摘要
YARN设计基本思想是,将资源管理和作业调度(监控)的功能拆离到不同的守护进程当中。该思想中,将会被设计出总的资源管理器:ResourceManager(RM)以及应用管理器:ApplicationMaster(AM)。一个Application即是一个单一的job,或者是job流即一个DAG.
ResourceManager和NodeManager将会从数据计算框架中衍生。
ResourceManager是在系统中的所有应用程序作为仲裁者的存在,将会对资源的分配做出仲裁。
NodeManager 是每台机器的框架代理,负责容器、监控它们的资源使用(cpu、内存、磁盘、网络)并将其报告给 ResourceManager/Scheduler。
每个应用程序的 ApplicationMaster 实际上是一个特定于框架的库,其任务是从 ResourceManager 协商资源并与 NodeManager(s) 一起执行和监视任务。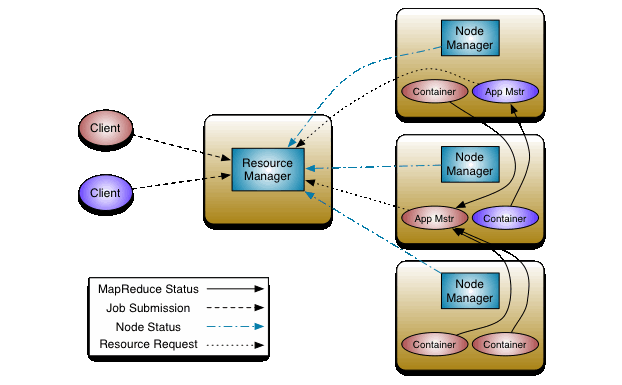
ResourceManager 有两个主要组件:Scheduler 和 ApplicationsManager。
调度程序负责根据容量、队列等熟悉的限制为各种正在运行的应用程序分配资源。调度程序是纯粹的调度程序,因为它不执行任何监视或跟踪应用程序的状态。此外,它不保证由于应用程序故障或硬件故障而重新启动失败的任务。 Scheduler 根据应用程序的资源需求执行其调度功能;它是基于资源容器的抽象概念来实现的,资源容器包含内存、cpu、磁盘、网络等元素。
调度器采用插拔式的策略,负责在各种队列、应用程序等之间划分集群资源。当前的调度器,如 CapacityScheduler 和 FairScheduler 就是插件的一些例子。
ApplicationsManager 负责接受作业提交,协商第一个容器以执行特定于应用程序的 ApplicationMaster,并提供在失败时重新启动 ApplicationMaster 容器的服务。每个应用程序的 ApplicationMaster 负责从调度程序协商适当的资源容器,跟踪它们的状态并监控进度。
hadoop-2.x 中的 MapReduce 保持 API 与先前稳定版本 (hadoop-1.x) 的兼容性。这意味着所有 MapReduce 作业仍应在 YARN 之上运行不变,只需重新编译即可。
YARN 通过 ReservationSystem 支持资源预留的概念,该组件允许用户指定资源配置文件随时间和时间约束(例如,截止日期),并预留资源以确保重要作业的可预测执行。ReservationSystem 跟踪资源超时,对保留执行准入控制,并动态指示底层调度程序确保完成保留。
为了将 YARN 扩展到数千个节点之外,YARN 通过 YARN 联合功能支持联合的概念。联邦允许透明地将多个纱线(子)集群连接在一起,并使它们看起来像一个巨大的集群。这可用于实现更大的规模,和/或允许将多个独立集群一起用于非常大的作业,或用于在所有这些作业中具有容量的租户。
基础架构
1> ResourceManager (RM)
- 接收客户端任务请求,
- 接收和监控
NodeManager中 的资源情况report, 负责资源的分配与调度,启动和监控
ApplicationMaster。2> NodeManager
每一台任务节点上的资源管理,
启动
Container运行task计算,进行
task的管理和调度- 向RM进行资源的申请
- 向NM发出
launch container指令 - 接受NM的task处理状态信息。
4> Job History Server
NodeManager在启动的过程中会初始化LogAggregationService服务,该服务会把本机执行的container log(在container执行完毕的时候)进行收集并存放于hdfs制定的目录当中。ApplicationMaster会把jobhistory信息写入到hdfs的jobhistory临时目录当中,在执行完毕之后,将hobhostry移动到制定目录当中。

若有收获,就点个赞吧
0 人点赞
