SSM Chapter 05 Spring 核心概念 笔记
本章目标:
- 理解Spring IoC的原理
- 掌握Spring IoC的配置
- 理解Spring AOP的原理
- 掌握Spring AOP的配置
1 . 初识 Spring帝国

1.1 Spring的历史:
- Spring : 春天 —->给软件行业带来了春天
- 2002年,Rod Jahnson首次推出了Spring框架雏形interface21框架。
- 2004年3月24日,Spring框架以interface21框架为基础,经过重新设计,发布了1.0正式版。
- 很难想象Rod Johnson的学历 , 他是悉尼大学的博士,然而他的专业不是计算机,而是音乐学。
- Spring理念 : 使现有技术更加实用 . 本身就是一个大容器, 整合现有的框架技术
1.2 企业级应用开发
企业级应用是指那些为商业组织,大型企业而创建并部署的解决方案及应用.这些大型企业级应用的结构复杂,涉及的外部资源众多,事务密集,数据规模大,用户数量多,有较高的安全性考虑和较高的性能要求.
当代的企业级应用绝不可能是一个个的独立系统.在企业中,一般都会部署多个进行交互的应用,同时这些应用又都有可能与其他企业的相关应用连接,从而构建一个结构复杂的.跨越Internet的分布式企业应用集群.
此外,作为企业级应用,不但要有强大的功能,还要能够满足未来业务需求的变化,易于扩展和维护.
传统的Java EE 解决企业级应用问题的”重量级”架构体系,使它的开发效率,开发难度和实际性能都令人失望. 正在人们苦苦寻找解决办法的时候,Spring 以一个 “救世主” 的形象出现在广大的Java程序员面前.
Spring致力于JavaEE应用的各种解决方案,而不是仅仅专注于某一层的方案.可以说Spring是企业级应用开发的”一站式”的选择,Spring贯穿表现层,业务层,持久层.然而Spring 并不想取代那些已经有的框架,而是以高度的开放性与它们无缝结合.
Spring框架是由于软件开发的复杂性而创建的。Spring使用的是基本的JavaBean来完成以前只可能由EJB完成的事情。然而,Spring的用途不仅仅限于服务器端的开发。从简单性、可测试性和松耦合性角度而言,绝大部分Java应用都可以从Spring中受益!
Spring的一个最大的目的就是使JAVA EE开发更加容易。同时,Spring之所以与Struts、Hibernate等单层框架不同,是因为Spring致力于提供一个以统一的、高效的方式构造整个应用,并且可以将单层框架以最佳的组合揉和在一起建立一个连贯的体系。可以说Spring是一个提供了更完善开发环境的一个框架,可以为POJO(Plain Old Java Object)对象提供企业级的服务
Spring的官网 :https://spring.io/
SpringFramework官网 : https://spring.io/projects/spring-framework
1.3 Spring的产品:
Spring 是一个 轻量级框架, 它大大简化了Java企业级开发,提供了强大.稳定的功能,又没有带来额外的负担,是人们在使用它做每件事情的时候 都有得体和优雅的感觉. Spring 有两个目标: 一是 让现有的技术更易于使用,二是促进良好的编程习惯(或者称为最佳实践).
Spring 是一个全面的解决方案,但它坚持一个原则:不重新发明轮子.已经有较好解决方案的领域,Spring绝不做重复性的实现.例如:对象持久化和ORM,Spring 只是对现有的JDBC. MyBatis. Hibernate 等技术提供支持,使之易用,而不是重新做一个实现.
从配置到安全,从web应用程序到大数据——不管你的应用程序的基础结构需要什么,有一个Spring项目可以帮助你构建它。从小处开始,使用你所需要的–Spring是模块化的设计
> SpringBoot
Spring诞生时是Java企业版(Java Enterprise Edition, JEE,也称J2EE)的轻量级代替品。无需开发重量级的Enterprise JavaBean(EJB),Spring为企业级Java开发提供了一种相对简单的方法。
虽然Spring的组件代码是轻量级的,但它的配置却是重量级的。一开始,Spring用XML配置,而且是很多的XML配置,即使后来有基于注解的改善,我们依然难逃大量配置的魔爪。而Spring Boot让这一切成为了过去,如果说Spring的目的是简化程序的开发,那么Spring Boot就是为了简化Spring本身的开发。
Spring Boot依赖于自动配置技术将Spring应用中样板式的配置移除掉,这样就能让我们免受于一大堆的配置之苦,更加专注于业务功能。Spring Boot同时还提供了多个Starter项目,拿来即可用,极大地简化了编程任务。
它提供了四个主要的特性,能够改变开发Spring应用程序的方式:
- Spring Boot Starter: 它将常用的依赖分组进行了整合,将其合并到一个依赖中,这样就可以一次性添加到项目的Maven或Gradle构建中,这里可以找到目前所有的starter项目。
- 自动配置: Spring Boot的自动配置特性利用了Spring 4对条件化配置的支持,合理地推测应用所需的bean并自动化配置它们,减少了你自己需要配置的数量。
- 命令行接口(Command-line interface,CLI):Spring Boot的CLI发挥了Groovy编程语言的优势,并结合自动配置进一步简化Spring应用的开发。
- Actuator: 它为Spring Boot应用添加了一定的管理特性。
> Spring Framework
Spring帝国之核心 , 其他的Spring产品都是基于Spring框架而来的 .至今已集成了20多个模块,这些模块分布在以下模块中:
- 核心容器(Core Container)
- 数据访问/集成(Data Access/Integration)层
- Web层
- AOP(Aspect Oriented Programming)模块
- 植入(Instrumentation)模块
- 消息传输(Messaging)
- 测试(Test)模块
Spring的体系结构如图:
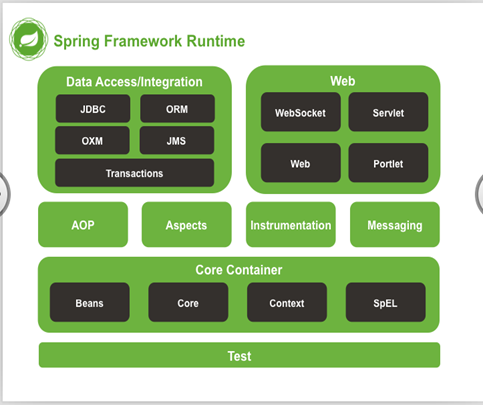
各个模块简单介绍:
核心容器(Core Container)
Spring的核心容器是其他模块建立的基础,有Spring-core、Spring-beans、Spring-context、Spring-context-support和Spring-expression(Spring表达式语言)等模块组成。
- Spring-core模块:提供了框架的基本组成部分,包括控制反转(Inversion of Control,IOC)和依赖注入(Dependency Injection,DI)功能。
- Spring-beans模块:提供了BeanFactory,是工厂模式的一个经典实现,Spring将管理对象称为Bean。BeanFactory使用控制反转(IoC)模式将应用的配置和依 赖规范与实际的应用程序代码分开。BeanFactory使用依赖注入的方式提供给组件依赖。
- Spring-context模块:建立在Core和Beans模块的基础之上,提供一个框架式的对象访问方式,是访问定义和配置的任何对象的媒介。ApplicationContext接口是Context模块的焦点。Spring上下文包括企业服务,如JNDI、EJB、电子 邮件、国际化、校验和调度功能。
- Spring-context-support模块:支持整合第三方库到Spring应用程序上下文,特别是用于高速缓存(EhCache、JCache)和任务调度(CommonJ、Quartz)的支持。
- Spring-expression模块:提供了强大的表达式语言去支持运行时查询和操作对象图。这是对JSP2.1规范中规定的统一表达式语言(Unified EL)的扩展。该语言支持设置和获取属性值、属性分配、方法调用、访问数组、集合和索引器的内容、逻辑和算术运算、变量命名以及从Spring的IOC容器中以名称检索对象。它还支持列表投影、选择以及常用的列表聚合。
数据访问/集成(Data Access/Integration)层
数据访问/集成层由JDBC、ORM、OXM、JMS和事务模块组成。
- Spring-jdbc模块:提供了一个JDBC的抽象层,消除了烦琐的JDBC编码和数据库厂商特有的错误代码解析
- Spring-orm模块:为流行的对象关系映射(Object-Relational Mapping)API提供集成层,包括JPA和Hibernate。使用Spring-orm模块可以将这些O/R映射框架与Spring提供的所有其他功能结合使用,例如声明式事务管理功能。
- Spring-oxm模块:提供了一个支持对象XML映射的抽象层实现,例如JAXB、Castor、JiBX和XStream
- Spring-jms模块(Java Messaging Service):指Java消息传递服务,包含用于生产和使用消息的功能。自Spring4.1以后,提供了与Spring-messaging模块的集成。
- Spring-tx模块(事务模块):支持用于实现特殊接口和所有POJO(普通Java对象)类的编程和声明式事务管理。
Web 层
Web层由Spring-web、Spring-webmvc、Spring-websocket和Portlet模块组成。
- Spring-web模块:提供了基本的Web开发集成功能,例如多文件上传功能、使用Servlet监听器初始化一个IOC容器以及Web应用上下文。
- Spring-webmvc模块:也称为Web-Servlet模块,包含用于web应用程序的Spring MVC和REST Web Services实现。Spring MVC框架提供了领域模型代码和Web表单之间的清晰分离,并与Spring Framework的所有其他功能集成。
- Spring-websocket模块:Spring4.0以后新增的模块,它提供了WebSocket和SocketJS的实现。
- Portlet模块:类似于Servlet模块的功能,提供了Portlet环境下的MVC实现。
AOP和Instrumentation
- Spring-aop模块:提供了一个符合AOP要求的面向切面的编程实现,允许定义方法拦截器和切入点,将代码按照功能进行分离,以便干净地解耦。
- Spring-aspects模块:提供了与AspectJ的集成功能,AspectJ是一个功能强大且成熟的AOP框架。
- Spring-instrument模块:提供了类植入(Instrumentation)支持和类加载器的实现,可以在特定的应用服务器中使用。
消息传输(Messaging)
Spring4.0以后新增了消息(Spring-messaging)模块,该模块提供了对消息传递体系结构和协议的支持。
测试
Spring-test模块支持使用JUnit或TestNG对Spring组件进行单元测试和集成测试
Spring三个核心容器(Core、Context、Beans)。如果再在他们三个中选一个核心来,那就非Beans莫属了,为何这样说?其实Spring就是面向Bean的变成(BOP,Bean Oriented Programming),Bean才是Spring中的真正主角。
Spring就是面向Bean的编程,在Spring中所有对象都可以看成一个Bean。
Bean在Spring 中作用就像Object对OOP的意义一样,没有对象的概念就没有面向对象编程,Spring中没有Bean也就没有Spring存在意义。就像一次演出舞台都准备好了但是却没有演员一样。为什么要Bean这种角色?或者说Bean在Spring中如此重要,这都是由Spring框架的设计目标决定的,Spring为何如此流行,我们使用Spring的原因是什么?思考下,你会发现原来Spring解决了一个非常关键的问题,他可以让你把对象之间的关系转而使用配置文件来管理,也就是他的依赖注入机制,而这个注入关系在一个叫Ioc的容器中管理。Spring正是通过把对象包装在Bean中从而达到对这些对象管理以及一系列额外操作的目的。
它的这种设计策略完全类似于Java实现OOP的设计理念,当然Java本身的设计要比Spring复杂太多太多,但是都是构建一个数据结构,然后根据这个数据结构设计他的生存环境,并让在这个环境后总按照一定得规律在不停的运动,在他们的不停运动中设计一系列与环境或者其他个体完成信息交换。这样想来,我们用到过的其他框架都是大概类似的设计理念
那这些核心组件如何协同工作?
前面说Bean是Spring中的关键因素,那Context和Core又有何作用?前面把Bean比作一场演出中的演员的话,那么Context就是这场演出的舞台背景,而Core就是应该是演出的道具了。只有他们在一起才能具备演出一场好戏的最基本条件。当然有最基本的条件还不能使这场演出脱颖而出,还要他表演的节目足够的精彩,这些节目就是Spring提供的特色功能了。
那它是怎么管理这些Bean的呢?
Spring把所有的Bean及它们之间的依赖关系以配置文件的方式组装起来,在一个叫IoC(Inversion of Control)的容器中进行管理,这也就是Spring的核心设计思想之一依赖注入机制,Spring的另一个核心设计思想叫做AOP,这两个概念在后续专题会有详细讲解,这里就不在赘述。
通过集成实现的接口就知道他具有Spring里面经典的工厂方法,还有对国际化支持的Message,以及配置信息的Resource,还有Spring支持的发布和监听事件功能。一个Context基本上把Spring具有的核心功能都包裹起来了,那么这就是Spring框架运行需要的环境,也就是常说的上下文。
任何一个框架运行都通过一个类来进行描述它执行时的环境,ServletContext也是一样,就是Servlet环境信息。可以将context理解为一个框架执行信息的载体,可以理解问一个框架的门面(门面模式),将框架内部的各个组件信息都通过一个context暴露给外部。
> Spring Cloud
在进入主题之前,首先来看看微服务,简单说来就是将原本单个独立的大系统拆分为分布式的多个小型的服务,这些小型服务各自独立运行,他们通过HTTP和RestFul API进行通信。
一个微服务一般完成某个特定的功能,比如下单管理、客户管理等等。每一个微服务都是微型六角形应用,都有自己的业务逻辑和适配器。一些微服务还会发布API给其它微服务和应用客户端使用。其它微服务完成一个Web UI,运行时,每一个实例可能是一个云VM或者是Docker容器。
微服务具有分布式系统的特性,如服务发现,负载均衡,故障转移,多版本,灰度升级,服务降级,分布式跟踪。
Spring Cloud是一套完整的分布式系统解决方案,它的子项目涵盖了所有实现分布式系统所需要的基础软件设施(包括配置管理、服务治理、智能路由、全局锁等等)。基于Spring Boot,Spring Boot做较少的配置,便可成为Spring Cloud中的一个微服务,使用Spring Cloud的开发者可以快速的启动服务或构建应用、同时能够快速和云平台资源进行对接,使得开发部署极其简单。
Spring Cloud专注于提供良好的开箱即用经验的典型用例和可扩展性机制覆盖:
- 分布式/版本化配置:Spring Cloud Config
- 服务注册和发现:Netflix Eureka 或者 Spring Cloud Eureka(对前者的二次封装)
- 路由:Spring Cloud Zuul 基于 Netflix Zuul
- service - to - service调用:Spring Cloud Feign
- 负载均衡:Spring Cloud Ribbon 基于 Netflix Ribbon 实现
- 断路器:Spring Cloud Hystrix
- 分布式消息传递:Spring Cloud Bus
> Spring Data
是为了简化构建基于 Spring 框架应用的数据访问技术,包括关系数据库、NoSQL、Map-Reduce 框架、云数据服务等等,旨在提供一种通用、统一的编码模式(但是并不是代码完全一样),使得在Spring中使用任何数据库都变得非常容易。
Spring Data作为Spring Source的其中一个父项目,旨在统一和简化对各类型持久化存储,而不拘泥于是关系型数据库还是NoSQL数据存储。
目前的Spring Data 包含如下的模块(或者说子项目):
- Spring Data Commons
- Spring Data JPA
- Spring Data KeyValue
- Spring Data LDAP
- Spring Data MongoDB
- Spring Data Gemfire
- Spring Data REST
- Spring Data Redis
- Spring Data for Apache Cassandra
- Spring Data for Apache Solr
- Spring Data Couchbase (community module)
- Spring Data Elasticsearch (community module)
- Spring Data Neo4j (community module)
无论是哪种持久化存储,数据访问对象(DAO,即Data Access Objects)通常都会提供对单一域对象的CRUD(创建、读取、更新、删除)操作、查询方法、排序和分页方法等。Spring Data则提供了基于这些层面的统一接口(CrudRepository,PagingAndSortingRepository)以及对持久化存储的实现。
你可能接触过某一种Spring模型对象——比如JdbcTemplate——来编写访问对象的实现。但是在基于Spring Data的数据访问对象,我们只需定义和编写一些查询方法的接口(基于不同的持续化存储, 定义有可能稍有不同),Spring Data会在运行时间生成正确的实现。
所有Spring Data的子项目都支持:
- 模板:处理资源分配和异常处理
- 对象、数据存储映射:如ORM
- 对数据访问对象的支持: 帮助我们编写一些模板式语句如分页排序
然而一些Spring Data子项目,如Spring Data Redis和Spring Data Riak都只是提供模板,这是由于其相应的数据存储都只支持非结构化的数据,而不适用于对象的映射和查询。
> Spring Security
安全对于许多应用都是一个非常关键的切面,因为安全性是超越应用程序功能的一个关注点,应用系统的绝大部分内容都不应该参与到与自己相关的安全性处理中。尽管我们可以直接在应用程序中编写安全性功能相关的代码,但更好的方式还是将安全性相关的关注点与应用程序本身的关注点进行分离,作为系统的一个切面。Spring Security就是通过AOP和Filter来为应用程序实现安全性的。
使用Servlet规范中的Filter保护Web请求并限制URL级别的访问。Spring Security还能够使用Spring AOP保护方法调用——借助于对象代理和使用通知,能够确保只有具备适当权限的用户才能访问安全保护的方法。
Spring Security非常灵活,能够基于各种数据存储来认证用户。它内置了多种常见的用户存储场景,如内存、关系型数据库以及LDAP。但我们也可以编写并插入自定义的用户存储实现。
当为浏览器渲染HTML内容时,你可能希望视图中能够反映安全限制和相关的信息。一个简单的样例就是渲染用户的基本信息( 比如显示“您已经以……身份登录”)。或者你想根据用户被授予了什么权限,有条件地渲染特定的视图元素。Spring Security本身提供了一个JSP标签库,而Thymeleaf通过特定的方言实现了与Spring Security的集成。借助于这些,可以很容易的实现对视图的保护。
1.4 Spring的优势:
- 方便解耦,简化开发. Spring就是一个大工厂,可以将所有对象创建和依赖的关系维护,交给Spring管理。
- AOP编程的支持. Spring提供面向切面编程,可以方便的实现对程序进行权限拦截、运行监控等功能。
- 声明式事务的支持. 只需要通过配置就可以完成对事务的管理,而无需手动编程。
- 方便程序的测试. Spring对Junit4支持,可以通过注解方便的测试Spring程序。
- 方便集成各种优秀框架. Spring不排斥各种优秀的开源框架,其内部提供了对各种优秀框架的直接支持(如:Struts、Hibernate、MyBatis等)。
- 降低JavaEE API的使用难度. Spring对JavaEE开发中非常难用的一些API(JDBC、JavaMail、远程调用等),都提供了封装,使这些API应用难度大大降低.
2 . Spring IoC
2.1 理解 “ 控制反转 “
控制反转(Inversion of Control IoC):也称为依赖注入(Dependency Injection,DI),是面向对象编程中的一种设计理念,用来降低程序代码之间的耦合度.
丑陋的代码
首先 考虑什么是依赖. 依赖:代码中一般通过局部变量.方法参数.返回值 等建立的对于其他对象的调用关系. 例如:在A类的方法中,实例化了B类的对象并调用其方法以完成特定的功能,我们就说A类依赖于B类.
几乎所有的应用都是由两个或更多的类 通过彼此合作来实现完整的功能.类和类之间的依赖关系增加了程序开发的复杂程度,我们在开发一个类的时候,还需要对正在使用该类的其他类的影响, 我们称之为丑陋的代码.
例如:常见的业务层调用数据访问层实现持久化操作。如示例 1 所示:
创建接口,完整路径为:cn.foo.dao.UserDao
package cn.foo.dao;/*** 用户DAO接口*/public interface UserDao {/*** 保存用户信息的方法* @param user* @return*/int save(User user);}
用户DAO实现类,实现对User类的持久化操作:
package cn.foo.dao.impl;
public class UserDaoImpl implements UserDao {
@Override
public int save(User user) {
System.out.println("保存用户信息到数据库...");
return 0;
}
}
用户业务实现类 实现对User功能的业务管理
package cn.foo.service;
public class UserServiceImpl implements UserService{
//实例化 所依赖 的UserDao对象
private UserDao userDao;
@Override
public void addNewUser(User user) {
userDao.save(user);
}
public void setUserDao(UserDao userDao){
this.userDao = userDao;
}
}
在上述代码中,UserServiceImpl 对 UserDaoimpl 存在依赖关系. 这样的代码很常见,当时存在一个严重的问题,即 UserServiceImpl 和 UserDaoImpl 高度耦合,如果因为需求变化需要替换UserDao的实现类,将导致UserServiceImpl 中的代码随之发生修改. 如此,程序将不具备优良的可扩展性和可维护性,甚至在开发中难以测试
我们可以利用简单工厂和工厂方法模式的思路来解决此类问题, 示例代码如下:
package cn.foo.factory;
/**
* 增加 DAO 工厂,负责用户DAO实例的创建工作
*/
public class UserDaoFactory {
//负责创建用户 DAO 实例的方法
public static UserDao getInstance(String type){
UserDao userDao = null;
switch (type){
case "dao":
userDao = new UserDaoImpl();
break;
//省略其他实现类
}
return userDao;
}
}
用户业务类,实现对User功能的业务管理:
package cn.foo.service.impl;
public class UserServiceImpl implements UserService{
//通过工厂获取所依赖的用户 DAO 对象
private UserDao userDao;
@Override
public void addNewUser(User user) {
userDao.save(user);
}
public void setUserDao(UserDao userDao){
this.userDao = userDao;
}
}
测试方法如下:
public class TestUserService {
public static void main(String[] args) {
UserServiceImpl userService = new UserServiceImpl();
UserDao userDao = UserDaoFactory.getInstance("dao");
userService.setUserDao(userDao);
userService.addNewUser(new User());
}
}
这里的用户DAO工厂类 UserDaoFactory 体现了 “ 控制反转 “ 的思想,UserServiceImpl不再依赖自身的代码去获得所依赖的具体的DAO对象, 而是把这一工作 转交给了 “ 第三方 “ ——-UserFactory , 从而避免了 和 具体 UserDao 实现类之间的耦合. 由此可见,在获取所依赖的对象这件事上,” 控制权 “ 发生了 “ 反转 “ ———从UserServiceImpl转移到了UserDaoFactory,这就是所谓的 “ 控制反转 “.
但是,当我们仔细研究工厂类采用简单工厂设计模式时,我们又发现了一个问题。
这个问题就是如果一个接口的实现类超过了10个甚至100个,那么代码就会变得非常的繁琐,且不利用维护。
如何解决因为实现类增加而导致简单工厂模式的代码大量重复的问题呢?
答案就是使用反射!
我们可以在获取实现类的方法中,将以前需要传递的类型参数换成类的完整路径的字符串,而方法内部使用反射获取该类的实例即可。这样对于简单工厂模式的类,优化的代码如下:
/**
* 增加 DAO 工厂,负责用户DAO实例的创建工作
*/
public class UserDaoFactory {
//负责创建用户 DAO 实例的方法
public static UserDao getBean(String beanName){
UserDao userDao = null;
try {
userDao = (UserDao) Class.forName(beanName).getDeclaredConstructor().newInstance();
} catch (Exception e) {
e.printStackTrace();
}
return userDao;
}
}
在测试的时候,就不能传入自定义的字符串了,而需要将实现类的完整路径的字符串当作方法参数传入。代码如下:
public class TestUserService {
public static void main(String[] args) {
UserServiceImpl userService = new UserServiceImpl();
UserDao userDao = UserDaoFactory.getBean("cn.foo.dao.impl.UserDaoImpl");;
userService.setUserDao(userDao);
userService.addNewUser(new User());
}
}
如此,工厂类的代码就会变得非常的简洁。
问题虽然得到了解决, 但是 大量的工厂类会被引入开发过程中, 明显增加了开发量 .
Spring帝国崛起
此时救世主Spring帝国崛起了,它不仅能够如秋风扫落叶般的替我们分担这些额外的工作,提供完整 IoC实现,而且还能够让我们从丑陋的代码中解放出来,得以专注于 业务类 和 DAO 类的设计.
当某个角色(比如一个java示例,调用者)需要另一个角色(另一个java示例,被调用者)的协助时,在传统的程序设计过程中,通常由调用者来创建被调用者的示例。但是在Spring里,创建被调用者的工作不再由调用者来完成。因此被称为控制反转;创建被调用者实例的工作通常由spring容器来完成,然后注入调用者,因此也称为依赖注入。这样给程序带来很大的灵活性,这样也实现了我们的接口和实现的分离。
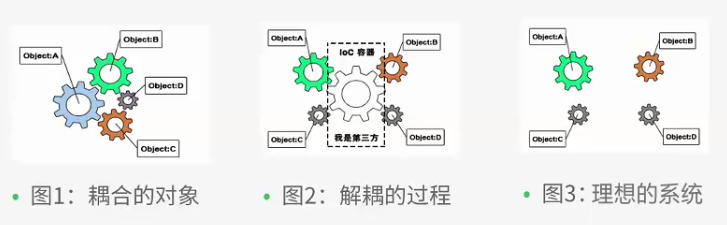
简而言之也就是说我们要获得一个对象,不由我们开发者自己创建,而是由我们的容器来注入给我们的程序来使用.
2.2 Hello Spring
问题 我们对 “ 控制反转 “ 有了了解,那么在我们的项目中 如何 使用 Spring 实现 “ 控制反转 “呢?开发第一个Spring项目,输出 “Hello Spring !!!”
具体要求如下:
- 编写 HelloSpring 类输出 “Hello, Spring ze! “.
- 其中字符串内容 “Spring” 通过Spring框架赋值到HelloSpring 类中.
实现思路以及关键代码
- (1) 下载 Spring 并添加到项目中 (或者使用maven导入依赖)
- (2) 编写 Spring 配置文件
- (3) 编写 代码通过 Spring 获取 HelloSpring 实例
1. 首先:
下载Spring 并添加到项目中(或者使用maven导入依赖)
通过 Spring官网下载地址:**https://repo.spring.io/release/org/springframework/spring/**下载 所需要的 Spring 资源,这里 以 Spring Framework 5.1.5 版本为例. 下载压缩包spring-framework-5.1.5.RELEASE-dist.zip 解压后的文件目录结构如下:
- docs : 该文件夹 下 包含 Spring 的相关文档,包括 API 参考文档,开发手册
- libs : 该文件夹下存放 Spring 各个模块的jar文件,每个模块提供三项内容,开发所需要的jar文件,以”-javadoc”后缀表示的API 和 以 “-sources” 后缀表示的源文件
- schema : 配置 Spring 的某些功能时 需要 用到的 schema文件
经验 : 作为开源框架, Spring 提供了 相关的源文件.在学习和开发过程中,可以通过阅读源文件,了解Spring 的底层实现.这不仅有利于 正确理解 和 运用Spring框架,也有助于开拓思路,提升自身的编程水平.
创建一个项目 HelloSpring , 将Spring所需要的jar文件添加到项目中,需要注意的是Spring的运行以来于 commons-logging 组件, 所以需要将相关的jar文件一并导入.
为了方便观察 Bean 实例化的过程, 我们采用log4j作为日志输出,所以也应该将log4j的jar文件添加到项目中.项目的jar文件如下:
spring-context-5.1.5.RELEASE.jar
spring-beans-5.1.5.RELEASE.jar
spring-core-5.1.5.RELEASE.jar
spring-jcl-5.1.5.RELEASE.jar
spring-expression-5.1.5.RELEASE.jar
log4j-1.2.17.jar
commons-logging-1.2.jar
若是maven工程,请使用 maven 导入jar包,pom.xml文件下 添加如下代码:
<!--普通java工程 导入spring的核心包 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.1.5.RELEASE</version>
</dependency>
<!--log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- 使用junit测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
为该项目添加log4j.properties文件,用来控制台输出日志,文件内容如下:
# rootLogger是所有日志的根日志,修改该日志属性将对所有日志起作用
# 下面的属性配置中,所有日志的输出级别是info,输出源是con
log4j.rootLogger=info,con
# 定义输出源的输出位置是控制台
log4j.appender.con=org.apache.log4j.ConsoleAppender
# 定义输出日志的布局采用的类
log4j.appender.con.layout=org.apache.log4j.PatternLayout
# 定义日志输出布局
log4j.appender.con.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%c%n -%m%n
也可以使用如下方式记录日志:
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.12.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.12.1</version>
</dependency>
编写log4j2.xml文件 , 内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout
pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<!--<logger name="org.springframework" level="debug"/>-->
<Root level="debug">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
可参考官网:https://logging.apache.org/log4j/2.x/articles.html
比较完整的log4j2.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<!--日志级别以及优先级排序: OFF > FATAL > ERROR > WARN > INFO > DEBUG > TRACE > ALL -->
<!--Configuration后面的status,这个用于设置log4j2自身内部的信息输出,可以不设置,当设置成trace时,你会看到log4j2内部各种详细输出-->
<!--monitorInterval:Log4j能够自动检测修改配置 文件和重新配置本身,设置间隔秒数-->
<configuration status="WARN" monitorInterval="30">
<!--先定义所有的appender-->
<appenders>
<!--这个输出控制台的配置-->
<console name="Console" target="SYSTEM_OUT">
<!--输出日志的格式-->
<PatternLayout pattern="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n"/>
</console>
<!--文件会打印出所有信息,这个log每次运行程序会自动清空,由append属性决定,这个也挺有用的,适合临时测试用-->
<File name="log" fileName="log/log.log" append="false">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</File>
<!-- 这个会打印出所有的info及以下级别的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档-->
<RollingFile name="RollingFileInfo" fileName="${sys:user.home}/logs/info.log" filePattern="${sys:user.home}/logs/$${date:yyyy-MM}/info-%d{yyyy-MM-dd}-%i.log">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)-->
<ThresholdFilter level="info" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy/>
<SizeBasedTriggeringPolicy size="100 MB"/>
</Policies>
</RollingFile>
<RollingFile name="RollingFileWarn" fileName="${sys:user.home}/logs/warn.log" filePattern="${sys:user.home}/logs/$${date:yyyy-MM}/warn-%d{yyyy-MM-dd}-%i.log">
<ThresholdFilter level="warn" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy/>
<SizeBasedTriggeringPolicy size="100 MB"/>
</Policies>
<!-- DefaultRolloverStrategy属性如不设置,则默认为最多同一文件夹下7个文件,这里设置了20 -->
<DefaultRolloverStrategy max="20"/>
</RollingFile>
<RollingFile name="RollingFileError" fileName="${sys:user.home}/logs/error.log"
filePattern="${sys:user.home}/logs/$${date:yyyy-MM}/error-%d{yyyy-MM-dd}-%i.log">
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="[%d{HH:mm:ss:SSS}] [%p] - %l - %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy/>
<SizeBasedTriggeringPolicy size="100 MB"/>
</Policies>
</RollingFile>
</appenders>
<!--然后定义logger,只有定义了logger并引入的appender,appender才会生效-->
<loggers>
<!--过滤掉spring和mybatis的一些无用的DEBUG信息-->
<logger name="org.springframework" level="INFO"></logger>
<logger name="org.mybatis" level="INFO"></logger>
<root level="all">
<appender-ref ref="Console"/>
<appender-ref ref="RollingFileInfo"/>
<appender-ref ref="RollingFileWarn"/>
<appender-ref ref="RollingFileError"/>
</root>
</loggers>
</configuration>
2. 编写:
HelloSpring类,以及编写Spring 配置文件
编写HelloSpring类代码如下:
/**
* 第一个Spring 输出 Hello Spring
*/
public class HelloSpring {
//private Logger log = LogManager.getLogger();//log4j2
private String who;
@Override
public String toString() {
return "HelloSpring{who='" + who + '\'' +
'}';
}
public String getWho() {
return who;
}
public void setWho(String who) {
this.who = who;
}
}
Spring配置文件以及各种命名空间如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd">
</beans>
XML Schema命名空间作用:
- 避免命名冲突,像Java中的package一样
- 将不同作用的标签分门别类(像Spring中的tx命名空间针对事务类的标签,context命名空间针对组件的标 签)
头文件解释:
- xmlns=”http://www.springframework.org/schema/beans“ 声明xml文件默认的命名空间,表示未使用其他命名空间的所有标签的默认命名空间。
- xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance“ 声明XML Schema 实例,声明后就可以使用 schemaLocation 属性了,标准组织发布的。
- xmlns:xxx=”http://www.springframework.org/schema/xxx“ 声明前缀为xxx(例如:context,aop,tx等)的命名空间,xxx是简写,地址是全命名空间
- xsi:schemaLocation=” http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd 这个地方,制定了某个命名空间的schema文件的具体位置,所以我们需要什么样的标签的时候,就引入什么样的命名空间和Schema 定义就可以了。
编写Spring配置文件,在项目的classpath 根路径下 创建 applicationContext.xml 文件(为了便于管理框架的配置文件,可下项目中创专门的Source Folder,如 resources 目录,并将Spring配置文件创建在其根路径下).在Spring 配置文件中创建HelloSpring类的实例 并为who属性 注入属性值. 配置文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--通过bean元素声明 需要 Spring 创建的实例. 该实例的类型 通过class 属性指定,
并通过id属性为该实例指定一个名称以便于访问-->
<bean id="helloSpring" class="org.springdemo.HelloSpring">
<!--property 元素用来为实例的属性赋值,此处实际是调用setWho()方法实现赋值操作
name为属性名,value为属性指定的值-->
<property name="who" value="hello,Spring" />
</bean>
</beans>
在Spring 配置文件中,使用**<bean>** 元素来定义Bean(也可称为组件)的实例.这个元素有两个常用属性,一个是id,表示Bean实例的名称,另一个是class,表示Bean实例的类型.
经验:
(1) 使用
**<bean>**元素定义一个组件时,通常需要使用id属性为其指定一个用来访问的唯一名称.如果想为bean指定更多的别名,可以通过name属性指定,名称之间需要使用逗号 分号 或者 空格进行分隔
(2) 在 本例中,Spring 为bean 的属性赋值 是通过属性的setter方法实现的,这种做法称为 “ 设值注入 “,
而非 直接为属性赋值.若属性名为who, 但是setter方法名为 setSomeBody(),
Spring配置文件中应写成name=”someBody” 而非 name=”who”
所以在为setter访问器 命名时, 一定要遵循 JavaBean 的命名规范
3. 测试:
测试类,以及测试方法,代码如下:
public class TestHelloSpring {
private Logger logger = Logger.getLogger(this.getClass());
//private Logger log = LogManager.getLogger();//log4j2
@Test
public void testHelloSpringInstance(){
//通过ClassPathXmlApplicationContext 实例化Spring的上下文
ApplicationContext applicationContext =
new ClassPathXmlApplicationContext("applicationContext.xml");
//通过applicationContext 的 getBean()方法,可以根据id 也可以根据类名 来获取bean实例
//HelloSpring helloSpring = (HelloSpring)applicationContext.getBean("helloSpring");
HelloSpring helloSpring = applicationContext.getBean(HelloSpring.class);
logger.info(helloSpring);
}
}
运行结果:
04-18 10:14:26[INFO]org.springdemo.TestHelloSpring
-HelloSpring{ who='hello,Spring'}
Process finished with exit code 0
在此示例中,ApplicationContext 是一个接口,负责读取Spring 配置文件,管理对象的加载,生成,维护Bean对象的与Bean对象之间的依赖关系,负责Bean的声明周期等, ClassPathXmlApplicationContext是ApplicationContext接口的实现类,用于从classpath路径中读取Spring的配置文件.
IOC接口:
- IOC思想基于IOC容器完成,IOC容器底层就是对象工厂
- Spring提供IOC容器实现的两种方式:(两个接口)
(1) BeanFactory:IOC容器的基本实现,是Spring内部的使用接口。
特点是在加载配置文件的时候不会创建对象,在获取(使用)对象的时候才会创建。
(2) ApplicationContext:BeanFactory的子接口,提供了更多更强大的功能。
特点是在加载配置文件的时候就会创建对象 - ApplicationContext接口的主要实现类如图:
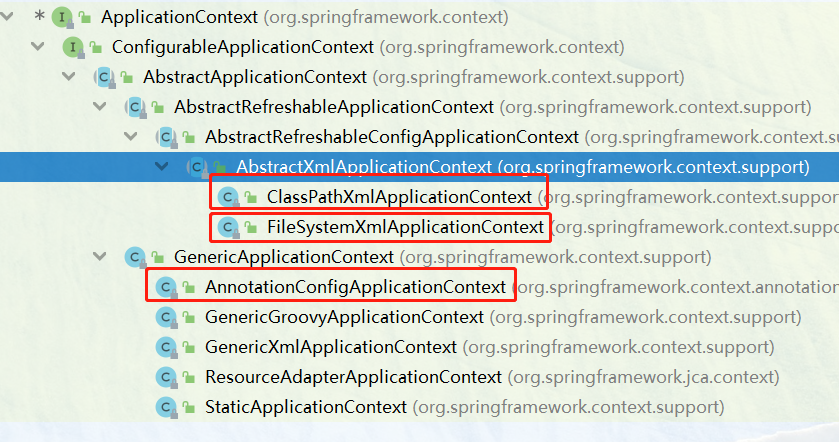
ClassPathXmlApplicationContext:为配置文件的类路径
FileSystemXmlApplicationContext:为配置文件的绝对路径
AnnotationConfigApplicationContext:Spring注解所在的类
知识扩展:
- (1) 除了ClassPathXmlApplicationContext,ApplicationContext接口还有其他实现类.例如:AnnotationConfigApplicationContext 也是其实现类,不过它可以用于扫描注解,有兴趣的可以查阅官网
- (2) 除了 ApplicationContext 及 其实现类, 还可以通过 BeanFactory 接口以及其实现类对 Bean 组件实施管理. 事实上,ApplicationContext 就是建立在BeanFactory的基础之上.BeanFactory 是 Spring IoC 容器的核心,负责管理组件和他们之间的依赖关系,应用程序 通过 BeanFactory 接口 与 Spring IoC 容器交互. ApplicationContext 是 BeanFactory 子接口,可以对企业开发提供全面的支持.有兴趣的学员 可以 自行查询资料,对BeanFactory 与 ApplicationContext的区别与联系 做更多的了解.
扩展使用注解完成上面的程序:
1.创建**AppConfig**类 , 加入对应的注解 , 详细代码如下:
/**
* 使用注解定义普通的类,完成Spring的配置
*/
@Configuration//相当于配置文件中的<beans>标签
public class AppConfig {
@Bean(name="helloSpring")//相当于配置文件中的bean标签
public HelloSpring getHelloSpring(){
HelloSpring helloSpring = new HelloSpring();
helloSpring.setWho("Hello");
return helloSpring;
}
}
2.修改测试类 , 加入以下测试代码:
@Test
public void testDemo(){
ApplicationContext applicationContext =
new AnnotationConfigApplicationContext(AppConfig.class);
HelloSpring helloSpring = applicationContext.getBean(HelloSpring.class);
System.out.println(helloSpring);
}
提示:
相对于 “ 控制反转 “ ,” 依赖注入 “ 的说法也许更容易理解一些,即 由容器(如 : Spring) 负责把 组件所 “依赖” 的具体对象 “注入”(赋值)给组件,从而避免 组件之间 以 硬编码 的方式 耦合在一起.
2.3 如何使用 “依赖注入”
问题:
如何 开发一个打印机?
- 可灵活配置 使用彩色墨盒或灰色 墨盒
- 可灵活配置 打印页面的大小
分析:
程序中包含 打印机(Printer) 墨盒(Ink) 和 纸张(Paper) 3类组件
打印机功能的实现依赖于墨盒和纸张
步骤如下:
1 . 定义墨盒(Ink) 和 纸张(Paper) 的接口标准
/**
* 墨盒接口
*/
public interface Ink {
/**
* 定义打印采用颜色的方法
* @param r 红色值
* @param g 绿色值
* @param b 蓝色值
* @return
*/
String getColor(int r,int g,int b);
}
Ink 接口 只定义一个getColor()方法 , 传入 红.绿.蓝 3种颜色的值,表示逻辑颜色;返回一个形如 #ffc800 的颜色字符串,表示打印采用的颜色
/**
* 纸张接口
*/
public interface Paper {
//定义纸张的换行符
String newline = "\r\n";
/**
* 输出一个字符 到 纸张
* @param c
*/
void putInChar(char c);
/**
* 得到输出 到 纸张上的内容
* @return
*/
String getContent();
}
Paper 接口 中定义了两个方法:putInChar() 用于 向纸张中 输出一个字符,向纸张输入字符后,纸张会根据自身大小(每页行数 和 每行字数的限制), 在输入流中 插入 换行符.分页符和页码:getContent() 用于得到纸张中所有的内容.
2 . 使用 Ink 接口 和 Paper 接口 开发 Printer 程序
/**
* 打印机程序
*/
public class Printer {
//面向接口编程 而不是具体的实现类
private Ink ink;//墨盒接口
private Paper paper;//纸张接口
//省略 设值所需要的setter方法
//.....
/**
* 打印机 打印方法
* @param str : 传入打印内容
*/
public void print(String str){
//输出颜色标记
System.out.println("使用"+ink.getColor(255,200,0)+"颜色打印:\n");
//逐字符输出到纸张
for (int i = 0; i < str.length(); i++) {
paper.putInChar(str.charAt(i));
}
//输出纸张的内容
System.out.print(paper.getContent());
}
}
Printer 类中 只有一个业务方法print(),输入的参数 是一个 即将被打印的字符串,打印机将这个字符串逐个字符输入到纸张,然后将纸张中的内容输出. 而print() 方法运行的时候,需要Ink 和 Paper的实例,提供setter方法,使用Spring的依赖注入特性 将其实现注入进来.至此,Printer类的开发工作就完成了.
3 . 开发 Ink 接口 和 Paper 接口 的实现类: ColorInk . GreyInk . TestPaper
/**
* 彩色墨盒
*/
public class ColorInk implements Ink {
@Override//打印采用彩色
public String getColor(int r, int g, int b) {
Color color = new Color(r,g,b);
return "#"+Integer.toHexString(color.getRGB()).substring(2);
}
}
/**
* 灰色墨盒
*/
public class GreyInk implements Ink {
@Override//打印采用灰色
public String getColor(int r, int g, int b) {
int c = (r+g+b)/3;
Color color = new Color(c,c,c);
return "#"+Integer.toHexString(color.getRGB()).substring(2);
}
}
彩色墨盒 的 getColor() 方法 只是把传入的颜色参数做了简单的格式转换,灰色墨盒只是先把传入的颜色值进行计算,转换成灰色,在进行格式转换.这不是需要关注的重点,了解即可.
/**
* 文本打印 纸张实现 TextPaper 实现 Paper 接口
*/
public class TextPaper implements Paper {
//每行字符数:
private int charPerLine = 16;
//每页行数
private int linePerPage = 5;
//纸张中的内容
private String content = "";
//当前横向位置 从 0 到 charPerLine - 1;
private int posX = 0;
//当前行数 从 0 到 linePerPage - 1;
private int posY = 0;
//当前页数
private int posP = 1;
@Override
public void putInChar(char c) {
content += c;
++posX;
//是否换行
if (posX == charPerLine) {
content += Paper.newline;
posX = 0;
++ posY;
}
//是否翻页
if (posY == linePerPage) {
content += "第" + posP + "页==";
content += Paper.newline + Paper.newline;
posY = 0;
++ posP;
}
}
@Override
public String getContent() {
String ret = this.content;
//补齐本页空行,并显示页码
if(!(posX == 0 && posY == 0)){
int count = linePerPage - posY;
for (int i = 0; i < count; i++) {
ret += Paper.newline;
}
ret += "第" + posP + "页";
}
return ret;
}
//提供setter, 用于注入所需要的值
public void setCharPerLine(int charPerLine) {
this.charPerLine = charPerLine;
}
public void setLinePerPage(int linePerPage) {
this.linePerPage = linePerPage;
}
}
在 TextPaper 实现类的代码中,我们不需要关心具体逻辑的实现,理解其功能即可.其中 content 用于保存当前纸张内容.charPerLine 和 linePerPage 用于限定 每行 可以打印多少个字符 和 每页可以打印多少行.
需要注意的是, setCharPerLine() 和 setLinePerPage() 两个 setter 方法, 是为了 组装时 “注入” 数据留下的 “插槽”. 我们不仅可以注入某个类的实例,还可以注入基本数据类型,字符串等类型的数据.
4 . 组装 打印机 , 运行调试
组装打印机 的 工作 在Spring 配置文件中完成.首先,创建几个待组装零件的实例. 在 applicationContext.xml中加入如下代码:
<!--定义彩色墨盒-->
<bean id="colorInk" class="org.springdemo.printer.ColorInk" />
<!--定义灰色墨盒-->
<bean id="greyInk" class="org.springdemo.printer.GreyInk" />
<!--定义 A4的纸张-->
<!--通过 setCharPerLine方法 为charPerLine属性注入每行字符数-->
<!--通过 setLinePerPage方法 为linePerPage属性注入每页行数-->
<bean id="a4Paper" class="org.springdemo.printer.TextPaper">
<property name="charPerLine" value="10" />
<property name="linePerPage" value="8" />
</bean>
<!--定义 B5的纸张-->
<bean id="b5Paper" class="org.springdemo.printer.TextPaper">
<property name="charPerLine" value="6" />
<property name="linePerPage" value="5" />
</bean>
各个”零件” 都定义好后,现在来完成打印机的组装,如下代码:
<!--组装打印机.定义打印机Bean -->
<bean id="printer" class="org.springdemo.printer.Printer">
<!--注入彩色墨盒,使用ref属性注入已经定义好的bean-->
<property name="ink" ref="colorInk"/>
<!--注入A4纸张-->
<property name="paper" ref="a4Paper" />
</bean>
上述示例 使用 代码组装了 一台彩色的,使用A4打印纸的打印机.
需要注意的是 : 这里没有使用
**<property>**的value属性,而是使用ref属性.value属性用来注入基本数据类型,以及字符串类型的值,而ref属性用来注入已经定义好的bean,如刚才定义好的 colorInk,greyInk,a4Papre,b5Paper,而Printer 的两个属性的参数要求传入的接口类型,所以任何实现类都可以注入.
从配置文件中,可以看出Spring 管理Bean的灵活性.Bean 与 Bean 之间的依赖关系放在配置文件里组织,而不是书写在代码里.通过配置文件的指定,Spring 能够精确的为每个Bean注入属性.
每个Bean 的 id 属性是该Bean 的唯一标识.程序通过 id 属性访问 Bean,Bean 与 Bean 之间的依赖关系 也通过id属性完成.
打印机已经组装好了,下面进入测试阶段.可以使用注解进行测试,先在项目pom.xml文件中加入spring test 依赖,代码如下:
<!--导入 Spring 测试包-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.1.5.RELEASE</version>
</dependency>
测试类中,增加如下代码,
/**
* 使用注解测试
*/
//RunWith的意思就是一个运行器
//SpringJUnit4ClassRunner是spring自己写的,扩展了junit的运行环境.在里面还兼备了创建工厂的逻辑
@RunWith(SpringJUnit4ClassRunner.class)
//告诉spring的测试环境,xml在哪个位置
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class TestPrinter {
@Autowired//为printer属性注入所依赖的对象,此类中可以该属性的setter方法
private Printer printer;
@Test
public void testPrinter(){
String content = "几位轻量级容器的作者曾骄傲地对我说:这些容器非常有"
+ "用,因为它们实现了“控制反转”。这样的说辞让我深感迷惑:控"
+ "制反转是框架所共有的特征,如果仅仅因为使用了控制反转就认为"
+ "这些轻量级容器与众不同,就好像在说“我的轿车是与众不同的," + "因为它有4个轮子。”";
printer.print(content);
}
}
运行测试方法,控制台正确输出结果.
总结:通过Spring 的强大的组装能力,我们再开发每个程序组件的时候,只要明确关联组件的接口定义,而不需要关系实现,这就是所谓的 “ 面向接口编程 “.
知识扩展:
**@RunWith**就是一个运行器**@RunWith(JUnit4.class)**就是指用**JUnit4**来运行**@RunWith(SpringJUnit4ClassRunner.class)**,让测试运行于Spring测试环境**@ContextConfiguration**Spring整合JUnit4测试时,使用注解引入多个配置文件- 单个文件:
**@ContextConfiguration(Locations="classpath:applicationContext.xml")** - 多个文件时:
**@ContextConfiguration(locations = { "classpath:spring1.xml", "classpath:spring2.xml" })** **@Autowired**注解,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。 通过 @Autowired的使用来消除 setter ,getter方法。当使用@Autowired注解的时候,其实默认就是@Autowired(required=true),表示注入的时候,该bean必须存在,否则就会注入失败(了解即可,后面的章节会讲解)`。**@Configuration**可以作用在任意类上,表示该类是一个配置类.可理解为用spring的时候xml里面的**<beans>**标签**@Bean**作用于方法上,其实就相当于xml配置文件中的**<bean>**,表示创建一个Bean,方法的返回值类型表示该Bean的类型,方法名表示该Bean的ID。
用注解类**@Configuration**表示其主要目的是作为Bean定义的来源。此外,**@Configuration**类允许通过调用**@Bean**同一类中的其他方法来定义Bean之间的依赖关系。最简单的**@Configuration**类如下:
@Configuration
public class AppConfig {
@Bean
public MyService myService() {
return new MyServiceImpl();
}
}
上一**AppConfig**类等效于以下Spring **<beans/>**XML:
<beans>
<bean id="myService" class="com.acme.services.MyServiceImpl"/>
</beans>
3 . Spring AOP
3.1 理解 “ 面向切面编程 “
面向切面编程(Aspect Orientend Programming AOP) 是软件编程思想发展到一定阶段的产物,是面向对象编程(Object Oriented Programming OOP) 的有益补充. AOP 一般适用于具有横切逻辑的场合,如何访问控制,事务管理,性能监测等
什么是横切逻辑呢? 我们先来看下面的程序代码。
在该段代码中,UserService 的addNewUser() 方法 根据 需求增加了日志和事务功能。
/**
* 用户业务类,实现对User功能的业务管理
*/
public class UserServiceImpl implements UserService {
private static final Logger log = Logger.getLogger(UserServiceImpl.class);
public boolean addNewUser(User user) {
log.info("添加用户 " + user.getUsername());//记录日志
SqlSession sqlSession = null;
boolean flag = false;
//异常处理
try {
sqlSession = MyBatisUtil.createSqlSession();
if (sqlSession.getMapper(UserMapper.class).add(user) > 0)
flag = true;
sqlSession.commit(); //事务控制
log.info("成功添加用户 "+user.getUserName);
} catch (Exception e) {
log.error("添加用户 " + user.getUsername() + "失败", e); //记录日志
sqlSession.rollback(); //事务控制
flag = false;
} finally {
MyBatisUtil.closeSqlSession(sqlSession);
}
return flag;
}
}
这是一个再典型不过的业务处理方法,日志、异常处理、事务控制等,都是一个健壮的业务系统所必需的。但是为了保证系统健壮可用,就需要在众多的业务方法中反复编写类似的代码,使得原来本就很复杂的业务处理代码变得更复杂。
业务功能的开发者还要关注这些 “额外”的代码是否处理正确,是否有遗漏的地方. 如果需要修改日志信息的格式 或者安全验证的规则,或者再增加新的辅助功能,都会导致业务代码频繁而大量的修改.
在业务系统中,总有一些散落.渗透到系统各处不得不处理的事情,这些穿插在既定业务中的操作 就是 “横切逻辑”.也称为切面.我们很容易想到可以这些重复性的代码抽取出来,放在专门的类和方中,这样就便于管理和维护了.
但即便如此,依然无法实现业务和逻辑的彻底耦合,因为业务代码中还要保留这些方法的调用代码,当需要增加或者减少横切逻辑的时候,还是要修改业务方法中的代码才能实现.我们希望无需编写 “ 显式 “ 的调用,在需要的时候,系统能够” 自动 “ 调用所需要的功能.这就是AOP 要解决的问题.
面向切面编程,简单的说就是在不改变 原程序的基础上,为代码增加新的功能,对代码进行增强处理. 它的设计思想来源于代理设计模式.
代理模式:为其他对象提供一种代理以控制对这个对象的访问。简单来说这就是给目标对象生成一个代理对象,并由代理对象控制对目标对象的引用。
下面以代码的方式简单演示一下,我们就以代购日本成人动作电影光盘为例写一个例子:
/**
* 创建一个电影的接口
*/
public interface Movie {
void buy();
}
/**
* 创建一个真实的 主角
*/
public class Me implements Movie{
@Override
public void buy() {
System.out.println("我想买岛国的成人动作电影光盘,但是我没法出国怎么办?");
}
}
/**
* 代理角色出场
*/
public class Proxy implements Movie {
private Me me;
@Override
public void buy() {
if (me == null) {
me = new Me();
}
me.buy();
// 代理增强处理的方法
proxys();
}
public void proxys() {
System.out.println("我去帮你买吧!");
}
}
也可以使用JDK动态代理实现此案例,编写代码如下:
/**
* JDKDynamicProxy
* jdkd动态代理
**/
public class JDKDynamicProxy implements InvocationHandler {
private Object target;
public JDKDynamicProxy(Object target){
this.target = target;
}
/**
* 获取被代理接口实例对象
* @param <T>
* @return
*/
public <T>T getProxy(){
return (T)Proxy.newProxyInstance(target.getClass().getClassLoader(),
target.getClass().getInterfaces(),this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// System.out.println("目标方法执行前");
Object result = method.invoke(target, args);
System.out.println("我帮你去买吧");
return result;
}
}
简单测试类如下:
public class Test {
public static void main(String[] args) {
Movie proxy = new Proxy();
proxy.buy();
}
}
使用JDK动态代理,测试代码如下:
public class Test {
public static void main(String[] args) {
Movie movie = new JDKDynamicProxy(new Me()).getProxy();
movie.buy();
}
}
通过代理模式可以为该对象 设置 一个代理对象,代理对象为buy() 通过一个代理方法,当通过代理对象的buy()方法调用原对象的buy()方法时,就可以在代理对象中添加新的功能,也就是所谓的增强处理.增强的功能既可以插到原对象的buy()方法前面,也可以插到后面.
在这种模式下,给编程人员的感觉是在原有代码乃至原业务流程都不修改的情况下,直接在业务流程中切入新代码,增加新功能.这就是所谓的面向切面编程.下面了解他的一些基本概念:
- 增强(Adivce)**:又翻译成通知,定义了切面是什么以及何时使用,描述了切面要完成的工作和何时需要执行这个工作。是织入到目标类连接点上的一段程序代码。增强包含了用于添加到目标连接点上的一段执行逻辑,又包含了用于定位连接点的方位信息。(所以spring提供的增强接口都是带方位名:BeforeAdvice、(表示方法调用前的位置)AfterReturninAdvice、(表示访问返回后的位置)ThrowAdvice等等,所以只有结合切点和增强两者一起才能确定特定的连接点并实施增强逻辑)**
- 切入点(Pointcut)**:Advice定义了切面要发生“故事”和时间,那么切入点就定义了“故事”发生的地点。例如某个类或者方法名,Spring中允许我们使用正则来指定。**
- 连接点(Joinpoint):切入点匹配的执行点称作连接点。如果说切入点是查询条件,那连接点就是被选中的具体的查询结果。程序执行的某个特定位置,程序能够应用增强代码的一个“时机”,比如方法调用或者特定异常抛出
- 切面(Aspect)**:切入点和增强组成切面。它包括了横切逻辑的定义,也包括了连接点的定义。Spring AOP就是负责实施切面的框架,它将切面所定义的横切逻辑织入到切面所指定的连接点中**
- 代理(Proxy):AOP框架创建的对象。一个类被AOP织入增强之后,就产生了一个结果类,它是融合了原类和增强逻辑的代理类。
- 目标对象(Target):增强逻辑的织入的目标类
- 织入(Weaving):将增强添加到目标类具体连接点上的过程。AOP有三种织入的方式:编译期织入、类装载期织入、动态代理织入(spring采用动态代理织入)
说明:
- 切面可以理解为 由增强处理和切入点组成,既包含了横切逻辑的定义,也包含了连接点的定义.
- 面向切面编程主要关心两个问题: 即在什么位置,执行什么功能
- Spring AOP 是负责实施切面的框架,即由Spring AOP 完成织入工作.
- Advice 直译为 “通知”,但是这种叫法并不确切,在此处翻译成 “增强处理” 便于大家理解.
3.2 使用Spring AOP 实现日志输出:
问题 : 日志输出的代码直接嵌入在业务流程的代码中,不利于系统的扩展和维护. 如何使用Spring AOP 来实现日志输出,以解决这个问题?
实现思路 以及 关键代码如下:
(1) 在项目中 添加 Spring AOP 相关的jar文件 (或者使用maven 加入Spring AOP 相关的依赖)
(2) 编写前置增强 和 后置增强 实现日志功能
(3) 编写 Spring 配置文件,对业务方法进行增强处理
(4) 编写测试代码, 获取带有增强处理的业务对象.
最终运行结果如下:
04-12 21:47:35[INFO]aop.UserServiceLogger
-调用 : service.impl.UserServiceImpl@5f16132a的 addNewUser 方法之前, 方法入参:[Ljava.lang.Object;@1356d4d4
保存用户信息到数据库!!!
04-12 21:47:35[INFO]aop.UserServiceLogger
-调用 : service.impl.UserServiceImpl@5f16132a的 addNewUser 方法结束,方法返回值:null
1. 项目中添加所需的jar 文件
spring-aop.jar提供了Spring AOP实现,而Spring 5.0 之前使用 spring-aop jar文件时 需要依赖 aopalliance 和 aspectj项目组件,相关版本的下载链接分别可以在**https://soucesforge.net/projects/aopalliance/1.0/** 和 **http://mvnrepository.com/artifact/org.aspectj/aspectjweaver** 地址中找到.
Spring 5.0 之后 只需 引入一个aspectj 项目组件就可以,使用maven导入依赖,代码如下:
<!--加入Spring aop 相关依赖-->
<!--加入Spring aop依赖的aspectj-->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.9.2</version>
</dependency>
或者使用以下依赖:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>5.1.5.RELEASE</version>
</dependency>
接下来,分别编写以下代码.实体层:User,DAO层 UserDao(接口) 以及 UserDaoImpl(实现), 业务层 UserService(接口) 以及 UserServiceImpl(实现).代码如下:
/**
* 实体类:User
*/
public class User {
private Integer id;
private String username;
private String password;
//省略getter setter toString()
}
DAO层: UserDao
/**
* 用户DAO层
*/
public interface UserDao {
/**
* 保存用户信息
* @param user
* @return
*/
int save(User user);
}
DAO层:UserDaoImpl 实现 UserDao
/**
* UserDao 实现
*/
public class UserDaoImpl implements UserDao {
@Override
public int save(User user) {
//此处仅为说明问题,不实现完整的数据库操作
System.out.println("保存用户信息到数据库!!!");
return 1;
}
}
Service层: UserService(接口)
/**
* 用户业务类,实现对User 功能的业务管理
*/
public interface UserService {
/**
* 保存用户信息
* @param user
*/
void addNewUser(User user);
}
Service层: UserServiceImpl(实现UserService)
/**
* 用户业务实现
*/
public class UserServiceImpl implements UserService {
// 声明 接口类型的引用 和 具体实现类解耦合
private UserDao dao;
//dao属性的setterr访问器
public void setDao(UserDao dao) {
this.dao = dao;
}
@Override
public void addNewUser(User user) {
//调用dao的方法保存用户信息
dao.save(user);
}
}
2. 编写前置增强 和 后置增强 实现日志功能
代码如下:
/**
* 定义增强方法的 JavaBean
*/
public class UserServiceLogger {
private final Logger logger = Logger.getLogger(this.getClass());
//代表前置增强的方法
public void before(JoinPoint joinPoint){
logger.info("调用 : "+joinPoint.getTarget() +"的 "+joinPoint.getSignature().getName()
+" 方法之前, 方法入参:" + joinPoint.getArgs());
}
//代表后置增强的方法
public void afterReturning(JoinPoint joinPoint,Object result){
logger.info("调用 : "+joinPoint.getTarget()+"的 "+joinPoint.getSignature().getName()
+" 方法结束,方法返回值:" + result);
}
}
UserServiceLogger 类中 定义了 before() 和 afterReturning() 两个方法. 我们希望把before() 方法作为前置增强使用,即将该方法添加到目标方法之前执行; afterReturning() 方法作为后置增强使用,即将该方法添加到目标方法正常返回之后执行.
这里先以前置增强 和 后置增强为例,其他增强类型 会在后续章节中介绍.
为了能够在增强方法中获得当前连接点的信息,以便实施相关的判断和处理,可以在增强方法中声明一个JoinPoint类型的参数,Spring 会自动注入该实例.
通过该实例的 getTarget() 方法可以得到被代理的目标对象,getSignature() 方法 返回被代理目标的方法, getArgs() 方法 返回 传递给目标方法的参数数组. 对于实现后置增强的 afterReturning() 方法,还以定义个参数用于接收目标方法的返回值.
3. 编写 Spring 配置文件,对业务方法进行增强处理
在Spring 配置文件中对相关组件进行声明,并进行AOP配置,定义切入点,以及指定增强方法的bean,配置文件代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd ">
<bean id="dao" class="dao.impl.UserDaoImpl" />
<bean id="service" class="service.impl.UserServiceImpl">
<property name="dao" ref="dao"/>
</bean>
<!--定义包含增强方法的JavaBean-->
<bean id="theLogger" class="aop.UserServiceLogger"/>
<aop:config>
<!--定义切入点 并命名为pointcut-->
<aop:pointcut id="pointcut"
expression="execution(public void addNewUser(entity.User))"/>
<!--引用包含增强方法的bean-->
<aop:aspect ref="theLogger">
<!--将before()方法 定义为前置增强 并引用 pointcut切入点-->
<aop:before method="before" pointcut-ref="pointcut"/>
<!--将afterReturning()方法 定义为后置增强 并引用 pointcut切入点-->
<!--通过returning 属性指定名为 result 的参数注入返回值-->
<aop:after-returning method="afterReturning" returning="result" pointcut-ref="pointcut"/>
</aop:aspect>
</aop:config>
</beans>
注意 : 在**<beans>** 元素中需要 添加 aop 的名称空间,以导入与AOP相关的标签
与AOP相关的配置都放在**<aop:config>** 标签中,如配置切入点的标签**<aop:pointcut>** . **<aop:pointcut>**的expression属性可以配置切入点表达式. 示例中的值如下:
expression="execution(public void addNewUser(entity.User))"
execution 是 切入点指示符,它的括号是一个切入点表达式,可以配置需要切入增强处理的方法的特征,切入点表达式支持模糊匹配.下面介绍几种常用的模糊匹配:
- public addNewUser(entity.User) : “ “ 表示匹配所有类型的返回值
- public void (entity.User) : “ “ 表示匹配所有方法名
- com.service..(..) : 这个表达式匹配 com.service 包下所有类的所有方法**
- com.service...(..) : 这个表达式匹配 com.service 包及其子包下所有类的所有方法**
开发者可以根据自己的需求来设置切入点的匹配规则.当然,匹配规则和关键字还有很多,具体可以参考Spring的开发手册进行学习.
最后,还需要在切入点处插入增强处理,这个过程的专业叫法是 “ 织入 “.
在
**<aop:config>**中使用**<aop:aspect>**引用包含增强方法Bean . 然后分别通过**<aop:before>**和**<aop:after-returning>**将方法声明为前置增强和后置增强.在
**<aop:after-returning>**中可以通过returning属性指定需要注入返回值的属性名. 方法的JoinPoint类型参数无须特殊梳理,Spring会自动为其注入连接点的实例.
很明显,UserService 的 addNewUser()方法 可以和切入点 pointcut 相匹配,Spring会生成代理对象,在它执行前后分别调用before() 和 afterReturning()方法,这样就完成了日志的输出.
4. 编写测试代码, 获取带有增强处理的业务对象
测试代码如下:
@Test
public void testAddNewUser(){
ApplicationContext applicationContext =
new ClassPathXmlApplicationContext("applicationContext.xml");
UserService userService = applicationContext.getBean(UserService.class);
User user = new User();
user.setId(1);
user.setUsername("tom");
user.setPassword("abc");
userService.addNewUser(user);
}
运行测试方法,控制台正常输出结果.
从以上示例中可以看出,业务代码和日志代码完全分离,经过AOP的配置以后,不做任何代码的修改就在addNewUser()方法前后实现了日志的输出.
其实 只需要稍稍修改切入点的指示符,不仅可以为UserService 的addNewUser()方法增强日志功能, 还可以为所有业务方法进行增强处理,增强日志功能,同时访问控制,事务管理,性能监测等这些实用功能都没有问题.
总结:
Spring AOP应用场景:
- 系统日志处理
- 系统事务管理
- 系统安全验证
- 系统数据缓存
- ……

若有收获,就点个赞吧
0 人点赞
