mapreduce.pdf
MapReduce工作机制-全流程图:
其中Map阶段分为MapTask阶段和Map的shuffle阶段:
MapTask:主要就是对输入的原文件进行分析读取,得到K1和V1,由自己编写规则
Map的shuffle阶段:主要就是分区、排序、规约(分组是属于Reduce的shuffle阶段)
1、MapTask的工作机制
2、ReduceTask和Shuffle的工作机制
3、Reduce 端实现 JOIN

reduce端join操作存在的问题:
如果数据很大,会将数据一起通过网络传输给reduce端进行join操作,这样大量数据经过网络传输不仅会影响效率,还会产生数据倾斜,将大量的数据都传输给了reduce端。
4、Map端实现 JOIN
适用于关联表中有小表的情形,使用map端的join就不用在写reduce了,就是在mapper中需要重写一个方法setup,在启动的时候只调用一次。
5、求共同好友
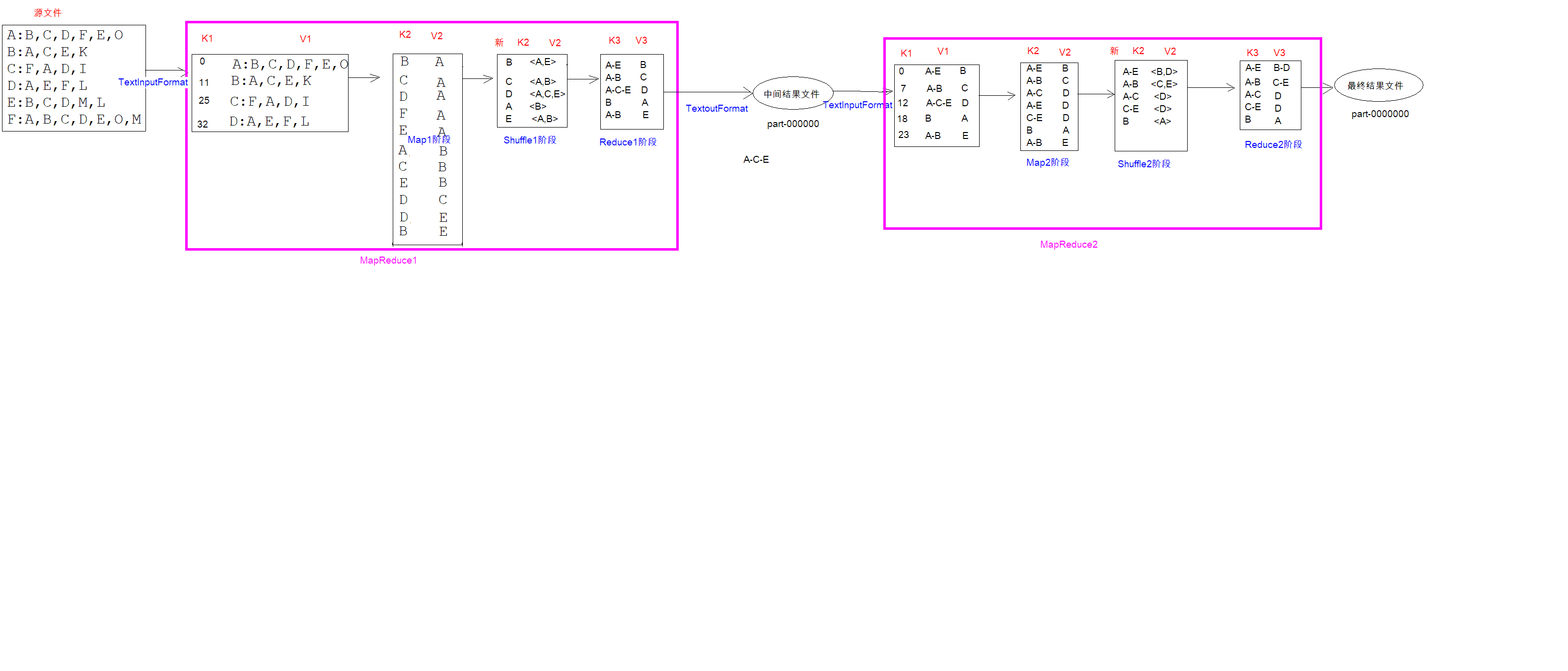
该功能的实现需要两个mapreduce

若有收获,就点个赞吧
0 人点赞
