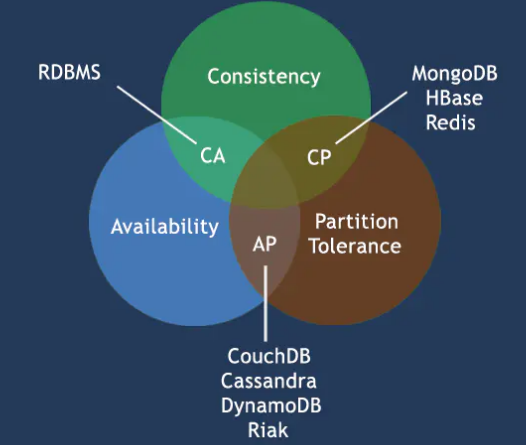
CAP原理称为CAP定理,指在同一个分布式系统中 一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,对于一个分布式系统来说 这三个要素最多只能同时实现两点,不可能三者兼顾。
Consistency 一致性:所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)Availability 可用性:在集群中一部分节点故障后,集群整体还能响应客户端的读写请求。(对数据更新具备高可用性)Partition Tolerance 容错性:分布式系统在遇到任何网络分区故障的时候,任然能够对外提供一致性和可用性的服务,
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
分区容错性指的是: System continues operating despire arbitrary message loss or failure of part of the system. 翻译过来就是说系统在遇到一些节点或者网络分区故障的时候,仍然能够提供满足一致性和可用性的服务。
总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
**
数据一致性:
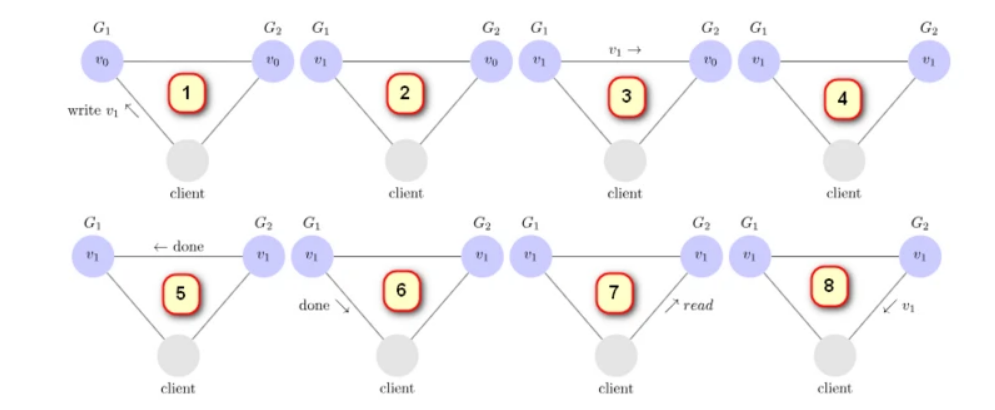
上面的这个图可以对数据一致性进行描述:
- 有两个服务器,一个客户端,当client向G1服务器写入数据 v1,这个时候 G1的数据 从 v0—>v1,这个时候G2的数据还是v0不一样,
- 接着G1在响应客户端成功之前要自动同步G2的数据, 使得G2服务器的数据也是v1
- 一致性保证了客户端不管向哪台服务器写入数据,其他的服务器都能实时同步数据
- G2同步数据之后告诉G1同步完成
- G1收到所有服务器的同步报告,才将“写入成功”信息响应给客户端
可用性:
CP: 一致性和分区容错性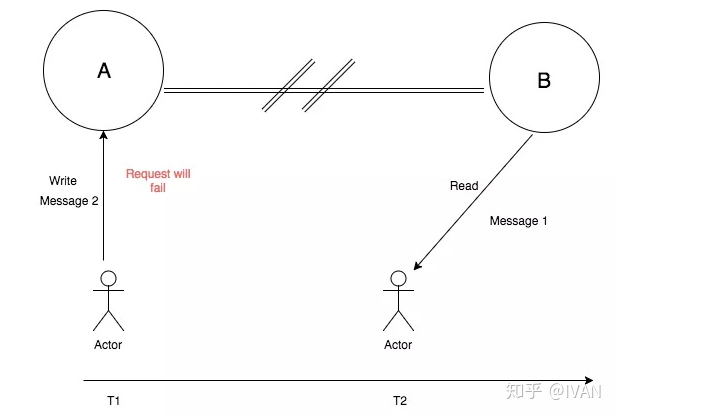
如上图,由于网络问题,节点A和节点B之前不能互相通讯。当有客户端(上图Actor)向节点A进行写入请求时(准备写入Message 2),节点A会不接收写入操作,导致写入失败,这样就保证了节点A和节点B的数据一致性,即保证了Consisteny(一致性)。
然后,如果有另一个客户端(上图另一个Actor)向B节点进行读请求的时候,B请求返回的是网络故障之前所保存的信息(Message 1),并且这个信息是与节点A一致的,是整个系统最后一次成功写入的信息,是能正常提供服务的,即保证了Partition tolerance(分区容错性)。
上述情况就是保障了CP架构,但放弃了Availability(可用性)的方案。
AP: 可用性和分区容错性:
如上图,由于网络问题,节点A和节点B之前不能互相通讯。当有客户端(上图Actor)向节点A进行写入请求时(准备写入Message 2),节点A允许写入,请求操作成功。但此时,由于A和B节点之前无法通讯,所以B节点的数据还是旧的(Message 1)。当有客户端向B节点发起读请求时候,读到的数据是旧数据,与在A节点读到的数据不一致。但由于系统能照常提供服务,所以满足了Availability(可用性)要求。
因此,这种情况下,就是保障了AP架构,但其放弃了 Consisteny(一致性)。
至于为什么不能兼得
如果一致性是第一需求,那么 高可用就会收到影响,因为要保证数据一致性,进行数据同步,不然请求的结果就会有差异,但是数据同步会消耗时间,期间的可用就降低了
参考链接:
https://www.cnblogs.com/techflow/p/12178912.html
Eureka是AP: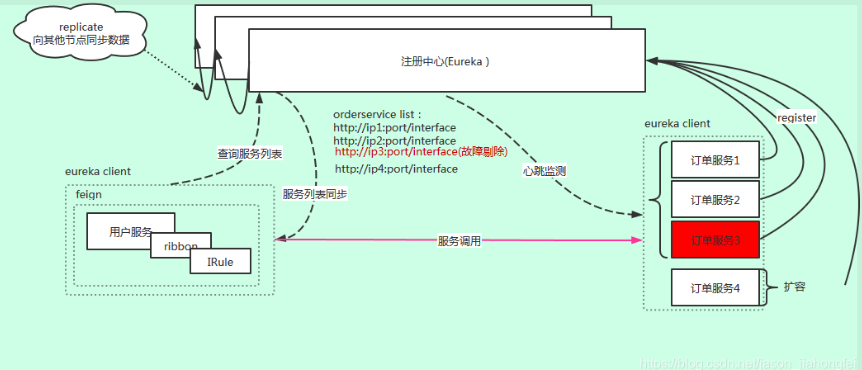
eureka 保证了可用性,实现最终一致性。
Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性),其中说明了,eureka是不满足强一致性,但还是会保证最终一致性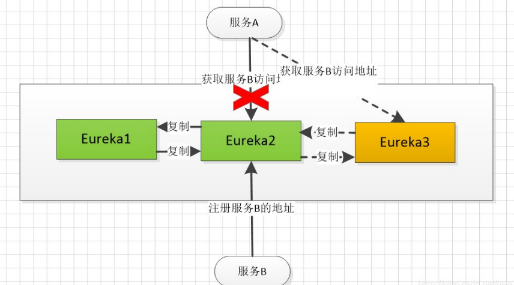
当我们后面增加了一个Eureka3 ,原本服务B是注册在Eureka2上的,在增加了3之后,2需要往3里面复制服务列表,但是还没有注册成功就挂掉了,这个事务服务A向Eureka中获取服务地址会发现数据不一致,当服务A通过服务注册于发现中心集群通过Eureka3来拿服务B的地址时,就无法拿到。这样就无法保证数据一致性
zookeeper是 CP模式:
zoomkeeper服务注册与发现中心集,在集群中,包含一个Leader节点,其余全部为Follower 节点。Leader节点负责读和写操作,Follower 节点只负责读操作。当客户端向集群发出写请求时,写请求会转发到Leader节点,Leader写操作完成后,采用广播的形式,向其余Follower 节点复制数据,Follower节点也写成功,返回给客户端成功。流程如图:

如图,在服务A向zoomkeeper集群注册时,写请求会被转发到Leader节点(zoomkeeper1),此时,Leader节点写入成功后,会通知 zoomkeeper2和zoomkeeper3节点进行复制,并且复制成功了才会向服务A返回注册成功的状态。此后,服务B通过集合获取服务A的地址,无论从哪个节点都能获取服务A的服务地址。
Base 理论:
- 基本可用
- 软状态
- 最终一致性

若有收获,就点个赞吧
0 人点赞
