正则表达式
1.使用一个正则表达式字面量。
其由包含在斜杠之间的模式组成,如下所示:
var re = /ab+c/;
2.调用[RegExp](https://developer.mozilla.org/zh-CN/docs/JavaScript/Reference/Global_Objects/RegExp)对象的构造函数。
第二个参数为i、g、m时分别的作用
var re = new RegExp("ab+c");var re = new RegExp("ab+c","igm");//第二个参数的值可以为ig,i代表忽略大小写,g表示执行全局搜索,//m表示可以进行多行匹配,但只有在^或$模式时才会起作用,一般和g一起用。### g用法详解//test方法,加不加g都一样。//exec方法,不加g只返回第一个匹配,加入g后,第一次执行返回第一个匹配,第二次执行返回第二个匹配...var regx=/user\d/;var str=“user18dsdfuser2dsfsd”;var rs=regx.exec(str);//此时rs的值为{user1}var rs2=regx.exec(str);//此时rs的值依然为{user1}如果regx=/user\d/g;则rs的值为{user1},rs2的值为{user2}//match方法,不加g,只返回第一个匹配,一直执行也只返回第一个匹配,加上g则一次性返回所有匹配var regx=/user\d/;var str=“user1sdfsffuser2dfsdf”;var rs=str.match(regx);//此时rs的值为{user1}var rs2=str.match(regx);//此时rs的值依然为{user1}如果regx=/user\d/g,则rs的值为{user1,user2},rs2的值也为{user1,user2}//replace方法,不加g则只替换第一个匹配,加g则替换所有匹配。//split方法,加不加g都一样。var sep=/user\d/;var array=“user1dfsfuser2dfsf”.split(sep);则array的值为{dfsf, dfsf}此时sep=/user\d/g,返回值是一样的//search方法,加不加g都一样。### m用法详解(只有在^或$模式时才会起作用,m的作用为:如果不加入m,则只能在第一行进行匹配,如果加入m则可以在所有的行进行匹配。普通无^或$的情况用g就能搜到)****************************使用^的例子****************************var regx=/^b./g;var str=`bd76 dfsdfsdfsdfs dfb8fsb76dsf sdfsdf`;var rs=str.match(regx);regx=/^b./g// ["bd"]regx=/^b./m;// ["bd"]regx=/^b./gm;// ["bd", "b7"]****************************使用其他模式的例子****************************var regx=/user\d/;var str=`sdfsfsdfsdfsdfsuser3 dffsb76dsf user6`;var rs=str.match(regx);regx=/user\d/; // ["user3"]regx=/user\d/g;// ["user3", "user6"]#加不加m没有影响regx=/user\d/m;// ["user3"]regx=/user\d/gm;// ["user3", "user6"]****************************另一个^例子****************************var regx=/^b./;var str=`ret76 dfsdfbjfsdfs dffsb76dsf sdfsdf`;var rs=str.match(regx);regx=/^b./;// nullregx=/^b./g;// nullregx=/^b./m;// ["bj"]regx=/^b./gm;// ["bj", "b7"]****************************补充****************************在HTML的textarea输入域中,按一个Enter键,对应的控制字符为“\r\n”,即“回车换行”。(上述在console中,\r\n无法识别到换行,只用\n能识别到。)


若.出现在[]中,如[a-z.],则此处是找a到z或者.,而不是找单字符。
. |
(小数点)默认匹配除换行符之外的任何单个字符。 例如, /.n/ 将会匹配 “nay, an apple is on the tree” 中的 ‘an’ 和 ‘on’,但是不会匹配 ‘nay’。如果 s (“dotAll”) 标志位被设为 true,它也会匹配换行符。 |
|---|---|
\s |
匹配一个空白字符,包括空格、制表符、换页符和换行符。等价于[ \f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。 例如, /\s\w*/ 匹配”foo bar.”中的’ bar’。经测试,\s不匹配”\u180e“,在当前版本Chrome(v80.0.3987.122)和Firefox(76.0.1)控制台输入/\s/.test(“\u180e”)均返回false。 |
|---|---|
\w |
匹配一个单字字符(字母、数字或者下划线)。等价于 [A-Za-z0-9_]。例如, /\w/ 匹配 “apple,” 中的 ‘a’,”$5.28,”中的 ‘5’ 和 “3D.” 中的 ‘3’。 |
|---|---|
\ |
依照下列规则匹配: 在非特殊字符之前的反斜杠表示下一个字符是特殊字符,不能按照字面理解。例如,前面没有 “\“ 的 “b” 通常匹配小写字母 “b”,即字符会被作为字面理解,无论它出现在哪里。但如果前面加了 “\“,它将不再匹配任何字符,而是表示一个字符边界。 在特殊字符之前的反斜杠表示下一个字符不是特殊字符,应该按照字面理解。详情请参阅下文中的 “转义(Escaping)” 部分。 如果你想将字符串传递给 RegExp 构造函数,不要忘记在字符串字面量中反斜杠是转义字符。所以为了在模式中添加一个反斜杠,你需要在字符串字面量中转义它。 /[a-z]\s/i 和 new RegExp("[a-z]\\s", "i") 创建了相同的正则表达式:一个用于搜索后面紧跟着空白字符(\s 可看后文)并且在 a-z 范围内的任意字符的表达式。为了通过字符串字面量给 RegExp 构造函数创建包含反斜杠的表达式,你需要在字符串级别和正则表达式级别都对它进行转义。例如 /[a-z]:\\/i 和 new RegExp("[a-z]:\\\\","i") 会创建相同的表达式,即匹配类似 “C:\“ 字符串。 |
|---|---|
.*?代表的意思
- . 匹配任意除换行符“\n”外的字符;
- *表示匹配前一个字符0次或无限次;
- ?表示前边字符的0次或1次重复 4、+或后跟?表示非贪婪匹配,即尽可能少的匹配,如?重复任意次,但尽可能少重复;
- .? 表示匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。 如:a.?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab和ab。
String对象和RegExp对象。
正则表达式中 test、exec、match 方法区别
exec、match、test等使用正则表达式的函数区别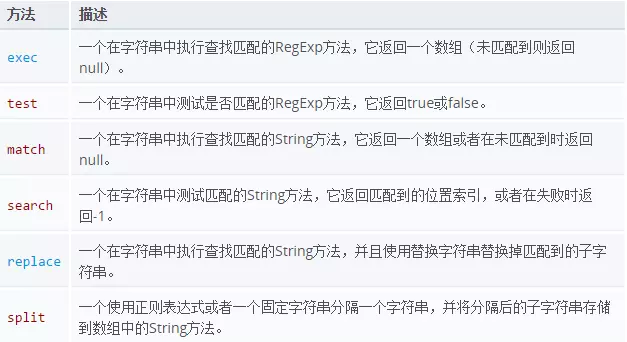
一、String对象支持四种利用正则表达式的方法,分别为search(),replace(),match(),split()
- 1、search()方法以正则表达式作为参数,返回第一个与之匹配的子串开始的位置,如果没有任何与之匹配的子串,它返回-1。
- 2、replace()方法执行检索和替换操作,它的第一个参数是正则表达式,第二个参数是要进行替换的字符串或者闭包。
- 3、 match()方法的唯一一个参数是正则表达式,它的行为取决于这个正则表达式的标志,如果正则表达式包含了标志g,它的返回值就是包含了出现在字符串中 匹配的数组。如果该正则表达式不包含标志g,它也返回一个数组,它的第一个元素是匹配的字符串,余下的元素则是正则表达式中的各个分组。
- 4、split()方法是能够支持模式匹配的。
二、RegExp对象定义了两个用于模式匹配的方法,它们是exec()和test()
- 1、 RegExp的exec()方法和String的match()方法很类似,它对一个指定的字符串执行一个正则表达式匹配,如果没有找到任何一个匹配,它 将返回null,否则返回一个数组,这个数组的第一个元素包含的是与正则表达式相匹配的字符串,余下的所有元素包含的是匹配的各个分组。而且,正则表达式 对象的index属性还包含了匹配发生的字符串的位置,属性input引用的则是被检索的字符串。 如果正则表达式具有g标志,它将把该对象的lastIndex属性设置到紧接着匹配字符串的位置开始检索,如果exec()没有发现任何匹配,它将把 lastIndex属性重置为0,这一特殊的行为可以使你可以反复调用exec()遍历一个字符串中所有的正则表达式匹配。

- 2、RegExp对象的test()参数为一个字符串,如果这个字符串包含正则表达式的一个匹配,它就返回true,否则返回false,当一个具有g标志的正则表达式调用test()方法时,它的行为和exec()相同,既它从lastIndex处开始检索特定的字符串,如果它发现匹配,就将lastIndex设置为紧接在那个匹配之后的字符的位置,这样我们就可以使用方法test()来遍历字符串了。 ```javascript **reg.test(str),返回 Boolean,查找对应的字符串中是否存在模式。* const str = ‘1a1b1c’; const reg = /^1./; const reg2 = new RegExp(‘1.$’,’’);
reg.test(str); // true reg2.test(str); // true
test()继承正则表达式的lastIndex属性,表达式在匹配全局标志g的时候须注意。
如何之前reg调用了exec或者test的方法,那么此处的lastIndex属性将继承。
function testDemo(){
var r, re; // 声明变量。
var s = “I”;
re = /I/ig; // 创建正则表达式模式。
document.write(re.test(s) + “
“); // 返回 Boolean 结果。 true
document.write(re.test(s) + “
“); // false
document.write(re.test(s)); // true
}
testDemo();
//当第二次调用test()的时候,lastIndex指向下一次匹配所在位置1,
//所以第二次匹配不成功,lastIndex重新指向0,等于第三次又重新匹配。
**reg.exec(str),查找并返回当前的匹配结果,并以数组的形式返回。**
不要忘记使用g,不然会一直匹配第一个。
const str = ‘1a1b1c’; const reg = /^1./;reg.exec(str); // [“1a”] const reg2 = new RegExp(‘1.$’,’’);reg2.exec(str); // [“1c”] const reg3 = /1./;reg3.exec(str); // [“1a”],不管执行几次都是输出[“1a”] const reg4 = /1./g;reg4.exec(str); // 第一次执行输出[“1a”],第二次执行输出[“1b”],依此类推。
exec返回的值可以拿到当前的匹配到的字符的index值,如reg2.exec(str).index; // 4
在匹配后,reg 的 lastIndex 属性被设置为匹配文本的最后一个字符的下一个位置。
lastIndex并不在返回对象的属性中,而是正则表达式对象的属性。
var str = ‘1a1b1c’; var reg4 = /1./g; var reg = reg4.exec(str); reg; // [“1a”, index: 0, input: “1a1b1c”, groups: undefined] reg.index; // 0 reg4.lastIndex; // 2(匹配文本的最后一个字符的下一个位置)
**str.match(reg),如果指定了参数 g,那么 match 一次返回所有的结果。** var str = “1a1b1c”; var reg = new RegExp(“1.”, “g”); alert(str.match(reg)); //alert(str.match(reg)); // 此句同上句的结果是一样的 此结果为一个数组,有三个元素,分别是:1a、1b、1c。
*str.search(reg),返回匹配字符串的起始位置,无则返回-1。* search() 方法不执行全局匹配,它将忽略标志 g。 它同时忽略 reg 的 lastIndex 属性,并且总是从字符串的开始进行检索。 这意味着它总是返回 str 的第一个匹配的位置。 var str=”Visit W3School!”; console.log(str.search(/w3school/i));// 6
**str.replace(reg,replacement),返回替换后的新字符串,str不改变。** replacement 可以是字符串,也可以是函数。如果它是字符串,那么每个匹配都将由字符串替换。 但是 replacement 中的 $ 字符具有特定的含义。如下表所示,它说明从模式匹配得到的字符串将用于替换。
将所有单词首字母大写
name = ‘aaa bbb ccc’; uw=name.replace(/\b\w+\b/g, function(word){ return word.substring(0,1).toUpperCase()+word.substring(1);} );
将Doe, John替换为John, Doe
name = “Doe, John”; name.replace(/(\w+)\s, \s(\w+)/, “$2 $1”); *str.replace(separator,howmany),返回不包含separator的字符串数组。* howmany,指定返回的数组的最大长度。 var str=”How are you doing today?”
console.log(str.split(“ “) + “
“) //How,are,you,doing,today?
console.log(str.split(“”) + “
“) //H,o,w, ,a,r,e, ,y,o,u, ,d,o,i,n,g, ,t,o,d,a,y,?
console.log(str.split(“ “,3)) // How,are,you
console.log(str.split(“”,3)) // [“H”, “o”, “w”]
console.log(str.split(“ “,5)) // [“How”, “are”, “you”, “doing”, “today?”]
console.log(str.split(“”,7)) // [“H”, “o”, “w”, “ “, “a”, “r”, “e”]
console.log(str.split(“ “,7)) // [“How”, “are”, “you”, “doing”, “today?”]
**reg.compile(“[a-z]{5}”, “g”),把正则表达式编译为内部格式,从而执行得更快。**
compile 方法把正则表达式编译为内部格式,从而执行得更快。
var reg = new RegExp();
reg.compile(“[a-z]{5}”, “g”);
alert(reg.test(“cftea”));
```
str.replace(reg,replacement),replacement中$的含义:

若有收获,就点个赞吧
0 人点赞
