- Python爬虫的分类
- 什么是Jupyter Notebook
- 网络爬虫模块
- 获取页面数据
page_text = response.read()
print(page_text) - 将获取的数据做持久化存储
page_text = response.read()
with open(‘fanbingbing.html’,’wb’) as fp:
fp.write(page_text)
print(‘写入成功’) - 返回一个状态码
#print(response.status_code) - 返回相应头信息
# print(response.headers)
方式二 ">获取请求的url
">获取请求的url
print(response.url)
Requests如何请求携带参数的get请求
-方式一
方式二- https://accounts.douban.com/login‘
#封装post请求的参数
data = {
‘source’:’movie’,
‘redir’:’https://movie.douban.com/‘,
‘form_email’:’18401747334’,
‘form_password’:’fei@163.com’,
‘login’:’登录’,
}
#自定义请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#发起post请求
respomse = requests.post(url=url,data=data,headers=headers)
#获取响应对象中的页面数据
page_text = respomse.text
#持久化
with open(‘./douban.html’,’w’,encoding=’utf-8’) as fp:
fp.write(page_text)
Requests模块ajax的get请求、
#基于ajax的get请求
import requests
url = ‘https://movie.douban.com/j/chart/top_list?‘
#封装ajax的get请求中携带的参数
params = {
‘type’: ‘13’,
‘interval_id’: ‘100:90’,
‘action’: ‘’,
‘start’: ‘10’,
‘limit’: ‘20’
}
#请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
respomse = requests.get(url=url,params=params,headers=headers)
print(respomse.text)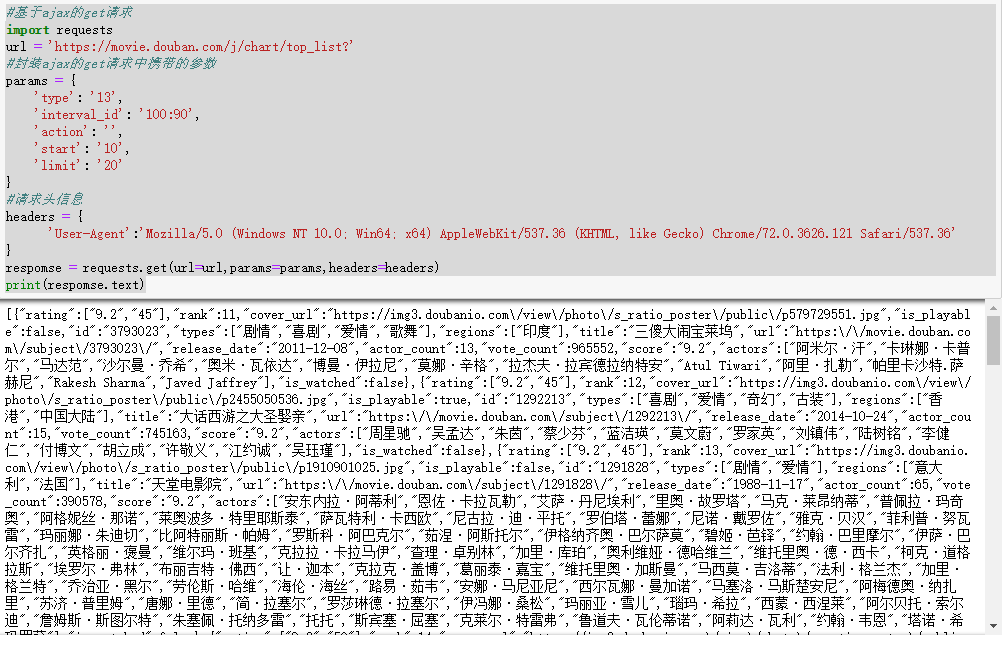
基于ajax的post请求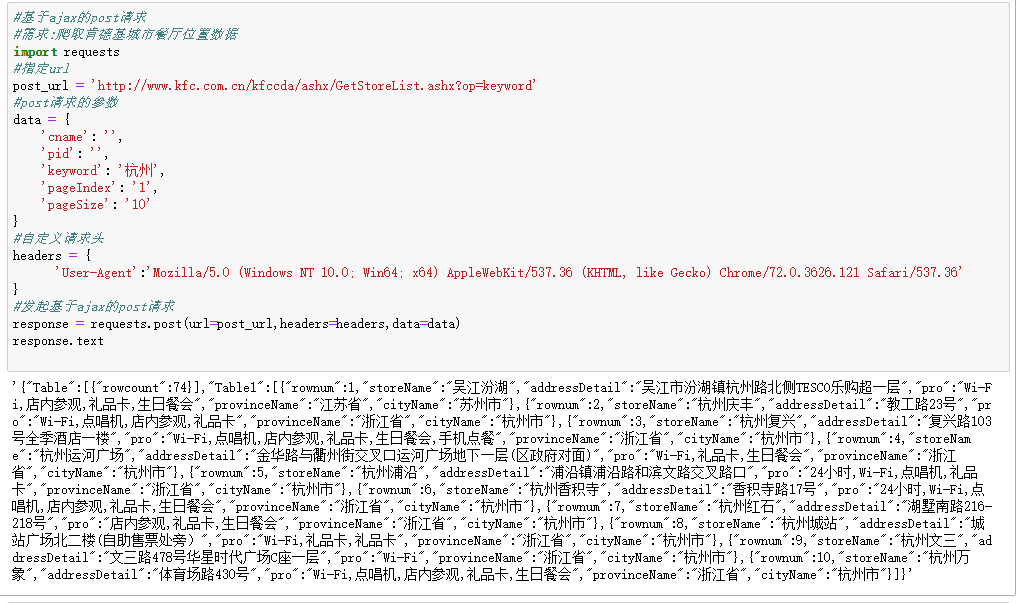
#基于ajax的post请求
#需求:爬取肯德基城市餐厅位置数据
import requests
#指定url
post_url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
#post请求的参数
data = {
‘cname’: ‘’,
‘pid’: ‘’,
‘keyword’: ‘杭州’,
‘pageIndex’: ‘1’,
‘pageSize’: ‘10’
}
#自定义请求头
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#发起基于ajax的post请求
response = requests.post(url=post_url,headers=headers,data=data)
response.text">将参数封装到字典中
params = {
‘query’:’周杰伦’,
‘ie’:’utf-8’
}
#自定义请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
response = requests.get(url=url,params=params,headers=headers)
response.status_code
基于requests模块发起的post请求
#基于requests模块发起的post请求
#- 需求:登陆豆瓣网,获取登陆成功后的页面数据
import requests
url = ‘https://accounts.douban.com/login‘
#封装post请求的参数
data = {
‘source’:’movie’,
‘redir’:’https://movie.douban.com/‘,
‘form_email’:’18401747334’,
‘form_password’:’fei@163.com’,
‘login’:’登录’,
}
#自定义请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#发起post请求
respomse = requests.post(url=url,data=data,headers=headers)
#获取响应对象中的页面数据
page_text = respomse.text
#持久化
with open(‘./douban.html’,’w’,encoding=’utf-8’) as fp:
fp.write(page_text)
Requests模块ajax的get请求、
#基于ajax的get请求
import requests
url = ‘https://movie.douban.com/j/chart/top_list?‘
#封装ajax的get请求中携带的参数
params = {
‘type’: ‘13’,
‘interval_id’: ‘100:90’,
‘action’: ‘’,
‘start’: ‘10’,
‘limit’: ‘20’
}
#请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
respomse = requests.get(url=url,params=params,headers=headers)
print(respomse.text)
基于ajax的post请求
#基于ajax的post请求
#需求:爬取肯德基城市餐厅位置数据
import requests
#指定url
post_url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
#post请求的参数
data = {
‘cname’: ‘’,
‘pid’: ‘’,
‘keyword’: ‘杭州’,
‘pageIndex’: ‘1’,
‘pageSize’: ‘10’
}
#自定义请求头
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#发起基于ajax的post请求
response = requests.post(url=post_url,headers=headers,data=data)
response.text - https://zhihu.sogou.com/zhihu‘
for page in range(start_pagenum,end_pageNum+1):
param = {
‘query’:word,
‘page’:page,
‘ie’:’utf-8’
}
response = requests.get(url=url,params=params,headers=headers)
#获取相应中的页面数据(指定页面(page))
page_text = respomse.text
#持久化
fileName = word +str(page)+’.html’
filePath = ‘pages/‘+fileName
with open(filePath,’w’,encoding=’utf-8’) as fp:
fp.write(page_text)
print(‘第%d页写入成功’%page)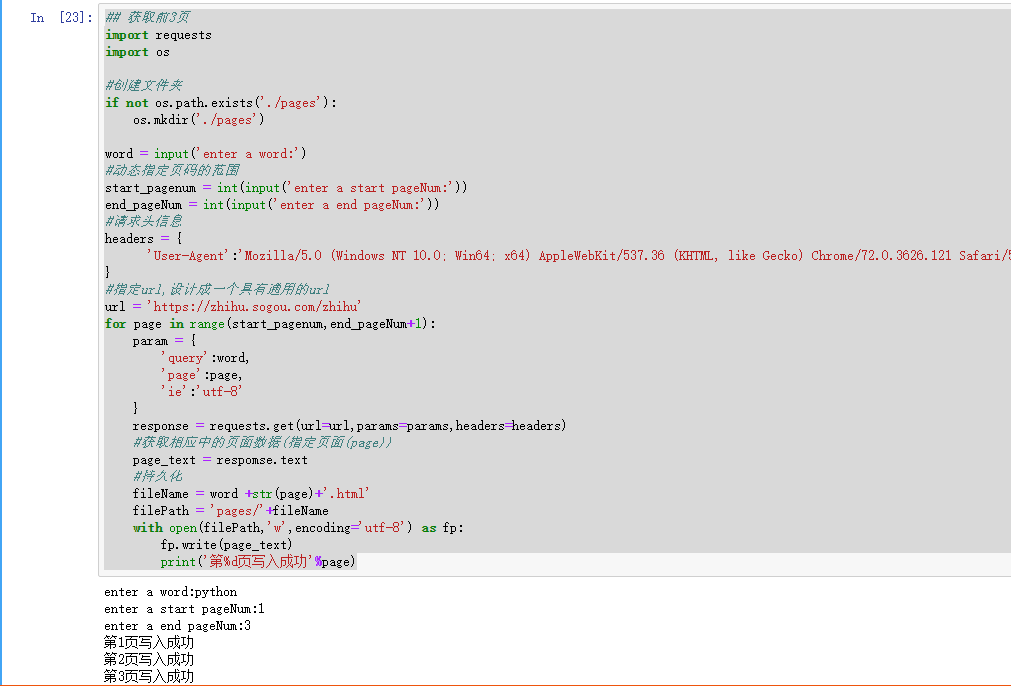
Requests – cookie
—cookie
基于用户的用户数据
-需求:爬取张三用户的豆瓣网上的个人主页页面数据
—cookie作用:
1.执行登陆操作(获取cookie)
2.在发起个人主页请求时,需要将cookie携带到请求中
注意:session对象:发送请求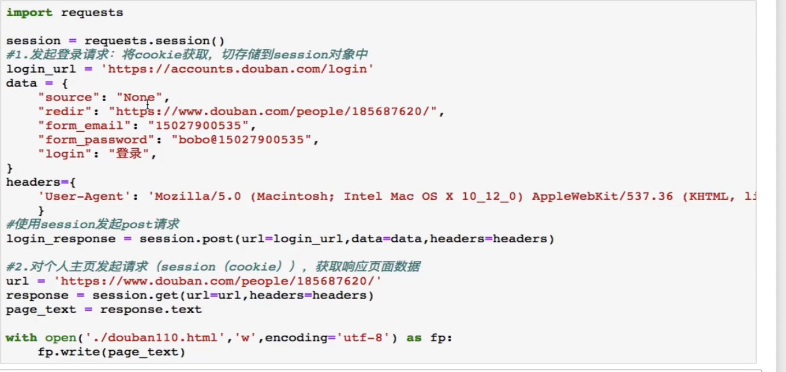 ">创建文件夹
">创建文件夹
if not os.path.exists(‘./pages’):
os.mkdir(‘./pages’)
word = input(‘enter a word:’)
#动态指定页码的范围
start_pagenum = int(input(‘enter a start pageNum:’))
end_pageNum = int(input(‘enter a end pageNum:’))
#请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#指定url,设计成一个具有通用的url
url = ‘https://zhihu.sogou.com/zhihu‘
for page in range(start_pagenum,end_pageNum+1):
param = {
‘query’:word,
‘page’:page,
‘ie’:’utf-8’
}
response = requests.get(url=url,params=params,headers=headers)
#获取相应中的页面数据(指定页面(page))
page_text = respomse.text
#持久化
fileName = word +str(page)+’.html’
filePath = ‘pages/‘+fileName
with open(filePath,’w’,encoding=’utf-8’) as fp:
fp.write(page_text)
print(‘第%d页写入成功’%page)
Requests – cookie
—cookie
基于用户的用户数据
-需求:爬取张三用户的豆瓣网上的个人主页页面数据
—cookie作用:
1.执行登陆操作(获取cookie)
2.在发起个人主页请求时,需要将cookie携带到请求中
注意:session对象:发送请求 - 三种数据解析方式
- Scrapy框架
#创建爬虫文件">创建爬虫项目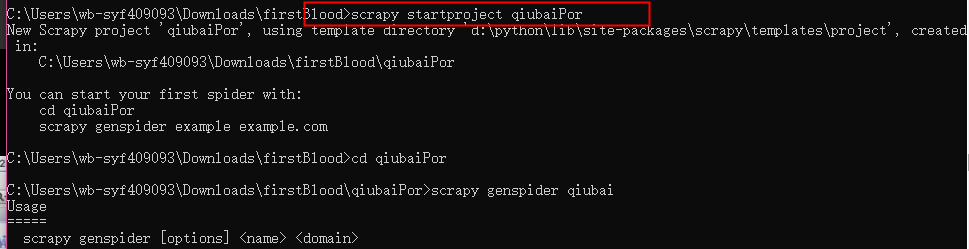
#创建爬虫文件
Python网络爬虫 |
|---|
作者:地铁昌平线 归档:学习笔记 2019/02/26 |
| 快捷键: Ctrl + 1 标题1 Ctrl + 2 标题2 Ctrl + 3 标题3 Ctrl + 4 实例 Ctrl + 5 程序代码 Ctrl + 6 正文 |
| 格式说明: 蓝色字体:注释 黄色背景:重要 绿色背景:注意 |
Python爬虫的分类
通用爬虫:
通用爬虫是搜索引擎BaiDu Google YaHoo等,抓取的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
聚焦爬虫
Robots.txt协议
自己的门户网站中的指定页面中的数据不想让爬虫程序取到的化,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取
反爬虫
门户网站通过相应的策略和技术手段,放置爬虫程序进行网站数据的爬取
反反爬虫
爬虫程序通过相应的策略和技术的手段,破解门户网站的反爬虫手段,从而爬取到相应的数据
什么是Jupyter Notebook
简介
Jupyter Notebook是基于网页的用于交互式计算的应用程序,期可被应用用全过程编码开发,文档编写,运行代码和展示结果
Jupyter Notebook的主要特点
- 编写时具有语法高亮、缩进、tab补全的功能
- 可直接通过浏览器运行代码,同时在代码块下放展示运行的结果
- 对代码编写说明文档或语句时,支持Markdown语法
安装
安装前提:
安装Jupter Noteboo的前提需要安装python3.3版本或2.7以上的版本
使用Anaconda安装
通过安装Anacida来解决Jupter NoteBoo的安装问题
官方下载地址: www.anaconda.com/download 自行下载,傻瓜式安装,默认配置环境变量
运行Jupyter Notebook
Jupyter notebook
使用介绍
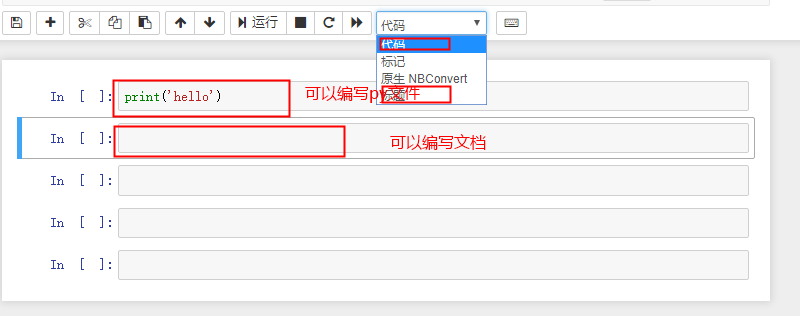
常用快捷键
向下插入一个cell b
向上插入一个cell a
将cell的类型切换成Markdown类型 m
将cell的类型切换成code类型 y
运行 shift + enter
帮助文档 Shift + Tab
补全 tab
网络爬虫模块
Urlib
Python中自带的一个基于爬虫的模块。
作用:可以使用代码模拟浏览器发起请求.request parse
使用流程:
指定url
发起请求
获取页面数据
持久化存储
需求 爬取搜狗首页数据
#需求爬取搜狗首页
import urllib.request
#1.指定url
url = ‘https://www.sogou.com/‘
#2.发请求,urlopen可以根据指定的url发起请求,且返回一个响应对象
response = urllib.request.urlopen(url=url)
#3.获取页面数据:read函数返回的就是响应对象中存储的页面数据(byte)
page_text = response.read()
#4.持久化存储
with open(‘./sogou.html’,’wb’) as fp:
fp.write(page_text)
print(‘写入数据成功’)
#需求:爬取指定词条所对应的页面数据
import urllib.request
import urllib.parse
#指定url
url = ‘https://www.sogou.com/web?query=‘
#url的特性:url不可以存在非ASCII编码的字符数据
word = urllib.parse.quote(‘范冰冰’)
url += word #有效的url
#发送请求
response = urllib.request.urlopen(url=url)
获取页面数据
page_text = response.read()
print(page_text)
将获取的数据做持久化存储
page_text = response.read()
with open(‘fanbingbing.html’,’wb’) as fp:
fp.write(page_text)
print(‘写入成功’)

反爬机制
-反爬虫机制:网站会检查请求的UA,如果发现请求的UA是爬虫程序,则拒绝提供网站数据
-User-Agent(UA):请求载体的身份标识
-反反爬机制:伪装爬虫程序请求的UA,
UA伪装
import urllib.request
url = ‘http://www.baidu.com/‘
#UA伪装
#1.自制定一个请求的对象
headers = {
#存储任意的请求头信息
‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#该请求对象的UA进行了成功的伪装
request = urllib.request.Request(url=url,headers=headers)
#2.针对自制定的请求对象发起请求
response = urllib.request.urlopen(request)
print(response.read())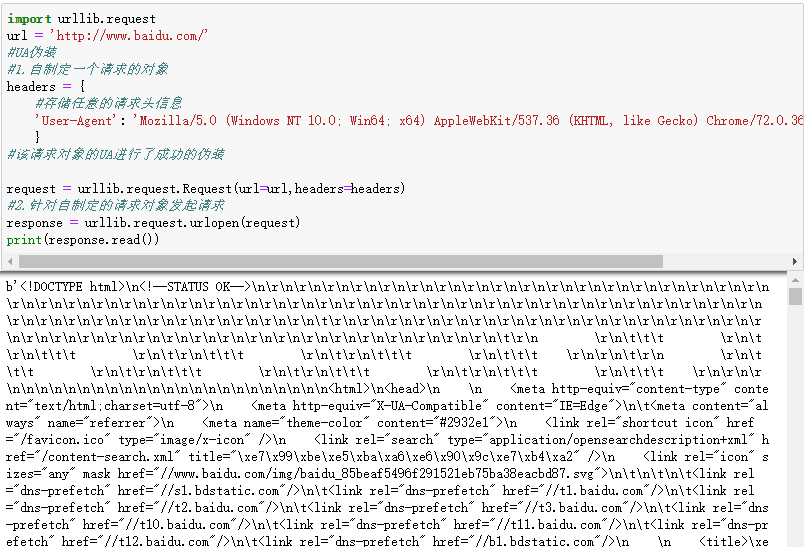
Post请求
import urllib.request
import urllib.parse
#指定url
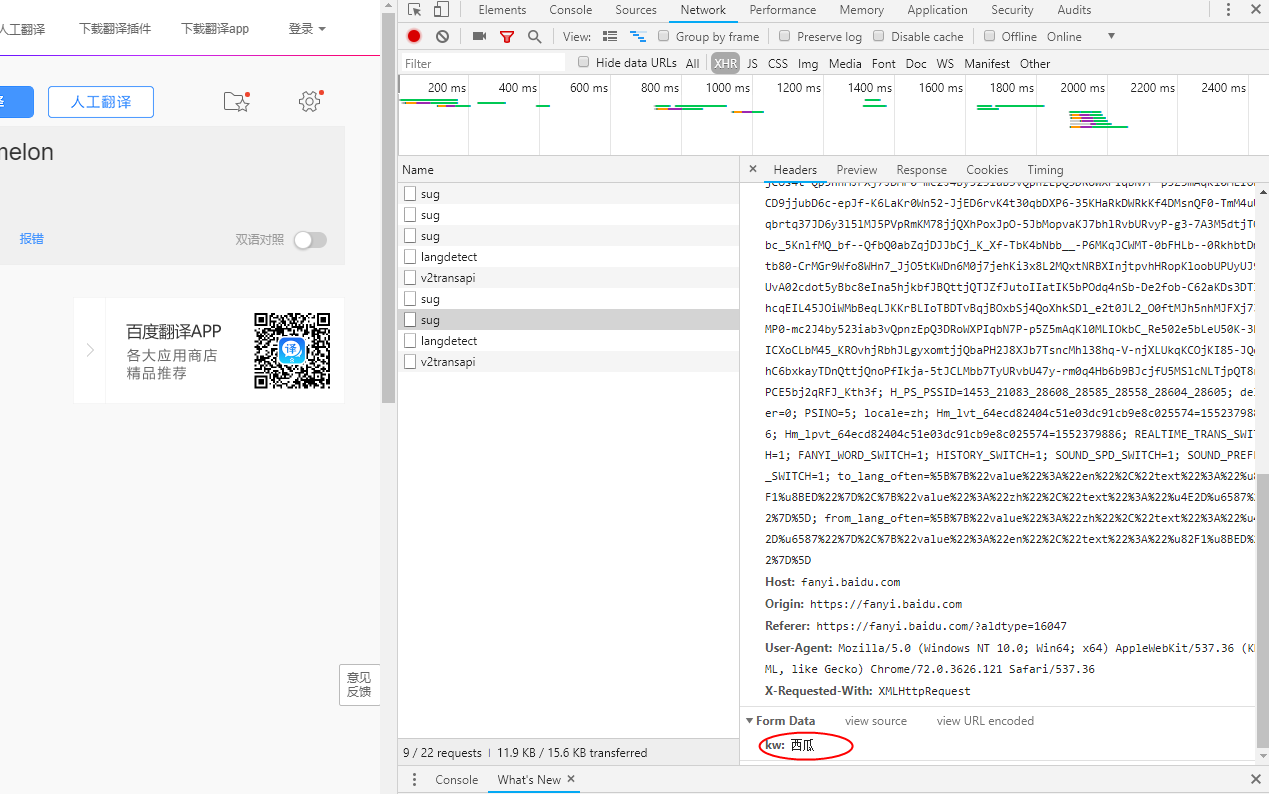
url = ‘https://fanyi.baidu.com/sug‘
#post请求携带的参数进行处理 流程:
#1.将POST 请求参数封装到字典
data = {
‘kw’:’西瓜’
}
#2。使用parse模块中的urlencode(返回值类型为str)进行编码处理
data = urllib.parse.urlencode(data)
type(data)
#3.将步骤2的编码结果转换成byte类型
data = data.encode()
#2.发起post请求:urlopen函数的data参数表示的就是经过处理之后的post请求携带的参数
response = urllib.request.urlopen(url=url,data=data)
response.read()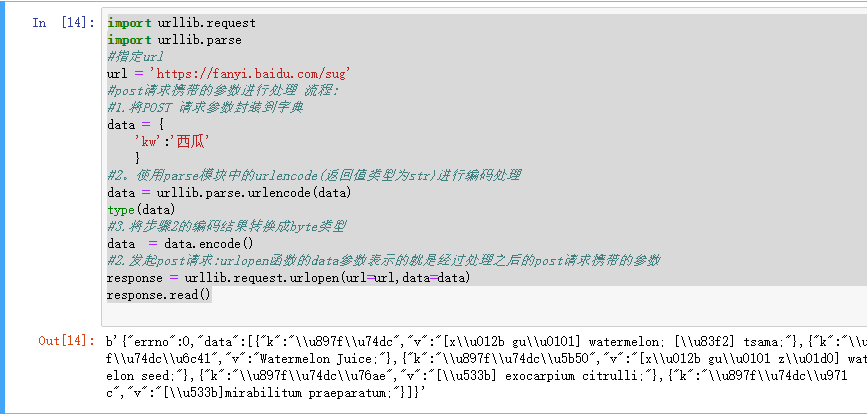
Urllib操作
代理操作
什么是代理:代理就是第三方代替本体处理相关
代理分类:
正向代理:代理客户端获取数据,正向代理是为了保护客户端防止被追究责任
反响代理:代理服务端提供数据,反向代理为了保护服务器或负载均衡
Requests模块
- 什么是requests模块
Python原生一个基于网络请求的模块,模拟浏览器发起请求。
- 为什么要使用requests模块
- 自带处理url编码,
- 自动处理post请求的参数urlencode()
- 简化Cookie的代理的操作
创建一个cookiejar对象
创建一个handler对象
创建一个openrner
创建一个handler对象,代理IP和端口封装到该对象
创建openner对象
3.requests如何被使用
安装:pip install requests
使用流程:
- 指定url
- 使用requests模块发起请求
- 获取响应数据
- 进行持久化存储
基于requests模块
—爬取搜狗首页
import requests
url = ‘https://www.sogou.com/‘
#发起get请求:get 方法会返回请求成功后的响应对象
response = requests.get(url=url)
#获取响应中的数据值,text可以获取响应对象中的字符串形式页面的数据
page_data = response.text
print(page_data)
#持久化操作
with open(‘./sogou.html’,’w’,encoding=’utf-8’) as fp:
fp.write(page_data)
Response对象中其他重要的属性
#response对象中其他重要的属性
import requests
url = ‘https://www.sogou.com/‘
#发起get请求:get 方法会返回请求成功后的响应对象
response = requests.get(url=url)
#获取响应中的数据值,text可以获取响应对象中的字符串形式页面的数据
#content获取的是response对象中二进制类型的数据
# print (response.content)
返回一个状态码
#print(response.status_code)
返回相应头信息
# print(response.headers)
获取请求的url
print(response.url)
Requests如何请求携带参数的get请求
-方式一
方式二
Requsts模块get请求自定义请求头信息
#自定义请求头信息
import requests
url = ‘https://sogou.com/web‘
将参数封装到字典中
params = {
‘query’:’周杰伦’,
‘ie’:’utf-8’
}
#自定义请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
response = requests.get(url=url,params=params,headers=headers)
response.status_code
基于requests模块发起的post请求
#基于requests模块发起的post请求
#- 需求:登陆豆瓣网,获取登陆成功后的页面数据
import requests
url = ‘https://accounts.douban.com/login‘
#封装post请求的参数
data = {
‘source’:’movie’,
‘redir’:’https://movie.douban.com/‘,
‘form_email’:’18401747334’,
‘form_password’:’fei@163.com’,
‘login’:’登录’,
}
#自定义请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#发起post请求
respomse = requests.post(url=url,data=data,headers=headers)
#获取响应对象中的页面数据
page_text = respomse.text
#持久化
with open(‘./douban.html’,’w’,encoding=’utf-8’) as fp:
fp.write(page_text)
Requests模块ajax的get请求、
#基于ajax的get请求
import requests
url = ‘https://movie.douban.com/j/chart/top_list?‘
#封装ajax的get请求中携带的参数
params = {
‘type’: ‘13’,
‘interval_id’: ‘100:90’,
‘action’: ‘’,
‘start’: ‘10’,
‘limit’: ‘20’
}
#请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
respomse = requests.get(url=url,params=params,headers=headers)
print(respomse.text)
基于ajax的post请求
#基于ajax的post请求
#需求:爬取肯德基城市餐厅位置数据
import requests
#指定url
post_url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
#post请求的参数
data = {
‘cname’: ‘’,
‘pid’: ‘’,
‘keyword’: ‘杭州’,
‘pageIndex’: ‘1’,
‘pageSize’: ‘10’
}
#自定义请求头
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#发起基于ajax的post请求
response = requests.post(url=post_url,headers=headers,data=data)
response.text
Requests模块综合学习
获取前3页
import requests
import os
创建文件夹
if not os.path.exists(‘./pages’):
os.mkdir(‘./pages’)
word = input(‘enter a word:’)
#动态指定页码的范围
start_pagenum = int(input(‘enter a start pageNum:’))
end_pageNum = int(input(‘enter a end pageNum:’))
#请求头信息
headers = {
‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36’
}
#指定url,设计成一个具有通用的url
url = ‘https://zhihu.sogou.com/zhihu‘
for page in range(start_pagenum,end_pageNum+1):
param = {
‘query’:word,
‘page’:page,
‘ie’:’utf-8’
}
response = requests.get(url=url,params=params,headers=headers)
#获取相应中的页面数据(指定页面(page))
page_text = respomse.text
#持久化
fileName = word +str(page)+’.html’
filePath = ‘pages/‘+fileName
with open(filePath,’w’,encoding=’utf-8’) as fp:
fp.write(page_text)
print(‘第%d页写入成功’%page)
Requests – cookie
—cookie
基于用户的用户数据
-需求:爬取张三用户的豆瓣网上的个人主页页面数据
—cookie作用:
1.执行登陆操作(获取cookie)
2.在发起个人主页请求时,需要将cookie携带到请求中
注意:session对象:发送请求
-代理操作:<br />为什么使用代理?
- 反爬操作
- 反反爬虫手段
分类:
正向代理:代替客户端获取数据
反向代理:代理服务端提供数据
免费代理ip的网站提供商
www.goubanjia.com
快代理
西祠代理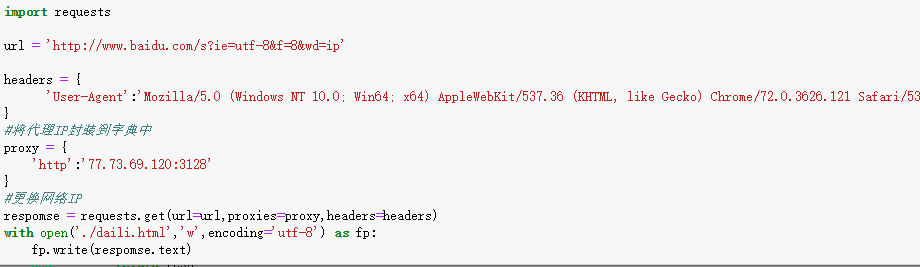
三种数据解析方式
数据解析
三种数据解析方式
正则
Bs4 
Xpath
安装xpath插件:就可以直接将xpath表达式作用于浏览器的网页当中
动态页面加载
- seleniun
- phantomJs


Scrapy框架


创建爬虫项目
#创建爬虫文件

#编写爬虫文件
修改setting的19行的AU和22行的ROBOTSTXT_OBEY默认是true 改成False不让他遵循ROBOTS协议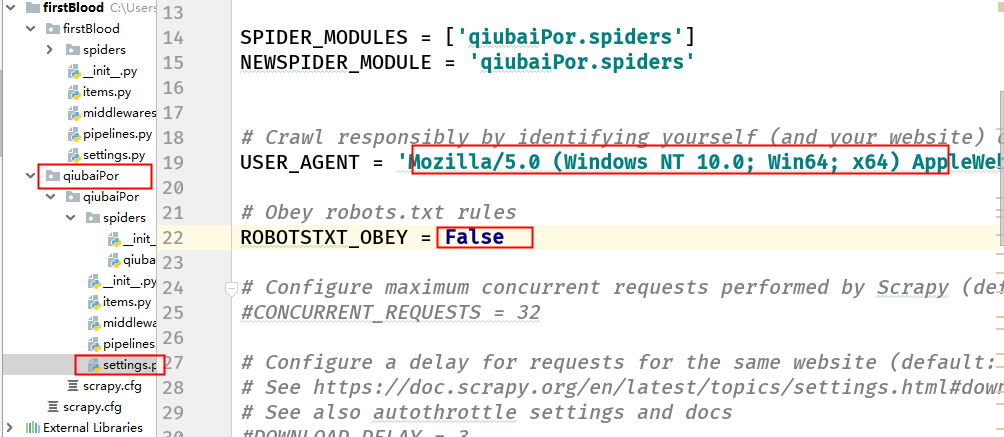
启动>scrapy crawl qiubai –nolog
持久化存储
持久化存储操作
A 磁盘文件
基于终端指令:
保证parse方法返回一个可迭代类型的对象(存储解析到页面内容)
使用终端指令完成数据存储到指定的文件当中
-o 指定的磁盘文件 –nolog 不输出日志
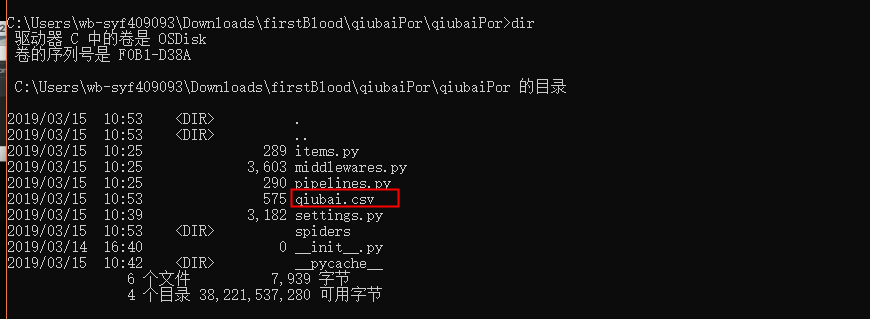
基于管道的数据存储
- items:存储解析到的页面数据
- pipelines:处理解析持久化存储相关操作
- 基于mysql
- 基于redis存储
需求:将爬取到

若有收获,就点个赞吧
0 人点赞
