Spark是什么?
RDD是什么?
RDD(Resilient Distributed Dataset)弹性分布式数据集,是Spark中最基本的抽象。它具有不可变,可分区,分区元素可并行计算的特性。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。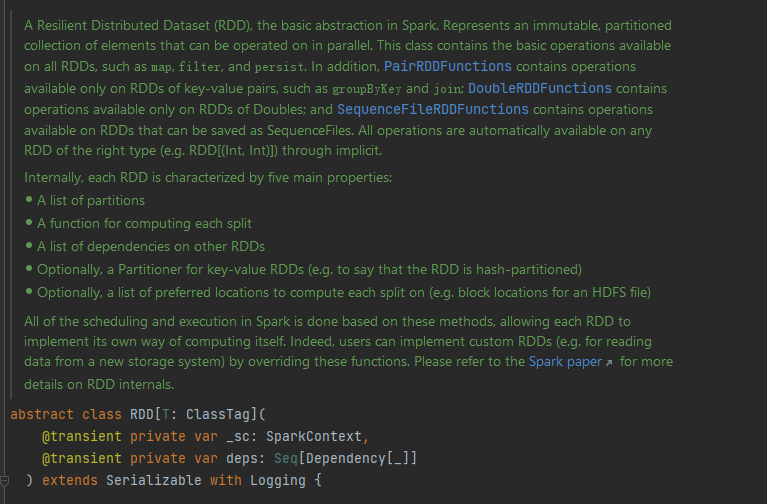
RDD Programming Guide:https://spark.apache.org/docs/latest/rdd-programming-guide.html
基本概念

基本流程
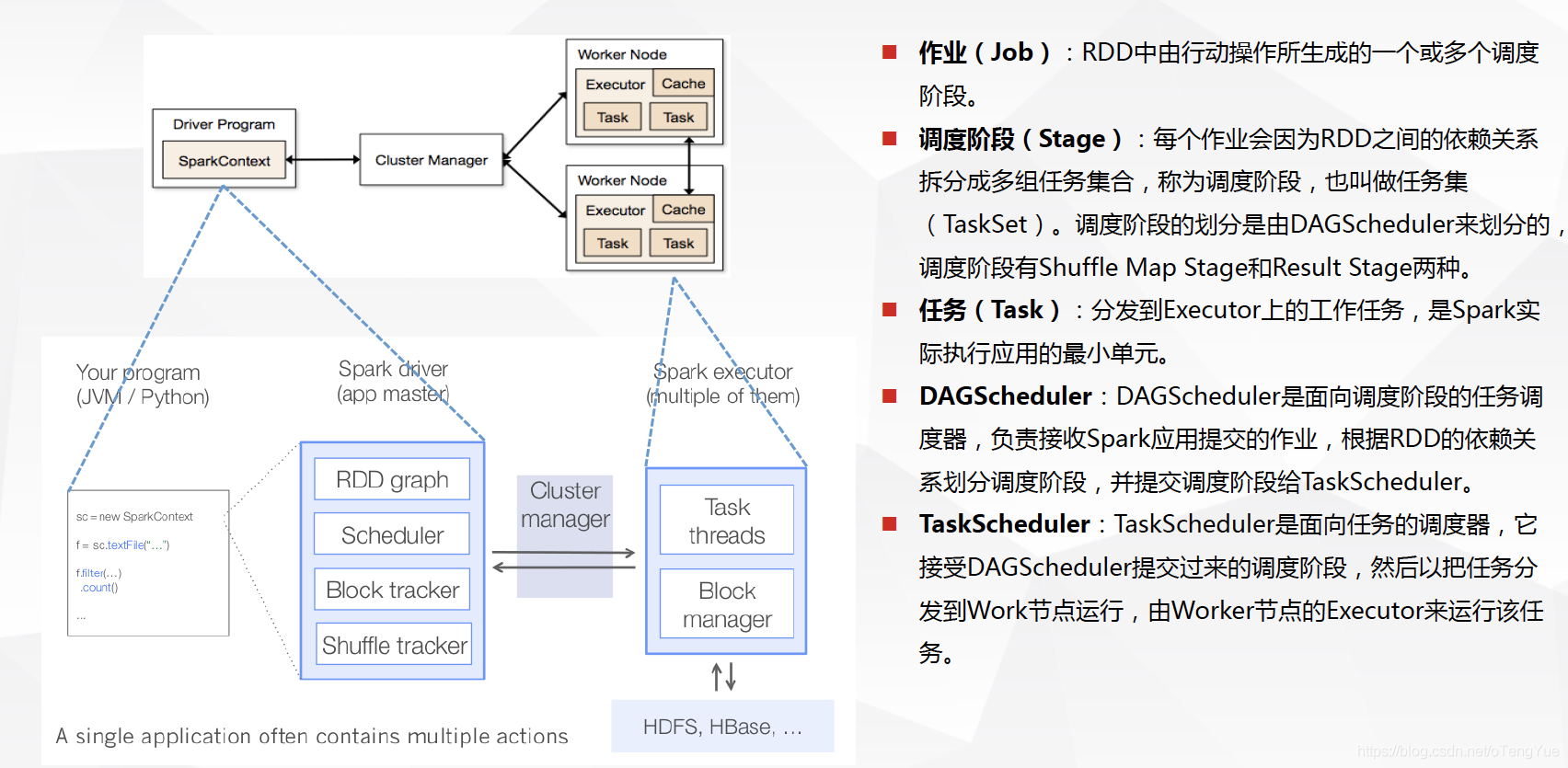
Spark 2.2.0 中文文档:http://spark.apachecn.org
Apache Spark 的设计与实现:https://spark-internals.books.yourtion.com/index.html
基本架构图
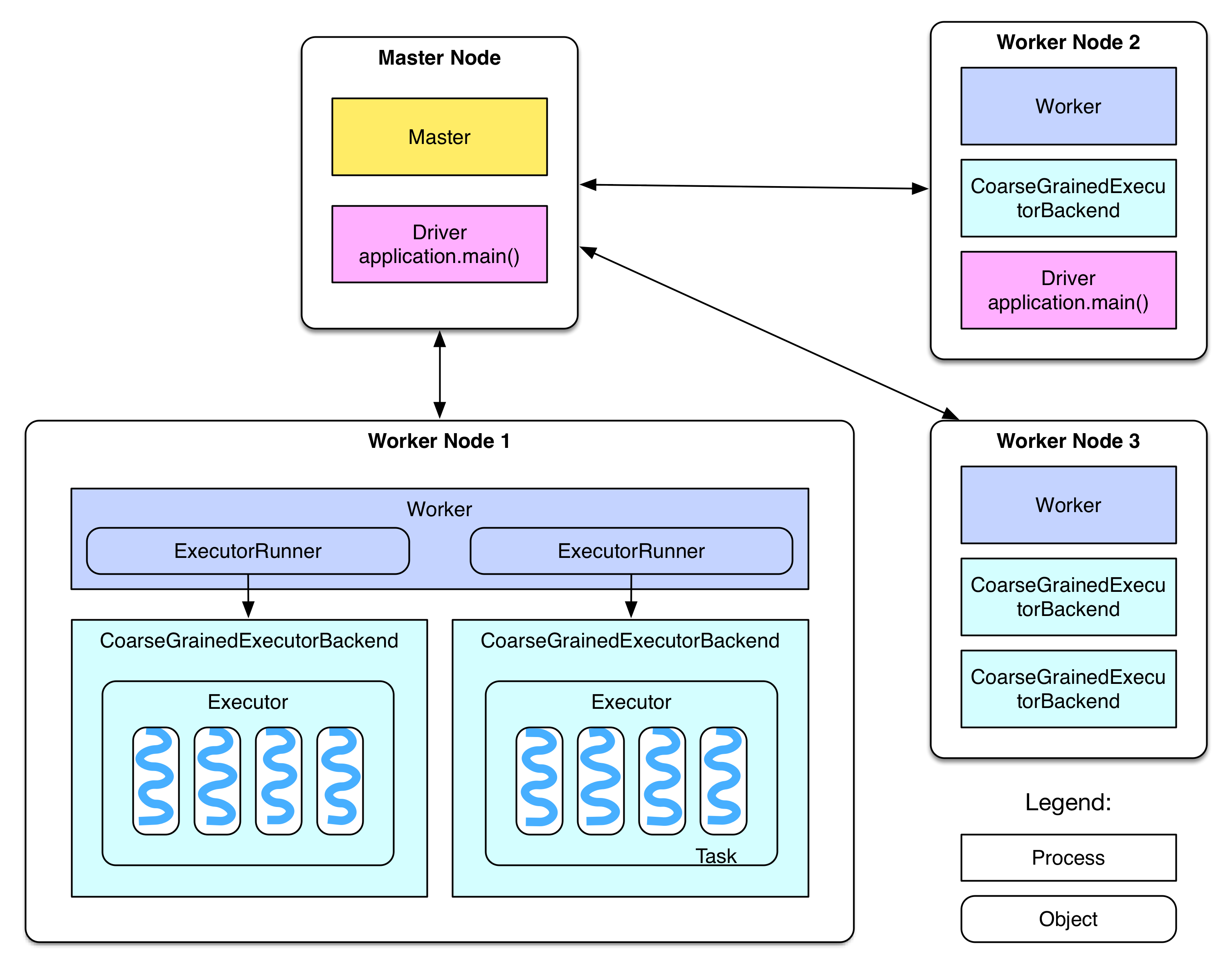
基本架构图描述
Master和Worker
- 整个集群分为 Master 节点和 Worker 节点,相当于 Hadoop 的 Master 和 Slave 节点。
- Master 节点上常驻 Master 守护进程,负责管理全部的 Worker 节点。
- Worker 节点上常驻 Worker 守护进程,负责与 Master 节点通信并管理 executors。
- 每个 Worker 上存在一个或者多个 ExecutorBackend 进程。每个进程包含一个 Executor 对象,该对象持有一个线程池,每个线程可以执行一个 task。
Worker 通过持有 ExecutorRunner 对象来控制 CoarseGrainedExecutorBackend 的启停。
Driver和Application
Driver 官方解释是 “The process running the main() function of the application and creating the SparkContext”。
- Application 就是用户自己写的 Spark 程序(driver program),比如
WordCount.scala。 - 每个 Application 包含一个 driver 和多个 executors,每个 executor 里面运行的 tasks 都属于同一个 application。
- 在 Standalone 版本中,ExecutorBackend 被实例化成 CoarseGrainedExecutorBackend 进程。
Examples
样例代码
使用 Spark 自带的 examples 中的 GroupByTest 。 ``` / Usage: GroupByTest [numMappers] [numKVPairs] [valSize] [numReducers] /
bin/run-example GroupByTest 100 10000 1000 36
GroupByTest 具体代码如下:```scalapackage org.apache.spark.examplesimport java.util.Randomimport org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.SparkContext._/*** Usage: GroupByTest [numMappers] [numKVPairs] [valSize] [numReducers]*/object GroupByTest {def main(args: Array[String]) {val sparkConf = new SparkConf().setAppName("GroupBy Test")var numMappers = 100var numKVPairs = 10000var valSize = 1000var numReducers = 36val sc = new SparkContext(sparkConf)val pairs1 = sc.parallelize(0 until numMappers, numMappers).flatMap { p =>val ranGen = new Randomvar arr1 = new Array[(Int, Array[Byte])](numKVPairs)for (i <- 0 until numKVPairs) {val byteArr = new Array[Byte](valSize)ranGen.nextBytes(byteArr)arr1(i) = (ranGen.nextInt(Int.MaxValue), byteArr)}arr1}.cache// Enforce that everything has been calculated and in cachepairs1.countprintln(pairs1.groupByKey(numReducers).count)sc.stop()}}
执行流程图
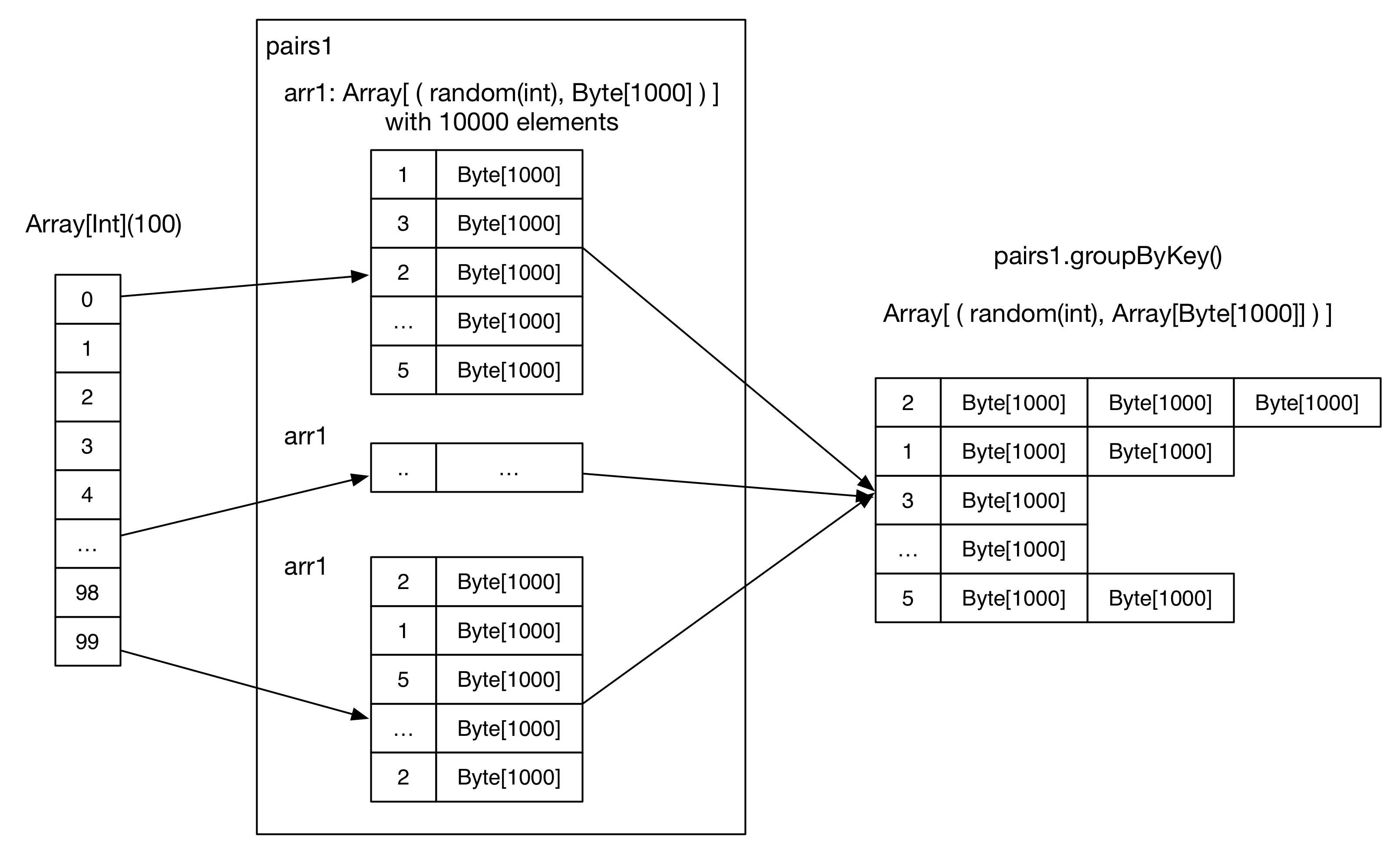
- 初始化 SparkConf()。
- 初始化 numMappers=100, numKVPairs=10,000, valSize=1000, numReducers= 36。
- 初始化 SparkContext。这一步很重要,是要确立 driver 的地位,里面包含创建 driver 所需的各种 actors 和 objects。
- 每个 mapper 生成一个 arr1: Array[(Int, Byte[])],length 为 numKVPairs。每一个 Byte[] 的 length 为 valSize,Int 为随机生成的整数。Size(arr1) = numKVPairs (4 + valSize) = 10MB,所以 Size(pairs1) = numMappers Size(arr1) =1000MB。这里的数值计算结果都是约等于。
- 每个 mapper 将产生的 arr1 数组 cache 到内存。
- 然后执行一个 action 操作 count(),来统计所有 mapper 中 arr1 中的元素个数,执行结果是 numMappers * numKVPairs = 1,000,000。这一步主要是为了将每个 mapper 产生的 arr1 数组 cache 到内存。
- 在已经被 cache 的 paris1 上执行 groupByKey 操作,groupByKey 产生的 reducer (也就是 partition) 个数为 numReducers。理论上,如果 hash(Key) 比较平均的话,每个 reducer 收到的 record 个数为 numMappers * numKVPairs / numReducer = 27,777,大小为 Size(pairs1) / numReducer = 27MB。
- reducer 将收到的
- 最后 count 将所有 reducer 中 records 个数进行加和,最后结果实际就是 pairs1 中不同的 Int 总个数。
Job 逻辑执行图
Job 的实际执行流程比用户头脑中的要复杂,需要先建立逻辑执行图(或者叫数据依赖图),然后划分逻辑执行图生成 DAG 型的物理执行图,然后生成具体 task 执行。分析一下这个 job 的逻辑执行图:
使用 RDD.toDebugString 可以看到整个 logical plan (RDD 的数据依赖关系)如下:
用图表示就是:MapPartitionsRDD[3] at groupByKey at GroupByTest.scala:51 (36 partitions)ShuffledRDD[2] at groupByKey at GroupByTest.scala:51 (36 partitions)FlatMappedRDD[1] at flatMap at GroupByTest.scala:38 (100 partitions)ParallelCollectionRDD[0] at parallelize at GroupByTest.scala:38 (100 partitions)
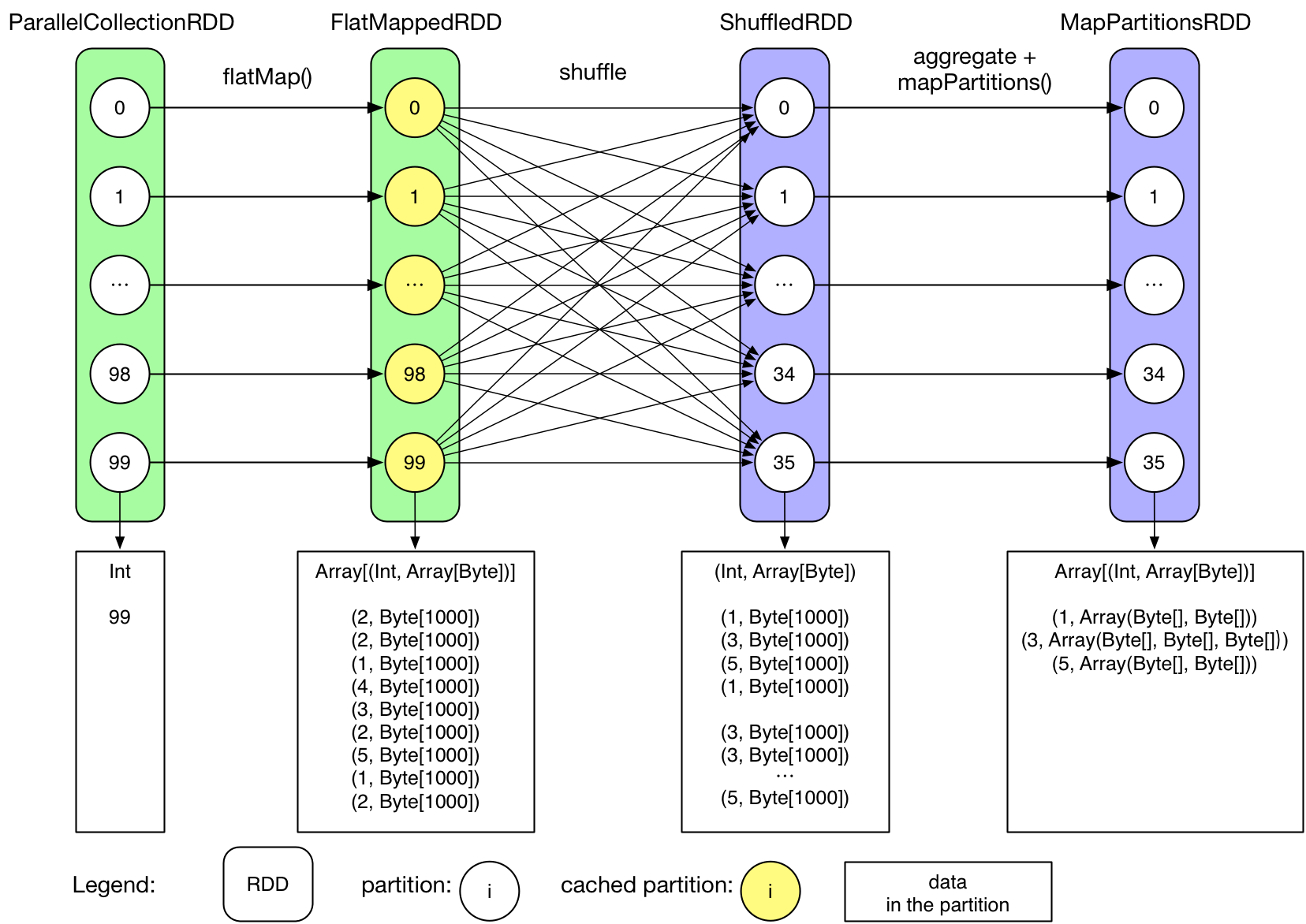
需要注意的是 data in the partition 展示的是每个 partition 应该得到的计算结果,并不意味着这些结果都同时存在于内存中。
根据上面的分析可知:
- 用户首先 init 了一个0-99 的数组: 0 until numMappers
- parallelize() 产生最初的 ParrallelCollectionRDD,每个 partition 包含一个整数 i。
- 执行 RDD 上的 transformation 操作(这里是 flatMap)以后,生成 FlatMappedRDD,其中每个 partition 包含一个 Array[(Int, Array[Byte])]。
- 第一个 count() 执行时,先在每个 partition 上执行 count,然后执行结果被发送到 driver,最后在 driver 端进行 sum。
- 由于 FlatMappedRDD 被 cache 到内存,因此这里将里面的 partition 都换了一种颜色表示。
- groupByKey 产生了后面两个 RDD,为什么产生这两个在后面章节讨论。
- 如果 job 需要 shuffle,一般会产生 ShuffledRDD。该 RDD 与前面的 RDD 的关系类似于 Hadoop 中 mapper 输出数据与 reducer 输入数据之间的关系。
- MapPartitionsRDD 里包含 groupByKey() 的结果。
- 最后将 MapPartitionsRDD 中的 每个value(也就是Array[Byte])都转换成 Iterable 类型。
- 最后的 count 与上一个 count 的执行方式类似。
可以看到逻辑执行图描述的是 job 的数据流:job 会经过哪些 transformation(),中间生成哪些 RDD 及 RDD 之间的依赖关系。
Job 物理执行图
逻辑执行图表示的是数据上的依赖关系,不是 task 的执行图。在 Hadoop 中,用户直接面对 task,mapper 和 reducer 的职责分明:一个进行分块处理,一个进行 aggregate。Hadoop 中 整个数据流是固定的,只需要填充 map() 和 reduce() 函数即可。Spark 面对的是更复杂的数据处理流程,数据依赖更加灵活,很难将数据流和物理 task 简单地统一在一起。因此 Spark 将数据流和具体 task 的执行流程分开,并设计算法将逻辑执行图转换成 task 物理执行图,转换算法后面的章节讨论。
针对这个 job,我们先画出它的物理执行 DAG 图如下: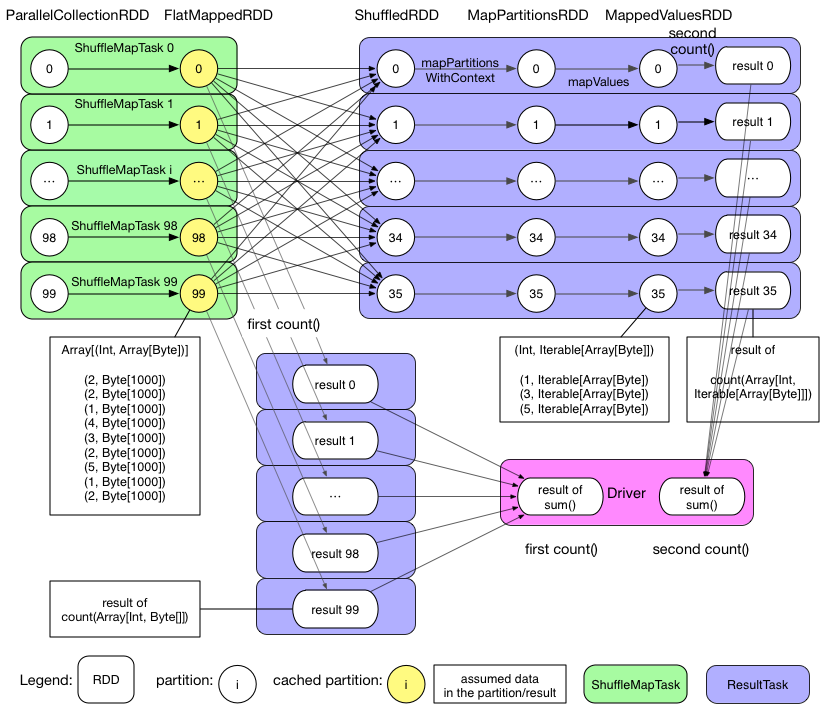
可以看到 GroupByTest 这个 application 产生了两个 job,第一个 job 由第一个 action(也就是 pairs1.count)触发产生,分析一下第一个 job:
- 整个 job 只包含 1 个 stage(不明白什么是stage没关系,后面章节会解释,这里只需知道有这样一个概念)。
- Stage 0 包含 100 个 ResultTask。
- 每个 task 先计算 flatMap,产生 FlatMappedRDD,然后执行 action() 也就是 count(),统计每个 partition 里 records 的个数,比如 partition 99 里面只含有 9 个 records。
- 由于 pairs1 被声明要进行 cache,因此在 task 计算得到 FlatMappedRDD 后会将其包含的 partitions 都 cache 到 executor 的内存。
- task 执行完后,driver 收集每个 task 的执行结果,然后进行 sum()。
- job 0 结束。
第二个 job 由 pairs1.groupByKey(numReducers).count 触发产生。分析一下该 job:
- 整个 job 包含 2 个 stage。
- Stage 1 包含 100 个 ShuffleMapTask,每个 task 负责从 cache 中读取 pairs1 的一部分数据并将其进行类似 Hadoop 中 mapper 所做的 partition,最后将 partition 结果写入本地磁盘。
- Stage 0 包含 36 个 ResultTask,每个 task 首先 shuffle 自己要处理的数据,边 fetch 数据边进行 aggregate 以及后续的 mapPartitions() 操作,最后进行 count() 计算得到 result。
- task 执行完后,driver 收集每个 task 的执行结果,然后进行 sum()。
- job 1 结束。
可以看到物理执行图并不简单。与 MapReduce 不同的是,Spark 中一个 application 可能包含多个 job,每个 job 包含多个 stage,每个 stage 包含多个 task。怎么划分 job,怎么划分 stage,怎么划分 task 等等问题会在后面的章节介绍。

若有收获,就点个赞吧
0 人点赞
