fdisk指令
语法
fdisk(选项)(参数)
选项
-l 查看所有的分区-b <大小> 扇区大小(512、1024、2048或4096)-c[=<模式>] 兼容模式:“dos”或“nondos”(默认)-h 打印此帮助文本-u[=<单位>] 显示单位:“cylinders”(柱面)或“sectors”(扇区,默认)-v 打印程序版本-C <数字> 指定柱面数-H <数字> 指定磁头数-S <数字> 指定每个磁道的扇区数
fdisk分区方法
fdisk的命令行用法为: fdisk 硬盘设备名 例如:fdisk /dev/sdb
进入fdisk后,首先键入’m’,即可显示fdisk全部菜单。
command (m for help): mCommand actiona toggle a bootable flagb edit bsd disklabelc toggle the dos compatibility flagd delete a partition :删除磁盘l list known partition types 列出磁盘信息m print this menun add a new partition 新加磁盘o create a new empty DOS partition tablep print the partition table 列出当前磁盘分区情况q quit without saving changess create a new empty Sun disklabelt change a partition's system idu change display/entry unitsv verify the partition tablew write table to disk and exitx extra functionality (experts only)
再键入’p’,显示当前分区表状态。
Command (m for help): pDisk /dev/sdb: 3221 MB, 3221225472 bytes255 heads, 63 sectors/track, 391 cylindersUnits = cylinders of 16065 * 512 = 8225280 bytesDevice Boot Start End Blocks Id System/dev/sdb1 1 1 8001 8e Linux LVM/dev/sdb2 2 26 200812+ 83 Linux
上面的磁盘信息中,sdb大小总共3221M,255个柱头,63个扇区,391个柱面。
磁头数(Heads)表示硬盘总共有几个磁头,也就是有几面盘片, 最大为 255 (用 8 个二进制位存储);柱面数(Cylinders) 表示硬盘每一面盘片上有几条磁道,最大为 1023(用 10 个二进制位存储);扇区数(Sectors) 表示每一条磁道上有几个扇区, 最大为 63(用 6个二进制位存储);每个扇区一般是 512个字节, 理论上讲这不是必须的,但好像没有取别的值的。然后看start-Edn对应的两列,是表示柱面的开始与结束。目前只用到26,剩下可用的为391-26个柱面。每个分区对应的Id是磁盘是什么类型的分区,主分区或是交换分区,或者是扩展分区等。
删除分区
举例删除刚才那两个分区
Command (m for help): dPartition number (1-4): 1Command (m for help): dSelected partition 2
然后再输入print 查看当前磁盘信息
建立新分区
Command (m for help): nCommand actione extendedp primary partition (1-4) p //建立主分区Partition number (1-4): 1 //分区号First cylinder (1-391, default 1): //分区起始位置Using default value 1last cylinder or +size or +sizeM or +sizeK (1-391, default 391): 100 //分区结束位置,单位为扇区Command (m for help): n //再建立一个分区Command actione extendedp primary partition (1-4)pPartition number (1-4): 2 //分区号为2First cylinder (101-391, default 101):Using default value 101Last cylinder or +size or +sizeM or +sizeK (101-391, default 391): +200M / /分区结束位置,单位为M
然后输入p,可以看到磁盘分区已经分好。
建立逻辑分区
Command (m for help): nCommand actione extendedp primary partition (1-4) e //选择扩展分区Partition number (1-4): 3First cylinder (126-391, default 126):Using default value 126 Last cylinder or +size or +sizeM or +sizeK (126-391, default 391):Using default value 391
然后再输入p,查看磁盘分区信息。
在扩展分区上建立两个逻辑分区
Command (m for help): nCommand actionl logical (5 or over)p primary partition (1-4) l //选择逻辑分区First cylinder (126-391, default 126):Using default value 126Last cylinder or +size or +sizeM or +sizeK (126-391, default 391): +400M
最后确认所有分区建立成功。
Command (m for help):p Disk /dev/sdb: 3221 MB, 3221225472 bytes255 heads, 63 sectors/track, 391 cylindersUnits = cylinders of 16065 * 512 = 8225280 bytesDevice Boot Start End Blocks Id System/dev/sdb1 1 100 803218+ 83 Linux/dev/sdb2 101 125 200812+ 83 Linux/dev/sdb3 126 391 2136645 5 Extended/dev/sdb5 126 175 401593+ 83 Linux
保存退出
Command (m for help): wThe partition table has been altered!Calling ioctl() to re-read partition table.Syncing disks.
建立好分区之后我们还需要对分区进行格式化才能在系统中使用磁盘。
mkfs.ext2 /dev/sdb1
dd指令
dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。
参数说明:
- if=文件名:输入文件名,默认为标准输入。即指定源文件。
- of=文件名:输出文件名,默认为标准输出。即指定目的文件。
- ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
- obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
- bs=bytes:同时设置读入/输出的块大小为bytes个字节。
- cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
- skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
- seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
- count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
- conv=<关键字>,关键字可以有以下11种:
- conversion:用指定的参数转换文件。
- ascii:转换ebcdic为ascii
- ebcdic:转换ascii为ebcdic
- ibm:转换ascii为alternate ebcdic
- block:把每一行转换为长度为cbs,不足部分用空格填充
- unblock:使每一行的长度都为cbs,不足部分用空格填充
- lcase:把大写字符转换为小写字符
- ucase:把小写字符转换为大写字符
- swap:交换输入的每对字节
- noerror:出错时不停止
- notrunc:不截短输出文件
- sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
- —help:显示帮助信息
- —version:显示版本信息
mkfs指令
该命令用来在特定的分区创建linux文件系统,常见的文件系统有ext2,ext3,vfat等,执行mkfs命令其实是在调用:mkfs.ext3 | mkfs.reiserfs |mkfs.ext2 | mkdosfs | mkfs.msdos | mkfs.vfat比如:
mkfs.ext3 /dev/sda6 # 把该设备格式化成ext3文件系统
mke2fs -j /dev/sda6 # 把该设备格式化成ext3文件系统
mkfs.reiserfs /dev/sda6 # 格式化成reiserfs文件系统
mkfs.vfat /dev/sda6 # 格式化成fat32文件系统
mkfs.msdos /dev/sda6 # 格式化成fat16文件系统,msdos就是fat16
mkdosfs /dev/sda6 # 格式化成msdos文件系统
pkg-config指令
介绍
pkg-config在编译应用程序和库的时候作为一个工具来使用。例如你在命令行通过如下命令编译程序时:
gcc -o test test.c `pkg-config --libs --cflags glib-2.0`
pkg-config可以帮助你插入正确的编译选项,而不需要你通过硬编码的方式来找到glib(或其他库)。
--cflags:一般用于指定头文件--libs一般用于指定库文件
大家应该都知道一般用第三方库的时候,就少不了要使用到第三方的头文件和库文件。我们在编译、链接的时候,必须要指定这些头文件和库文件的位置。对于一个比较大的第三方库,其头文件和库文件的数量是比较多的,如果我们一个个手动地写,那将是相当的麻烦的。因此,pkg-config就应运而生了。pkg-config能够把这些头文件和库文件的位置指出来,给编译器使用。pkg-config主要提供了下面几个功能:
- 检查库的版本号。 如果所需要的库的版本不满足要求,它会打印出错误信息,避免链接错误版本的库文件
- 获得编译预处理参数,如宏定义、头文件的位置
- 获得链接参数,如库及依赖的其他库的位置,文件名及其他一些链接参数
- 自动加入所依赖的其他库的设置
pkg-config命令的基本用法如下:
pkg-config <options> <library-name>
例如,我们可以通过如下命令来查看当前安装了哪些库:
配置环境变量
事实上,pkg-config只是一个工具,所以不是你安装了一个第三方库,pkg-config就能知道第三方库的头文件和库文件的位置的。为了让pkg-config可以得到一个库的信息,就要求库的提供者提供一个.pc文件。默认情况下,比如执行如下命令:
pkg-config --libs --cflags glib-2.0
pkg-config会到/usr/lib/pkconfig/目录下去寻找glib-2.0.pc文件。也就是说在此目录下的.pc文件,pkg-config是可以自动找到的。然而假如我们安装了一个库,其生成的.pc文件并不在这个默认目录中的话,pkg-config就找不到了。此时我们需要通过PKG_CONFIG_PATH环境变量来指定pkg-config还应该在哪些地方去寻找.pc文件。
我们可以通过如下命令来设置PKG_CONFIG_PATH环境变量:
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig/
这样pkg-config就会在/usr/local/lib/pkgconfig/目录下寻找.pc文件了。
pkg-config与LD_LIBRARY_PATH
pkg-config与LD_LIBRARY_PATH在使用时有些类似,都可以帮助找到对应的库(静态库和共享库)。这里我们重点介绍一下它们两者的区别。我们知道一个程序从源代码,然后编译连接,最后再执行这一基本过程。这里我们列出pkg-config与LD_LIBRARY_PATH的主要工作阶段:
pkg-config: 编译时、 链接时LD_LIBRARY_PATH: 链接时、 运行时
pkg-config主要是在编译时会用到其来查找对应的头文件、链接库等;而LD_LIBRARY_PATH环境变量则在链接时和运行时会用到。程序编译出来之后,在程序加载执行时也会通过LD_LIBRARY_PATH环境变量来查询所需要的库文件。
下面我们来讲述一下LD_LIBRARY_PATH及ldconfig命令库文件在链接(静态库和共享库)和运行(仅限于使用共享库的程序)时被使用,其搜索路径是在系统中进行设置的。一般Linux系统把/lib和/usr/lib这两个目录作为默认的库搜索路径,所以使用这两个目录中的库时不需要进行设置搜索路径即可直接使用。对于处于默认库搜索路径之外的库,需要将库的位置添加到库的搜索路径之中。设置库文件的搜索路径有下列两种方式,可任选其中一种使用:
- 在环境变量
LD_LIBRARY_PATH中指明库的搜索路径 - 在
/etc/ld.so.conf文件中添加库的搜索路径
将自己可能存放库文件的路径都加入到/etc/ld.so.conf中是明智的选择。添加方法也及其简单,将库文件的绝对路径直接写进去就OK了,一行一个。比如:
/usr/X11R6/lib
/usr/local/lib
/opt/lib
需要注意的是:第二种搜索路径的设置方式对于程序链接时的库(包括共享库和静态库)的定位已经足够了。但是对于使用了共享库的程序的执行还是不够的,这是因为为了加快程序执行时对共享库的定位速度,避免使用搜索路径查找共享库的低效率,所以是直接读取库列表文件/etc/ld.so.cache的方式从中进行搜索。/etc/ld.so.cache是一个非文本的数据文件,不能直接编辑,它是根据/etc/ld.so.conf中设置的搜索路径由/sbin/ldconfig命令将这些搜索路径下的共享库文件集中在一起而生成的(ldconfig命令要以root权限执行)。因此为了保证程序执行时对库的定位,在/etc/ld.so.conf中进行了库搜索路径的设置之后,还必须要运行/sbin/ldconfig命令更新/etc/ld.so.cache文件之后才可以。ldconfig,简单的说,它的作用就是将/etc/ld.so.conf列出的路径下的库文件缓存到/etc/ld.so.cache以供使用。因此当安装完一些库文件(例如刚安装好glib),或者修改ld.so.conf增加新的库路径之后,需要运行一下/sbin/ldconfig使所有的库文件都被缓存到ld.so.cache中。如果没有这样做,即使库文件明明就在/usr/lib下的,也是不会被使用的,结果在编译过程中报错。 在程序链接时,对于库文件(静态库和共享库)的搜索路径,除了上面的设置方式之外,还可以通过-L参数显示指定。因为用-L设置的路径将被优先搜索,所以在链接的时候通常都会以这种方式直接指定要链接的库的路径。 前面已经说明过了,库搜索路径的设置有两种方式:在环境变量LD_LIBRARY_PATH中设置以及在/etc/ld.so.conf文件中设置。其中,第二种设置方式需要root权限,以改变/etc/ld.so.conf文件并执行/sbin/ldconfig命令。而且,当系统重新启动后,所有的基于GTK2的程序在运行时都将使用新安装的GTK+库。不幸的是,由于GTK+版本的改变,这有时会给应用程序带来兼容性的问题,造成某些程序运行不正常。为了避免出现上面的这些情况,在GTK+`及其依赖库的安装过程中对于库的搜索路径的设置将采用第一种方式进行。这种设置方式不需要root权限,设置也简单:
export LD_LIBRARY_PATH=/opt/gtk/lib:$LD_LIBRARY_PATH
pc文件书写规范
这里我们首先来看一个例子: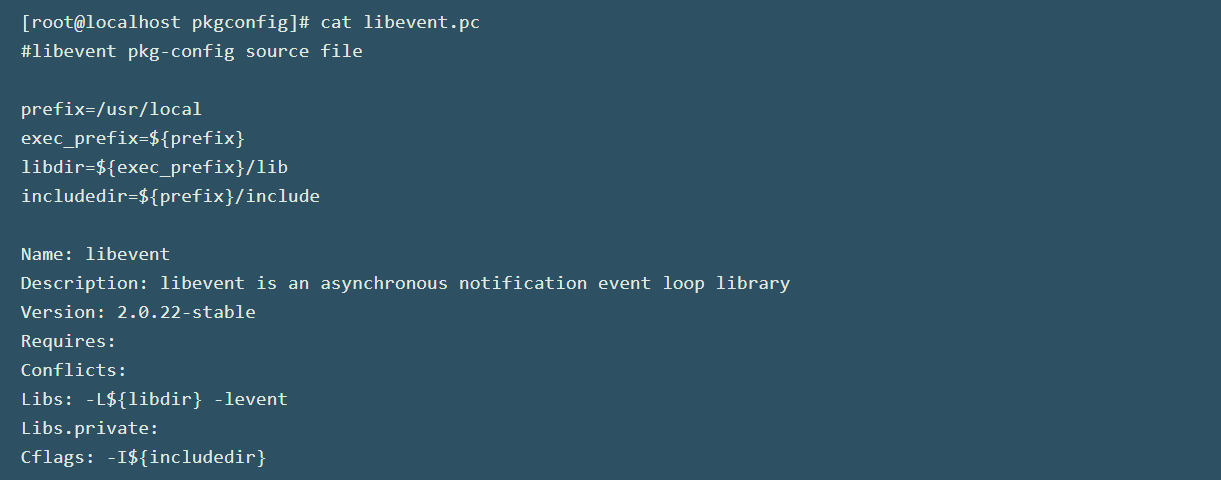
这是libevent库的一个真实的例子。下面我们简单描述一下pc文件中的用到的一些关键词:
Name: 一个针对library或package的便于人阅读的名称。这个名称可以是任意的,它并不会影响到pkg-config的使用,pkg-config是采用pc文件名的方式来工作的。Description: 对package的简短描述。URL: 人们可以通过该URL地址来获取package的更多信息或者package的下载地址。Version: 指定package版本号的字符串。Requires: 本库所依赖的其他库文件。所依赖的库文件的版本号可以通过使用如下比较操作符指定:=,<,>,<=,>=。Requires.private: 本库所依赖的一些私有库文件,但是这些私有库文件并不需要暴露给应用程序。这些私有库文件的版本指定方式与Requires中描述的类似。Conflicts: 是一个可选字段,其主要用于描述与本package所冲突的其他package。版本号的描述也与Requires中的描述类似。本字段也可以取值为同一个package的多个不同版本实例。例如:Conflicts: bar < 1.2.3, bar >= 1.3.0。Cflags: 编译器编译本package时所指定的编译选项,和其他并不支持pkg-config的library的一些编译选项值。假如所需要的library支持pkg-config,则它们应该被添加到Requires或者Requires.private中。Libs: 链接本库时所需要的一些链接选项,和其他一些并不支持pkg-config的library的链接选项值。与Cflags类似`。Libs.private: 本库所需要的一些私有库的链接选项。
cut指令
cut [-bn] [file]
cut [-c] [file]
cut [-df] [file]
cut命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段写至标准输出。如果不指定File参数,cut命令将读取标准输入。
-b:以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了-n标志。-c:以字符为单位进行分割。-d:自定义分隔符,默认为制表符。-f:与-d一起使用,指定显示哪个区域。-n:搭配-b选项使用: 表示不要分割多字节字符。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除。--complement: 补全选中的字节、字符或域-s,--only-delimited: 不打印没有包含分界符的行--output-delimiter=STRING: 使用STRING作为输出分隔符
-c或-b指定了你想从file中的每行内提取哪些字符(依据位置)。这可以是单个数字,如-c5可以从输入的每行中提取第5个字符;以逗号分隔的数字列表,如-c1,13,50,可以提取第1个、第13个及第50个字符;以连接符分隔的数字范围,如-c20-50,可以提取第 20~50 个字符。要提取从指定位置到行尾的所有字符,只需要忽略范围写法中的第二个数字就可以了:cut -c5- data。
例如:
有如下两个文件:test1.txt文件以TAB键分割,中间还有一行空行
test2.txt文件
剪切单个字节

剪切多个字节
剪切字符

这里我们看到出现乱码,因为-b只是针对字节进行裁剪,对一个汉字进行字节裁剪,得到的结果必然是乱码,若想使用-b命令对字节进行裁剪,那么则需要使用-n选项,此选项的作用是取消分割多字节字符。

剪切指定域上面的-b、-c只是针对于格式固定的数据中剪切,但是对于一些格式不固定的,就没有办法获取到我们想要的数据,因此便有了-f域的概念
将上面的第一个:前面的字符给剪切出来,那么我们就可以使用-d命令,指定其分割符为:然后再选取第一个域内的内容即可: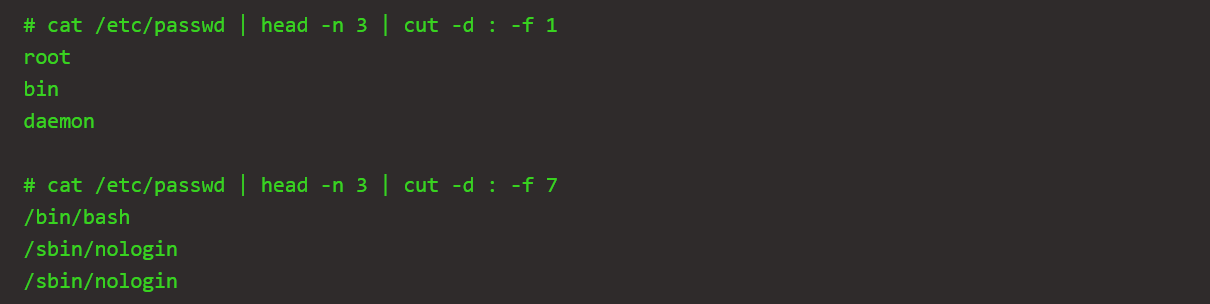
paste指令
paste [-s][-d <间隔字符>][--help][--version][文件...]
由files指定的每个文件中对应的行被粘贴或合并在一起,形成了一行,然后写入到标准输出中。连接符-可以用在files中,将输入源指定为标准输入。
假设有一个名为names的文件,其中是一系列姓名:

假设还有另一个名为numbers的文件,其中包含了names文件中姓名所对应的电话号码:
你可以使用paste命令并排打印出姓名和电话号码:
names文件中的每一行都和numbers文件中对应的行一同被打印出来,两者之间由制表符分隔。
下一个例子演示了多个文件合并时的情形:

-d选项如果你不希望使用制表符作为输出字段的分隔符,可以通过-d选项来指定:
-dchars
chars可以是一个或多个字符,用于分隔粘贴在一起的行。也就是说,chars中的第一个字符用来分隔来自第一个文件和第二个文件的行,第二个字符用来分隔来自第二个文件和第三个文件的行,以此类推。
如果文件的数量比chars中列出的字符要多,paste会绕回(wraps around)到字符列表头部,重新开始。-d选项的最简单形式就是只指定单个分隔符,该分隔符用来分隔粘贴的所有字段:
-s选项-s选项告诉paste只从同一个文件中粘贴行,不管其他文件。如果只指定了单个文件,其效果是将该文件中所有的行合并到一起,彼此之间用制表符分隔(或是由-d选项指定的分隔符)。
在上一个例子中,ls的输出通过管道传给了paste,后者将来自标准输入(-)的所有行(-s选项)进行合并,字段之间使用单个空格(-d' '选项)分隔。
sed指令
sed处理流程
sed会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
- 每次仅读取一行内容;
- 根据提供的规则命令匹配并修改数据。注意,
sed默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据 - 将执行结果输出。
- 当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕
sed指令的格式
sed命令的基本格式如下:
sed [选项] [脚本命令] 文件名
sed命令常用选项及含义
| 选项 | 描述 |
|---|---|
| -e 脚本命令 | 该选项会将其后跟的脚本命令添加到已有的命令中。 |
| -f 脚本命令文件 | 该选项会将其后文件中的脚本命令添加到已有的命令中。 |
| -n | 默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。 |
| -i | 此选项会直接修改源文件,要慎用。 |
sed替换操作
此命令的基本格式为:
[address]s/pattern/replacement/flags
address: 表示指定要操作的具体行pattern: 指的是需要替换的内容replacement: 指的是要替换的新内容flags: 标记功能
flags标记选项
| flags标记 | 功能 |
|---|---|
| n | 1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换,例如,一行中有 3 个 A,但用户只想替换第二个 A,这是就用到这个标记; |
| g | 对数据中所有匹配到的内容进行替换,如果没有 g,则只会在第一次匹配成功时做替换操作。例如,一行数据中有 3 个 A,则只会替换第一个 A; |
| p | 会打印与替换命令中指定的模式匹配的行。此标记通常与 -n 选项一起使用。 |
| w file | 将缓冲区中的内容写到指定的 file 文件中; |
| & | 用正则表达式匹配的内容进行替换; |
| \n | 匹配第 n 个子串,该子串之前在 pattern 中用 \(\) 指定。 |
| \ | 转义(转义替换部分包含:&、\ 等)。 |
示例一 比如,可以指定sed用新文本替换第几处模式匹配的地方:  可以看到,使用数字2作为标记的结果就是,
可以看到,使用数字2作为标记的结果就是,sed编辑器只替换每行中第2次出现的匹配模式。
示例二如果要用新文件替换所有匹配的字符串,可以使用g标记:

示例三我们知道-n选项会禁止sed输出,但p标记会输出修改过的行,将二者匹配使用的效果就是只输出被替换命令修改过的行,例如:
示例四w标记会将匹配后的结果保存到指定文件中,比如:
示例五在使用s脚本命令时,替换类似文件路径的字符串会比较麻烦,需要将路径中的正斜线进行转义,例如:
sed删除操作
此命令的基本格式为:
[address]d
如果需要删除文本中的特定行,可以用d脚本命令,它会删除指定行中的所有内容。但使用该命令时要特别小心,如果你忘记指定具体行的话,文件中的所有内容都会被删除。
示例一删除文件所有内容: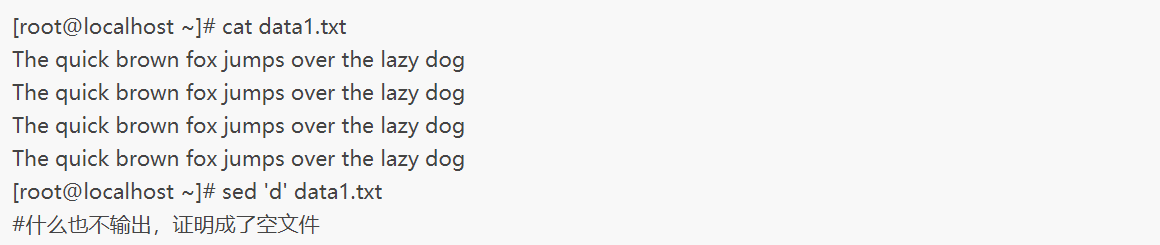
示例二通过行号指定,比如删除data6.txt文件内容中的第3行:
示例三或者通过特定行区间指定,比如删除data6.txt文件内容中的第 2、3行:
示例四也可以使用两个文本模式来删除某个区间内的行,但这么做时要小心,你指定的第一个模式会打开行删除功能,第二个模式会关闭行删除功能,因此,sed会删除两个指定行之间的所有行(包括指定的行),例如:
示例五通过特殊的文件结尾字符,比如删除data6.txt文件内容中第3行开始的所有的内容:
sed插入操作
指令格式:
[address]a(或 i)\新文本内容
a命令表示在指定行的后面附加一行i命令表示在指定行的前面插入一行
示例一将一个新行插入到数据流第三行前,执行命令如下:
示例二将一个新行附加到数据流中第三行后,执行命令如下:
示例三如果你想将一个多行数据添加到数据流中,只需对要插入或附加的文本中的每一行末尾(除最后一行)添加反斜线即可,例如: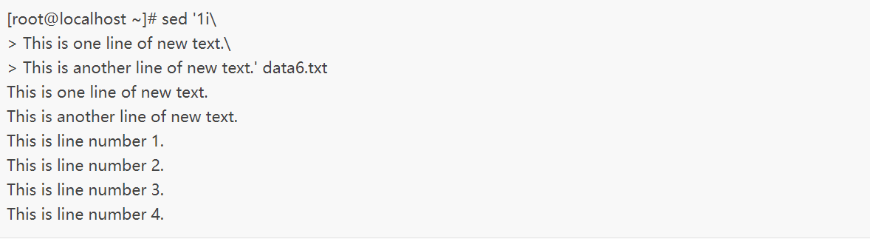
sed替换行操作
c命令表示将指定行中的所有内容,替换成该选项后面的字符串。该命令的基本格式为:
[address]c\用于替换的新文本
示例
sed处理单字符操作
y转换命令是唯一可以处理单个字符的sed脚本命令,其基本格式如下:
[address]y/inchars/outchars/
转换命令会对inchars和outchars值进行一对一的映射,即inchars中的第一个字符会被转换为outchars中的第一个字符,第二个字符会被转换成outchars中的第二个字符。这个映射过程会一直持续到处理完指定字符。如果inchars和outchars的长度不同,则sed 会产生一条错误消息。
转换命令是一个全局命令,也就是说,它会文本行中找到的所有指定字符自动进行转换,而不会考虑它们出现的位置。
示例一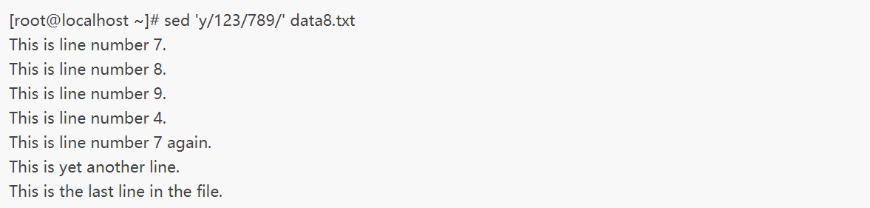
可以看到,inchars模式中指定字符的每个实例都会被替换成outchars模式中相同位置的那个字符。
示例二
sed转换了在文本行中匹配到的字符1的两个实例,我们无法限定只转换在特定地方出现的字符。
sed的打印操作
p命令表示搜索符号条件的行,并输出该行的内容,此命令的基本格式为:
[address]p
p命令常见的用法是打印包含匹配文本模式的行,例如: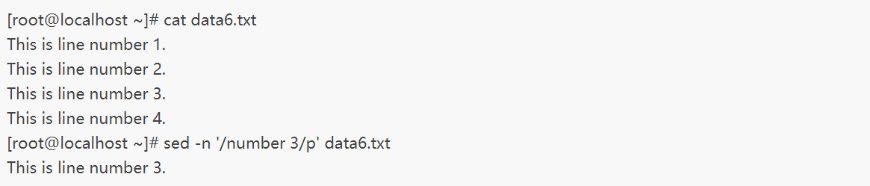
可以看到,用-n选项和p命令配合使用,我们可以禁止输出其他行,只打印包含匹配文本模式的行。
如果需要在修改之前查看行,也可以使用打印命令,比如与替换或修改命令一起使用。可以创建一个脚本在修改行之前显示该行,如下所示:
sed命令会查找包含数字3的行,然后执行两条命令。首先,脚本用p命令来打印出原始行;然后它用s命令替换文本,并用p标记打印出替换结果。输出同时显示了原来的行文本和新的行文本。
sed写入文件操作
w命令用来将文本中指定行的内容写入文件中,此命令的基本格式如下:
[address]w filename
这里的filename表示文件名,可以使用相对路径或绝对路径,但不管是哪种,运行sed命令的用户都必须有文件的写权限。
示例一将数据流中的前两行打印到一个文本文件中: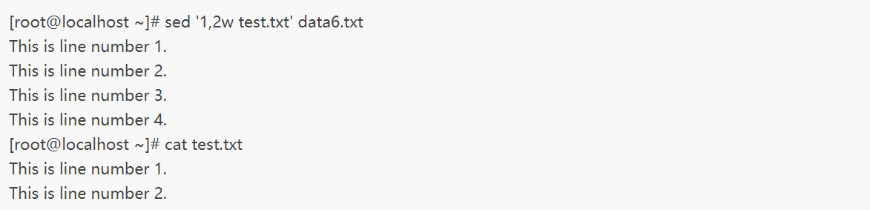
示例二当然,如果不想让行直接输出,可以用-n选项,再举个例子:
可以看到,通过使用w脚本命令,sed可以实现将包含文本模式的数据行写入目标文件。
sed的读取文件插入
r命令用于将一个独立文件的数据插入到当前数据流的指定位置,该命令的基本格式为:
[address]r filename
示例一sed命令会将filename文件中的内容插入到address指定行的后面。
示例二如果你想将指定文件中的数据插入到数据流的末尾,可以使用$地址符,例如:
sed的退出指令
q命令的作用是使sed命令在第一次匹配任务结束后,退出sed程序,不再进行对后续数据的处理。
比如:
可以看到,sed命令在打印输出第2行之后,就停止了,是q命令造成的,再比如:
使用q命令之后,sed命令会在匹配到number 1时,将其替换成number 0,然后直接退出。
sed命令的寻址方式
对各个脚本命令来说,address用来表明该脚本命令作用到文本中的具体行。
默认情况下,sed命令会作用于文本数据的所有行。如果只想将命令作用于特定行或某些行,则必须写明address部分,表示的方法有以下2种:
- 以数字形式指定行区间
- 用文本模式指定具体行区间
以上两种形式都可以使用如下这2种格式,分别是:
[address]脚本命令
或者
address {
多个脚本命令
}
以数字形式指定行区间
当使用数字方式的行寻址时,可以用行在文本流中的行位置来引用。sed会将文本流中的第一行编号为1,然后继续按顺序为接下来的行分配行号。
在脚本命令中,指定的地址可以是单个行号,或是用起始行号、逗号以及结尾行号指定的一定区间范围内的行。这里举一个sed命令作用到指定行号的例子:
可以看到,sed只修改地址指定的第二行的文本。下面的例子中使用了行地址区间:
在此基础上,如果想将命令作用到文本中从某行开始的所有行,可以用特殊地址$:
用文本模式指定行区间
sed允许指定文本模式来过滤出命令要作用的行,格式如下:
/pattern/command
注意,必须用正斜线将要指定的pattern封起来,sed会将该命令作用到包含指定文本模式的行上。
举个例子,如果你想只修改用户demo的默认shell,可以使用sed命令,执行命令如下: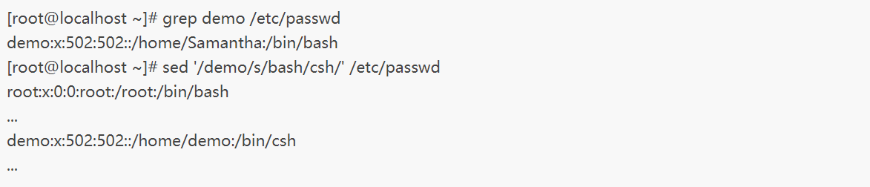
虽然使用固定文本模式能帮你过滤出特定的值,就跟上面这个用户名的例子一样,但其作用难免有限,因此,sed允许在文本模式使用正则表达式指明作用的具体行。正则表达式允许创建高级文本模式匹配表达式来匹配各种数据。这些表达式结合了一系列通配符、特殊字符以及固定文本字符来生成能够匹配几乎任何形式文本的简练模式。
sed多行命令
sed包含了三个可用来处理多行文本的特殊命令,分别是:
Next命令(N):将数据流中的下一行加进来创建一个多行组来处理。Delete(D):删除多行组中的一行。Print(P):打印多行组中的一行。
N多行操作命令
N命令会将下一行文本内容添加到缓冲区已有数据之后(之间用换行符分隔),从而使前后两个文本行同时位于缓冲区中,sed命令会将这两行数据当成一行来处理。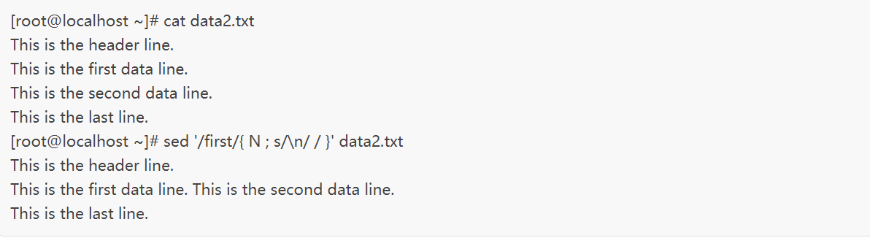
在这个例子中,sed命令查找含有单词first的那行文本。找到该行后,它会用N命令将下一行合并到那行,然后用替换命令s将换行符替换成空格。结果是,文本文件中的两行在sed的输出中成了一行。
如果要在数据文件中查找一个可能会分散在两行中的文本短语,如何实现呢?这里给大家一个实例: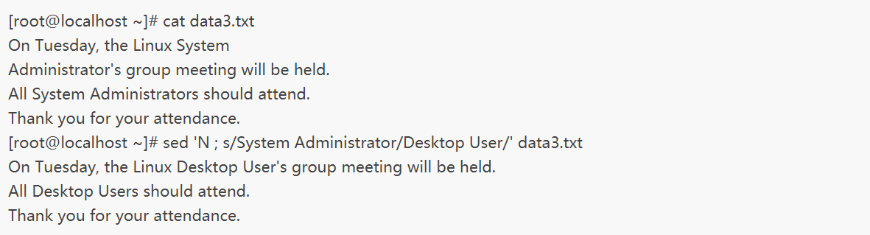
用N命令将发现第一个单词的那行和下一行合并后,即使短语内出现了换行,你仍然可以找到它,这是因为,替换命令在System和 Administrator之间用了通配符(.)来匹配空格和换行符这两种情况。但当它匹配了换行符时,它就从字符串中删掉了换行符,导致两行合并成一行。这可能不是你想要的。
要解决这个问题,可以在sed脚本中用两个替换命令,一个用来匹配短语出现在多行中的情况,一个用来匹配短语出现在单行中的情况,比如:
第一个替换命令专门查找两个单词间的换行符,并将它放在了替换字符串中。这样就能在第一个替换命令专门在两个检索词之间寻找换行符,并将其纳入替换字符串。这样就允许在新文本的同样位置添加换行符了。
但这个脚本中仍有个小问题,即它总是在执行sed命令前将下一行文本读入到缓冲区中,当它到了后一行文本时,就没有下一行可读了,此时N命令会叫sed程序停止,这就导致,如果要匹配的文本正好在最后一行中,sed命令将不会发现要匹配的数据。
解决这个bug的方法是,将单行命令放到N命令前面,将多行命令放到N命令后面,像这样: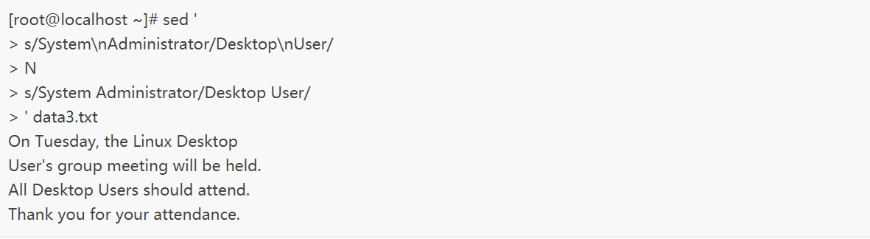
现在,查找单行中短语的替换命令在数据流的后一行也能正常工作,多行替换命令则会负责短语出现在数据流中间的情况。
D多行删除命令
sed不仅提供了单行删除命令(d),也提供了多行删除命令D,其作用是只删除缓冲区中的第一行,也就是说,D命令将缓冲区中第一个换行符(包括换行符)之前的内容删除掉。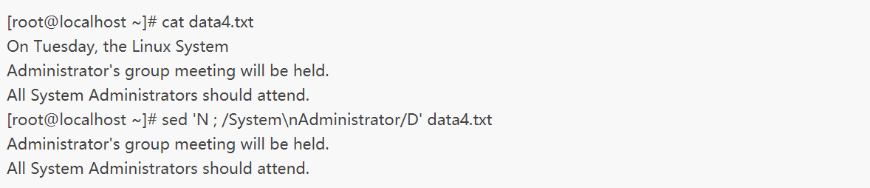
文本的第二行被N命令加到了缓冲区,因此sed命令第一次匹配就是成功,而D命令会将缓冲区中第一个换行符之前(也就是第一行)的数据删除,所以,得到了如上所示的结果。
下面的例子中,它会删除数据流中出现在第一行前的空白行: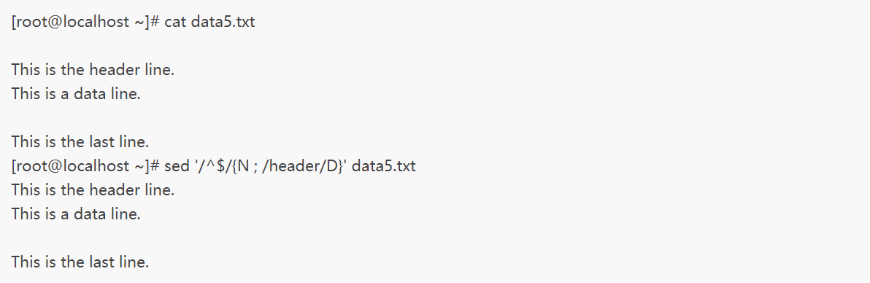
sed会查找空白行,然后用N命令来将下一文本行添加到缓冲区。此时如果缓冲区的内容中含有单词header,则D命令会删除缓冲区中的第一行。
P多行打印命令
同d和D之间的区别一样,P(大写)命令和单行打印命令p(小写)不同,对于具有多行数据的缓冲区来说,它只会打印缓冲区中的第一行,也就是首个换行符之前的所有内容。
例如,test.txt文件中的内容如下:
下面是对test.txt文件中的内容分别用p命令和P命令后,产生的输出信息的对比。
第一个sed命令,每次都使用N将下一行内容追加到缓冲区内容的后面(用换行符间隔),也就是说,第一次时缓冲区中的内容为aaa\nbbb,但P(大写) 命令的作用的打印换行符之前的内容,也就是aaa,之后则是sed在自动输出功能输出aaa和bbb(sed命令会自动将\n输出为换行),依次类推,就输出了所看到的结果。
第二个sed命令,使用的是p(小写)单行打印命令,它会将缓冲区中的所有内容全部打印出来(\n会自动输出为换行),因此,出现了看到的结果。
sed保持空间
前面我们一直说,sed命令处理的是缓冲区中的内容,其实这里的缓冲区,应称为模式空间。值得一提的是,模式空间并不是sed命令保存文件的唯一空间。sed还有另一块称为保持空间的缓冲区域,它可以用来临时存储一些数据。
| 命令 | 描述 |
|---|---|
| h | 将模式空间中的内容复制到保持空间 |
| H | 将模式空间中的内容附加到保持空间 |
| g | 将保持空间中的内容复制到模式空间 |
| G | 将保持空间中的内容附加到模式空间 |
| x | 交换模式空间和保持空间中的内容 |
通常,在使用 h或 H命令将字符串移动到保持空间后,最终还要用 g、 G或 x命令将保存的字符串移回模式空间。保持空间最直接的作用是,一旦我们将模式空间中所有的文件复制到保持空间中,就可以清空模式空间来加载其他要处理的文本内容。 由于有两个缓冲区域,下面的例子中演示了如何用 h和 g命令来将数据在 sed缓冲区之间移动。

这个例子的运行过程是这样的:
sed脚本命令用正则表达式过滤出含有单词first的行- 当含有单词
first的行出现时,h命令将该行放到保持空间 p命令打印模式空间也就是第一个数据行的内容n命令提取数据流中的下一行(This is the second data line),并将它放到模式空间p命令打印模式空间的内容,现在是第二个数据行g命令将保持空间的内容(This is the first data line)放回模式空间,替换当前文本p命令打印模式空间的当前内容,现在变回第一个数据行了
sed改变指定流程
b分支命令
通常,sed程序的执行过程会从第一个脚本命令开始,一直执行到最后一个脚本命令(D命令是个例外,它会强制sed返回到脚本的顶部,而不读取新的行)。sed提供了b分支命令来改变命令脚本的执行流程,其结果与结构化编程类似。b分支命令基本格式为:
[address]b [label]
其中,address参数决定了哪些行的数据会触发分支命令,label参数定义了要跳转到的位置。
需要注意的是,如果没有加label参数,跳转命令会跳转到脚本的结尾,比如: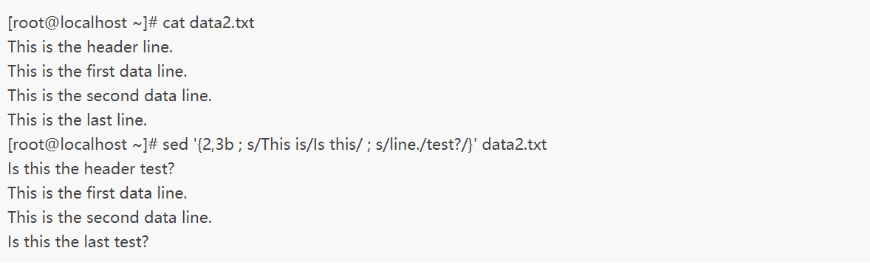
可以看到,因为b命令未指定label参数,因此数据流中的第2行和第3行并没有执行那两个替换命令。
如果我们不想直接跳到脚本的结尾,可以为b命令指定一个标签(也就是格式中的label,最多为7个字符长度)。在使用此该标签时,要以冒号开始(比如:label2),并将其放到要跳过的脚本命令之后。这样,当sed命令匹配并处理该行文本时,会跳过标签之前所有的脚本命令,但会执行标签之后的脚本命令。
比如说:
在这个例子中,如果文本行中出现了first,程序的执行会直接跳到jump1标签之后的脚本行。如果分支命令的模式没有匹配,sed会继续执行所有的脚本命令。b分支命令除了可以向后跳转,还可以向前跳转,例如: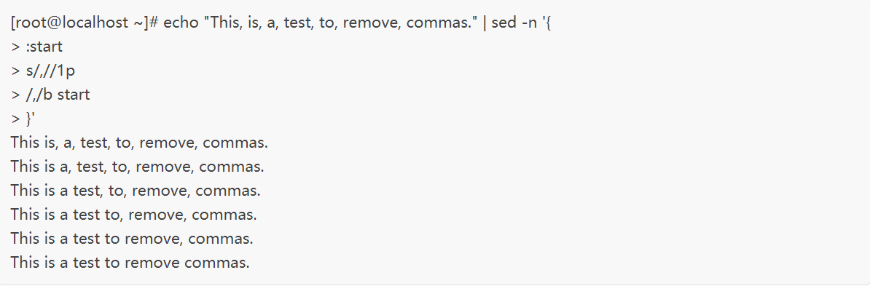
在这个例子中,当缓冲区中的行内容中有逗号时,脚本命令就会一直循环执行,每次迭代都会删除文本中的第一个逗号,并打印字符串,直至内容中没有逗号。
t测试命令
类似于b分支命令,t命令也可以用来改变sed脚本的执行流程。t测试命令会根据s替换命令的结果,如果匹配并替换成功,则脚本的执行会跳转到指定的标签;反之,t命令无效。
测试命令使用与分支命令相同的格式:
[address]t [label]
跟分支命令一样,在没有指定标签的情况下,如果s命令替换成功,sed会跳转到脚本的结尾(相当于不执行任何脚本命令)。例如:
此例中,第一个替换命令会查找模式文本first,如果匹配并替换成功,命令会直接跳过后面的替换命令;反之,如果第一个替换命令未能匹配成功,第二个替换命令就会被执行。
再举个例子: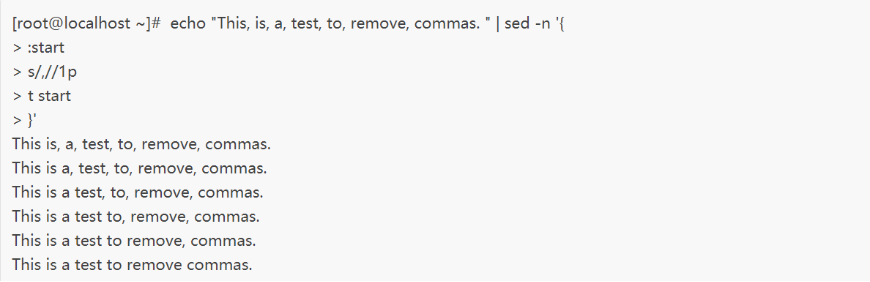
grep指令
grep命令能够在一个或多个文件中,搜索某一特定的字符模式(也就是正则表达式),此模式可以是单一的字符、字符串、单词或句子。
正则表达式是描述一组字符串的一个模式,正则表达式的构成模仿了数学表达式,通过使用操作符将较小的表达式组合成一个新的表达式。正则表达式可以是一些纯文本文字,也可以是用来产生模式的一些特殊字符。为了进一步定义一个搜索模式,grep命令支持如下所示的这几种正则表达式的元字符(也就是通配符)。
| 通配符 | 描述 |
|---|---|
* |
将匹配0个或多个字符 。 |
. |
将匹配任何一个字符,且只能是一个字符。 |
[xyz] |
匹配方括号中的任意一个字符。 |
[^xyz] |
匹配除方括号中字符外的所有字符。 |
^ |
锁定行的开头。 |
$ |
锁定行的结尾。 |
grep命令是用来在每一个文件或中(或特定输出上)搜索特定的模式,当使用grep时,包含指定字符模式的每一行内容,都会被打印(显示)到屏幕上,但是使用grep命令并不改变文件中的内容。 grep命令的基本格式如下: shell grep [选项] 模式 文件名 这里的模式,要么是字符(串),要么是正则表达式。 选项如下:
| 选项 | 含义 |
|---|---|
| -c | 仅列出文件中包含模式的行数。 |
| -i | 忽略模式中的字母大小写。 |
| -l | 列出带有匹配行的文件名。 |
| -n | 在每一行的最前面列出行号。 |
| -v | 列出没有匹配模式的行。 |
| -w | 把表达式当做一个完整的单字符来搜寻,忽略那些部分匹配的行。 |
注意,如果是搜索多个文件,grep命令的搜索结果只显示文件中发现匹配模式的文件名;而如果搜索单个文件,grep命令的结果将显示每一个包含匹配模式的行。
示例一假设有一份emp.data员工清单,现在要搜索此文件,找出职位为CLERK的所有员工,则执行命令如下:
而在此基础上,如果只想知道职位为CLERK的员工的人数,可以使用-c选项,执行命令如下:
示例二搜索emp.data文件,使用正则表达式找出以78开头的数据行,执行命令如下:
find指令
find命令用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
语法
find(选项)(参数)
选项
| 选项 | 描述 |
|---|---|
| -amin<分钟> | 查找在指定时间曾被存取过的文件或目录,单位以分钟计算; |
| -anewer<参考文件或目录> | 查找其存取时间较指定文件或目录的存取时间更接近现在的文件或目录; |
| -atime<24小时数> | 查找在指定时间曾被存取过的文件或目录,单位以24小时计算 |
| -cmin<分钟> | 查找在指定时间之时被更改过的文件或目录 |
| -cnewer<参考文件或目录> | 查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录 |
| -ctime<24小时数> | 查找在指定时间之时被更改的文件或目录,单位以24小时计算 |
| -daystart | 从本日开始计算时间 |
| -depth | 从指定目录下最深层的子目录开始查找 |
| -empty | 寻找文件大小为0 Byte的文件,或目录下没有任何子目录或文件的空目录 |
| -exec<执行指令> | 假设find指令的回传值为True,就执行该指令 |
| -false | 将find指令的回传值皆设为False |
| -fls<列表文件> | 此参数的效果和指定“-ls”参数类似,但会把结果保存为指定的列表文件 |
| -follow | 排除符号连接 |
| -fprint<列表文件> | 此参数的效果和指定“-print”参数类似,但会把结果保存成指定的列表文件 |
| -fprint0<列表文件> | 此参数的效果和指定“-print0”参数类似,但会把结果保存成指定的列表文件 |
| -fprintf<列表文件><输出格式> | 此参数的效果和指定“-printf”参数类似,但会把结果保存成指定的列表文件 |
| -fstype<文件系统类型> | 只寻找该文件系统类型下的文件或目录 |
| -gid<群组识别码> | 查找符合指定之群组识别码的文件或目录 |
| -group<群组名称> | 查找符合指定之群组名称的文件或目录 |
| -help | 在线帮助 |
| -ilname<范本样式> | 此参数的效果和指定“-lname”参数类似,但忽略字符大小写的差别 |
| -iname<范本样式> | 此参数的效果和指定“-name”参数类似,但忽略字符大小写的差别 |
| -inum |
查找符合指定的inode编号的文件或目录 |
| -ipath<范本样式> | 此参数的效果和指定“-path”参数类似,但忽略字符大小写的差别 |
| -iregex<范本样式> | 此参数的效果和指定“-regexe”参数类似,但忽略字符大小写的差别 |
| -links<连接数目> | 查找符合指定的硬连接数目的文件或目录 |
| -iname<范本样式> | 指定字符串作为寻找符号连接的范本样式 |
| -ls | 假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出 |
| -maxdepth<目录层级> | 设置最大目录层级 |
| -mindepth<目录层级> | 设置最小目录层级 |
| -mmin<分钟> | 查找在指定时间曾被更改过的文件或目录,单位以分钟计算 |
| -mount | 此参数的效果和指定“-xdev”相同 |
| -mtime<24小时数> | 查找在指定时间曾被更改过的文件或目录,单位以24小时计算 |
| -name<范本样式> | 指定字符串作为寻找文件或目录的范本样式 |
| -newer<参考文件或目录> | 查找其更改时间较指定文件或目录的更改时间更接近现在的文件或目录 |
| -nogroup | 找出不属于本地主机群组识别码的文件或目录 |
| -noleaf | 不去考虑目录至少需拥有两个硬连接存在 |
| -nouser | 找出不属于本地主机用户识别码的文件或目录 |
| -ok<执行指令> | 此参数的效果和指定“-exec”类似,但在执行指令之前会先询问用户,若回答“y”或“Y”,则放弃执行命令 |
| -path<范本样式> | 指定字符串作为寻找目录的范本样式 |
| -perm<权限数值> | 查找符合指定的权限数值的文件或目录 |
| 假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式为每列一个名称,每个名称前皆有“./”字符串 | |
| -print0 | 假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式为全部的名称皆在同一行 |
| -printf<输出格式> | 假设find指令的回传值为Ture,就将文件或目录名称列出到标准输出。格式可以自行指定 |
| -prune | 不寻找字符串作为寻找文件或目录的范本样式 |
| -regex<范本样式> | 指定字符串作为寻找文件或目录的范本样式 |
| -size<文件大小> | 查找符合指定的文件大小的文件 |
| -true | 将find指令的回传值皆设为True |
| -type<文件类型> | 只寻找符合指定的文件类型的文件 |
| -uid<用户识别码> | 查找符合指定的用户识别码的文件或目录 |
| -used<日数> | 查找文件或目录被更改之后在指定时间曾被存取过的文件或目录,单位以日计算 |
| -user<拥有者名称> | 查找符和指定的拥有者名称的文件或目录 |
| -version或—version | 显示版本信息 |
| -xdev | 将范围局限在先行的文件系统中 |
| -xtype<文件类型> | 此参数的效果和指定“-type”参数类似,差别在于它针对符号连接检查 |
type参数的选项 f:普通文件 l:符号连接 d:目录 c:字符设备 b:块设备 s:套接字 * p:管道
时间戳选项UNIX/Linux文件系统每个文件都有三种时间戳:
- 访问时间(
-atime/天,-amin/分钟):用户最近一次访问时间。 - 修改时间(
-mtime/天,-mmin/分钟):文件最后一次修改时间。 - 变化时间(
-ctime/天,-cmin/分钟):文件数据元(例如权限等)最后一次修改时间。
size选项文件大小单元:
b: 块(512字节)c: 字节w: 字(2字节)k: 1024字节M: 1024*1024字节G: 1024_1024_1024字节
参数
起始目录:查找文件的起始目录。
示例
- 列出当前目录及子目录下所有文件和文件夹
find .
- 在
/home目录下查找以.txt结尾的文件名
find /home -name "*.txt"
- 在
/home目录下查找以.txt结尾的文件名,忽略大小写
find /home -iname "*.txt"
- 当前目录及子目录下查找所有以
.txt和.pdf结尾的文件

- 匹配文件路径或者文件
find /usr/ -path "*local*"
- 基于正则表达式匹配文件路径
find . -regex ".*\(\.txt\|\.pdf\)$"
- 基于正则表达式匹配文件路径,忽略大小写
find . -iregex ".*\(\.txt\|\.pdf\)$"
- 找出
/home下不是以.txt结尾的文件
find /home ! -name "*.txt"
- 向下最大深度限制为3
find . -maxdepth 3 -type f
- 搜索出深度距离当前目录至少2个子目录的所有文件
find . -mindepth 2 -type f
- 搜索最近七天内被访问过的所有文件
find . -type f -atime -7
- 搜索恰好在七天前被访问过的所有文件
find . -type f -atime 7
- 搜索超过七天内被访问过的所有文件
find . -type f -atime +7
- 搜索访问时间超过10分钟的所有文件
find . -type f -amin +10
- 找出比file.log修改时间更长的所有文件
find . -type f -newer file.log
- 搜索大于10KB的文件
find . -type f -size +10k
- 搜索小于10KB的文件
find . -type f -size -10k
- 搜索等于10KB的文件
find . -type f -size 10k
- 删除当前目录下所有
.txt文件
find . -type f -name "*.txt" -delete
- 当前目录下搜索出权限为777的文件
find . -type f -perm 777
- 找出当前目录下权限不是644的php文件
find . -type f -name "*.php" ! -perm 644
- 找出当前目录用户tom拥有的所有文件
find . -type f -user tom
- 找出当前目录用户组sunk拥有的所有文件
find . -type f -group sunk
- 找出当前目录下所有root的文件,并把所有权更改为用户tom
find .-type f -user root -exec chown tom {} \;
上例中,
{}用于与-exec选项结合使用来匹配所有文件,然后会被替换为相应的文件名。
- 找出自己家目录下所有的
.txt文件并删除
find $HOME/. -name "*.txt" -ok rm {} \;
- 查找当前目录下所有
.txt文件并把他们拼接起来写入到all.txt文件中
find . -type f -name "*.txt" -exec cat {} \;> all.txt
- 将30天前的
.log文件移动到old目录中
find . -type f -mtime +30 -name "*.log" -exec cp {} old \;
- 找出当前目录下所有
.txt文件并以File:文件名的形式打印出来
find . -type f -name "*.txt" -exec printf "File: %s\n" {} \;
- 因为单行命令中
-exec参数中无法使用多个命令,以下方法可以实现在-exec之后接受多条命令
```shell
-exec ./text.sh {} ;
* 查找当前目录或者子目录下所有`.txt`文件,但是跳过子目录`sk`
```shell
find . -path "./sk" -prune -o -name "*.txt" -print
- 要列出所有长度为零的文件
find . -empty
xargs指令
xargs命令是给其他命令传递参数的一个过滤器,也是组合多个命令的一个工具。它擅长将标准输入数据转换成命令行参数,xargs能够处理管道或者stdin并将其转换成特定命令的命令参数。xargs也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。xargs的默认命令是echo,空格是默认定界符。这意味着通过管道传递给xargs的输入将会包含换行和空白,不过通过xargs的处理,换行和空白将被空格取代。xargs是构建单行命令的重要组件之一。xargs用作替换工具,读取输入数据重新格式化后输出。
定义一个测试文件,内有多行文本数据:
多行输入单行输出:
-n选项多行输出:
-d选项可以自定义一个定界符:
结合-n选项使用:
读取stdin,将格式化后的参数传递给命令。假设一个命令为sk.sh和一个保存参数的文件arg.txt:
arg.txt文件内容:
xargs的一个选项-I,使用-I指定一个替换字符串{},这个字符串在xargs扩展时会被替换掉,当-I与xargs结合使用,每一个参数命令都会被执行一次:
复制所有图片文件到/data/images目录下:
用rm删除太多的文件时候,可能得到一个错误信息:/bin/rm Argument list too long.用xargs去避免这个问题:
xargs -0将\0作为定界符。
统计一个源代码目录中所有php文件的行数:
查找所有的jpg文件,并且压缩它们:
假如你有一个文件包含了很多你希望下载的URL,你能够使用xargs下载所有链接:
awk指令
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。

若有收获,就点个赞吧
0 人点赞
