并查集(Disjoint set,Union-Find)是一种用来管理元素分组情况的数据结构。并查集的一种高效实现是:使用树的根节点「代表」一个集合,同一棵树上的所有节点属于一个集合。只要两个元素的根节点相同,就视为属于同一个集合。使用树的根节点代表一个集合的方法,称之为「代表元」法。
- 初始化(Init):将每个元素所在集合初始化为其自身。
- 合并(Union):将两个元素所属的集合合并为一个集合。
- 查找(Find):查找元素所在的集合,即根节点。
应用
- 最小生成树:Kruskal 算法
- 图的联通分量
- 动态联通性格
- 二分图判断等
局限
- 不支持拆分(split)操作:任何节点一旦成为其他节点的子节点后,将永远不可能再成为树根。
- 集合必须是不相交的(disjoint):同一个元素不能属于多个集合。
- 代表元不记录集合成员信息:
- 父节点不记录子节点的信息。
- 查找图中某节点所在的连通分量的所有节点需要再次扫描或者维护额外信息。
代码模板
//并查集 init(n),Find(x) 以及 Union(x, y) 函数,分别对应初始化,查找,合并操作class UnionFind {int count;int[] parent;int[] rank;//init初始化public UnionFind(int n) {//连通分量个数count = 0;//集合的代表元素 parent 数组parent = new int[n];/*考虑到优化并查集的算法时间复杂度可以采用路径压缩和按秩合并两种方式下面使用按秩合并,为了实现按秩合并,秩是衡量一颗树的指标,它可以是树中节点数,也可以是树的最大深度。我们使用 rank 数组记录额外信息*/rank = new int[n];for (int i = 0; i < n; ++i) {// 初始时每个集合的代表元素就是自身parent[i] = i;++count;//初始化的时候每个集合节点rank都一样 只有一个元素rank[i] = 1;}}//最坏情况下树退化为链 Find 函数最坏时间复杂度是:O(n),n 为节点数。/* 查找 x 所在集合的代表元素,即父节点 */public int find(int x) {while (x != parent[x]) {// 不断循环查找根结点x = parent[x];}return parent[x];}/* union函数 合并 x y 所在集合 */public void union(int x, int y) {//查询x所在集合int rootx = find(x);//查询y所在集合int rooty = find(y);if (rootx != rooty) {// x 所在集合比 y 所在集合节点数多// 将 y 所在集合合并到 x 所在集合,并更新 x 所在集合的节点数信息if (rank[rootx] > rank[rooty]) {parent[rooty] = rootx;rank[rootx] +=rank[rooty];} else {// x 所在集合不比 y 所在集合节点数多// 将 x 所在集合合并到 y 所在集合,并更新y所在集合的信息parent[rootx] = rooty;rank[rooty] += rank[x];}//合并一次就要减少一次连通分量的个数--count;}}//返回连通分量个数public int getCount() {return count;}// 判断两个节点是否在一个连通分量里面public boolean isConnect(int x,int y){int rootx = find(x),rooty = find(y);return rootx == rooty;}}
例题1:
lc785 二分图的判定 https://leetcode-cn.com/problems/is-graph-bipartite/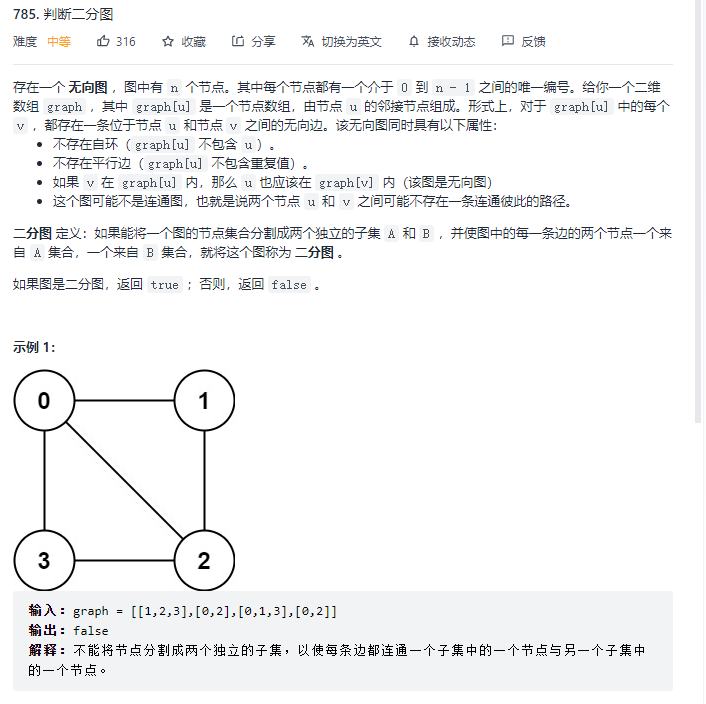
AC 代码
class Solution {public boolean isBipartite(int[][] graph) {int len = graph.length;// 初始化并查集UnionFind uf = new UnionFind(len);// 遍历每个顶点,将当前顶点的所有邻接点进行合并for (int i = 0; i < len; i++) {int[] adjs = graph[i];// 遍历该顶点的邻接点for (int w: adjs) {// 若某个邻接点与当前顶点已经在一个集合中了,说明不是二分图,返回 false。if (uf.isConnected(i, w)) {return false;}// 所有邻接点进行合并uf.union(adjs[0], w);}}return true;}}// 并查集class UnionFind {int[] roots;public UnionFind(int n) {roots = new int[n];for (int i = 0; i < n; i++) {roots[i] = i;}}public int find(int i) {if (roots[i] == i) {return i;}return roots[i] = find(roots[i]);}// 判断 p 和 q 是否在同一个集合中public boolean isConnected(int p, int q) {return find(q) == find(p);}// 合并 p 和 q 到一个集合中public void union(int p, int q) {roots[find(p)] = find(q);}}
例题二
lc839:https://leetcode-cn.com/problems/similar-string-groups/
思路将每个字符串看成图中的一个顶点,判断是否为相似的字符串,如果相似则用并查集合并
最后检查并查集里面有多少连通分量,即相似的字符串组
AC代码:
class Solution {public int numSimilarGroups(String[] strs) {int len = strs.length;int strlen = strs[0].length();UnionFind uf = new UnionFind(len);for(int i=0;i<len;i++){for(int j=i+1;j<len;j++){// 如果两个点已经在一个连通分量里面了 就不需要合并了if(uf.isConnect(i,j))continue;if(check(strs[i],strs[j],strlen)){// 合并两个字符串uf.union(i,j);}}}// 返回连通分量个数return uf.getCount();}// 判断给定字符串是否相似public boolean check(String a, String b, int len) {int num = 0;for (int i = 0; i < len; i++) {if (a.charAt(i) != b.charAt(i)) {num++;if (num > 2) {return false;}}}return num == 0 || num == 2;}class UnionFind {int count;int[] parent;int[] rank;public UnionFind(int n) {//连通分量个数count = 0;parent = new int[n];rank = new int[n];for (int i = 0; i < n; ++i) {parent[i] = i;++count;rank[i] = 1;}}public int find(int x) {while (x != parent[x]) {x = parent[x];}return parent[x];}public void union(int x, int y) {int rootx = find(x);int rooty = find(y);if (rootx != rooty) {if (rank[rootx] > rank[rooty]) {parent[rooty] = rootx;rank[rootx] +=rank[rooty];} else {parent[rootx] = rooty;rank[rooty] += rank[x];}//合并一次就要减少一次连通分量的个数--count;}}//返回连通分量个数public int getCount() {return count;}// 判断两个节点是否在一个连通分量里面public boolean isConnect(int x,int y){int rootx = find(x),rooty = find(y);return rootx == rooty;}}}
并查集的时间复杂度
理论上,「路径压缩」与「按秩合并」,
执行 m次 Find操作, n-1 次 union操作的时间复杂度是  ,
,
其中 
 是反阿克曼函数。
是反阿克曼函数。
反阿克曼函数是一个渐进复杂度很低的函数,通常可以认为是 常数级别的时间复杂度。感兴趣的可以自行查询
Theorem. [Tarjan 1975] Link-by-size with path compression performs any intermixed sequence of m \geq nm≥n FIND and n-1n−1 UNION operations in O(m \space \alpha(m, n))O(m α(m,n)) time, where \alpha(m, n)α(m,n) is a functional inverse of the Ackermann function. [1, 2]

若有收获,就点个赞吧
0 人点赞
