写在前面
hadoop的部署分为本地模式、伪集群模式、完全分布式部署,本小节主要介绍本地模式、伪集群模式。
本地模式
上一节安装完成之后,默认就是本地模式,下面我们在从测试环境下运行一个demo。
1.第一个示例
进入hadoop安装目录,执行如下命令。
mkdir inputcp etc/hadoop/*.xml inputbin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar grep input output 'dfs[a-z.]+'cat output/*

2.第二个示例
进入hadoop安装目录,执行如下命令。
mkdir wcinputcd wcinput/vim wc.inputcd ..bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount wcinput wcoutputcat wcinput/wc.input
其中文件wc.input内容如下,
aaa bbb cccbbbdddtesttestaaaaaa
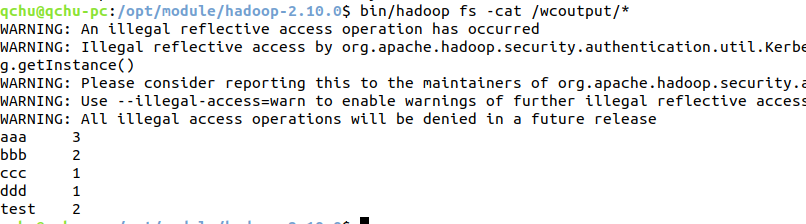
该demo中用户自定义个了一个输入,统计了输入的各个单词的数量。结果输出如下。
伪集群模式
1.配置hadoop-env.sh
Hadoop配置Jdk安装目录,进入到Hadoop的安装目录,找到文件 etc/hadoop/hadoop-env.sh
2.配置core-site.xml

<configuration><!-- 指定HDFS的namenode地址 --><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><!-- 指定hadoop运行时产生文件的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-2.10.0/data/tmp</value></property></configuration>
3.配置hsfs-site.xml
<configuration><!-- 制定hdfs副本的数量 --><property><name>dfs.replication</name><value>1</value></property></configuration>
4.启动集群
1)格式化namenode(第一次启动时格式化,以后就不要总格式化),格式化命令: bin/hdfs namenode -format,执行日志如下。
2)启动namenode
3)启动datanode
4)查看产生的日志
5)为什么只能第一次启动时进行格式化
格式化namenode会产生新的集群id,导致namenode和datanode的集群id不一致,最后集群启动不起来。所以格式化之前,需要删除掉data和log。
6)启动完成之后,可以访问地址 http://127.0.0.1:50070/dfshealth.html#tab-overview
5.配置yarn-env.sh

6.配置yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property></configuration>
7.配置mapred-env.sh

8.配置mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property></configuration>
9.启动集群
1)保证namenode和datanode已经启动
2)启动resourcemanger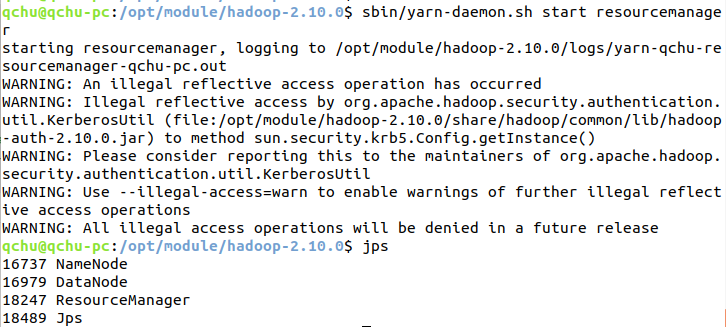
3)启动nodemanager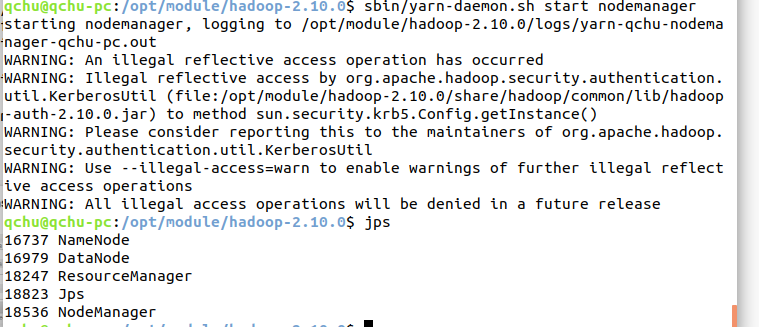
4)集群监控,地址 http://127.0.0.1:8088/cluster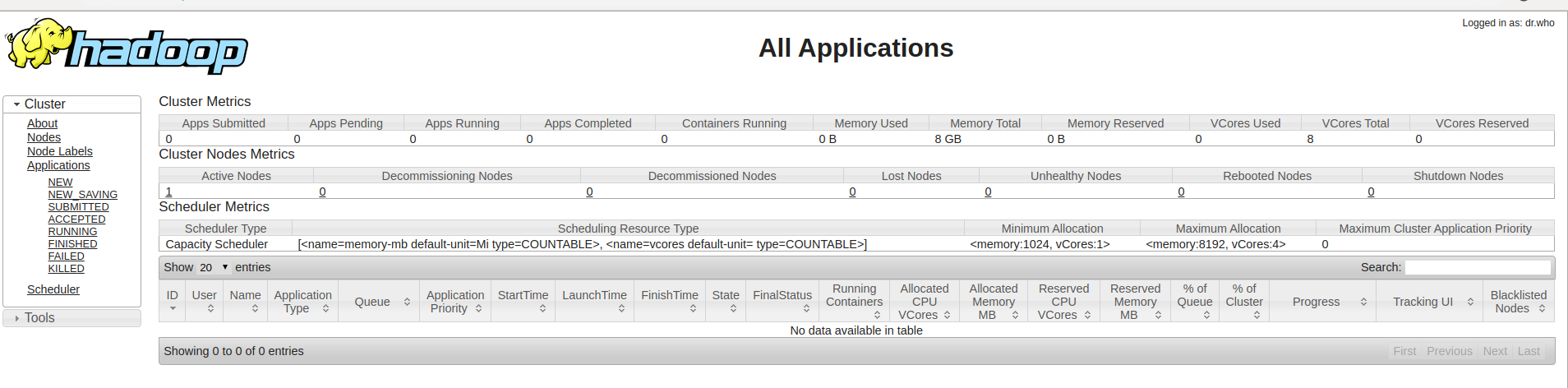
10.集群测试
1)创建一个测试文件
命令
mkdir wcinputvim wcinput/wc.input
文件wc.input内容
aaa bbb cccbbbdddtesttestaaaaaa
2)上传文件到hdfs
命令
bin/hadoop fs -put wcinput /
效果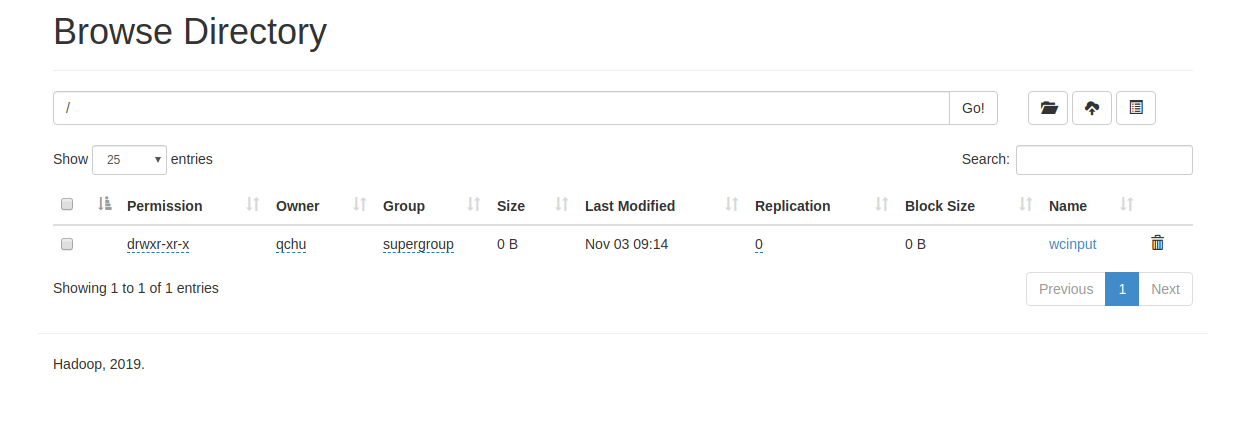
3)执行demo
命令
效果

若有收获,就点个赞吧
0 人点赞
