内部测试环境:mysql数据库:10.16.225.53:43306 用户:root 密码:可以私下问我
分析:依据文档(https://www.yuque.com/u296762/fatb75/xw23gv),对设备管理库的18号至21号慢日志做了一轮性能分析。对于执行频繁高用总时间较长的四类sql执行做了分析。(时间平均为超过1秒)。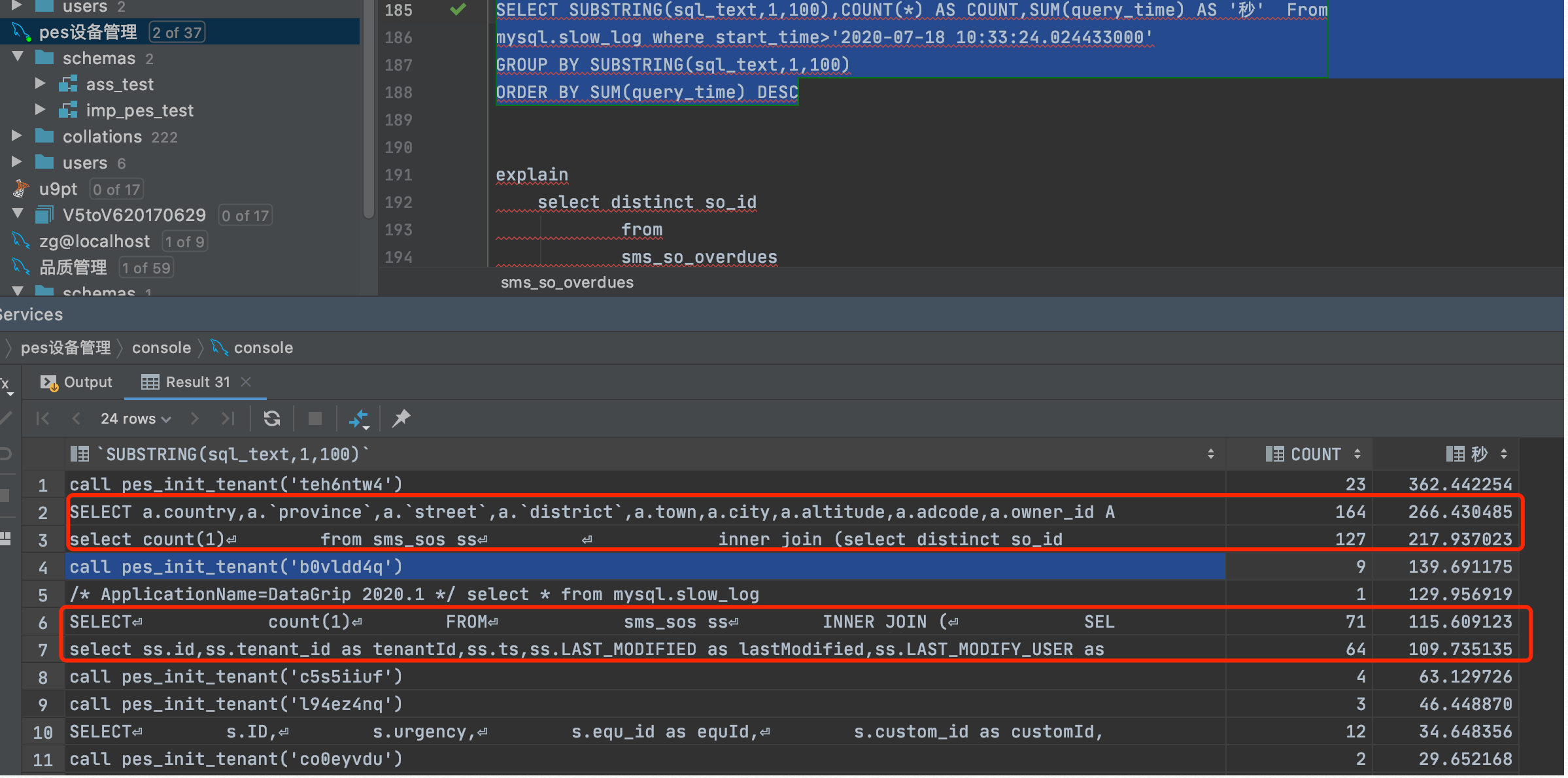
问题一:top2语句: 表本身有索引,但sql太长了,达740Kb,主要在于owner_id串过多。mysql规范中建议对于 超过iD串超过2000时分批处理(不推荐使用临时表)。请开发看此处业务情况?对于字符串拼接的这个大串,业务上能否改为其他方案?或看下平台有没有提供类似u9的方案idlist方案。如:A.[ItemInfo_ItemID] in (select id from F_GetIDTable(@PMIDPM_PO_PMSV_QueryPOForMFGSimulateSV_ItemID__IDList)))?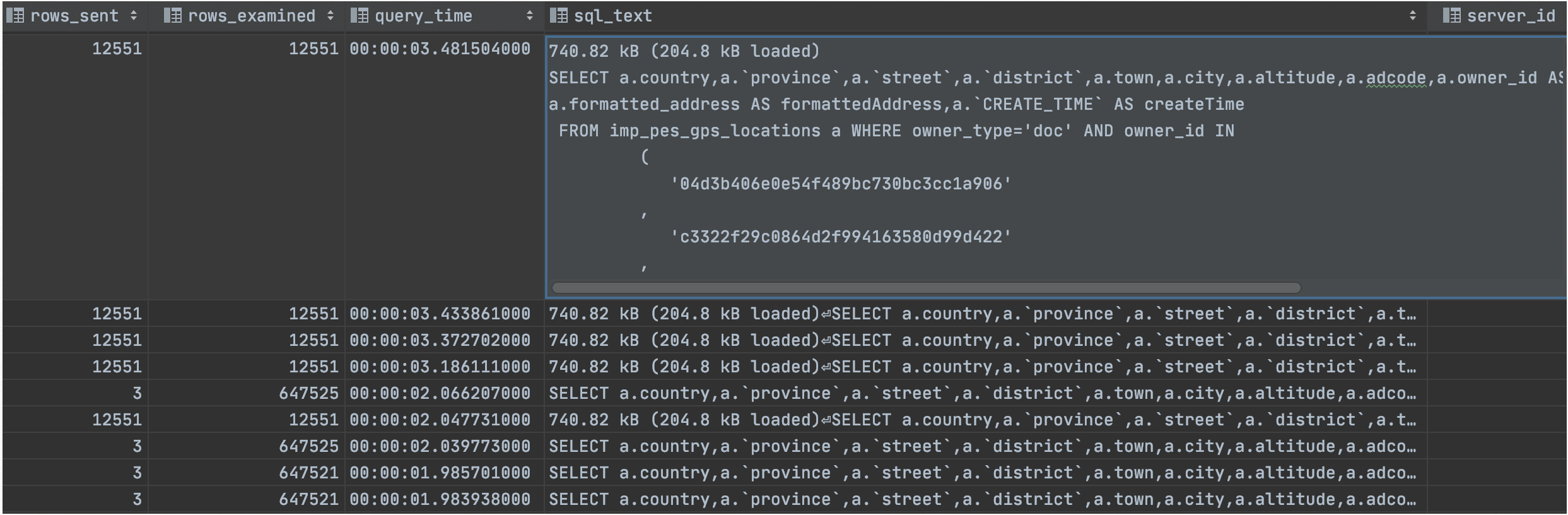
top2语句中,还有一类语句,是由于where后面在有函数,导致无法高效使用索引,rows_examined近65万。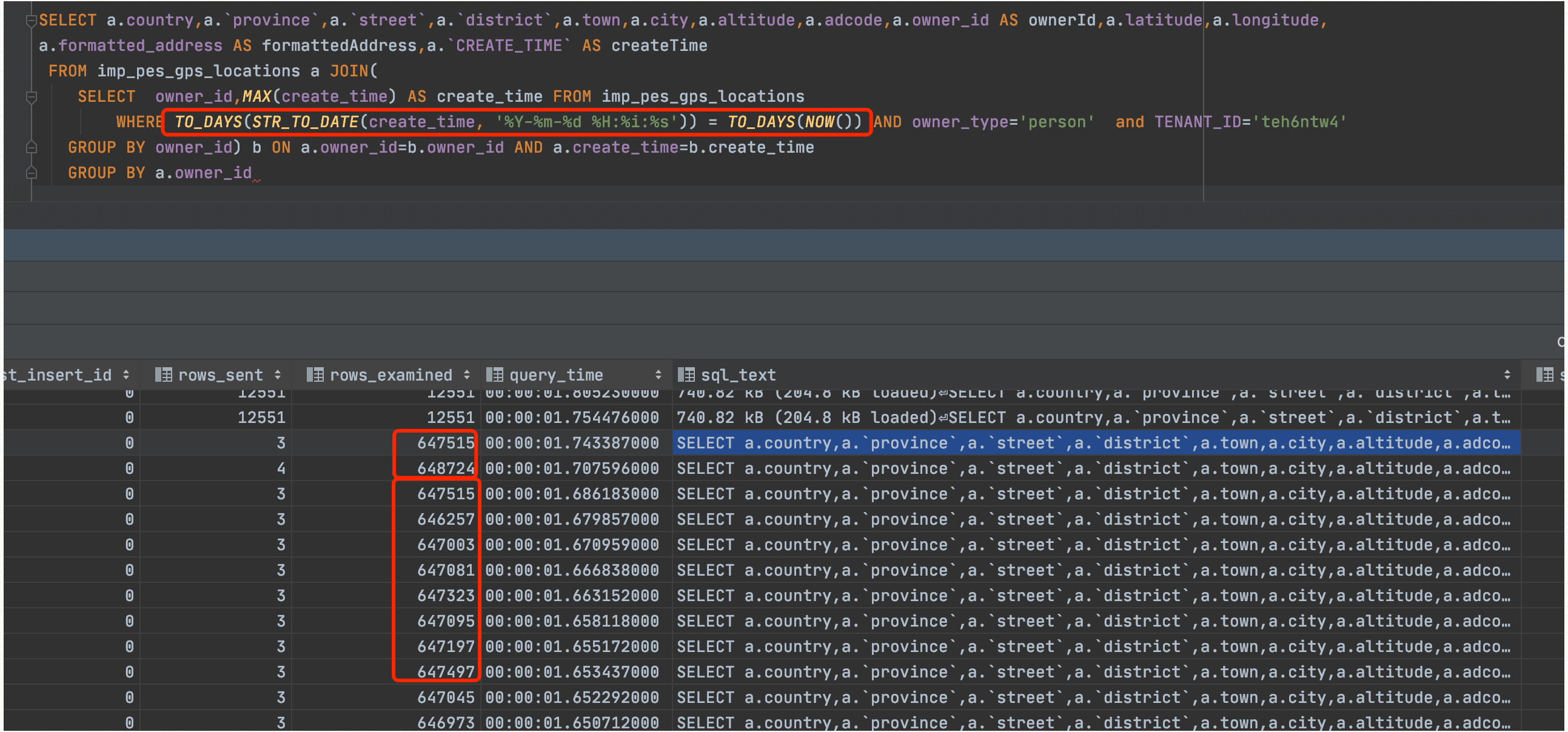
通过explain查看,通过索引idx_owner扫描,rows行数达57.7万。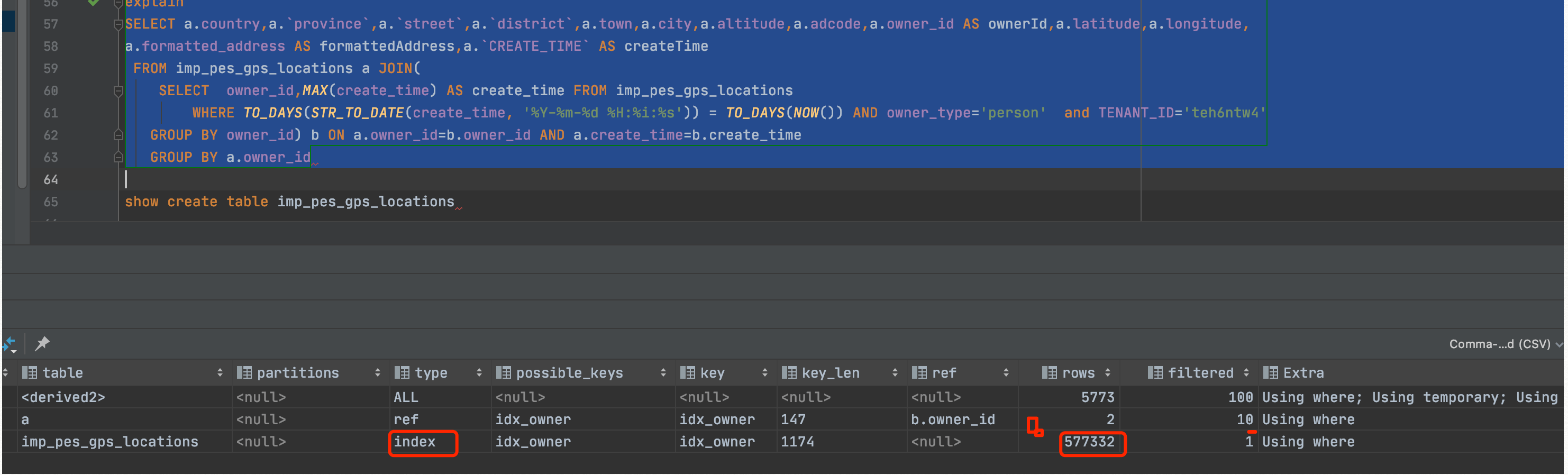
优化方案:
1.补充索引:create index ix_zg2 on imp_pes_gps_locations(create_time,owner_id,owner_type)
2.修改where语句,去掉对字段的函数。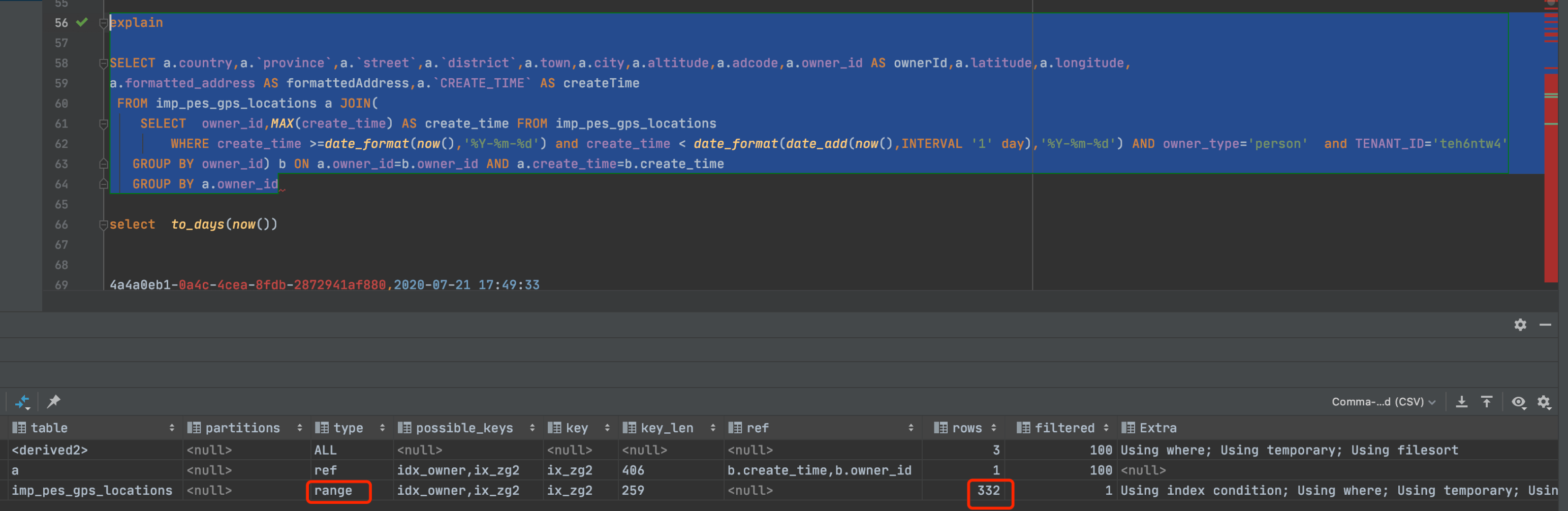
效果:
补充索引后,Index变为range(范围查找),时间由1.4秒减少到20毫秒。rows行数由57.7万减少到只有332行。
问题二:top3:同样type为index,rows行数达到47万。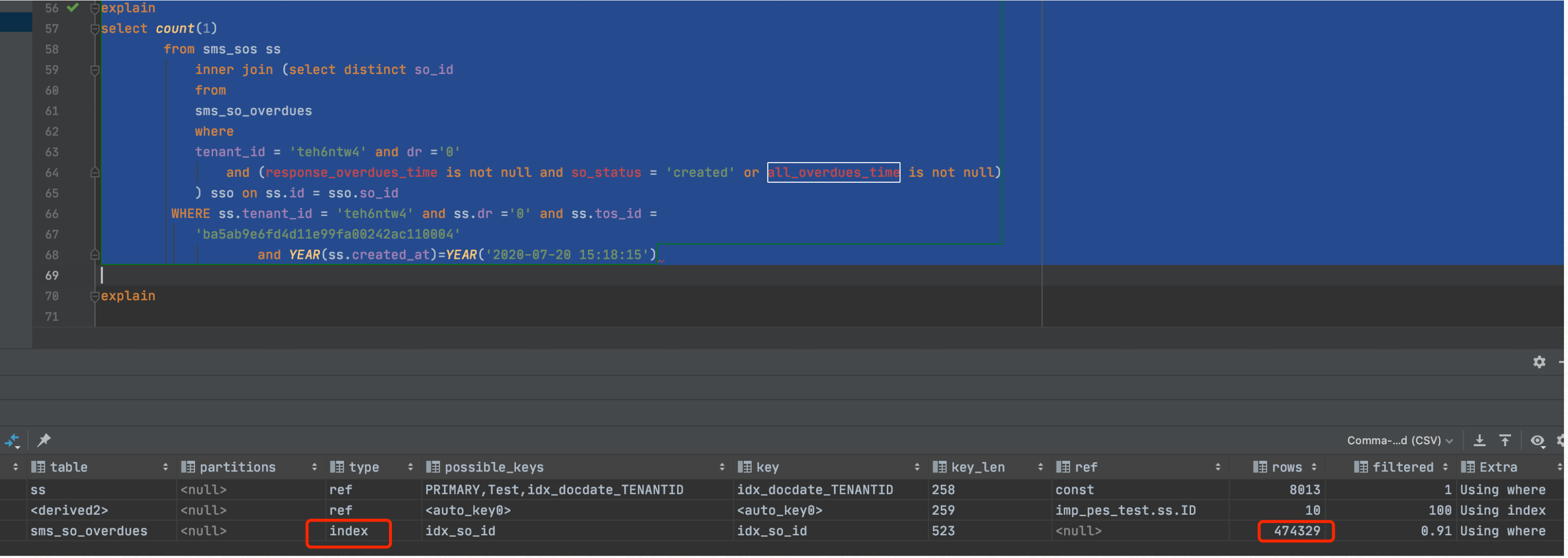
优化建议:
1.子查询中的distinct,从这个数据来看,去重和不去重数据是一样的,可以考虑把distinct去掉即可。
2.添加索引:create index zg3 on sms_so_overdues(tenant_id,dr) 后,时间从1.4秒减少到80毫秒。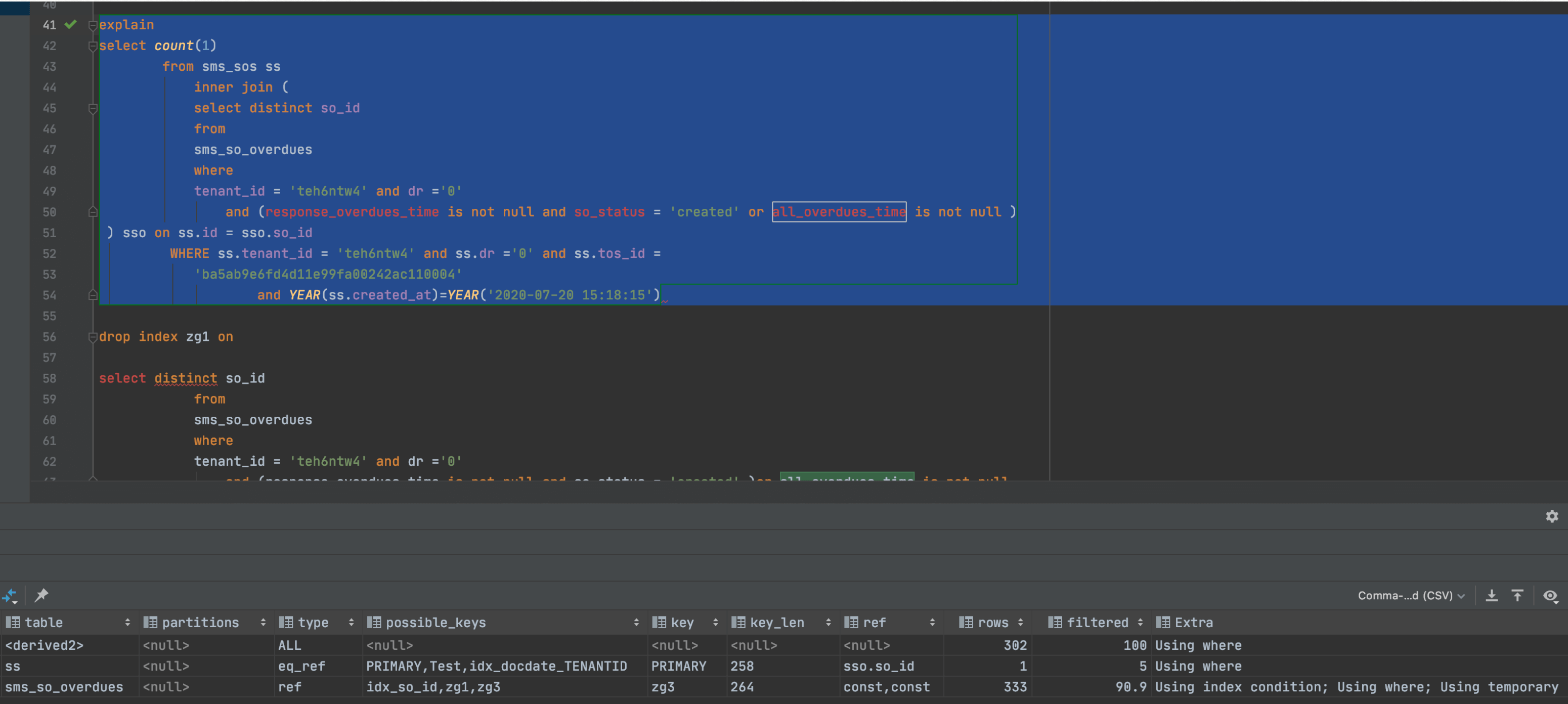
综合考虑:**看下原来表上的索引:index idx_so_id on sms_so_overdues(so_id,tenant_id,dr),直接变为:create index zg3 on sms_so_overdues(tenant_id,dr,so_id),理论上即可同时满足要求。
其他尝试,效果有进一步提升,但不太明显了,暂时不采用:
尝试一:.如果是这样添加索引
create index zg3 on sms_so_overdues(tenant_id,dr,all_overdues_time,so_id)。可进一步由80减少到40毫秒。不过暂时不用这种索引了。
尝试二:通过下面添加索引和修改sql语句结构),能进一步提升1倍左右,如从40毫秒到20毫秒,但变动较大,先不用调整了。
//1.添加索引:
//create index zg1 on sms_so_overdues(so_status,tenant_id,dr,response_overdues_time)
//create index zg3 on sms_so_overdues(tenant_id,dr,all_overdues_time)
//2.(非必须,实际测试了,虽然有or,但explain基本一样的)修改语句结构: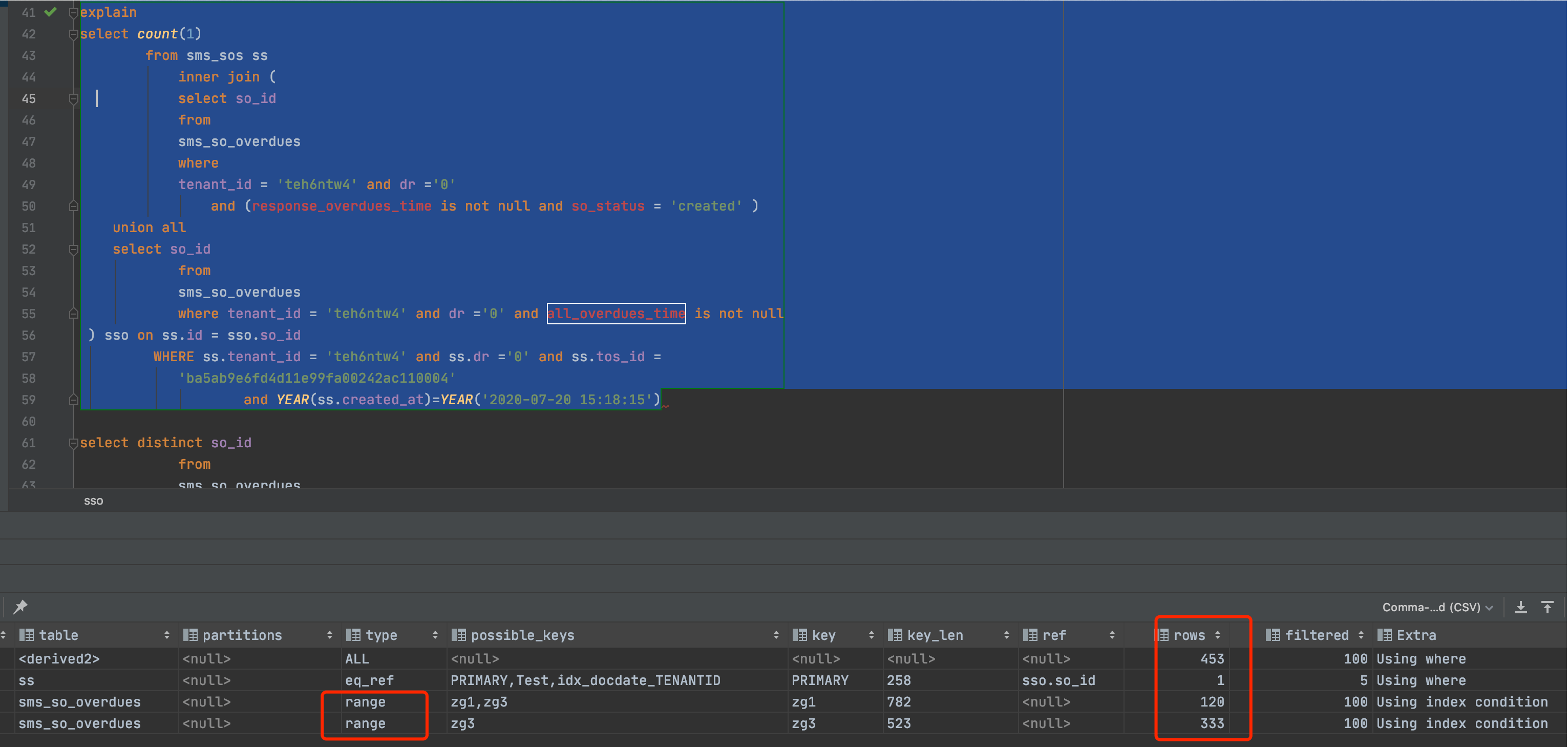
问题三、四:top6和top7 问题和上面一样,在添加添加了后,由1.4秒减少到70毫秒。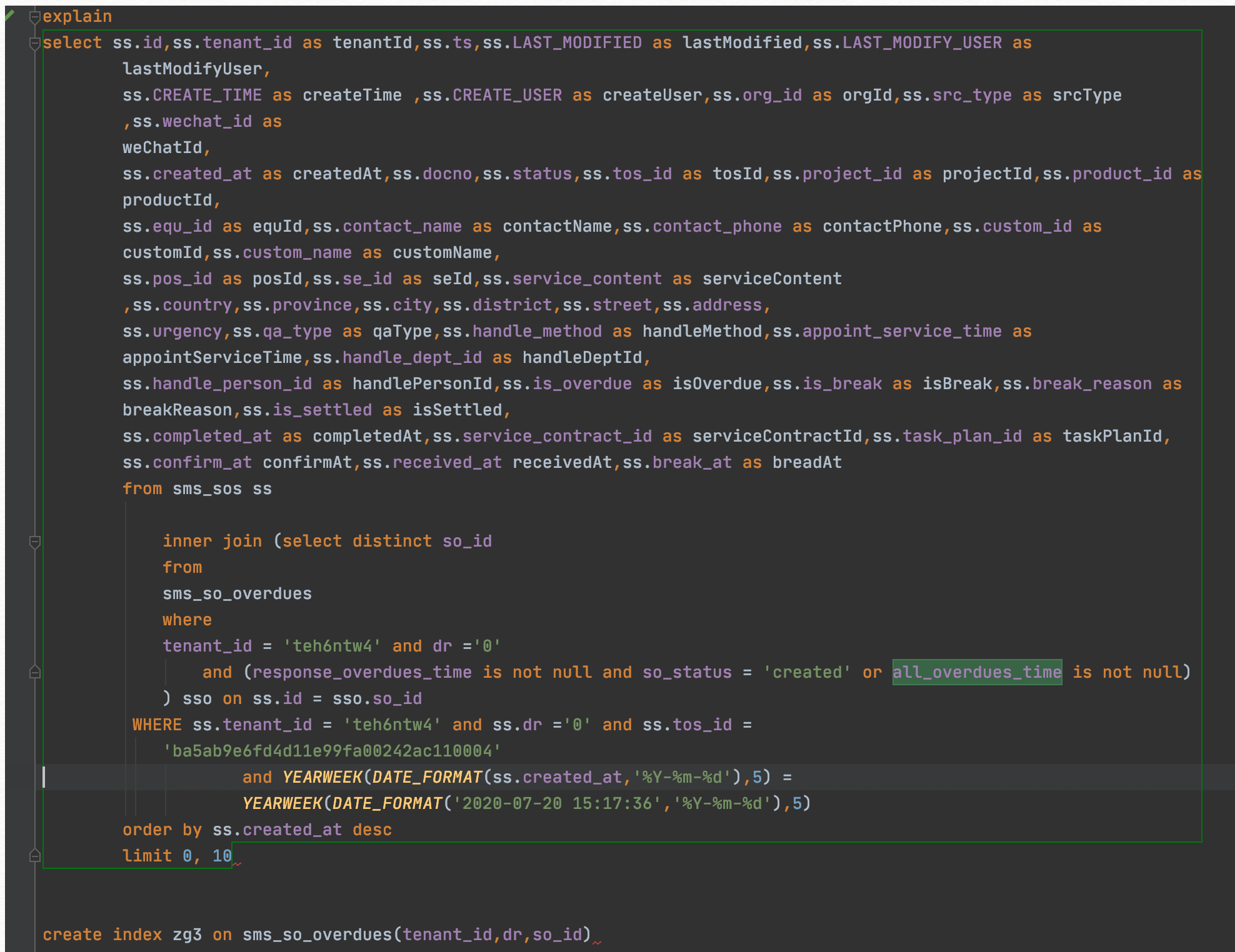
其他:
对于时间类的字段过滤,同时参考 top2,不要对字段使用函数,直接转换为一个日期大于和小于对比即可。

若有收获,就点个赞吧
0 人点赞
