令后直接加文件
- 管道:管道很牛,但有缺点
- 输入重定向:通过输入重定向,就代表着使用了标准输入。
- 常见:<filename 、 <(cmd):第二个是进程替换
- here string :三个
<cat <<< “hello”:将hello做为cat的输入
- here doc :
<<eof:eof就代表文件开始的头位置,再次输入eof代表文件结束
cat <<eof>hello>world!>eof ## 文件结束
8.3 读取数据的方式
- 程序自身读取文件或标准输入的逻辑,程序员控制的,我们shell用户没法控制
shell下的read ,用户可控
- while read line:不建议使用管道+while read line(管道会创建子进程来执行while语句)
- 按字符读取
- 按行读取
注意区分:read是读取数据的,管道是传递数据的
8.4 while read line 如何替换管道
while read line;do#...#... 多次操作#...done </etc/passwd
9. 重定向
9.1 基础(背景知识)
重定向的作用:
- 为程序指定数据输入源
- 为程序指定数据输出目标
重定向基础内容:
- 文件和文件描述符:
/proc/self/fd/:文件描述符表的位置,对应于文件描述符,所以/proc/目录是用户查看内核和改变内核的入口,注意文件描述符在用户空间层。 - /dev/stdin(0)
- /dev/stdout(1)
- /dev/stderr(2) :注意:每个程序运行时都打开了上面三个文件描述符(0、1、2)
- /proc/self/fd :这是本进程打开的文件描述符
- 软连接指向关系:
- 目录:
/dev/fd -> /proc/self/fd /dev/std(in,out,err) -> /proc/self/fd/{0,1,2}/proc/self/fd/{0,1,2} -> /dev/pts/N(N是终端号,最终连接到了当前终端)
- 目录:
- 特殊文件:短横线(
-),代表了读取标准输入,需要程序内部代码去解析短横线特殊文件,如果没有相关解析代码,会报错。 - 重定向操作是在shell解析命令行的时候执行的,在命令执行之前,就已经确定了(即完成数据处理操作)
- 注意:重定向操作可以放在命令行的任意位置。
ls -l /dev/std*# /dev/stdin -> /proc/self/fd/0# /dev/stdout -> /proc/self/fd/1# /dev/stderr -> /proc/self/fd/2ls -l /proc/self/fd ##当我们输入了这些命令行,还没敲回车时,这个目录是不存在的。敲下回车之后,就记录了本进程(ls)所打开的文件描述符# 0 -> /dev/pts/0 ## 这个/dev/pts/0 就是当前的终端 ,意思就是数据的输入输出读取都# 1 -> /dev/pts/0 ## 传输到这个终端# 2 -> /dev/pts/0# 3 -> /proc/2666/fdls -l /proc/self/fd ## 新开一个终端,再次使用次命令# 0 -> /dev/pts/1 ## 都连接/dev/pts/1 这个终端(当前终端)# 1 -> /dev/pts/1# 2 -> /dev/pts/1# 3 -> /proc/2736/fd
9.2 基本重定向
- 输入重定向
<:(使用输入重定向之后,数据就变成了标准输入) - 覆盖(截断)输出重定向
>: - 追加输出重定向
>> - 标准错误
2> - 重定向可以放在命令行的任意位置,因为是执行之前就解析
9.3 exec的作用
- 替换当前shell进程
- 让重定向操作在当前shell下生效
- exec只能让输出重定向在当前shell下生效
exec >/tmp/a.logls # 结果不会在屏幕输出,而是进入/tmp/a.logcat /etc/passwd # 同理不会再屏幕输出
9.4 高级重定向
9.4.1 复制(duplicate):
[n]>&N(省略n时,默认n=1)[n]<&N(省略n时,默认n=0)- 含义解析:让 n 指向 N 所指的 文件(不严谨)。指向的是文件或设备!!!
- 方便理解:
>/dev/null 2>&1:先把1定义到空,再把2定义到1所指的文件(空)。结果2和1都定义到了空,没有任何输出 ===(&>/dev/null) - 重定向的顺序很重要:
第四步如果这样写:2>&1 >/dev/null:会导致 2 先定义到1所指的输出(屏幕),再把1指向空。结果:错误输出定向到了屏幕,标准输出定向到了空文件 - 通过exec将文件描述符绑定到文件:
exec 5</etc/hosts # 把文件描述符5 绑定到文件/etc/hostsread <&5 # 再把标准输入(0)绑定到文件描述符为5的文件上(/etc/hosts)
注意:之所以说上面的含义不严谨,是因为 fd table 中文件描述符都指向了open file table中的一条记录。他们两个描述符共享同一个文件偏移量指针,都互相影响(因为指针共享)。例:
exec 3>/tmp/a.logecho "haha1" >&3echo "haha2" >&3echo "haha3" >&3# 结果:# haha1# haha2# haha3# 结果三行都存在,我们明明使用了一个'>',本来表示覆盖重定向,但是并没有覆盖,同理绑定4到3exec 4>&3echo "haha4" >&4echo "haha5" >&4echo "haha6" >&4# 结果也是 haha1 到 haha6 都有。# 原因解释:文件描述符共享文件偏移指针。虽然执行多次echo操作,但文件仅打开了一次。第一次输出haha1之后,文件偏移指针指向了haha1的后面,由于偏移指针共享,所以再次输出haha2时,会接着上一次的指针位置去写数据(上一次指针位置是haha1后面)。同理后面绑定4到3,均不会再次打开文件,而是接着上一次的指针位置去写数据。# 虽然只是用了一个“>”,但是并不表示覆盖重定向。他是 "n>&N" ,文件描述符复制。
9.4.2 关闭(close)文件描述符
[n]>&-[n]<&-
9.4.3 打开(open)文件描述符
exec 6<> /etc/fstab:可读可写的方式绑定6到文件上(默认不用,因为指针从头开始,会覆盖数据)- 文件描述符的复制,也会打开文件描述符
9.4.6 移动(move)文件描述符
[n]>&N-[n]<&N-- 含义解析:移动的意思就是先复制一份文件,然后把源文件删除。即 先复制一份文件描述符n,然后关闭原来的 N 文件描述符
9.5 高级重定向用法示例
- 文件描述符的备份和还原(w命令可以查看用户及终端)
exec 6>&1 # 6 指向 1(把1备份为6)exec > /tmp/file.txt # 1定向到文件,完成操作echo "---------------"exec 1>&6 6>&- # 操作完,再把 1 还原,删除6echo "===============" # 完成工作## (推荐使用第一种 备份和还原操作)# 第二种直接还原的方法:先在另一个终端种执行 w 命令,查看终端pts/[n],然后执行下面的语句即可exec 1>/dev/pts/[n]## Linux一切皆文件,文件描述符指向哪个文件(设备、终端),就会向哪个文件(终端、设备)输出## 如果在pts/1下执行这些命令,就会将数据输出到另一个终端:exec 1>/dev/pts/0echo "我是终端1"## 此时,pts/0 终端就会输出 我是终端1## 注意:一切皆文件
- 实现临时文件(一切皆文件)
# open fd=3 and remove file # 创建文件,然后删除exec 3<> /tmp/${0}${$}.temprm -rf /tmp/${0}${$}.temp# file deletedls /proc/self/fd # 通过查看,描述符还在,说明重定向的文件还能用lsof -n | grep -E 'temp.*delete[d]' # 发现被删除了,但是文件描述符依然能用#write to fdecho "hello world" >&3 # 向3中输入数据# read from fd# cat <&3 # 此处不用 cat直接从3中读取,是因为只打开了一次文件,刚才写入数据之后,cat /proc/self/fd/3 # 偏移指针就指向了world的末尾,直接用cat读取会直接向后读,没有数据的,必须使用cat 读取那个文件(Linux一切皆文件!!!),才是重新打开描述符3# close fd # 关闭exec 3<&-lsof -n | grep -E 'temp.*delete[d]'
- 多进程控制(进程池)
- 后台进程
- 进程替换
- coproc
- xargs -P N :
- 指定最多多少进程同时运行,只适用于没有大量IO操作的场景
- split/csplit
- parallel :解决xargs的缺点,但 复杂
10. shell 解析命令行
10.1 引号解析示例
- 单引号中的双引号,以及双引号中的单引号,都会被保留不被 shell 解析(只解析配对的引号)
- 引号配对,从左至右进行配对
- 可以将一个参数通过引号配对的方式分隔开,分隔开,只要分隔的时候不要使用空白符号断开。(分隔开了就会被当成两个参数)
- 单引号是强引用,双引号是弱引用
解析问题:
- 如果在单引号中使用单引号,双引号中使用双引号,必须配对再输入一个单(双)引号
- 如果在不想让双引号中的特殊字符解析,必须转义。例如:
echo “\$name” - 单引号(强引用)中使用反斜线转义没有意义。
echo 'hello"world'echo "hello'world"
sed 程序示例:
sed -n "$p" filename ## 如果想输出文件的最后一行,这是错误的。应该用单引号sed -n '$p' filename ## 正确的使用sed -n \$p filename ## 正确sed -n '$-2p' /etc/passwd ## 想输出倒数第三行,使用错误,因为sed中的行号计数器只有在全部读取完文件后才给$赋值wc -l /etc/passwd;line=27; ## 先把行号赋值给line变量sed -n "${line}p" /etc/passwd ## 正确sed -n "${line}p;$p" /etc/passwd ## 想输出倒数第三行和最后一行,错误sed -n "${line}p;"'$p' /etc/passwd ## 正确.使用单引号,不让shell 解析$p,而是交给sed处理sed -n "${line}p;\$p" /etc/passwd ## 正确.使用反斜线转义,也可实现sed -n ${line}"p;\$p" /etc/passwd ## 也可以
awk 程序示例:
## 想输出 hello'world (带单引号)awk 'BEGIN{print "hello world"}' ## 输出不带单引号的hello world 成功awk 'BEGIN{print "hello'world"}' ## 输出带单引号的hello'world 失败 (看颜色也可以知道),因为前两个双引号配对了,shell就解析了,后面就剩了一个双引号,一个单引号awk 'BEGIN{print "hello' "'" 'world"}' ## 用双引号把那个单独的单引号包围,前后再加上单引号配对一开始的和最后的单引号,注意:引号引号之间没有空白符,我是为了理解才加上的awk " BEGIN{print \"hello'world\" }" ## 正确,将一开始单引号换成双引号,里面的双引号进行转义(交给awk程序处理,单引号因没有配对,而被解析成单个字符)awk 'BEGIN{print "hello\047 world"}' ## 正确,用八进制ASCII代表单引号(shell不认识但awk认识ASCII)awk -v q="'" 'BEGIN{print "hello"q"world"}' ## 把变量q定义为单引号,然后应用## 直接使用awk脚本文件a.awk,内容为:BEGIN {print "hello'world"} ## 不需要考虑与shell冲突的问题了
10.2 命令行解析
- shell 解析的过程:
- 暴露给shell解析,使用双引号或不使用引号
- 避免给shell 解析到,就一定要放到单引号当红,或使用反斜线转义
- 用来解析shell的特殊符号:引号、管道符号、重定向符号、变量替换符号、进程替换、命令替换、&、大小括号、空白符号(IFS) 等等
- IFS:将命令行划分成一个个的word
- shell 解析完成之后,命令行就变了。 通过
cat /proc/self/cmdline查看,可知空白符被替换成了NUL(\0)
- 命令(程序自身解析):
- 这个解析过程,在命令行中是我们无法控制的,由编写程序的程序员决定解析什么选项、什么参数、以及如何解析
- 为什么要避免shell解析:
- 因为某些命令中的特殊符号,和shell的特殊符号冲突了
- 如果,想要把这个特殊符号,留给命令自身,就不能被shell解析
- 如果想要把特殊符号留给shell解析,就需要将特殊符号暴露给shell去解析
10.3 shell 解析命令行的细节(核心)
- 读取命令行
- 命令组合的特殊符号,管道、&、()、;等等
- 划分token
- 单词(word)拆分:按照$IFS拆分(默认“SPACE\t\n”)
- 引号和反斜线的作用:引号配对
- 确定重定向的位置(>截断)
- 命令检查(是否是某些特殊结构的命令)
- if、for、while、until、select、case
- 检查是否是别名
- 各种扩展
- 大括号扩展:
echo {1..10};echo {a..d}、touch /tmp/{a..d}.log - 波浪号扩展:
~:表示家目录~+:表示当前目录 == $PWD~-:表示上一次所处的路径(目录) == $OLDPWD
- 参数、变量替换:
echo $name;echo $(name%%s*):变量替换是在echo进程出现前进行的,后面 name%%s* 意思是贪婪删除,知道出现s为止的所有字符,如果name=longshuai,会删除最后到s(逆向)输出long
- 算术扩展:
a=44;echo $((a+6)) - 命令替换、进程替换
- 命令替换:
$()以及两个反引号:echo $(echo hello)==echo haha - 进程替换:
<()、>()
注意:如果进行了一个或两个 第3、4、5步中的扩展,会再次进行单词拆分(只有未在引号中进行扩展,才会进行这一单词拆分的过程,被包含在引号中就不会拆分了)
- 命令替换:
- 文件名通配符扩展
*不能匹配以点开头的隐藏文件,除非开启匹配选项(shopt -s dotglob)*默认不能递归到子目录去匹配,除非开启(shopt -s globstar),使用**/*.c即可到子目录的.c文件下搜索- shopt -s extglob :扩展shell下的通配功能,使用正则。
- 大括号扩展:
- 引号去除:
- 命令自身是不需要引号的
- 搜索命令
- 判断相对路径、绝对路径:斜杠
- 检查是否有同名函数
- 是否是bash内置命令
- $PATH
- fork+exec
- 执行命令
- 解析选项、参数
- 执行主代码逻辑
- 退出;返回退出状态码
- 父bash进程收到退出状态码后为子进程收尸
- 触发信号捕获功能
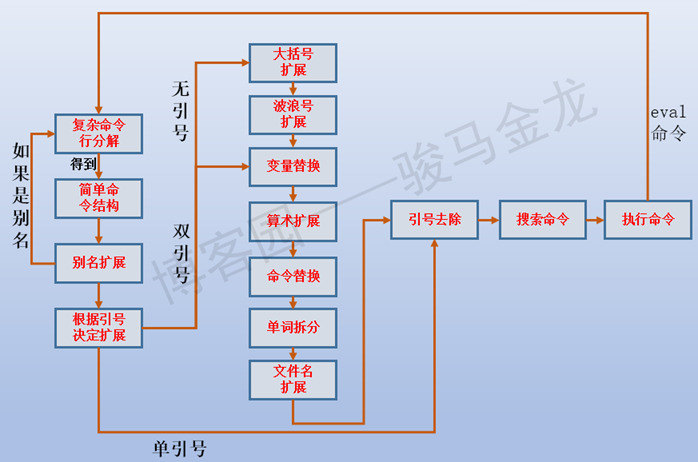
图为 https://www.cnblogs.com/f-ck-need-u/p/7426371.html 中的图,注意双引号扩展不包括单词拆分和文件名扩展功能,图中未标注
示例:
name=longshuaia=24echo -e "some files:" ~/i* "\nThe date:$(date +%F)\n$name's age is $((a+4))" >/tmp/a.log
图解上面命令:

10.4 eval 二次解析
a=hellohello=xiaomageeval echo \$$a# 解析1:eval echo $hello# 解析2:echo $hello## 结果:输出xiaomage
类似可以二次解析的命令还有time、xargs等
11 作用域
- 函数自动全局和局部修饰local
- shell中自定义函数也是默认全局作用域,除非使用local 修饰该变量
- 子shell 不影响父shell 环境
- 通过子shell 也可以实现局部作用域
- 词法作用域
- 文本定义(函数定义)位置决定了作用域的课件范围,在哪定义就属于哪个作用域
- 动态作用域
- 文本调用位置决定作用域可见范围,在哪调用就属于哪个作用域
- bash 采取动态作用域
#!/bin/bash# 1.动态作用域规则:文本调用位置决定作用域范围,# 因为f()是在g()函数内部调用的,而且g()函数内部定义了局部变量x# 所以,调用f()函数的时候,f()内部访问的变量x是g()内部的局部变量# 所以,f()中输出的是 f: 3# 而且,f()修改的变量x也是g()中的局部变量x# 于是,在g()中的echo输出的是 g: 2# 整个输出结果:# f: 3# g: 2# 1# shell 使用动态作用域,所以会显示这个#2.词法作用域规则:文本定义位置决定作用域范围# 因为f()和g()是定义在全局范围内的,所以,f()和g()内部访问的变量x都是全局变量x# 但是g()函数内部使用local修改了局部变量x,使得local语句之后的所有访问变量x的语句都只能访问到局部变量x# 所以,f()中访问的变量x是全局变量x=1,修改的也是全局变量x# g()访问的变量x是局部变量x=3# 注意:f()和g()访问的变量不一样# 输出结果:# f: 1# g: 3# 2x=1function f(){echo "f: $x";x=2;}function g(){local x=3;f;echo "g: $x";}gecho $x
12 信号和信号捕捉
12.1 操作系统中的信号
- 软中断:从软件的角度上去打断进程的正常执行流程
- 异步
- 信号是随时可能产生的
- 信号产生后,可能会等待一段时间才会发送给进程
- 进程接收到信号后,仍然可能会等待一段时间才会去处理信号
- 注册信号处理程序,自定义处理逻辑
- 谁发送信号
- 内核
- 进程自身发送信号给自己
- 进程1发送信号给进程2
- 每个信号都有一个自己的数值编号
- HUP
- SIGHUP
- 信号的分类:
- 标准信号(1-31)
- 实时信号(34-64)
- 不同操作系统类型对有些信号的实现是不一样的,编号也可能不一样
12.2 常见信号
kill -l:查看所有信号。标准信号(1-31)、实时信号(34-64)
- HUP(1):hang up
- 终止“普通”进程。只要进程没有脱离终端,就是“普通”进程
- 当终端断开连接的时候,内核会发送HUP信号给控制进程(产生链式反应)。控制进程会将HUP信号继续发送给终端内的所有进程
- 发送HUP信号给daemon(守护进程)类进程时,不会终止进程,而是让这类进程重读配置文件,实现 graceful restart的功能c
- INT(2):Ctrl + C
- Ctrl + C 和 INT 信号是有区别的:前者是发送给整个进程组,会影响进程组内的所有进程;后者是发送给进程组的leader进程,不会影响进程组内的其他进程。kill -INT -PGID
- KILL(9):必杀信号(实在没有办法采用,一般不用)
- TERM(15):终止进程的标准信号,比kill(9)好多了
注意:上面四个信号以及 0信号 必须掌握
- TSTP:Ctrl + Z
- 让前台的进程进入后台,并进入stop状态(注意这不是终止进程,仅仅是停止,可恢复)
- CONT:让stop状态的进程提到前台,继续运行 runing
fg命令 - QUIT:Ctrl + \
- 比term信号好一点,会产生coredump文件
- CHLD:
- 内核发送CHLD信号给父进程,通知父进程它有子进程已经终止了,仅仅是通知(收尸是父进程使用wait/waitpid)
- WINCH:
- 当一个窗口尺寸发生改变时,就会发送此信号。
- 对后台进程而言,他们没有窗口,所以默认情况下 WINCH 是不起作用的,所以,程序员就可以去对后台进程注册 WINCH 信号的处理程序,实现自定义的处理逻辑
- STOP、USR1、USR2、TTIN、TTOU……
- 特殊信号(0):检查进程是否存在
12.3 shell中发送信号的方式
- kill 类命令
kill -CONT %1:给后台进程id为1 的进程发送CONT信号 - 快捷键:Ctrl + (C、Z、\):对于脱离了终端的后台进程无效
12.4 shell 中 trap 捕获信号
- trap:shell中用来注册信号处理程序
- 执行命令列表:
trap 'cmdlist' sig_list - 忽略信号:
trap '' sig_list - 重置信号:
trap - sig_list:重置为刚登陆时的那种状态
trap "echo trapped" INT ## 定义:当捕获到INT信号时(按CTRL + c),就输出trappedtrap "echo trapped;echo haha;echo hehe;" INT QUIT TERM ##可以给多个信号同时定义多个命令trap '' INT ## 定义为忽略信号,按ctrl + C 没有任何反应trap - SIGHUP INT QUIT TERM ## 全部重置掉
- 在shell脚本中使用trap
- 清理临时文件
- 清理脚本中的后台进程
- 使用
kill 0杀掉整个进程组
# 清理临时文件#!/bin/bashtrap "echo trapped;rm -rf $tmp_dir;exit 1 " INT HUP QUIT TERM# trap 'echo trapped;rm -rf $tmp_file;exit 1' EXITtmp_dir=/tmp/$BASHPIDmkdir $tmp_dirtouch $tmp_dir/{a..d}.tmpls $tmp_dirsleep 5## 前台进入睡眠时,按ctrl + c 停止,即可看见清理文件的作用,查看一下临时文件是否还在rm -rf $tmp_direcho 'over'
# 清理脚本中的后台进程function signal_handle(){echo trappedkill $pidexit 1}trap 'signal_handle' INT HUP QUIT TERM# trap 'signal_handle' EXITsleep 20 &pid = $!sleep 20 &pid="$! $pid"sleep 5
#!/bin/bash# 使用kill 0 杀当前进程function signal_handle(){echo trappedkill -TERM 0 ## 通过发送TERM信号杀掉整个进程组,因为脚本运行时,脚本进程就是当前进程组的leader进程## 不推荐使用 QUIT INT ,快捷键发送的信号对后台进程没有效果的exit 1}trap 'signal_handle' EXITsleep 10 &sleep 20 &sleep 5
12.5 shell中信号和trap 的注意事项
- trap 是bash内置命令,它守护的是bash环境
- 接收到信号后,会等待正在执行的前台任务完成后才去触发信号处理程序。原因:shell认为前台进程都是重要任务
- trap 设置的信号守护 是对bash 运行环境的设置,可能会被子shell继承:只有忽略类型的信号会被子shell继承
- 信号守护是有范围的
- 交互式shell 会忽略 TERM 信号(
killall bash发送的就是TERM 信号);在任何情况下,bash都会忽略 QUIT 信号 - 特殊信号:
- ERR 信号:bash 出错的时候,set -e
- EXIT 信号:bash 退出的时候(KILL信号例外)
13 子shell
13.1 什么是子shell
- 是子进程?(不一定)
- 子shell(bash 进程)
- 不考虑进程,只考虑shell环境
13.2 子shell为什么这么重要
- 不考虑进程,只考虑shell环境
13.3 bash内置命令和函数的特殊性
- 不需要开启新的进程
- 它们依赖于shell环境,没有shell环境,就没法执行
13.4 子shell的特点
- 按需继承父shell 环境、不影响父shell
- 当前shell中执行:
source(return语句)(仅影响当前shell)、{}(仅影响当前shell) - 子shell中执行:
()(仅在子shell中生效)
13.5 什么时候进入新的shell环境
- 两个特殊的变量
$BASHPID:常用,查看bash PID$BASH_SUBSHELL:查看当前所处的是第几层嵌套环境
- 普通命令:
?(N) - bash 内置命令
?(N),但放管道后?(Y) - 管道
?(Y):开启进程组,两个子shell环境 - bash 命令自身
bash,?(Y) (cmd1;cmd2;cmd3…),?(Y){cmd1;cmd2;cmd3;…;},?(N)- 命令替换
?(Y) - 进程替换
?(Y) - 后台任务
?(Y) - 直接执行shell脚本
?(Y),但source脚本除外?(N)
注意:进入新shell环境的共同点:fork 进程时,需要shell解析(比如特殊符号)特殊:source 是bash 内置命令,所以不会进入子shell
14 wait 命令
- 子进程需要等待 收尸
- wait()、waitpid()
- 再看命令生命周期:shell前台进程
- fork之后两个进程分支
- 子进程exec加载新程序
- 父进程wait(),进入阻塞,等待给子进程收尸
- bash的wait():
- wait pid1 pid2 pid3 …
- wait job1 job2 job3 …
- wait pid jobid
- 无参数wait():等待所有子进程(特别实用)
- wait的好处:解决前后有依赖性的命令:例如软件安装配置脚本,需要等待软件包安装完以后,再执行自动配置操作
15 终端、进程组、会话、shell
15.1 登录终端
- 登录控制台终端的过程:
- init 加载 getty 程序:根据/etc/inittab 决定加载的终端
- getty进程open终端设备(文件)(虚拟终端)
- 打开文件描述符 0、1、2
- 显示login 提示输入用户名
- getty 加载login进程
- login 进程提示输入密码、验证、加载shell
- 网络登录终端(如ssh)
- sshd 等待客户端连接
- sshd 打开伪终端
- 打开文件描述符0、1、2
- 显示login 提示输入用户名
- fork 子进程:子进程加载login程序,父进程sshd继续监听
- login验证用户登录,加载shell
15.2 进程组
- 标识:PGID
- 是进程的集合,每个进程都有所属进程组
- 每个进程组都有leader进程 leader的pid==进程组的pgid
- 子进程创建出来时会继承父进程所属进程组的ID
- 脱离组忽略组信号:例如独自成组(
setpgid()) - 进程组的好处:
- 为实现shell提供支持
- 使得waitpid()可以等待整个进程组
- 可以发送信号给整个进程组
- shell(如bash)登录后,shell是一个进程组
- shell中通过管道成立进程组
- 支持作业系统的bash,执行每个命令都独自成组
15.3 会话
- 标识:SESSION ID/SID
- 是进程组的集合,包含一个或多个进程组
- 每个session有leader:session创建者进程
- 子进程创建出来时会继承父进程所属session id
- setsid()函数
- 创建session和第一个process group
- 进程自己成为session leader和group leader
- setsid设置的会话是没有控制终端的,如果之前有,将会切断会脱离终端
- daemon类进程,会调用setsid()来脱离终端,成立独自的session
- 存在一个setsid 命令(不是函数):将进程放入一个新session中,脱离终端
- 存在一个daemon/daemonize令:将某个进程运行成daemon进程(脱离终端,新session)
15.4 终端、会话、进程组、shell、普通进程 的关系
关系:(军营、军队、小分队、将军、小兵)
15.4.1
- 类比:
- 终端—> 军营
- 会话—> 军队
- 进程组—> 小分队
- 登录终端时的shell 进程 —> 将军
- 普通的进程—> 小兵
- session 可以用于0或1个终端
- 控制终端是谁创建的
- 终端由getty 或sshd 创建
- user login之后将创建一个session,此时session还没有绑定终端
- session leader 绑定一个终端,该终端将成为session的控制终端
- 终端的控制进程:
- 该session leader将成为终端的控制进程:shell 进程
- 是控制进程的标志:当该进程与终端断开时,内核发送SIGHUP信号给该控制进程(session leader),从而引起链式反应
- 结果是:该终端上的所有任务都被终止,或者直接脱离终端
- 另一角度看,控制进程断开连接后,终端和会话就断开了,需要和会话中的其他进程也断开关系
- 在有终端的会话中
- 只有一个前台进程组,n(n>0)个后台进程组
- 键盘发送的信号都发送给前台进程组:Ctrl + c/z
- tcsetpgrp()可将某进程组设置为终端的前台进程组(fg)
- 在没有终端的会话中
- setsid()设置的会话是没有终端的
- 没有终端的会话是脱离终端的,父进程死掉后会被pid=1的init/systemd收养
15.4.2 一些命令
ps -o pid,ppid,pgid,tpgid,sid,tty,comm===ps j- pid: 进程id、ppid:父进程ID
- pgid:进程组ID、sid:会话ID
- tpgid: 这个进程所属会话对应的终端的前台进程组ID
ps jps j &ps j & | catps j | cat &
15.4.3 进程脱离终端的几种方法
- 脱离终端方法论:从当前shell中脱离,成为孤儿进程或孤儿进程组
- nohup、screen、tmux
- ((cmd)&) 、(cmd&)
- 子shell中忽略SIGHUP信号:
trap ‘’ SIGHUP - disown
- setsid
- daemon或daemonize 创建daemon类进程
- 父进程pid = 1
- 没有(脱离)终端
- 自己成立session、 process group
- 关闭std{in/out/err}
- chdir到/,防止文件系统卸载导致进程错误
- 清空umask,使得进程可以按权限需求创建文件
- 脱离终端注意事项:重定向需要关闭否?
16 作业 job
- 没有脱离 shell 的进程组就是作业
- 作业中可以有一个或多个进程
- 一个作业称之为一个pipeline
- 作业中的多个进程通过管道组合
- 作业和shell的关系
- 作业控制是shell的一个特性
- 一个shell可以执行多个作业,一个前台,多个后台
- 作业是属于shell的,当前shell下只能查看自己的作业信息
- 作业状态
- running(包含两种进程状态的进程:)
- 正在被调度执行的进程
- 正处于就绪队列的进程
- stopped:它并不代表进程真的完全停止不运行了
- done
- JOBID 标识每个作业:%jobid 查看进程
+符号代表CPU当前正在执行的作业-符号代表操作系统下次调度的进程
- running(包含两种进程状态的进程:)
- 作业控制
- 通过Ctrl + Z ( sigtstp 信号)、fg(CONT)前台运行、bg(CONT)后台运行
- 每个 shell 都维护属于自己的作业表
- 通过一张作业表记录当前的作业
- disown可将作业(进程组)移出作业表,使之脱离终端
- disown [-a|-r] [-h] [JOBID]
- 不加-h表示将任务从表中移出,加-h表示不移除,但设置忽略SIGHUP 信号
- -a 表示对所有任务失效
- -r 表示对当前running状态任务生效
- 如果既没有给-a、-r也没有jobid,那么操作的是+符号的作用
17 shell 的一些技巧或脚本规范
17.1 文件锁
劝告锁:要求双方或多方都同时使用同样的锁机制,否则文件锁就失去意义
- 通过文件存在性判断
#!/usr/bin/bashtrap 'echo "trapped";rm -rf ${lock_file};exit' EXITlock_file=/var/lock/mylockwhile [-f "${lock_file}"];doecho "locked..."sleep 1donetouch ${lock_file}## 上面就是用文件存在性来判断文件锁;其他文件也需要这样判断timeout 5 bash -c 'while true;doecho "lock1.sh:`date +'%T'`" >> /tmp/a.logsleep 1done'## 同理可以将上面的语句写成一个头文件(API)函数## 注意需要在引用它的文件中使用source加载进shell环境。# API 文件:#!/bin/bashfunction lockfile(){trap 'echo "trapped";rm -rf ${lock_file};exit' EXITlock_file=$1while [-f "${lock_file}"];doecho "locked..."sleep 1donetouch ${lock_file}}## lock333.sh#!/bin/bash[-f "lockfile.sh"] && source lockfile.sh || {echo "lockfile.sh not exit";exit 1;}lock_file=/var/lock/mylocklockfile ${lock_file}timeout 5 bash -c 'while true;doecho "lock1.sh:`date +'%T'`" >> /tmp/a.logsleep 1done'
- flock 文件锁
lslocks查看锁、man flock查看手册- 排他锁(独占锁、互斥锁、写锁,X)(仅有一个能申请排他锁)
- 共享锁(读锁,S)(可存在多个)(共享锁与排他锁不可共存)
flock -s a.lock echo hahaflock -x a.lock echo hahaflock -w 5 -s a.lock -c cat
17.2 设计脚本的选项:getopt
https://www.cnblogs.com/f-ck-need-u/p/9757959.html
https://www.cnblogs.com/f-ck-need-u/p/9758075.html#blog1
- bash内置命令getopts
- getopt设计的选项的共性
- 短选项可以连在一起
- 参数可以给多个,而且放置的位置任意
- 选项型参数可以和选项连在一起,也可以空格分开
- getopt的功能:解析选项并将解析的结果分类整理
- 选项:短选项、长选项
- 参数
- 选项型参数:必须跟在选项后(选项型参数可以和选项连在一起)
- 非选项型参数:可任意放置位置
- 自己设计脚本—功能
- 把sleep 当成守护进程去运行
- 可以去启动、可以去终止这个守护进程
- 指定sleep 睡眠时长的参数,也可以以配置文件的方式提供
- 指定pid文件
- 选项以及参数
- 非选项型参数:睡眠时长
-c/--config:睡眠时长-s/--start:启动模式-k/--kill:终止进程-p/--pidfile:指定守护进程的pid文件-v/--version-h/--help
#!/bin/bash## 注意:1. [ ] 里面和两边都需要有空格分开## 2. 判断使用 == ,而不是=VERSION=1.0function usage(){cat <<EOFusage: $0 [OPTIONS] [TIME]options:-s,--start start mode-k,--kill kill mode-c,--config config-p,--pidfile pidfile-h,--help print help info-v,--version print VERSIONEOF}args=`getopt -n "$0" -o skc:p:vh -l start,kill,config:,pidfile:,version,help -- "$@" `echo "args:$args"#通过 set -- args 将args变量当中的选项和参数设置成bash的位置变量# $1,$2eval set -- "$args"while true;docase "$1" in-s|--start)[ -n "$mode" ] && { echo "-s/-c/-k can't use together";exit 1; }mode="start"shift;;-k|--kill)[ -n "$mode" ] && { echo "-s/-c/-k can't use together";exit 1; }mode="kill"shift ## 把当前第一个位置参数给踢掉,那么第二个就变成了第一个;;-c|--config)config=$2shift 2 ## 有选项存在,所以shift 两次;;-p|--pidfile)pidfile=$2shift 2;;-h|--help)usage;exit 1;;-v|--version)echo $VERSIONexit 1;;--)time=$2shiftbreak;;*)usageexit 1esacdone## 必须要给模式,如果不给,就是用默认start[ -z "$mode" ] && mode="start"## 如果没有给定pidfile,就使用默认的pidfile=/tmp/mysleep.pid[ -z "$pidfile" ] && pidfile=/tmp/mysleep.pid# 在启动模式下,必须要给一个且只能给一个time# 在终止模式下,可以给可以不给if [ "$mode" == "start" ];then# start modeif [ -n "$config" -a -n "$time" ];thenecho "config and time can 't use together"exit 1;elif [ -n "$config" ];thenif [ -r "$config" ] ;thenread line <"$config"[ -z "$line" ] && { echo "time invalid";exit 1; }[ -n "${line//[0-9]/}" ] && { echo "time invalid";exit 1; }time = $lineelseecho "config unreadable"exit 1;fielif [ -n "$time" ];then[ -n "${line//[0-9]/}" ] && { echo "time invalid";exit 1; }elseecho "must give me a time to sleep"exit 1fielse# kill mode:fiecho "mode : $mode"echo "pidfile : $pidfile"echo "time : $time"function startmysleep(){pidfile=$1time=$2# $!: 表示最近一个后台子进程的pid( sleep $time & echo $! ) >> "$pidfile"}function killmysleep(){pidfile=$1if [ -r "${pidfile}" ];thenwhile read pid;do[ -z "$pid" ] && { echo "pid invalid";exit 1; }[ -n "${pid//[0-9]/}" ] && { echo "pid invalid";exit 1; }echo "this $pid has been killed...."kill $piddone < "${pidfile}"rm -rf "$pidfile"return 0fiecho "${pidfile} unreadable"return 1}case "$mode" instart)startmysleep $pidfile $time;;kill)killmysleep $pidfile;;*)usageexit 1esac
17.3 tee命令的花式用法
echo haha | tee file1 file2 file3tee >(cmd1) >(cmd2) stdout- 数据可能会和bash的命令提示符混合在一起
- 解决方案:再把数据通过管道输出给cat (可避免后台进程执行不完就出现命令提示符的状况) 或 把进程替换的数据分别写入不同文件
- 多个命令的输出结果顺序无法保证
- tee 只能把数据传递给多个文件,不能传递给多个命令(除非使用进程替换:进程替换是数据传递给虚拟文件,然后从虚拟文件读取数据,不建议用进程替换,顺序会乱)
echo haha | tee >(grep "a") >(sed "s/haha/heihei/") >/dev/null | cat
17.4 pee命令
- 数据传递给多个命令,并且保证最后的输出顺序
echo haha | pee "grep 'a'" "sed 's/haha/heihei/'"
17.5 shell脚本的规范:
https://zh-google-styleguide.readthedocs.io/en/latest/google-shell-styleguide/contents/
17.6 shell脚本编程书籍推荐:
《shell脚本专家指南》

若有收获,就点个赞吧
0 人点赞
