課程導讀
欢迎报名学习《HCIA-Big Data华为认证大数据工程师在线课程 V3.0》。
为了更好地掌握课程内容,保证学习效果,建议你先详细阅读以下要点,再开始学习。
学习顺序
本课程共14章内容,其中第1-8章、第10、12章由重庆邮电大学副教授雷大江老师讲解,剩余4章由华为认证大数据讲师讲解。
内容按顺序依次是:大数据发展趋势与鲲鹏大数据,HDFS和ZooKeeper,Hive分布式数据仓库,HBase、MapReduce和Yarn技术原理,Spark基于内存的分布式计算,Flink流批一体分布式实时处理引擎,Flume海量日志聚合,Loader数据转换,Kafka分布式消息订阅系统,LDAP Kerberos,分布式全文检索服务ElasticSearch,Redis内存数据库,华为大数据解决方案。
因该课程主要讲解常用的大数据组件基础技术,各章之前基本相互独立,故你可以选择按顺序进行学习,也可以按照自己对各部分内容的熟悉程度,进行章节选择学习。
L01 大數據發展趨勢與鯤鵬大數據

同学们可以带着这些问题去学习:
1. 大数据从什么地方来?这些数据有哪些特点?
大数据可以应用在哪些社会领域?
大数据面临哪些挑战?
L02 HDFS分布式文件系统和ZooKeeper
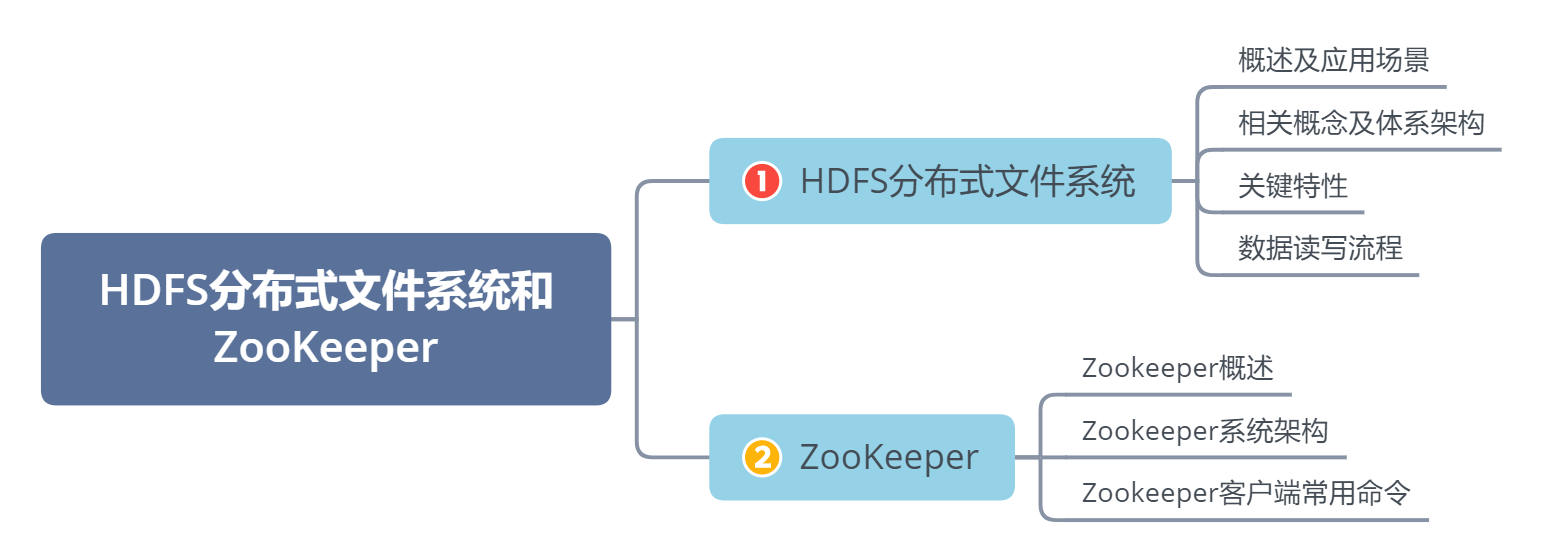
同学们可以带着这些问题去学习:
大数据平台提供的最基本的两个功能是什么?
HDFS主要包括哪些角色?
大数据生态圈组件为什么需要Zookeeper去提供分布式协调?
L03 Hive分布式数据仓库
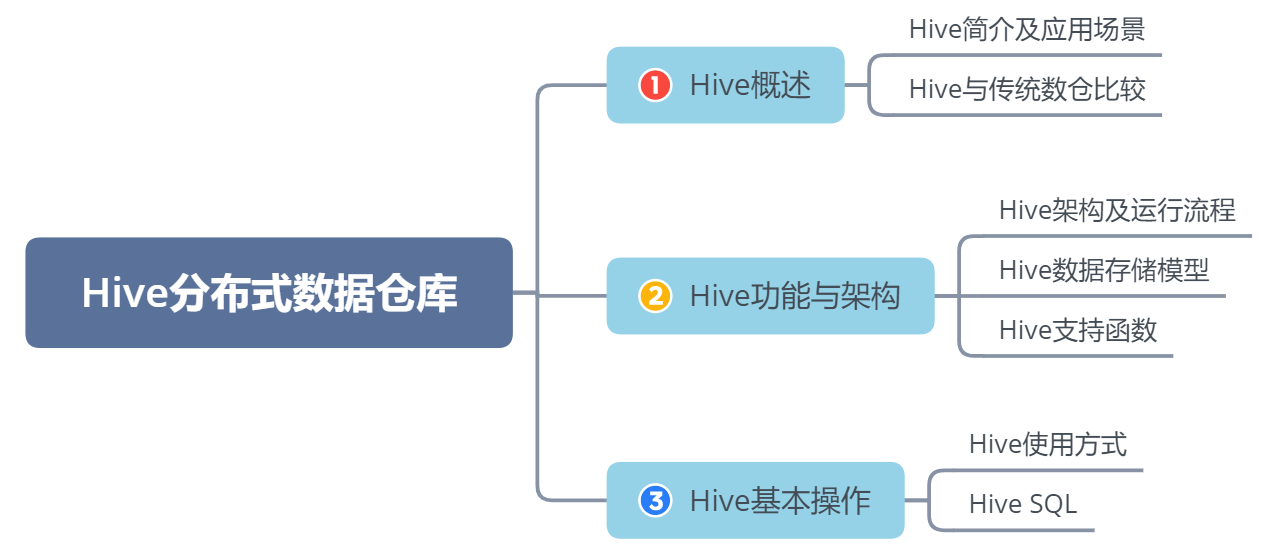
同学们可以带着这些问题去学习:
能够通过写SQL语句就可以进行大数据的统计分析?
Hive中写HQL语句最终转换成了什么程序?
Hive提供了哪些客户端接口供用户使用?
L04 HBase 技術原理
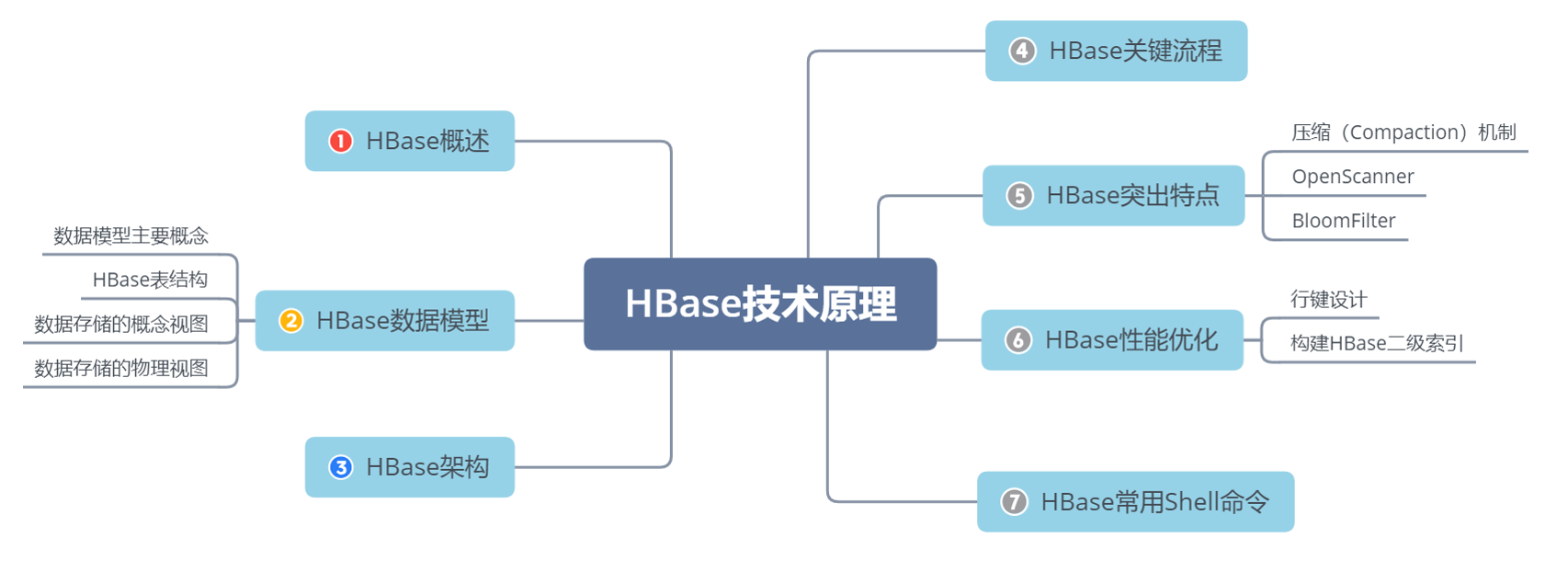
同学们可以带着这些问题去学习:
HBase能否应用于实时响应查询计算的应用场景?
为什么说HBase是键值类型数据库?
HBase的主要角色有哪些?分别提供什么作用?
Zookeeper对HBase提供了什么服务支持?
L05 MapReduce和Yarn技术原理

同学们可以带着这些问题去学习:
MapReduce适用于数据密集型任务,还是计算密集型任务?
MapReduce 1.x主要包括哪些角色?主要功能是什么?
Yarn主要分担了MapReduce 1.x中的哪些功能?
- Yarn默认包含哪三种三种资源调度器?
L06 Spark基于内存的分布式计算
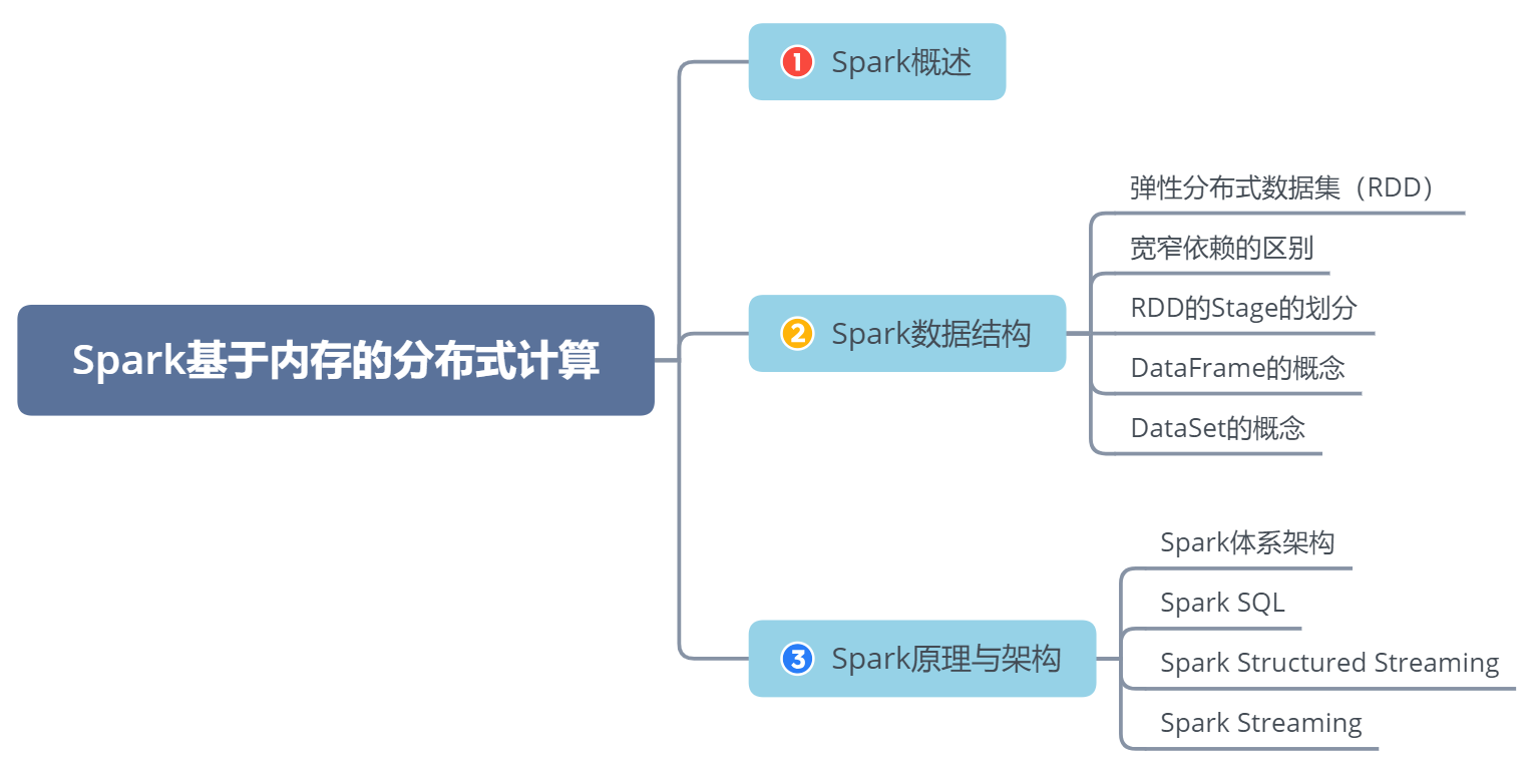
同学们可以带着这些问题去学习:
为什么说Spark是基于内存的分布式计算引擎?
RDD宽依赖和窄依赖的主要区别是什么?
RDD有哪些主要操作?
Spark支持流计算吗?
L07 Flink 流批一体分布式实时处理引擎
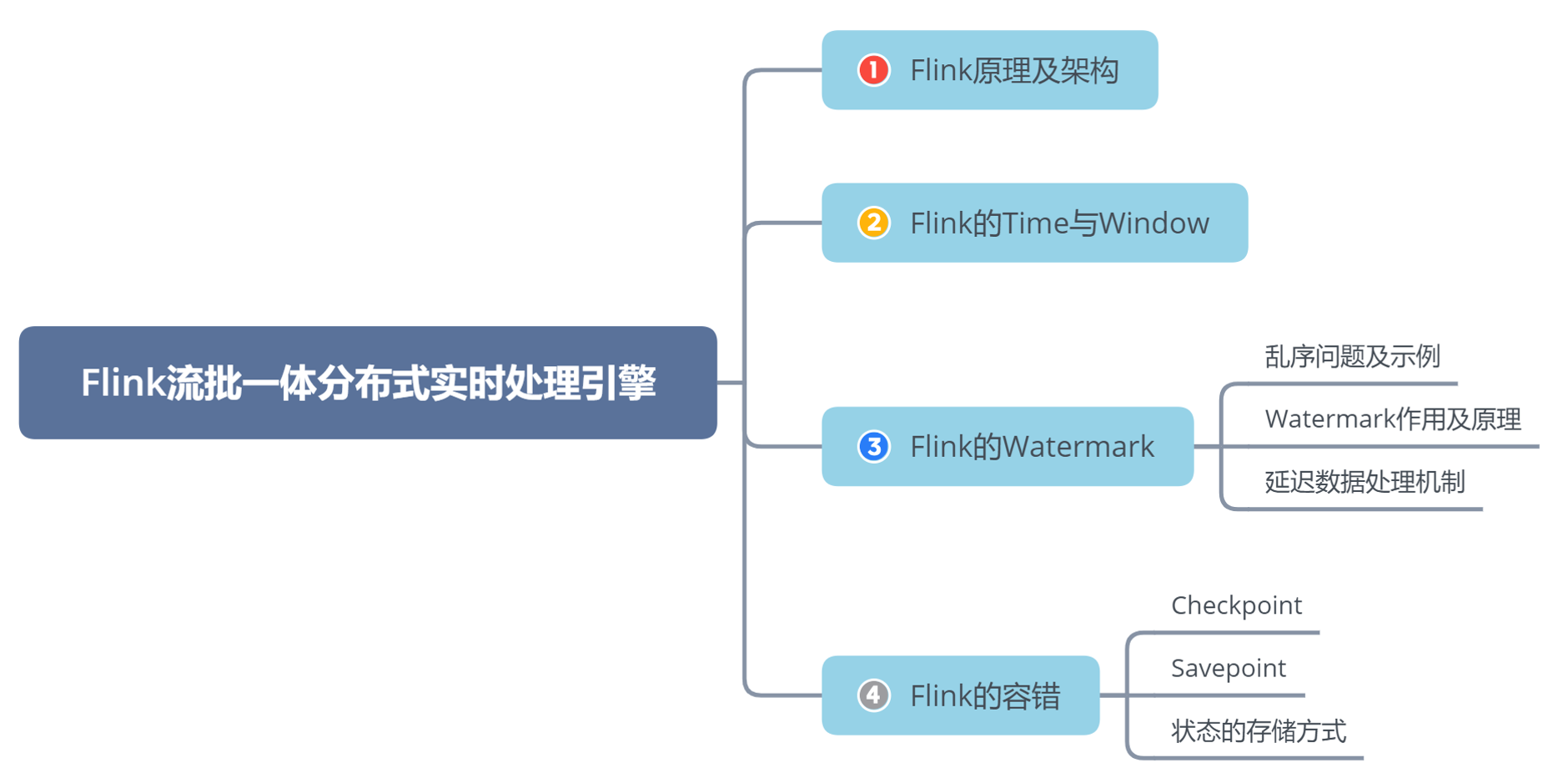
同学们可以带着这些问题去学习:
Flink看待数据的观点是流,为什么又可以作批处理计算?
Flink中三种时间是什么时间?每种时间作用是什么?
Flink如何使用Watermark来解决数据乱序和延迟问题的?
L08 Flume海量日志聚合
Flume海量日志聚合>☆ 本章导读>本章导读

同学们可以带着这些问题去学习:Flume的Agent主要包括哪三个组件?
Flume怎么保证数据传输的可靠性?
Flume如果采用memory channel,当Agent宕机,数据会丢失吗?
L09 Loader数据转换
9.Loader数据转换>☆ 本章导读>本章导读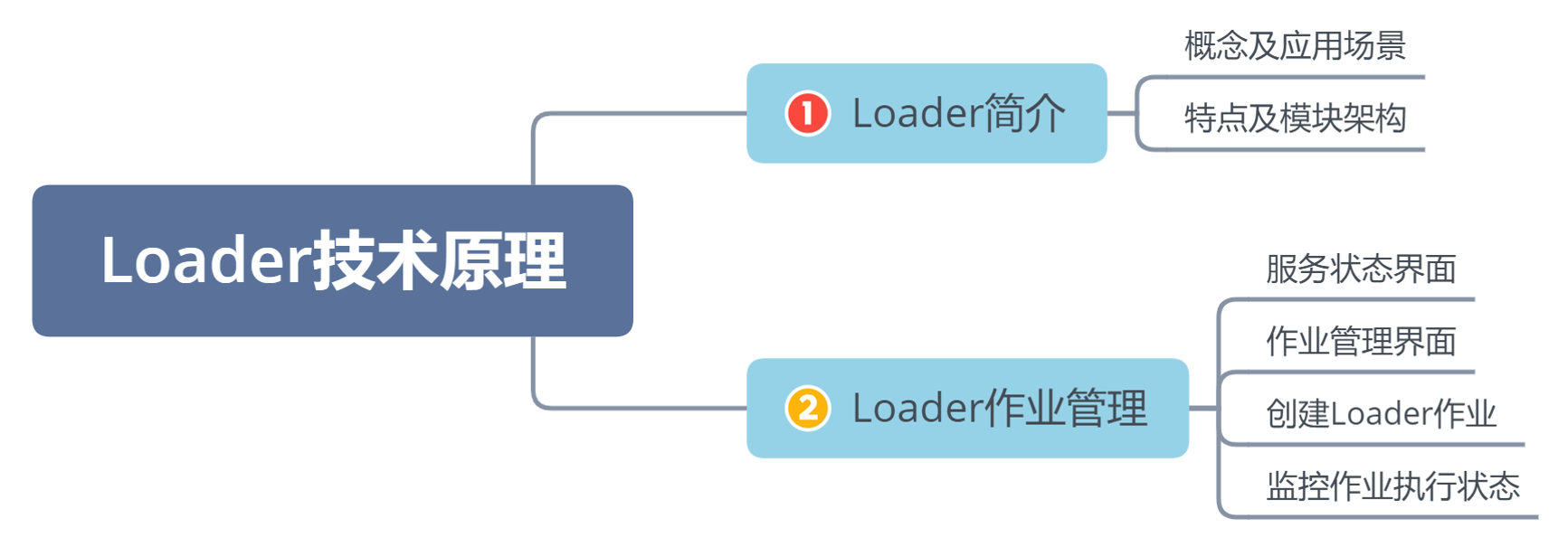
同学们可以带着这些问题去学习:
Loader是什么?
Loader的架构是怎样的?
Loader如何使用?
L10 Kafka分布式消息订阅系统
Kafka分布式消息订阅系统>☆ 本章导读>本章导读
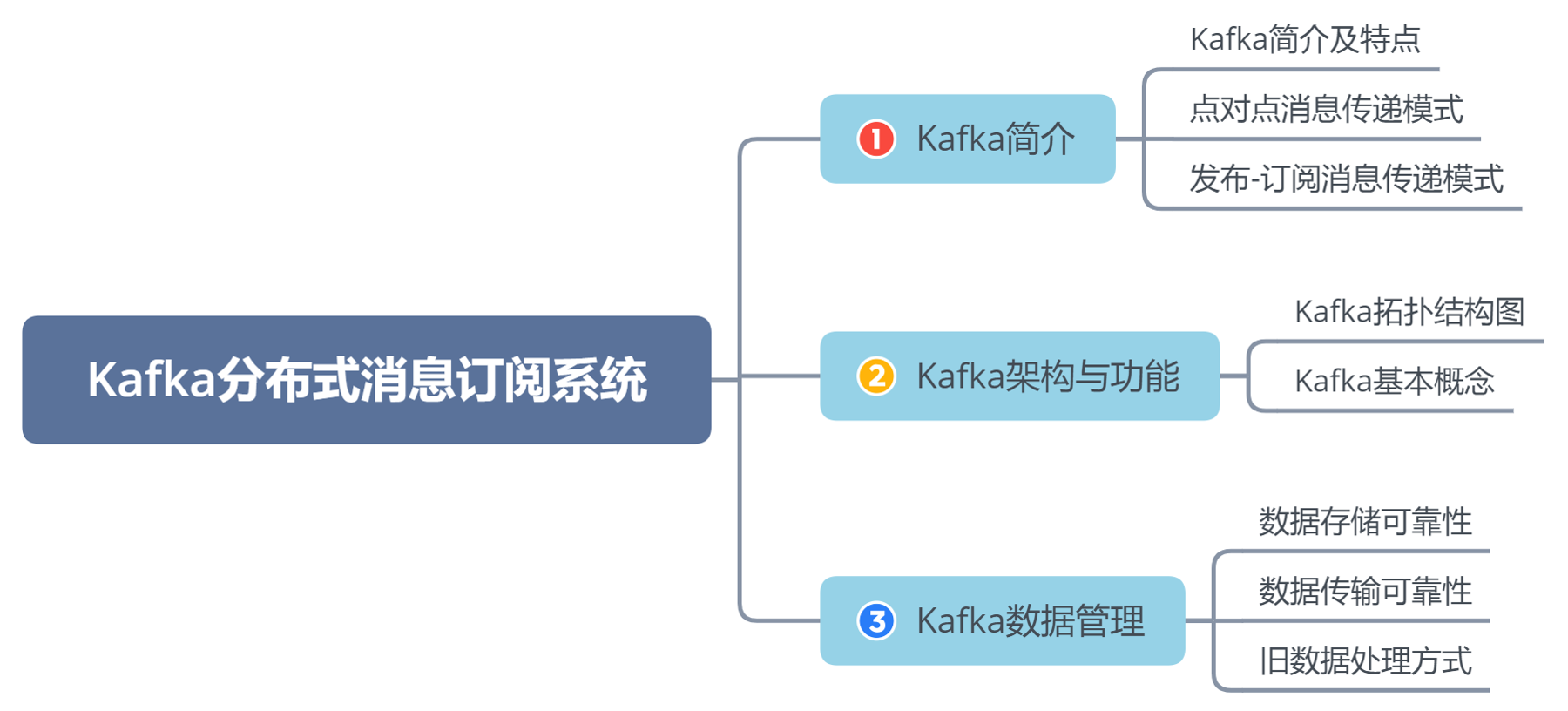
同学们可以带着这些问题去学习:在有可能会宕机情况下,点对点消息传递模式和发布订阅消息传递模式,哪种数据更加可靠?
Flume将消息传递给消费者与Kafka将消息传递给消费者采用模式是否相同?
Kafka如果有多个Consumer Group是否可以订阅相同Topic中的消息?
Kafka的Producer有哪三种ack机制?分别代表什么含义?
L11 LDAP Kerberos
LDAP Kerberos>☆ 本章导读>本章导读
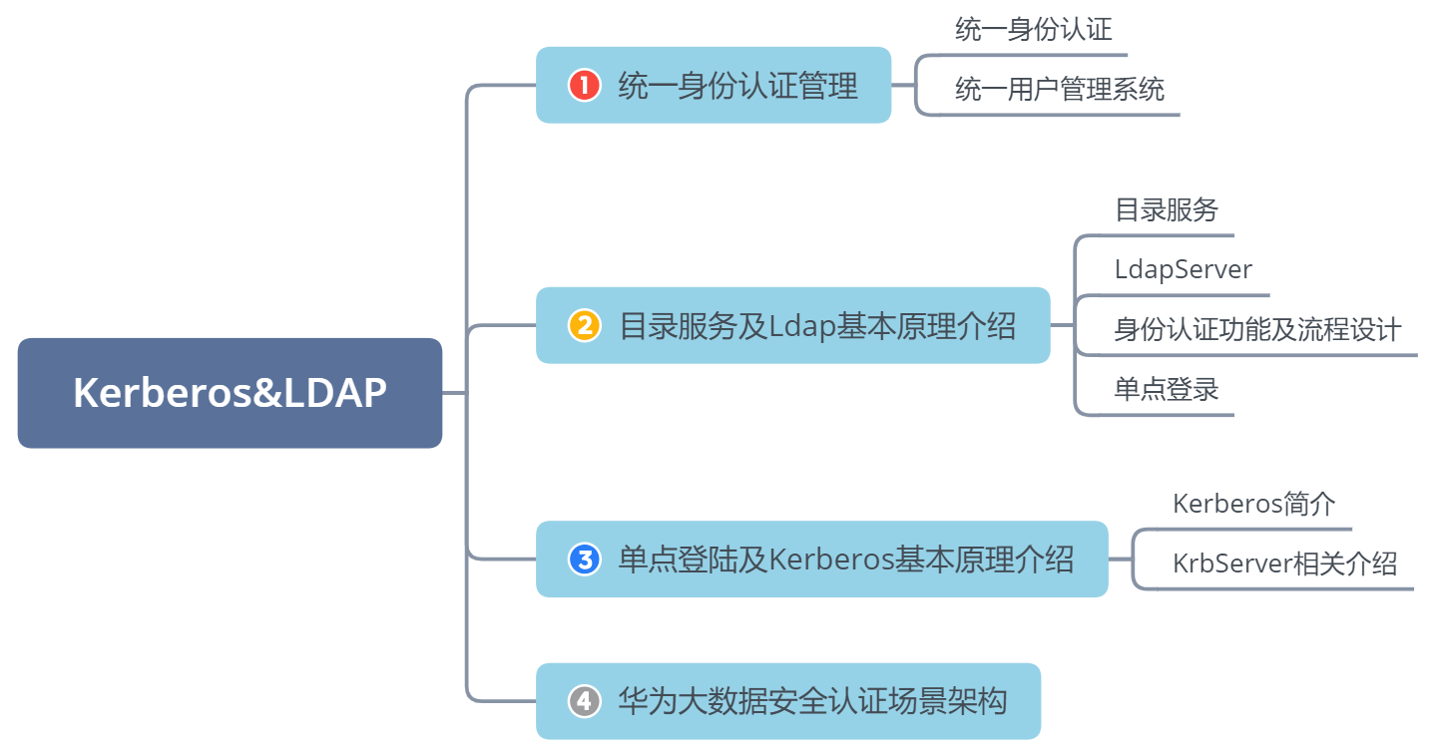
同学们可以带着这些问题去学习:什么是统一身份认证?
Kerberos和LDAP的组合如何实现数据安全?
华为大数据安全认证的架构?
L12 分布式全文检索服务 ElasticSearch
分布式全文检索服务ElasticSearch>☆ 本章导读>本章导读
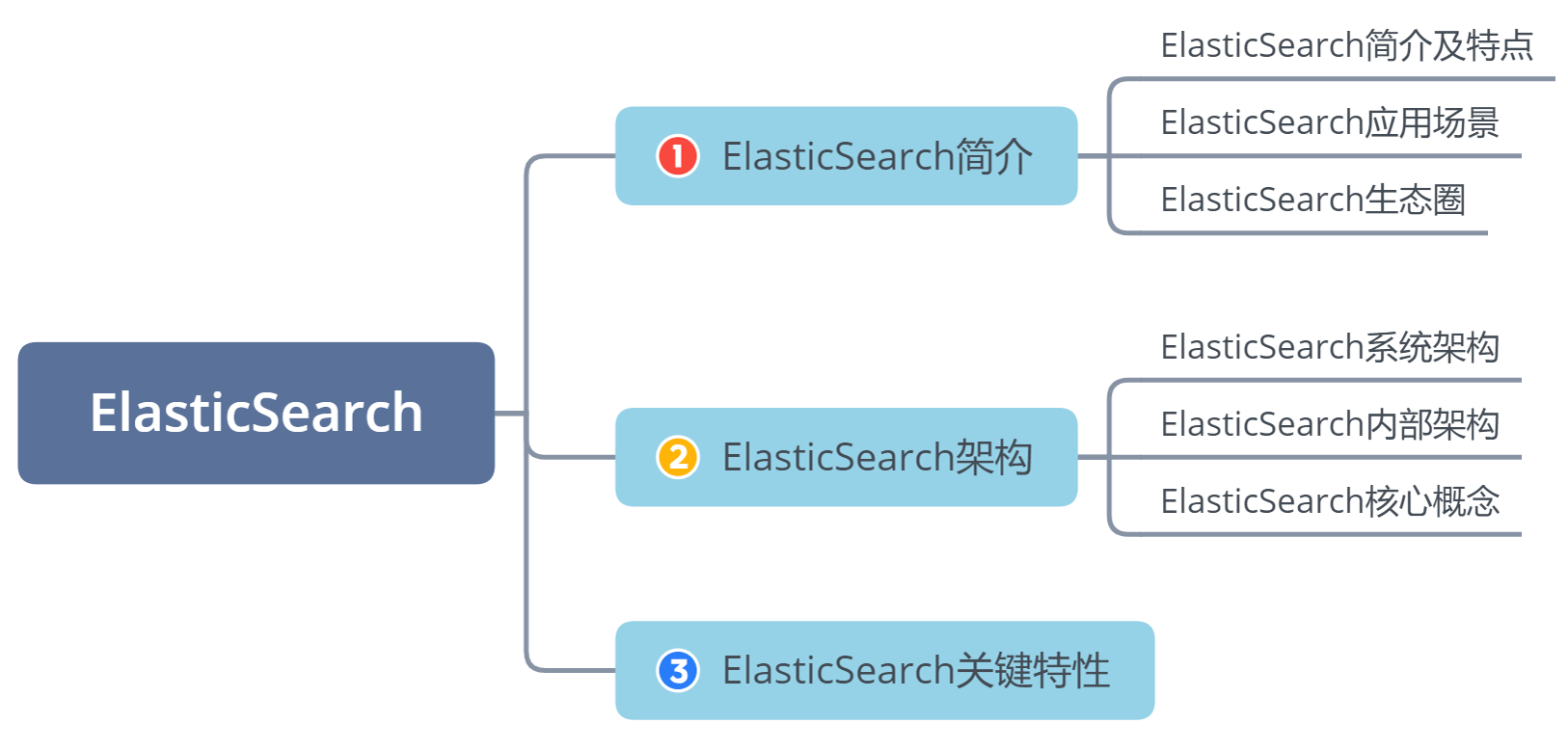
同学们可以带着这些问题去学习:ElasticSearch的生态圈(Elastic Stack)还包含哪两个组件?
对于非结构化数据,也即对全文数据的搜索主要有哪两种方法?
ElasticSearch是否需要Zookeeper进行分布式协调管理?
ElasticSearch如何进行倒排索引?
L13 Redis 内存数据库
Redis内存数据库>☆ 本章导读>本章导读
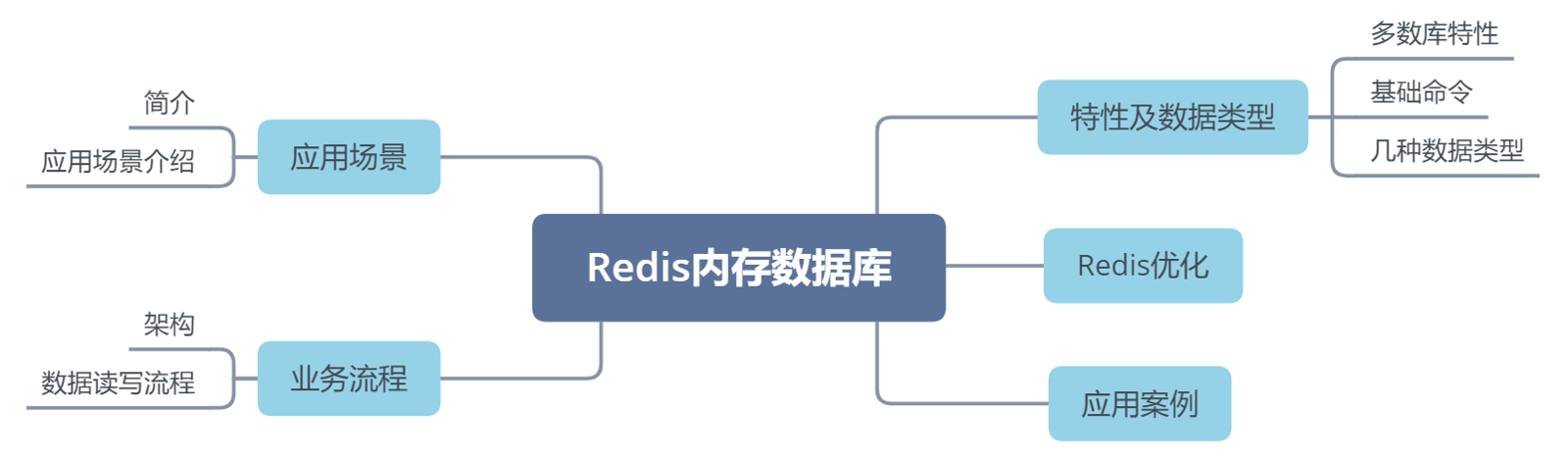
同学们可以带着这些问题去学习:Redisd的应用场景有哪些?
Redis支持哪些数据结构?
Redis性能优化的常见方法?
L14 华为大数据解决方案
华为大数据解决方案>☆ 本章导读>本章导读
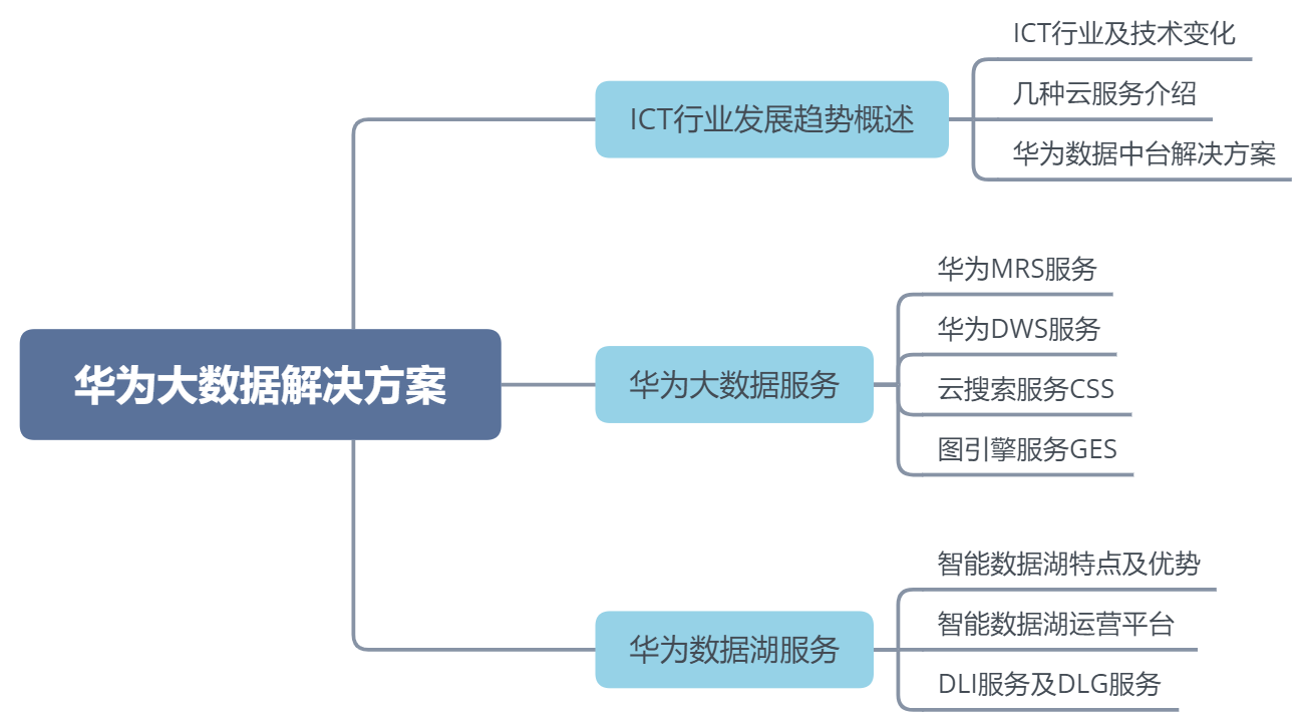
同学们可以带着这些问题去学习:
1. ICT行业面临的挑战?华为大数据服务都有哪些?
华为智能数据湖有哪些特点?

若有收获,就点个赞吧
0 人点赞
