- 题目
Bag of Tricks for Efficient Text Classification
Enriching word vectors with subword information
- 优点
- 快速进行文本分类,效果与许多深度学习分类器平分秋色。
- 提出使用子词的词向量训练方法,一定程度上解决OOV问题。
- 模型
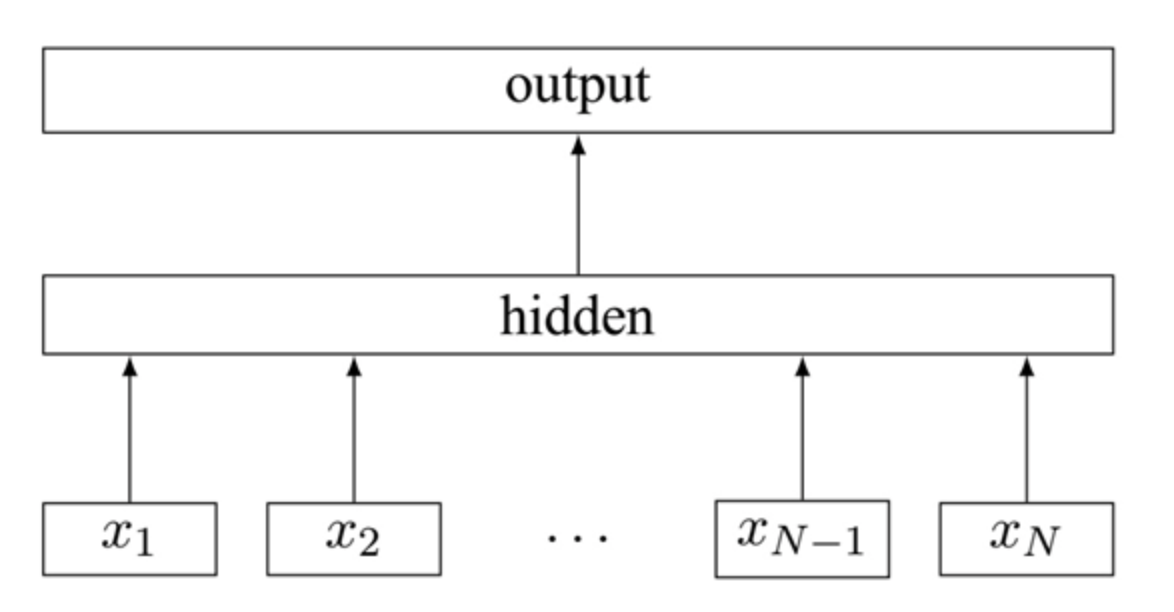
与CBOW的联系
- 对数线性模型。
- 对输入的词向量做平均然后进行预测。
- 模型结构一样。
与CBOW的区别
- fastText提取的是句子特征,CBOW提取的上下文特征。
- fastText是监督学习,CBOW为无监督学习。
存在的问题与解决方法
- 类别很多的时候,softmax速度慢,采用层次softmax。
- 使用词袋模型,没有词序信息,采用n-gram。
- 代码
数据预处理
from torch.utils import dataimport osimport csvimport nltkimport numpy as npimport torchimport torch.nn as nnimport numpy as npf = open("./data/AG/train.csv")rows = csv.reader(f, delimiter=',', quotechar='"')rows = list(rows)n_gram = 2lowercase = Truelabel = []datas = []for row in rows:label.append(int(row[0])-1)txt = " ".join(row[1:])if lowercase:txt = txt.lower()txt = nltk.word_tokenize(txt) # 将句子转化成词new_txt= []for i in range(0,len(txt)):for j in range(n_gram): # 添加n-gram词if j<=i:new_txt.append(" ".join(txt[i-j:i+1]))datas.append(new_txt)min_count = 3word_freq = {}for data in datas: # 首先统计词频,后续通过词频过滤低频词for word in data:if word_freq.get(word) != None:word_freq[word] +=1else:word_freq[word] = 1word2id = {"<pad>":0,"<unk>":1}for word in word_freq: # 首先构建uni-gram词,因为不需要hashif word_freq[word] < min_count or " " in word:continueword2id[word] = len(word2id)uniwords_num = len(word2id)for word in word_freq: # 构建2-gram以上的词,需要hashif word_freq[word] < min_count or " " not in word:continueword2id[word] = len(word2id)max_length = 100for i, data in enumerate(datas):for j, word in enumerate(data):if " " not in word:datas[i][j] = word2id.get(word,1)else:datas[i][j] = word2id.get(word, 1) % 100000 + uniwords_num # hash函数datas[i] = datas[i][0:max_length]+[0]*(max_length-len(datas[i]))
模型
注:torch.nn.``AvgPool1d
input_shape : [N,C,in]output_shape : [N,C,out]m = nn.AvgPool1d(3, stride=2) # pool with window of size=3, stride=2m(torch.tensor([[[1.,2,3,4,5,6,7]]]))# tensor([[[ 2., 4., 6.]]])

class Fasttext(nn.Module):
def __init__(self, vocab_size, embedding_size, max_length, label_num):
super(Fasttext,self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size) # 嵌入层
self.avg_pool = nn.AvgPool1d(kernel_size=max_length, stride=1) # 平均层
self.fc = nn.Linear(embedding_size, label_num) # 全连接层
def forward(self, x):
x = x.long()
out = self.embedding(x) # batch_size*length*embedding_size
out = out.transpose(1, 2).contiguous() # batch_size*embedding_size*length
out = self.avg_pool(out).squeeze() # batch_size*embedding_size
out = self.fc(out) # batch_size*label_num
return out
from torchsummary import summary
fasttext = Fasttext(vocab_size=1000,embedding_size=10,max_length=100,label_num=4)
summary(fasttext, input_size=(100,))

若有收获,就点个赞吧
0 人点赞
