redo log是InnoDB存储引擎层的日志,又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。在实例和介质失败(media failure)时,redo log文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。
在一条更新语句进行执行的时候,InnoDB引擎会把更新记录写到redo log日志中,然后更新内存,此时算是语句执行完了,然后在空闲的时候或者是按照设定的更新策略将redo log中的内容更新到磁盘中,这里涉及到WAL即Write Ahead logging技术,他的关键点是先写日志,再写磁盘。
有了redo log日志,那么在数据库进行异常重启的时候,可以根据redo log日志进行恢复,也就达到了crash-safe。redo log日志的大小是固定的,即记录满了以后就从头循环写。
MySQL有一个参数:innodb_flush_log_at_trx_commit能够控制事务提交时,刷redo log的策略。 目前有三种策略:
- 策略一:最佳性能(innodb_flush_log_at_trx_commit=0):每隔一秒,才将Log Buffer中的数据批量write入OS cache,同时MySQL主动fsync。这种策略,如果数据库奔溃,有一秒的数据丢失。
强一致(innodb_flush_log_at_trx_commit=1):每次事务提交,都将Log Buffer中的数据write入OS cache,同时MySQL主动fsync。这种策略,是InnoDB的默认配置,为的是保证事务ACID特性。
折衷(innodbflush_log_at_trx_commit=2):每次事务提交,都将Log Buffer中的数据write入OS cache;每隔一秒,MySQL主动将OS cache中的数据批量fsync。画外音:磁盘IO次数不确定,因为操作系统的fsync频率并不是MySQL能控制的。_这种策略,如果操作系统奔溃,最多有一秒的数据丢失。
作用:
确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
redo log为什么循环写入?
redo log采用固定大小,循环写入的格式,当redo log写满之后,重新从头开始如此循环写,形成一个环状。因为redo log记录的是数据页上的修改,如果Buffer Pool中数据页已经刷磁盘后,那这些记录就失效了,新日志会将这些失效的记录进行覆盖擦除。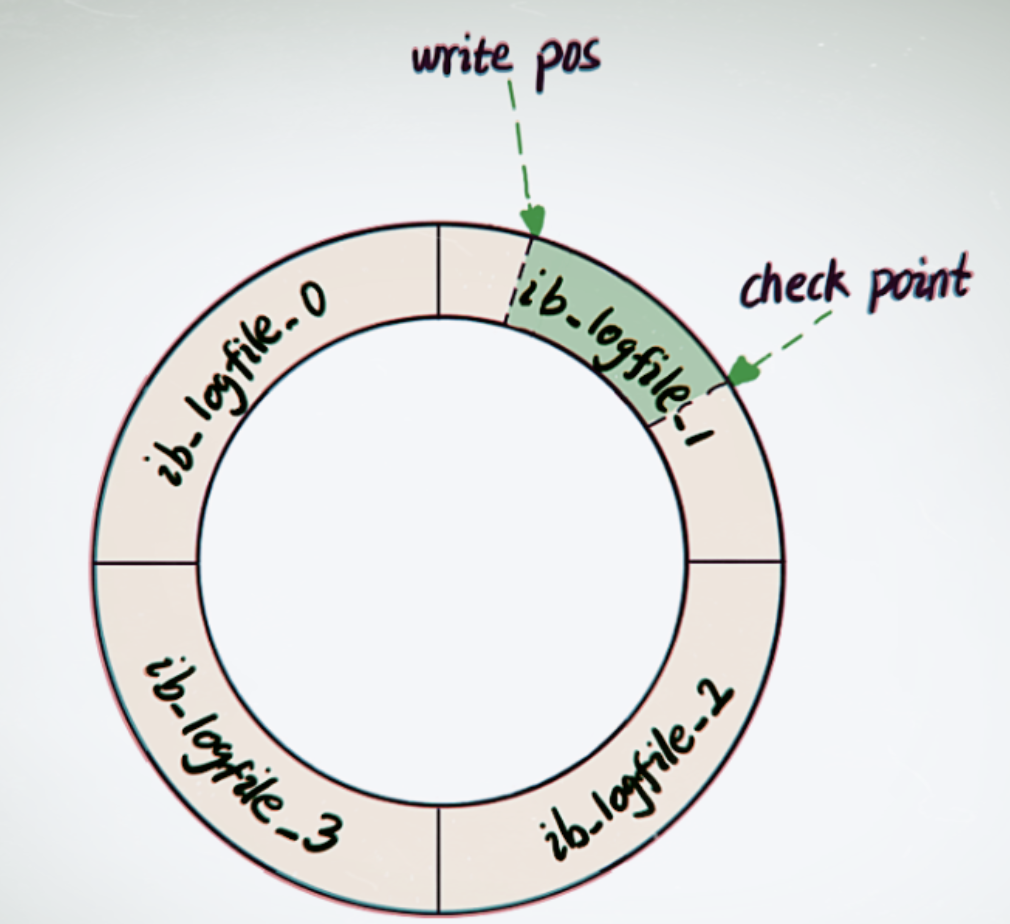
上图中的write pos表示redo log当前记录的日志序列号LSN(log sequence number),写入还未刷盘,循环往后递增;check point表示redo log中的修改记录已刷入磁盘后的LSN,循环往后递增,这个LSN之前的数据已经全落盘。write pos到check point之间的部分是redo log空余的部分(绿色),用来记录新的日志;check point到write pos之间是redo log已经记录的数据页修改数据,此时数据页还未刷回磁盘的部分。当write pos追上check point时,会先推动check point向前移动,空出位置(刷盘)再记录新的日志。
注意:redo log日志满了,在擦除之前,需要确保这些要被擦除记录对应在内存中的数据页都已经刷到磁盘中了。擦除旧记录腾出新空间这段期间,是不能再接收新的更新请求的,此刻MySQL的性能会下降。所以在并发量大的情况下,合理调整redo log的文件大小非常重要。
crash-safe
因为redo log的存在使得Innodb引擎具有了crash-safe的能力,即MySQL宕机重启,系统会自动去检查redo log,将修改还未写入磁盘的数据从redo log恢复到MySQL中。MySQL启动时,不管上次是正常关闭还是异常关闭,总是会进行恢复操作。会先检查数据页中的LSN,如果这个 LSN 小于 redo log 中的LSN,即write pos位置,说明在redo log上记录着数据页上尚未完成的操作,接着就会从最近的一个check point出发,开始同步数据。
简单理解,比如:redo log的LSN是500,数据页的LSN是300,表明重启前有部分数据未完全刷入到磁盘中,那么系统则将redo log中LSN序号300到500的记录进行重放刷盘。

若有收获,就点个赞吧
0 人点赞
