一、Autograd自动求导
autograd 是 pytorch 构建神经网络的核心
**
- 当把tensor的属性 .requires_grad置为True时,pytorch则会追踪在这个tensor上的接下来的所有操作。然后当使用.backward()时,将会自动求导。所有分支上的梯度值将会被累计在 .grad中
- 可以使用with torch.no_grad(): 来暂停梯度记录(可以用在evaluation中)
- 用.backward()求导
1.tensor创建
例1:
import torchx = torch.ones(2, 2, requires_grad=True)print(x)y = x + 2print(y)
结果:这里x的requires_grad 设置成为 True,因此pytorch将会记录x的所有相关的计算流程,方便求微分。
tensor([[1., 1.],[1., 1.]], requires_grad=True)y = x + 2print(y)tensor([[3., 3.],[3., 3.]], grad_fn=<AddBackward0>)
由于运算过程中x 已经设为requires_grad, 在进行 y的赋值运算时 x执行了加法运算。而在y中的grad_fn不为空,说明已经包含了当执行back propagation 时,y所对应的backward函数,这个函数存在y.grad_fn中。
y由x与2相加生成,查看一下y.grad_fn,发现x与2对应的backward 函数被打包成名为next_function的tuple类,其中第一项对应的即为x的backward相关函数,第二项对应的即为2对应的相关函数,由于对实数求导得0,因此不含backward函数。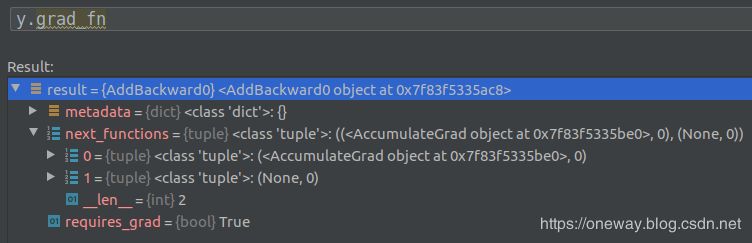
例2:
a = torch.randn(2, 2)a = ((a * 3) / (a - 1))print(a.requires_grad)a.requires_grad_(True)print(a.requires_grad)b = (a * a).sum()print(b.grad_fn)OUT:FalseTrue<SumBackward0 object at 0x7f341c47cd68>
结果:可知在不指定a的时候,默认a的requiresgrad 为 False,当声明a后,可以通过in-place操作`.requires_grad( … )`来改变状态。
2.自动求梯度
例 1 结果为标量时
x = torch.ones(2, 2, requires_grad=True)y = x + 2z = y * y * 3out = z.mean()#由于最终的结果只是单个标量#out.backward()等于 out.backward(torch.tensor(1.))out.backward()print(x.grad)tensor([[4.5000, 4.5000],[4.5000, 4.5000]])
结果:对out进行backprop,out关于x的导数存在了x的.grad中,所以直接print(x.grad)
整个公式: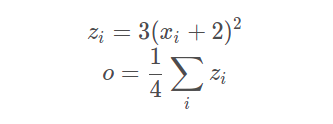
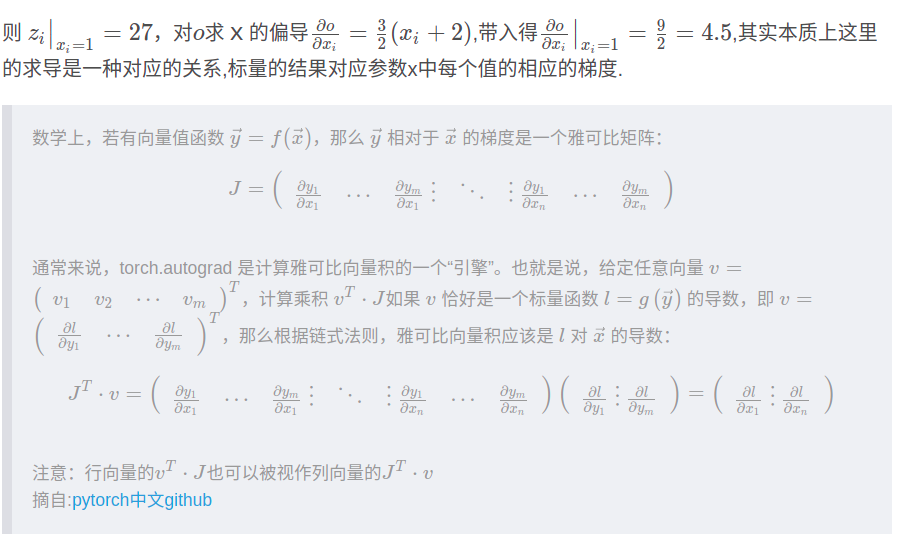
雅可比向量积的这一特性使得将外部梯度输入到具有非标量输出的模型中变得非常方便。
例 2 结果不为标量时
x = torch.randn(3, requires_grad=True)y = x * 2while y.data.norm() < 1000:y = y * 2print(y)tensor([1444.3817, -340.2753, -480.7858], grad_fn=<MulBackward0>)
此时torch.autograd不能直接计算完整的Jacobian矩阵(就是pytorch能力不足).但此时如果想计算vector-Jacobian乘积,只需要把向量加到backward中作为参数即可.
x = torch.tensor([1.,2.,3.], requires_grad=True)y = x * 2print(y)v = torch.tensor([2,1,1],dtype=torch.float)y.backward(v)print(x.grad)tensor([2., 4., 6.], grad_fn=<MulBackward0>)tensor([4., 2., 2.])
结果:可见这里y本身可以看成三个x与2相乘的结果的集合而成的向量. 在这里的v相当于给了结果向量一个权重,生成对应的关于x的导数.
二、leaf 叶子(张量)
在pytorch的tensor类中,有个is_leaf的属性,姑且把它作为叶子节点. is_leaf 为False的时候,则不是叶子节点, is_leaf为True的时候为叶子节点(或者叶张量)
所以问题来了: leaf的作用是什么?为什么要加 leaf?
我们都知道tensor中的 requires_grad()属性,当requires_grad()为True时我们将会记录tensor的运算过程并为自动求导做准备,但是并不是每个requires_grad()设为True的值都会在backward的时候得到相应的grad.它还必须为leaf.这就说明. leaf成为了在 requires_grad()下判断是否需要保留 grad的前提条件。**
_
is_leaf()
**
- 按照惯例,所有requires_grad为False的张量(Tensor) 都为叶张量( leaf Tensor)
- requires_grad为True的张量(Tensor),如果他们是由用户创建的,则它们是叶张量(leaf Tensor).这意味着它们不是运算的结果,因此gra_fn为None,但是如果创建后参与运算则为非叶子张量。
- 只有是叶张量的tensor在反向传播时才会将本身的grad传入的backward的运算中. 如果想得到当前tensor在反向传播时的grad, 可以用retain_grad()这个属性
例子
>>> a = torch.rand(10, requires_grad=True)>>> a.is_leafTrue>>> b = torch.rand(10, requires_grad=True).cuda()>>> b.is_leafFalse# b was created by the operation that cast a cpu Tensor into a cuda Tensor>>> c = torch.rand(10, requires_grad=True) + 2>>> c.is_leafFalse# c was created by the addition operation>>> d = torch.rand(10).cuda()>>> d.is_leafTrue# d does not require gradients and so has no operation creating it (that is tracked by the autograd engine)>>> e = torch.rand(10).cuda().requires_grad_()>>> e.is_leafTrue# e requires gradients and has no operations creating it>>> f = torch.rand(10, requires_grad=True, device="cuda")>>> f.is_leafTrue# f requires grad, has no operation creating it
三、autograd的流程机制原理
例1:
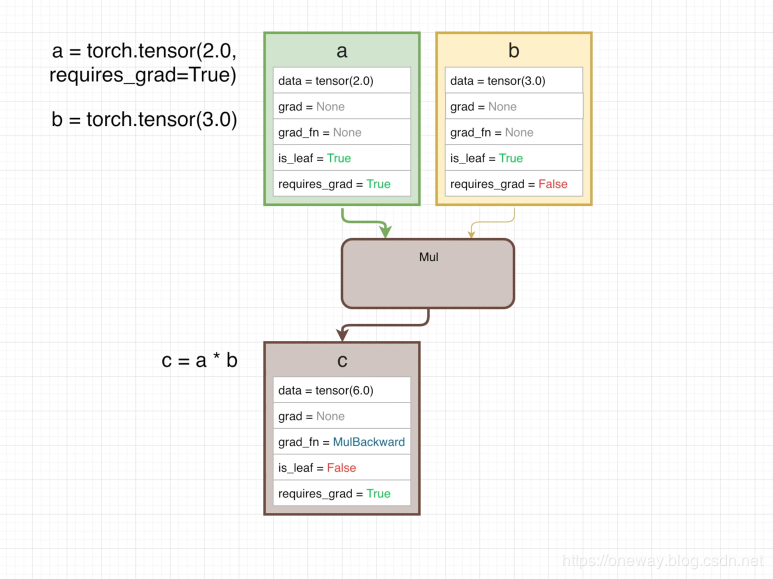
a = torch.tensor(2.0)b = torch.tensor(3.0)c = a*b
前项的计算图如下:
每个方框代表一个tensor,其中列出一些属性(还有其他很多属性):
- .data 存了tensor的data
- .grad 当计算gradient的时候将会存入此函数对应情况下的gradient
- .grad_fn 指向用于backward的函数的节点
- .is_leaf 判断是否是叶节点 (关于叶节点的信息)
- .requires_grad 如果是设为
True,那么在做backward时候将作为图的一部分参与backwards运算,如果为False则不参加backwards运算
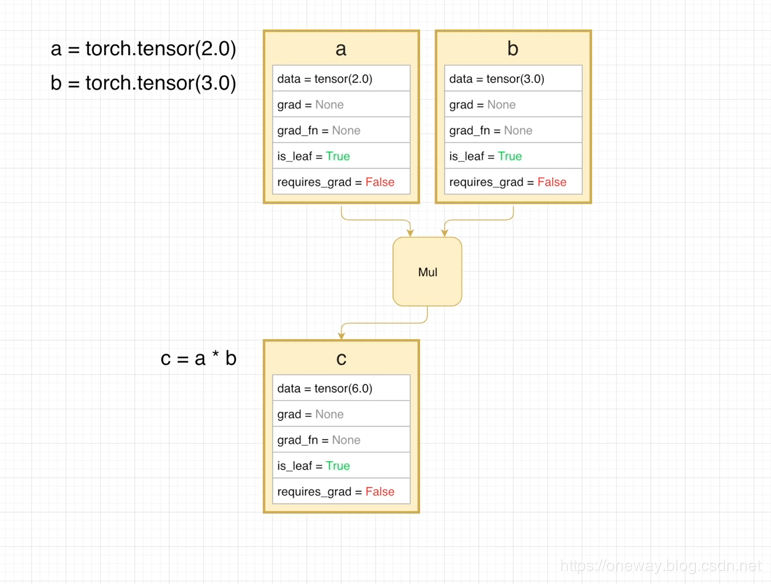
在图中可见, c= a*b的运算也算作计算图的一部分, 用Mul表示.由于a 和b 是require_grad,所以自动的被算为 is_leaf 为True, 此时由于requires_grad都为False,因此没有backwards的graph。
例2:
a = torch.tensor(2.0,requires_grad = True)b = torch.tensor(3.0)c = a*bc.backward()
重新进行计算,设tensor a的 requires_grad 为True,输出结果c因为输入自变量的属性为True而自动改变成 requires_grad 为True.这说明只要自变量中有一个requires_grad 为True, 进一步通过运算生成的变量也为True. 此时的c 为非叶节点, grad_fn 指向做backwards时与当前变量相关的backwards的函数(函数为pytorch自动生成的).
这是算数式的前馈流程图, 使我们可以通过函数代码观察到的.在此流程图的背后,其实pytorch还自动生成了对应的backwards的流程图:

当我们调用tensor的乘法函数时,同时调用了隐性变量 ctx (context)变量的save_for_backward(),这样就把此函数做backward时所需要的从forward函数中获取的相关的一些值存到了ctx中.ctx起到了缓存相关参数的作用,变成连接forward与backward之间的缓存站. ctx中的值将会在c 做backwards时传递给对应的Mulbackward 操作.
与此同时 由于c是通过 c=a*b运算得来的, c的grad_fn中存了做backwards时候对应的函数.且把这个对应的backward 叫做 “MulBackward”
当进行c的backwards的时候,其实也就相当于执行了 c = a*b这个函数分别对 a 与b 做的偏导. 那么理应对应两组backwards的函数,这两组backwards的函数打包存在 MulBackward的 next_functions 中. nex_function为一个 tuple list, AccumulateGrad 将会把相应得到的结果送到 a.grad中.
于是在进行 c.backward() 后, c进行关于a以及关于b的求导,由于b设requires_grad为False,因此b项不参与backwards运算(自然的,next_function中list的第二个tuple即为None),c关于a的梯度为3,因此3将传递给AccumulaGrad进一步传给a.grad 因此 a.grad 的结果为3
从这个backward graph中,可以看出,其实pytorch在定义这些变量的运算函数时,其实也定义了函数对应的backwards的函数.如果想使用自定义的函数,那么自己也必须要定义backwards函数.
例3:
a = torch.tensor(2.0,requires_grad = True)b = torch.tensor(3.0,requires_grad = True)c = a*bd = torch.tensor(4.0,requires_grad = True)e = c*de.backward()

- e的grad_fn 指向节点 MulBackward, c的grad_fn指向另一个节点 MulBackward
**
- c 为中间值is_leaf 为
False,因此并不包含 grad值,在backward计算中,并不需要再重新获取c.grad的值, backward的运算直接走相应的backward node 即可
- MulBackward 从 ctx.saved_tensor中调用有用信息, e= c+d中 e关于c的梯度通过MulBackward 获取得4. 根据链式规则, 4再和上一阶段的 c关于 a和c关于b的两个梯度值3和2相乘,最终得到了相应的值12 和8
- a.grad 中存入12, b.grad中存入 8

若有收获,就点个赞吧
0 人点赞
