
如果不知道问题背后的模型到底是线性的、二次的还是指数的?或者干脆就是一个正弦曲线?这种情况下如果事先就估计了的话,路就走偏了




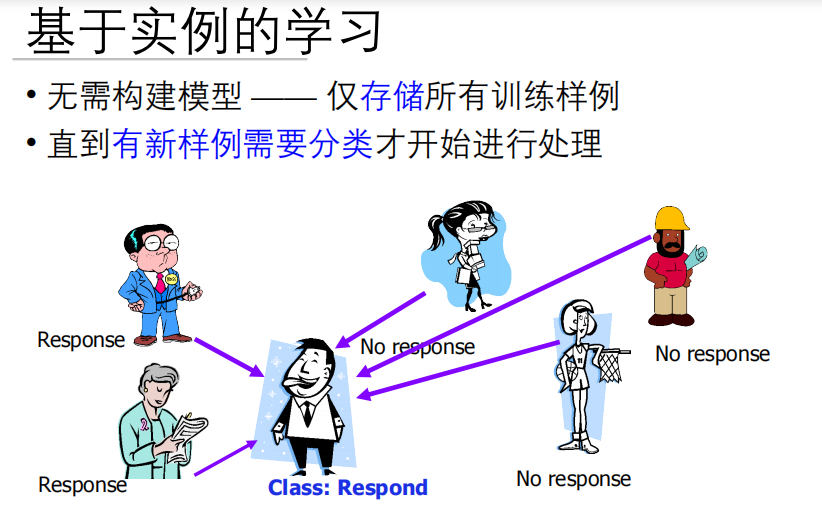
只需要让机器记住它,然后当有新样例需要分类时才做所有的处理



最近邻方法的错误率大于贝叶斯方法,但是不大于Bayes方法错误率的2倍
图为Voronoi分割,是一种凸分割,不会有凹进去的连线
- 几个概念
基点Site:具有一些几何意义的点
细胞Cell:这个Cell中的任何一个点到Cell中基点中的距离都是最近的,离其他Site比离内部Site的距离都要远。
Cell的划分:基点Site与其它的n-1个点所对应的那个平分线所确定的那个离它更近的那个半平面。把所有这些半平面公共的交集求出来就是这个cell.
因此每个Cell都是凸的,图中一定会有一些Cell是无界的

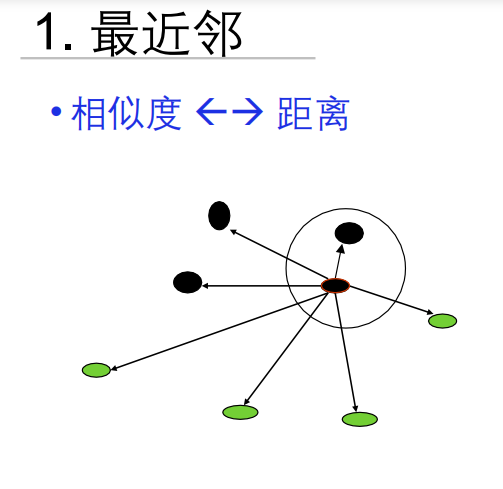
K-近邻(KNN)

距离和相似度是相反的



不做归一化很容易带来特别差的结果
取log常用于数据分布不均匀的情况下











若有收获,就点个赞吧
0 人点赞
