首先:一致性哈希采用的也是取模法,不过它不是对服务器数量取模,而是对 2^32 取模
1,场景
假设现在缓存服务器(Redis)遇到了瓶颈,数据量太大,单台 Redis 存不下来,这是后就需要部署多台 Redis 服务器来存储不同的数据,这时候我们有以下几个需求:
- 所有的数据在缓存服务器是均匀分布的
-
1,数据的均匀分布
我们必须要满足数据是在服务器均匀分布且可追踪的,假设如果随机分布,那么确定数据是否被缓存就必须要遍历所有缓存服务器,此时性能将大大降低,这也就失去了缓存数据的本意,所以我们要采用取模法:
**hash(数据) % N(服务器数量)**2,服务高可用
假设我们使用以上的取模法,会有以下问题:
当有服务器宕机时,服务器数量变更,导致所有数据的取模结果可能发生变更,本来命中缓存的请求全部去查询数据库
- 当扩容服务器时,服务器数量变化导致取模的结果不一致,也就是本就被缓存的数据但是取模后发现命中的服务器没有,还是会去请求数据库
2,一致性哈希的基本概念
我们将 2^32 次方比作一个圆环,圆环上的每个点都是 0-2^32 次方的一个数字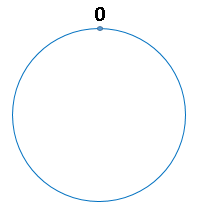
我们将服务器的 IP 对 2^32 次方取模,就是服务器在圆环上的位置:**hash(服务器 IP) % 2^32**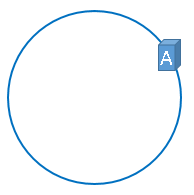
假设我们现在有三台服务器 ABC,理想情况下是均匀分布在圆环上的三个位置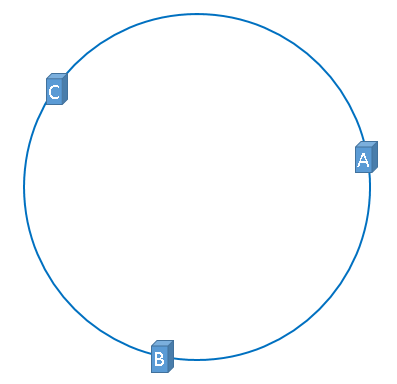
现在有数据进行缓存,我们采用顺时针法,数据哈希取模的结果对应的点的顺时针服务器就是缓存的目标服务器
如下:数据 1,2 将缓存在服务器 A,数据 3 将缓存在服务器 B,数据 4 将缓存在服务器 C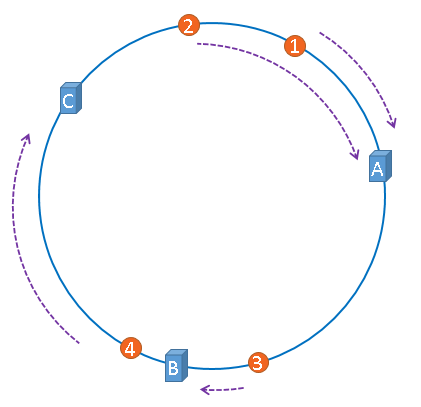
3,服务器扩容与缩容
当有扩容加入时,比如新的服务器位置落在 AB 之间,那么对 A 没影响,但是会挡住服务器 B 的请求,此时就需要将服务器 B 的一部分数据复制到新的服务器,来提供可用性,因为不复制的话,请求落在新服务器上发现没数据,就会查询数据库
相反的,当缩容服务器时,需要将要去掉的服务器的数据在缩容之前复制给下一个节点服务器,保证缩容后请求可以正常处理4,一致性哈希的优点
1,服务器故障
假设服务器 B 宕机,那么圆环就会变成,此时数据 3 的位置发生改变,但是数据 1,2,4 的位置没有变更,也就是说只有部分缓存会失效,这样就大大提高了系统容错性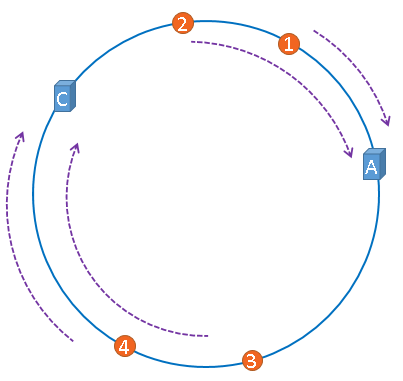
5,一致性哈希存在的问题
1,哈希环偏斜
前面说到了,理想情况下服务器的哈希取模结果是均匀的,但是事实并不是如此,现实往往是下面这种情况: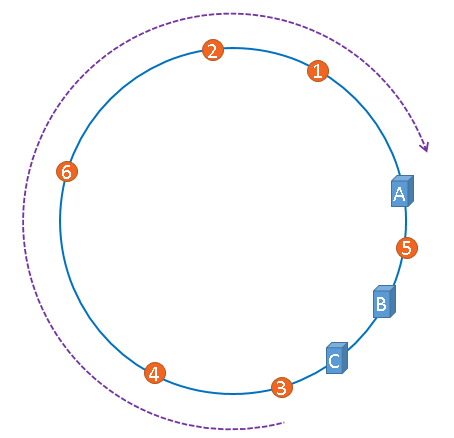
如上图,数据 1,2,3,4,6 缓存在服务器 A,数据 5 缓存在服务器 B,服务器 C 暂时没数据,这就造成了数据分配不均匀,有些服务器压力大,有些服务器空闲,系统容错率降低,为此,我们引入了虚拟节点1,虚拟节点
物理服务器的 IP 是不可控或者难以控制的,也就是说物理服务器在哈希环上的分布我们很难介入,但是创造虚拟 IP 我们确是可以实现的: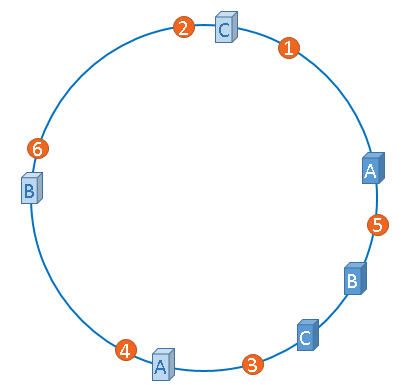
上图,我们分别给服务器 ABC 复制了三个虚拟节点,并保证虚拟节点的均匀分布,只要有数据哈希取模落到虚拟节点上,就去寻找其真正的物理服务器,这样就做到了数据的均匀分配

若有收获,就点个赞吧
0 人点赞
