title: ‘Pandas系列二:数据结构’
tags:
- Pandas
categories: - Python
cover: ‘http://qiniu.zhouwenzhen.top/qiniuImg/pandas.jpg‘
abbrlink: 67b94e0d
date: 2020-07-02 16:31:36
Pandas的数据结构
Pandas核心的数据结构有两种,表示一维的series和二维的dataframe,二者可以分别看做是在numpy一维数组和二维数组的基础上增加了相应的标签信息。numpy中关于数组的用法基本可以直接应用到这两个数据结构,包括数据创建、切片访问、通函数、广播机制等
Series
它是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。

Series支持的数据类型包括:
- Python字典
- ndarray
- 标量
如何创建Series?
s1 = pd.Series(data=np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])## ndarrayd = {'a': 1, 'b': 2, 'c': 3}s2 = pd.Series(data=d) ## Python字典s3 = pd.Series(data=d, index=['a', 'm', 'n']) ## Python字典s4 = pd.Series(data=5., index=['a', 'b', 'c', 'd', 'e']) ## 标量index为标签列表
Series的属性操作
理解Series的属性,比如ndim/shape/dtypes/size,分别表示了数据的维数、形状、数据类型和元素个数:
s1 = pd.Series(data=np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])print(s1)
输出的结果为:

print(s1.ndim) ## 1print(s1.shape) ## (5,)print(s1.dtypes) ## float64print(s1.dtype)## float64"""由于pandas允许数据类型是异构的,各列之间可能含有多种不同的数据类型,所以dtype取其复数形式dtypes。与此同时,series因为只有一列,所以数据类型自然也就只有一种,pandas为了兼容二者,series的数据类型属性既可以用dtype也可以用dtypes获取;而dataframe则只能用dtypes。"""print(s1.size)## 5d = {'a': 1, 'b': 2, 'c': 3}s2 = pd.Series(data=d)print(s1.array)"""<PandasArray>[-0.42215731012740565, -1.302176998745536, 0.8425921792645086,0.07607689395042025, 2.845175479227247]Length: 5, dtype: float64"""print(s1.to_numpy()) # [-0.42215731 -1.302177 0.84259218 0.07607689 2.84517548]print(s1.index) # Index(['a', 'b', 'c', 'd', 'e'], dtype='object')print(s1[0]) # -0.42215731012740565print(s1['a']) # -0.42215731012740565print('a' in s1) # Trueprint(s1.get('f'), np.nan) # None nanprint(s1 + s1)"""a -0.844315b -2.604354c 1.685184d 0.152154e 5.690351dtype: float64"""print(s1 + s2)"""a 0.577843b 0.697823c 3.842592d NaNe NaNdtype: float64"""
DataFrame
DataFrame是Pandas中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。

类似于 Excel 、SQL 表,或 Series 对象构成的字典。DataFrame 是最常用的 Pandas 对象,与 Series 一样,DataFrame支持多种类型的输入数据:
- 一维 ndarray、列表、字典、Series 字典
- 二维 numpy.ndarray
- 结构多维数组或记录多维数组
SeriesDataFrame
如何创建DataFrame?
用 Series 字典或字典生成 DataFrame
可以使用多个Serics生成DataFrame:

s1 = pd.Series(data=np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])s2 = pd.Series(data={'a': 1, 'b': 2, 'c': 3})sd = {'one': s1, 'two': s2}d1 = pd.DataFrame(data=sd)print(d1)"""one twoa -2.210606 1.0b -0.260349 2.0c -0.158748 3.0d 0.047268 NaNe 1.588751 NaN"""d2 = pd.DataFrame(sd, index=['d', 'b'])print(d2)"""one twod 0.047268 NaNb -0.260349 2.0"""d3 = pd.DataFrame(sd, columns=['two', 'three'])print(d3)"""two threea 1 NaNb 2 NaNc 3 NaN"""
用多维数组字典、列表字典生成 DataFrame
sd = {'one': [1, 2, 3, 4], 'two': [5, 6, 7, 8]}d1 = pd.DataFrame(data=sd)print(d1)"""one two0 1 51 2 62 3 73 4 8"""d2 = pd.DataFrame(sd, index=['0', '2', '1', '3'])print(d2)"""one two0 1 52 2 61 3 73 4 8"""d3 = pd.DataFrame(sd, columns=['two', 'three'])print(d3)"""two three0 5 NaN1 6 NaN2 7 NaN3 8 NaN"""
用结构多维数组或记录多维数组生成 DataFrame
data = np.zeros((2,), dtype=[('A', 'i4'), ('B', 'f4'), ('C', 'a10')])data[:] = [(1, 1., 'test1'), (2, 2., 'test2')]d1 = pd.DataFrame(data)print(d2)"""A B C0 1 1.0 b'test1'1 2 2.0 b'test2'"""d2 = pd.DataFrame(data, index=['first', 'second'])print(d2)"""A B Cfirst 1 1.0 b'test1'second 2 2.0 b'test2'"""d3 = pd.DataFrame(data, columns=['C', 'A', 'B'])print(d3)"""C A B0 b'test1' 1 1.01 b'test2' 2 2.0"""
用列表字典生成 DataFrame
sd = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]d1 = pd.DataFrame(data=sd)print(d1)"""a b c0 1 2 NaN1 5 10 20.0"""d2 = pd.DataFrame(sd, index=['first', 'second'])print(d2)"""a b cfirst 1 2 NaNsecond 5 10 20.0"""d3 = pd.DataFrame(sd, columns=['a', 'b'])print(d3)"""a b0 1 21 5 10"""
用元组字典生成 DataFrame
d1 = pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})print(d1)"""a bb a c a bA B 1.0 4.0 5.0 8.0 10.0C 2.0 3.0 6.0 7.0 NaND NaN NaN NaN NaN 9.0"""
备选构建器
DataFrame.from_dict
特别注意的是 orient 参数,默认为 columns,把 orient 参数设置为 'index', 即可把字典的键作为行标签。
d1 = pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]))print(d1)"""A B0 1 41 2 52 3 6"""d2 = pd.DataFrame.from_dict(dict([('A', [1, 2, 3]), ('B', [4, 5, 6])]), orient='index', columns=['a', 'b', 'c'])print(d2)"""a b cA 1 2 3B 4 5 6"""
DataFrame.from_records
A BCb'test1' 1 1.0b'test2' 2 2.0
DataFrame的属性操作
提取、设置、删除列
- DataFrame 就像带索引的 Series 字典,提取、设置、删除列的操作与字典类似
用方法链分配新列
- DataFrame 提供了
assign()方法,可以利用现有的列创建新列,assign返回的都是数据副本,原 DataFrame 不变
索引 / 选择
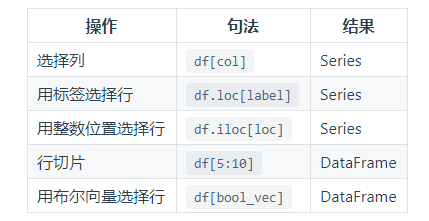
数据对齐和运算
sd = {'one': [1, 2, 3, 4], 'two': [5, 6, 7, 8]}d1 = pd.DataFrame(data=sd)print(d1)"""one two0 1 51 2 62 3 73 4 8"""print(d1 + d1)"""one two0 2 101 4 122 6 143 8 16"""###布尔运算d1 = pd.DataFrame({'a': [1, 0, 1], 'b': [0, 1, 1]}, dtype=bool)d2 = pd.DataFrame({'a': [0, 1, 1], 'b': [1, 1, 0]}, dtype=bool)print(d1 & d2)"""a b0 False False1 False True2 True False"""
转置
sd = {'one': [1, 2, 3, 4], 'two': [5, 6, 7, 8]}d1 = pd.DataFrame(data=sd)print(d1)"""one two0 1 51 2 62 3 73 4 8"""print(d1.T)"""0 1 2 3one 1 2 3 4two 5 6 7 8"""
DataFrame 应用 NumPy 函数
Series 与 DataFrame 可使用 log、exp、sqrt 等多种元素级 NumPy 通用函数(ufunc) ,假设 DataFrame 的数据都是数字。
sd = {'one': [1, 2, 3, 4], 'two': [5, 6, 7, 8]}d1 = pd.DataFrame(data=sd)print(d1)"""one two0 1 51 2 62 3 73 4 8"""print(np.exp(d1))"""one two0 2.718282 148.4131591 7.389056 403.4287932 20.085537 1096.6331583 54.598150 2980.957987"""print(np.asarray(d1))"""[[1 5][2 6][3 7][4 8]]"""
Serics和DataFrame 的重构结构属性
- rename,对标签名重命名,也可以重置index和columns的部分标签列信息,接收标量(用于对标签名重命名)或字典(用于重命名行标签和列标签)
- reindex,接收一个新的序列与已有标签列匹配,当原标签列中不存在相应信息时,填充NAN或者可选的填充值
- set_index/reset_index,互为逆操作,前者是将已有的一列信息设置为标签列,而后者是将原标签列归为数据,并重置为默认数字标签
- set_axis,设置标签列,一次只能设置一列信息,与rename功能相近,但接收参数为一个序列更改全部标签列信息(rename中是接收字典,允许只更改部分信息)
- rename_axis,重命名标签名,rename中也可实现相同功能

若有收获,就点个赞吧
0 人点赞

{kind=link}