数据准备
创建或者指定一个数据库用来建表以及存储数据(本文使用
data)create database data charset utf8;
- 注意字符编码,有时候在windows上字符编码默认是gbk所以在后面可能会出现乱码问题。
使用数据库
use data;导入数据(命令行)
source orderinfo.sql; source userinfo.sql- 本文是在在ubuntu下直接在文件所在目录打开的终端并打开mysql之后导入,所以没有路径名,如果不在文件目录下需要输入明确的文件年路径。
- 数据查看
```sql
查看是否导入
show tables;
查看表情况
select from orderinfo; select from userinfo;
查看表结构
desc userinfo; desc orderinfo;
<br />表信息
- userinfo(用户信息表)
- userid:用户ID
- sex:用户性别
- birth:用户出生日期
- orderinfo
- orderid:订单ID
- userid:用户ID
- isPaid:是否支付
- price:付款价格
- paidTime:付款时间
<a name="e1c71aeb"></a>
## 业务需求
<a name="fceedc96"></a>
### 需求一:统计不同月份的下单人数
**思路**:在orderinfo表中使用函数提取年份和月份,并对年份月份进行分组,使用聚合函数求得下单认识。
```sql
select
year(paidTime) as 年份,
month(paidTime) as 月份,
count(distinct userid) cons
from orderinfo
group by 年份,月份;
结果如下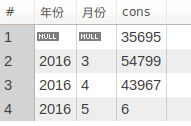
通过结果说明查询有问题,出现了很多年份和月份是null的值。
使用语句查询
select
paidTime,
count(0) nums
from orderinfo
group by paidTime;
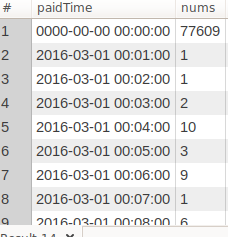
观察发现其中paidTime为'0000-00-00 00:00:00'的数据有很多,其实这些都是脏数据。
所以,牢记使用数据的时候要充分预览数据,发现数据规律以及那些不合理之处。
修正之后的语句
select
year(paidTime) as 年份,
month(paidTime) as 月份,
count(distinct userid) cons
from orderinfo
where paidTime != '0000-00-00 00:00:00'
group by 年份,月份;
需求二:统计用户三月份的回购率和复购率
table
- orderinfo
概念
- 回购率:上月购买用户中有多少用户本月又再次购买的比率
- 购率:当月购买了多次的用户占当月用户的比例
复购率
思路:使用orderifno表利用按照orderid分组后使用having过滤找出次数大于一的就是回购人数,回购人数除总人数就是回购率。
- 三月消费情况
select * from orderinfo where isPaid = "已支付" and month(paidTime) = "03";
其中isPaid = "已支付"解决脏数据的
每个用户在三月消费多少次
select userid, count(1) as cons from orderinfo where isPaid = "已支付" and month(paidTime) = "03" group by userid;使用sumif求满足条件的人数并求得复购率
select count(1) as userid_cons, sum(if(cons>1,1,0)) as fugou_cons, sum(if(cons>1,1,0))/count(1) as fugou_rate from (select userid, count(1) as cons from orderinfo where isPaid="已支付" and month(paidTime)="03" group by userid ) a;
回购率
思路:先查询3月中消费的用户,之后查询4月份消费的用户使用left join。
select
a.month_dt,
count(a.userid) ,
count(b.userid) ,
count(b.userid) / count(a.userid)
from (select
userid,
date_format(paidTime,'%Y-%m-01') as month_dt,
count(1) as cons
from orderinfo
where isPaid="已支付"
group by userid,date_format(paidTime,'%Y-%m-01')) a
left join (select
userid,
date_format(paidTime,'%Y-%m-01') as month_dt,
count(1) as cons
from orderinfo
where isPaid="已支付"
group by userid,date_format(paidTime,'%Y-%m-01')) b
on a.userid=b.userid
and date_sub(b.month_dt,interval 1 month)=a.month_dt
group by a.month_dt;
需求三:统计男女用户消费频次是否有差异
消费频次 = 消费总数 / 消费人数
select
sex,
avg(cons) as avg_cons
from ( select
a.userid,
sex,
count(1) as cons
from orderinfo a
inner join userinfo b
on a.userid = b.userid
group by userid,sex) a
group by sex;
需求四:统计多次消费的用户,第一次和最后一次消费间隔是多少天
思路:可以直接使用聚合函数
select
userid,
min(paidTime),
max(paidTime),
datediff(max(paidTime),min(paidTime))
from orderinfo
where isPaid = "已支付"
group by userid
having count(1) > 1;
需求五:统计不同年龄段,用户的消费金额是否有差异
计算每个用户的年龄,并对年龄进行分层:每10岁为一个等级
select userid, birth, now(), ceil(timestampdiff(year,birth,now())/10) as age from userinfo where birth>'1901-00-00';关联订单信息,获取不同年龄段的一个消费频次和消费金额
select a.userid, age, count(1) as cons, sum(price) as prices from orderinfo a inner join (select userid, birth, now(), ceil(timestampdiff(year,birth,now())/10) as age from userinfo where birth>'1901-00-00') b on a.userid=b.userid group by a.userid,age;对年龄分层进行聚合,得到不同年龄层的消费情况
select age, avg(cons), avg(prices) from (select a.userid, age, count(1) as cons, sum(price) as prices from orderinfo a inner join (select userid, birth, now(), ceil(timestampdiff(year,birth,now())/10) as age from userinfo where birth>'1901-00-00') b on a.userid=b.userid group by a.userid,age) a group by age;
需求六:统计消费的二八法则,消费的top20%用户,贡献了多少消费额
统计每个用户的消费金额,并进行一个降序排序
select userid, sum(price) as total_price from orderinfo a where isPaid="已支付" group by userid;统计一下一共有多少用户,以及总消费金额是多少
select count(1) as cons, sum(total_price) as all_price from (select userid, sum(price) as total_price from orderinfo a where isPaid="已支付" group by userid) a;取出前20%的用户进行金额统计
select count(1) as cons, sum(total_price) as all_price from ( select userid, sum(price) as total_price from orderinfo a where isPaid="已支付" group by userid order by total_price desc limit 17000) b ;
总结
- 使用数据的所时候一定要充分了解数据,特别是对那些不合理的脏数据进行处理,不然会出现很大的偏差。
- 在一个很复杂的需求下,都是由一条一条简单的组成,所以,遇到难的需求的时候先分解之后再聚合。

若有收获,就点个赞吧
0 人点赞
