一、swoole解决的问题
1、 swoole是什么?
Swoole 是 PHP 的协程高性能网络通信引擎,使用 C/C++ 语言编写,提供了多种通信协议的网络服务器和客户端模块,使 PHP 开发人员可以编写高性能的异步并发 TCP、UDP、Unix Socket、HTTP,WebSocket 服务。Swoole 可以广泛应用于互联网、移动通信、企业软件、云计算、网络游戏、物联网(IOT)、车联网、智能家居等领域。使用 PHP + Swoole 作为网络通信框架,可以使企业 IT 研发团队的效率大大提升。
2、安装swoole
- 环境依赖
- 编译安装
- php.ini选项
-
3、衍生开源项目、用户与案例
-
4、swoole学习路线
- 计算机网络
- linux高性能服务器编程
- 其他需要掌握的基础知识
二、swoole解决的问题
1、php-fpm 是如何处理web请求的?有什么问题?
我们用的 PHP 主要用于 web 开发,通过 nginx、apache 等服务端程序调用 php-fpm 处理服务端的业务逻辑,处理完后 php 撤消内存并返回结果。一个 web 请求就要加载一次 php 的全部文件,需要的系统资源开销很大,这是目前 php-fpm 的缺点之一;并且因为 php-fpm 在一次请求结束就释放内存,无法做连接池,也不合适 service 端的开发。
下面是 php-fpm 的运行流程,各位可以参考一下:
http://www.test.cc|Nginx|路由到 http://www.test.cc/index.php|加载nginx的fast-cgi模块|fast-cgi监听127.0.0.1:9000地址|www.test.com/index.php请求到达127.0.0.1:9000|php-fpm 监听127.0.0.1:9000|php-fpm 接收到请求,启用worker进程处理请求|php-fpm 处理完请求并撤消内存,返回给nginx|nginx 将结果通过http返回给浏览器
总结一下我理解 php-fpm 的优缺点:
优点:
- 部署简单
- 调试方便
- 基于传统 php 的项目非常多,易于参考
缺点:
- 每次 http 请求都要加载全部的项目文件
- php-fpm 性能不佳,并发性能不好
- 核心不支持异步IO处理,IO密集型请求响应变长
- 对网络通信协议的支持不好,应用场景基本被限制在web领域
2、swoole是如何解决php-fpm遇到的问题的?
swoole如何避免文件的反复加载:
swoole是完全的长驻内存的,长驻内存一个最大的好处就是可以性能加速。在fpm模式下,我们处理一个请求,通常会有一些空消耗,比如框架共用文件加载,配置文件加载,那么在swoole中,可以在onworkerstart的时候提前一次性把一些必要的文件和配置加载好,不必每次receive重复加载一遍,这样能提升不小的性能。
swoole如何实现高并发:
请求到达 Main Reactor|Main Reactor 根据 Reactor 的情况,将请求注册给对应的 Reactor(每个 Reactor 都有 epoll,用来监听客户端的变化)|客户端有变化时,交给 worker 来处理|worker 处理完毕,通过进程间通信(比如管道、共享内存、消息队列)发给对应的 reactor|reactor 将响应结果发给相应的连接|请求处理完成
因为reactor基于epoll,所以每个reactor可以处理很多个连接请求。 如此,swoole就轻松的处理了高并发。
swoole如何实现异步I/O
swoole的worker进程有2种类型:一种是普通的worker进程,一种是task worker进程。
worker进程是用来处理普通的耗时不是太长的请求;task worker进程用来处理耗时较长的请求,比如数据库的I/O操作。
我们以异步Mysql举例:
耗时较长的Mysql查询进入worker|worker通过管道将这个请求交给taskworker来处理|worker再去处理其他请求|task worker处理完毕后,处理结果通过管道返回给worker|worker 将结果返回给reactor|reactor将结果返回给请求方
如此,通过worker、task worker结合的方式,我们就实现了异步I/O。
swoole对网络通信协议的支持情况:
swoole 提供了多种通信协议的网络服务器和客户端模块,使 PHP 开发人员可以编写高性能的异步并发 TCP、UDP、Unix Socket、HTTP,WebSocket 服务。Swoole 可以广泛应用于互联网、移动通信、企业软件、云计算、网络游戏、物联网(IOT)、车联网、智能家居等领域。
总结一下 swoole 的技术特点:
- 常驻内存,避免重复加载带来的性能损耗,提升海量性能;
- 基于epoll,轻松支持高并发;
- 协程异步I/O,提高对I/O密集型场景并发处理能力;
支持多种通信协议,方便地开发 Http、WebSocket、TCP、UDP 等应用。
3、swoole与php-fpm对比有哪些优缺点?
swoole 相对于 php-fpm 优点:
常驻内存的 cli 运行模式,不用每次请求加载一次项目代码
- 大大提高了对连接请求的并发能力
- 协程异步I/O,提高对I/O密集型场景并发处理能力
- 支持多种通信协议,能搭建 TCP/UDP/UnixSocket 服务器
-
swoole 相对于 php-fpm 缺点:
相关文档较少
- 不支持 xdebug,不支持手动 dump,不熟悉相关工具的话,不太方便调试
入门难度高,多数 phper 不了解 TCP/IP 网络协议、多进程 / 多线程、异步 io 等
三、swoole核心概念
服务器(Server)
-
四、swoole进程结构
1、进程的基本知识
什么是进程,所谓进程其实就是操作系统中一个正在运行的程序,我们在一个终端当中,通过php,运行一个php文件,这个时候就相当于我们创建了一个进程,这个进程会在系统中驻存,申请属于它自己的内存空间系统资源并且运行相应的程序
对于一个进程来说,它的核心内容分为两个部分,一个是它的内存,这个内存是这进程创建之初从系统分配的,它所有创建的变量都会存储在这一片内存环境当中
一个是它的上下文环境我们知道进程是运行在操作系统的,那么对于程序来说,它的运行依赖操作系统分配给它的资源,操作系统的一些状态。
在操作系统中可以运行多个进程的,对于一个进程来说,它可以创建自己的子进程,那么当我们在一个进程中创建出若干个子进程的时候那么可以看到如图,子进程和父进程一样,拥有自己的内存空间和上下文环境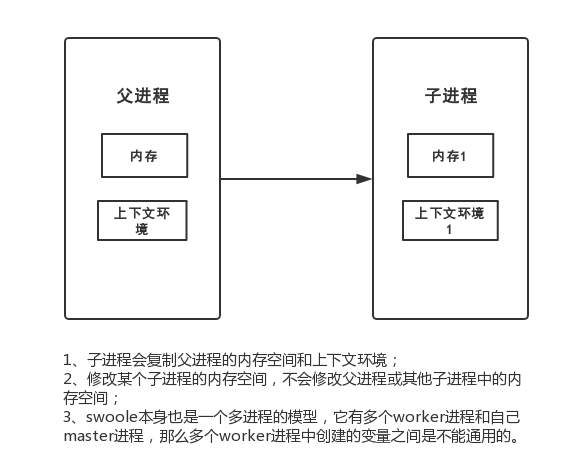
2、Swoole进程结构
Swoole的高效不仅仅于底层使用c编写,他的进程结构模型也使其可以高效的处理业务,我们想要深入学习,并且在实际的场景当中使用必须了解,下面我们先看一下结构图:

首先先介绍下swoole的这几种进程分别是干什么的:
从这些层级的名字,我们先大概说一下,下面这些层级分别是干什么的,做一个详细的说明。1)Master进程:主进程
第一层,Master进程,这个是swoole的主进程,这个进程是用于处理swoole的核心事件驱动的,那么在这个进程当中可以看到它拥有一个MainReactor[线程]以及若干个Reactor[线程],swoole所有对于事件的监听都会在这些线程中实现,比如来自客户端的连接,信号处理等。
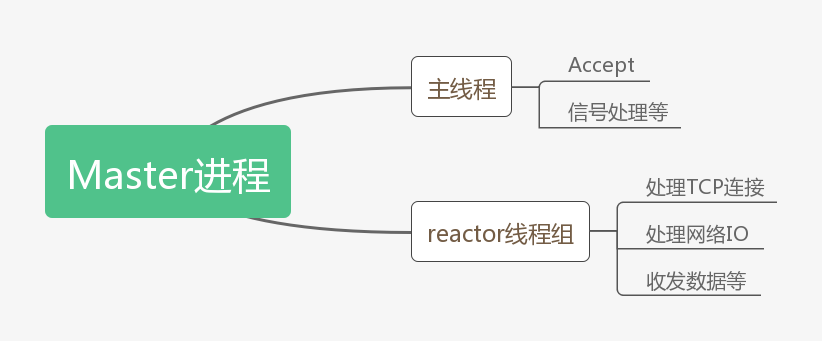
每一个线程都有自己的用途,下面多每个线程有一个了解 MainReactor(主线程)
主线程会负责监听server socket,如果有新的连接accept,主线程会评估每个Reactor线程的连接数量。将此连接分配给连接数最少的reactor线程,做一个负载均衡。
Reactor线程组
Reactor线程负责维护客户端机器的TCP连接、处理网络IO、收发数据完全是异步非阻塞的模式。 swoole的主线程在Accept新的连接后,会将这个连接分配给一个固定的Reactor线程,在socket可读时读取数据,并进行协议解析,将请求投递到Worker进程。在socket可写时将数据发送给TCP客户端。
心跳包检测线程(HeartbeatCheck)
Swoole配置了心跳检测之后,心跳包线程会在固定时间内对所有之前在线的连接 发送检测数据包
UDP收包线程(UdpRecv)
接收并且处理客户端udp数据包
2)Manger进程:管理进程
Swoole想要实现最好的性能必须创建出多个工作进程帮助处理任务,但Worker进程就必须fork操作,但是fork操作是不安全的,如果没有管理会出现很多的僵尸进程,进而影响服务器性能,同时worker进程被误杀或者由于程序的原因会异常退出,为了保证服务的稳定性,需要重新创建worker进程。
Swoole在运行中会创建一个单独的管理进程,所有的worker进程和task进程都是从管理进程Fork出来的。管理进程会监视所有子进程的退出事件,当worker进程发生致命错误或者运行生命周期结束时,管理进程会回收此进程,并创建新的进程。换句话也就是说,对于worker、task进程的创建、回收等操作全权有“保姆”Manager进程进行管理。
再来一张图梳理下Manager进程和Worker/Task进程的关系。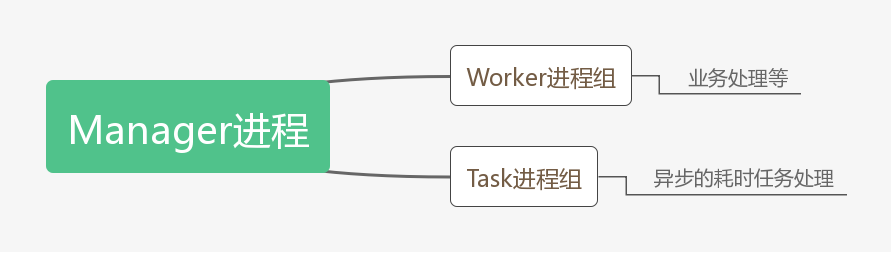
3)Worker进程:工作进程
worker 进程属于swoole的主逻辑进程,用户处理客户端的一系列请求,接受由Reactor线程投递的请求数据包,并执行PHP回调函数处理数据生成响应数据并发给Reactor线程,由Reactor线程发送给TCP客户端可以是异步非阻塞模式,也可以是同步阻塞模式。
4)Task进程:异步任务工作进程
taskWorker进程这一进城是swoole提供的异步工作进程,这些进程主要用于处理一些耗时较长的同步任务,在worker进程当中投递过来。
3、进程查看及流程梳理
当启动一个Swoole应用时,一共会创建2 + n + m个进程,2为一个Master进程和一个Manager进程,其中n为Worker进程数。m为TaskWorker进程数。
默认如果不设置,swoole底层会根据当前机器有多少CPU核数,启动对应数量的Reactor线程和Worker进程。我机器为1核的。Worker为1。
所以现在默认我启动了1个Master进程,1个Manager进程,和1个worker进程,TaskWorker没有设置也就是为0,当前server会产生3个进程。
在启动了server之后,在命令行执行ps -ajft|grep server.php查看当前产生的进程
这三个进程中,所有进程的根进程,也就是例子中的21915进程,就是所谓的Master进程;而21917进程,则是Manager进程;最后的21919进程,是Worker进程。
4、swoole事件处理流程
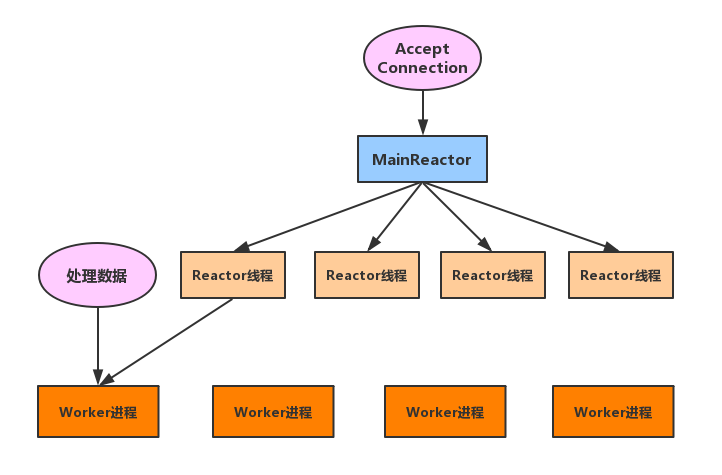
swoole使用的是reactor事件处理模式,一个请求经历的步骤如下:
- 服务器主线程等待客户端连接。
- Reactor线程处理接连socket,读取socket上的请求数据(Receive),将请求封装好后投递给work进程。
- Work进程就是逻辑单元,处理业务数据。
- Work进程结果返回给Reactor线程。
-
五、协程工作原理
协程(Coroutine)在执行过程中可中断去执行其他任务,执行完毕后再回来继续原先的操作。可以理解为两个或多个程序协同工作。
协程特点在于单线程执行。
优势一:具有极高的执行效率,因为在任务切换的时候是程序之间的切换(由程序自身控制)而不是线程间的切换,所以没有线程切换导致的额外开销(时间浪费),线程越多,协程性能优势越明显。
优势二:由于是单线程工作,没有多线程需要考虑的同时写变量冲突,所以不需要多线程的锁机制,故执行效率比多线程更高。
常利用多进程(利用多核)+协程来获取更高的性能。迭代生成器
讲工作原理前先了解下迭代生成器,迭代生成器也是一个函数,不同的是这个函数的返回值是依次返回,而不是只返回一个单独的值。或者,换句话说,生成器使你能更方便的实现了迭代器接口。下面通过实现一个xrange函数来简单说明:
<?phpfunction xrange($start, $end, $step = 1) {for ($i = $start; $i <= $end; $i += $step) {yield $i;}}foreach (xrange(1, 1000000) as $num) {echo $num, "\n";}
上面这个xrange()函数提供了和PHP的内建函数range()一样的功能.但是不同的是range()函数返回的是一个包含值从1到100万的数组(注:请查看手册)。而xrange()函数返回的是依次输出这些值的一个迭代器,而不会真正以数组形式返回。
这种方法的优点是显而易见的,它可以让你在处理大数据集合的时候不用一次性的加载到内存中。甚至你可以处理无限大的数据流。
当然,也可以不同通过生成器来实现这个功能,而是可以通过继承Iterator接口实现。但通过使用生成器实现起来会更方便,不用再去实现iterator接口中的5个方法了。
生成器为可中断的函数
要从生成器认识协程, 理解它内部是如何工作是非常重要的: 生成器是一种可中断的函数, 在它里面的yield构成了中断点.
还是看上面的例子, 调用xrange(1,1000000)的时候, xrange()函数里代码其实并没有真正地运行. 它只是返回了一个迭代器:
<?php$range = xrange(1, 1000000);var_dump($range); // object(Generator)#1var_dump($range instanceof Iterator); // bool(true)?>
这也解释了为什么xrange叫做迭代生成器,因为它返回一个迭代器,而这个迭代器实现了Iterator接口。
调用迭代器的方法一次,其中的代码运行一次。例如,如果你调用$range->rewind(),那么xrange()里的代码就会运行到控制流第一次出现yield的地方。而函数内传递给yield语句的返回值可以通过$range->current()获取。
为了继续执行生成器中yield后的代码,你就需要调用$range->next()方法。这将再次启动生成器,直到下一次yield语句出现。因此,连续调用next()和current()方法,你就能从生成器里获得所有的值,直到再没有yield语句出现。
对xrange()来说,这种情形出现在$i超过$end时。在这中情况下,控制流将到达函数的终点,因此将不执行任何代码。一旦这种情况发生,vaild()方法将返回假,这时迭代结束。
协程
协程的支持是在迭代生成器的基础上,增加了可以回送数据给生成器的功能(调用者发送数据给被调用的生成器函数)。 这就把生成器到调用者的单向通信转变为两者之间的双向通信。
传递数据的功能是通过迭代器的send()方法实现的。下面的logger()协程是这种通信如何运行的例子:
<?phpfunction logger($fileName) {$fileHandle = fopen($fileName, 'a');while (true) {fwrite($fileHandle, yield . "\n");}}$logger = logger(__DIR__ . '/log');$logger->send('Foo');$logger->send('Bar')?>
正如你能看到,这儿yield没有作为一个语句来使用,而是用作一个表达式,即它能被演化成一个值。这个值就是调用者传递给send()方法的值。在这个例子里,yield表达式将首先被Foo替代写入Log,然后被Bar替代写入Log。
上面的例子里演示了yield作为接受者,接下来我们看如何同时进行接收和发送的例子:
<?phpfunction gen() {$ret = (yield 'yield1');var_dump($ret);$ret = (yield 'yield2');var_dump($ret);}$gen = gen();var_dump($gen->current()); // string(6) "yield1"var_dump($gen->send('ret1')); // string(4) "ret1" (the first var_dump in gen)// string(6) "yield2" (the var_dump of the ->send() return value)var_dump($gen->send('ret2')); // string(4) "ret2" (again from within gen)// NULL (the return value of ->send())?>
要很快的理解输出的精确顺序可能稍微有点困难,但你确定要搞清楚为什按照这种方式输出。以便后续继续阅读。
另外,我要特别指出的有两点:
第一点,yield表达式两边的括号在PHP7以前不是可选的,也就是说在PHP5.5和PHP5.6中圆括号是必须的。
第二点,你可能已经注意到调用current()之前没有调用rewind()。这是因为生成迭代对象的时候已经隐含地执行了rewind操作。
多任务协作
如果阅读了上面的logger()例子,你也许会疑惑“为了双向通信我为什么要使用协程呢?我完全可以使用其他非协程方法实现同样的功能啊?”,是的,你是对的,但上面的例子只是为了演示了基本用法,这个例子其实并没有真正的展示出使用协程的优点。
正如上面介绍里提到的,协程是非常强大的概念,不过却应用的很稀少而且常常十分复杂。要给出一些简单而真实的例子很难。
在这篇文章里,我决定去做的是使用协程实现多任务协作。我们要解决的问题是你想并发地运行多任务(或者 程序 ),不过我们都知道CPU在一个时刻只能运行一个任务(不考虑多核的情况)。因此处理器需要在不同的任务之间进行切换,而且总是让每个任务运行 一小会儿 。
多任务协作这个术语中的 协作 很好的说明了如何进行这种切换的:它要求当前正在运行的任务自动把控制传回给调度器,这样就可以运行其他任务了。这与 抢占 多任务相反,抢占多任务是这样的:调度器可以中断运行了一段时间的任务,不管它喜欢还是不喜欢。协作多任务在Windows的早期版本(windows95)和Mac OS中有使用,不过它们后来都切换到使用抢先多任务了。理由相当明确:如果你依靠程序自动交出控制的话,那么一些恶意的程序将很容易占用整个CPU,不与其他任务共享。
现在你应当明白协程和任务调度之间的关系:yield指令提供了任务中断自身的一种方法,然后把控制交回给任务调度器。因此协程可以运行多个其他任务。更进一步来说,yield还可以用来在任务和调度器之间进行通信。
为了实现我们的多任务调度,首先实现 任务 , 一个用轻量级的包装的协程函数:
<?phpclass Task {protected $taskId;protected $coroutine;protected $sendValue = null;protected $beforeFirstYield = true;public function __construct($taskId, Generator $coroutine) {$this->taskId = $taskId;$this->coroutine = $coroutine;}public function getTaskId() {return $this->taskId;}public function setSendValue($sendValue) {$this->sendValue = $sendValue;}public function run() {if ($this->beforeFirstYield) {$this->beforeFirstYield = false;return $this->coroutine->current();} else {$retval = $this->coroutine->send($this->sendValue);$this->sendValue = null;return $retval;}}public function isFinished() {return !$this->coroutine->valid();}}
如代码,一个任务就是用任务ID标记的一个协程(函数)。使用 setSendValue() 方法,你可以指定哪些值将被发送到下次的恢复(在之后你会了解到我们需要这个),run() 函数确实没有做什么,除了调用 send() 方法的协同程序,要理解为什么添加了一个 beforeFirstYieldflag 变量,需要考虑下面的代码片段:
<?phpfunction gen() {yield 'foo';yield 'bar';}$gen = gen();var_dump($gen->send('something'));// 如之前提到的在send之前,当$gen迭代器被创建的时候一个renwind()方法已经被隐式调用// 所以实际上发生的应该类似://$gen->rewind();//var_dump($gen->send('something'));//这样renwind的执行将会导致第一个yield被执行, 并且忽略了他的返回值.//真正当我们调用yield的时候, 我们得到的是第二个yield的值! 导致第一个yield的值被忽略.//string(3) "bar"
通过添加 beforeFirstYieldcondition 我们可以确定第一个yield的值能被正确返回。
调度器现在不得不比多任务循环要做稍微多点了,然后才运行多任务:
<?phpclass Scheduler {protected $maxTaskId = 0;protected $taskMap = []; // taskId => taskprotected $taskQueue;public function __construct() {$this->taskQueue = new SplQueue();}public function newTask(Generator $coroutine) {$tid = ++$this->maxTaskId;$task = new Task($tid, $coroutine);$this->taskMap[$tid] = $task;$this->schedule($task);return $tid;}public function schedule(Task $task) {$this->taskQueue->enqueue($task);}public function run() {while (!$this->taskQueue->isEmpty()) {$task = $this->taskQueue->dequeue();$task->run();if ($task->isFinished()) {unset($this->taskMap[$task->getTaskId()]);} else {$this->schedule($task);}}}}?>
newTask()方法(使用下一个空闲的任务id)创建一个新任务,然后把这个任务放入任务map数组里。接着它通过把任务放入任务队列里来实现对任务的调度。接着run()方法扫描任务队列,运行任务。如果一个任务结束了,那么它将从队列里删除,否则它将在队列的末尾再次被调度。
让我们看看下面具有两个简单(没有什么意义)任务的调度器:
<?phpfunction task1() {for ($i = 1; $i <= 10; ++$i) {echo "This is task 1 iteration $i.\n";yield;}}function task2() {for ($i = 1; $i <= 5; ++$i) {echo "This is task 2 iteration $i.\n";yield;}}$scheduler = new Scheduler;$scheduler->newTask(task1());$scheduler->newTask(task2());$scheduler->run();
两个任务都仅仅回显一条信息,然后使用yield把控制回传给调度器。输出结果如下:
This is task 1 iteration 1.This is task 2 iteration 1.This is task 1 iteration 2.This is task 2 iteration 2.This is task 1 iteration 3.This is task 2 iteration 3.This is task 1 iteration 4.This is task 2 iteration 4.This is task 1 iteration 5.This is task 2 iteration 5.This is task 1 iteration 6.This is task 1 iteration 7.This is task 1 iteration 8.This is task 1 iteration 9.This is task 1 iteration 10.
输出确实如我们所期望的:对前五个迭代来说,两个任务是交替运行的,而在第二个任务结束后,只有第一个任务继续运行。

若有收获,就点个赞吧
0 人点赞
