:::info 💡 Kafka Stream为我们屏蔽了直接使用Kafka Consumer的复杂性,不用手动进行轮询poll(),不必关心commit()。而且,使用Kafka Stream,可以方便的进行实时计算、实时分析。 :::
WindowBy
根据时间窗口做聚合,是在实时计算中非常重要的功能。比如我们经常需要统计最近一段时间内的count、sum、avg等统计数据。
Kafka中有这样四种时间窗口。
| Window name | Behavior | Short description |
|---|---|---|
| Tumbling time window | Time-based | Fixed-size, non-overlapping, gap-less windows |
| Hopping time window | Time-based | Fixed-size, overlapping windows |
| Sliding time window | Time-based | Fixed-size, overlapping windows that work on differences between record timestamps |
| Session window | Session-based | Dynamically-sized, non-overlapping, data-driven windows |
介绍四种窗口前,先提供一些公用方法,用于下面测试。
private boolean isOldWindow(Windowed<String> windowKey, Long value, Instant initTime) {Instant windowEnd = windowKey.window().endTime();return windowEnd.isBefore(initTime);}private void dealWithTimeWindowAggrValue(Windowed<String> key, Long value) {Windowed<String> windowed = getReadableWindowed(key);System.out.println("处理聚合结果:key=" + windowed + ",value=" + value);}private Windowed<String> getReadableWindowed(Windowed<String> key) {return new Windowed<String>(key.key(), key.window()) {@Overridepublic String toString() {String startTimeStr = toLocalTimeStr(Instant.ofEpochMilli(window().start()));String endTimeStr = toLocalTimeStr(Instant.ofEpochMilli(window().end()));return "[" + key() + "@" + startTimeStr + "/" + endTimeStr + "]";}};}private static String toLocalTimeStr(Instant i) {return i.atZone(ZoneId.systemDefault()).toLocalDateTime().toString();}
/*** Test启动前启动一个KafkaProducer,每1秒产生两条数据,数据的key为“service_1,service_2”,value为“key@当前时间”。*/@BeforeClasspublic static void generateValue() {Properties props = new Properties();props.put("bootstrap.servers", BOOT_STRAP_SERVERS);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("request.required.acks", "0");new Thread(() -> {KafkaProducer<String, String> producer = new KafkaProducer<>(props);try {while (true) {TimeUnit.SECONDS.sleep(1L);Instant now = Instant.now();String key = "service_1";String value = key + "@" + toLocalTimeStr(now);producer.send(new ProducerRecord<>(TEST_TOPIC, key, value));String key2 = "service_2"; // 模拟另一个服务也在发送消息String value2 = key + "@" + toLocalTimeStr(now);producer.send(new ProducerRecord<>(TEST_TOPIC, key2, value2));}} catch (Exception e) {e.printStackTrace();producer.close();}}).start();}
Tumbling time windows
翻滚时间窗口Tumbling time windows是跳跃时间窗口hopping time windows的一种特殊情况,与后者一样,翻滚时间窗也是基于时间间隔的。但它是固定大小、不重叠、无间隙的窗口。翻滚窗口只由一个属性定义:size。翻滚窗口实际上是一种跳跃窗口,其窗口大小与其前进间隔相等。由于翻滚窗口从不重叠,数据记录将只属于一个窗口。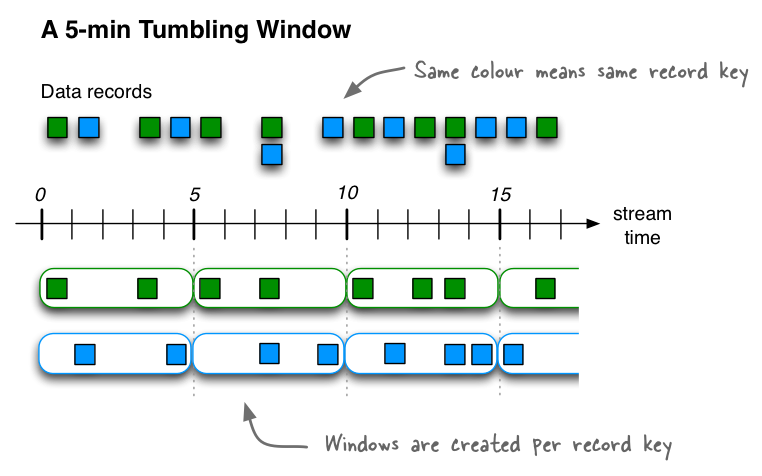
@Testpublic void testTumblingTimeWindows() throws InterruptedException {// kfk连接配置Properties props = configStreamProperties();// stream配置StreamsBuilder builder = new StreamsBuilder();KStream<String, String> data = builder.stream("test_topic");Instant initTime = Instant.now();data.groupByKey()// 5s的时间窗口.windowedBy(TimeWindows.of(Duration.ofSeconds(5L))).count(Materialized.with(Serdes.String(), Serdes.Long())).toStream()// 剔除太旧的时间窗口// 程序二次启动时,会重新读取历史数据进行整套流处理,为了不影响观察,这里过滤掉历史数据.filterNot(((windowedKey, value) -> this.isOldWindow(windowedKey, value, initTime))).foreach(this::dealWithTimeWindowAggrValue);Topology topology = builder.build();KafkaStreams streams = new KafkaStreams(topology, props);streams.start();Thread.currentThread().join();}
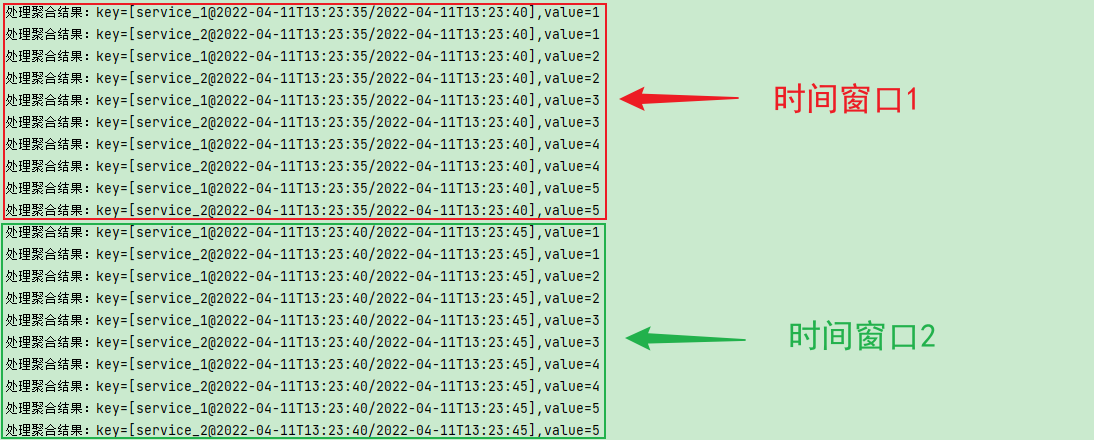
我们的流任务根据key的不同先做group,在进行时间窗口的聚合。结果如图
Hopping time windows
跳跃时间窗口Hopping time windows是基于时间间隔的窗口。它们为固定大小(可能)重叠的窗口建模。跳跃窗口由两个属性定义:窗口的size及其前进间隔advance interval (也称为hop)。前进间隔指定一个窗口相对于前一个窗口向前移动多少。例如,您可以配置一个size为5分钟、advance为1分钟的跳转窗口。由于跳跃窗口可以重叠(通常情况下确实如此),数据记录可能属于多个这样的窗口。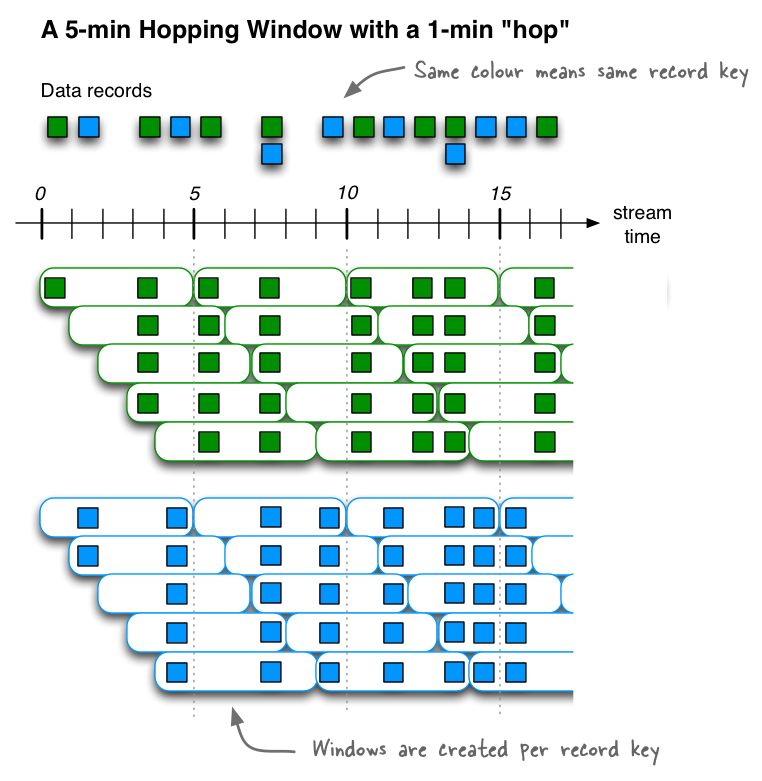

若有收获,就点个赞吧
0 人点赞
