1.底层数据结构
底层数据结构为数组+链表+红黑数(java1.7之前是数组+链表)
使用数组+链表的原因是因为可以利用数组快速查找的属性+链表便于增删改的属性解决hash冲突的问题
使用数组+链表+红黑树的原因是因为当发生极端hash冲突的情况下,数组某一节点的链表长度过长会导致效率变低。链表的效率为O(n),红黑树的效率为O(logn)
2.HashMap的一些属性
HashMap不是线程安全的
主干数组:
- 容量,初始值为16,hashMap的数组容量都为2的倍数
- 负载因子,初始值为0,75
- 扩容阈值 = 容量 * 负载因子。当数组长度>=扩容阈值后,主干数组进行扩容。另外还会被用于存储初始化容量,当第一次put值时,主干数组才会进行初始化‘
数组节点:
- 树化阈值:8。当一个节点上链表长度>8并且主干数组长度>=64时,才会进行树化
- 链化阈值:6。当一个节点上红黑树节点<6时,才会进行链化
3.为什么树化阈值=8,链化阈值=6
因为在红黑树节点过少时,实际上的查询效率与链表并无差异,而且红黑树所需要的内存空间更多。因此为了在空间和效率上做出一个平衡,才将树化阈值设置为8
因为树化以及链化需要消耗时间和空间,因此如果将链化阈值设置为8会导致频繁的树化链化。总体上来说造成了很多不必要的资源消耗。所以叫链化阈值设置为64.为什么HashMap数组容量都为2的倍数
n |= n>>>1 的含义: n = n | n>>>1static final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
a >>> b的含义:将a向右移动b指定的位数,多出的高位用0部位,溢出的低位舍弃
因为1 | 1 = 1 ,1 | 0 = 1因此可以判定出经过右移之后,所有的低位值都会变为1,然后再+1,得到的值必然是2的倍数了。那么一开始第一行代码-1,就是为了防止自定义容量为2的倍数的情况5.为什么HashMap数组容量必须为2的倍数
实现节点均匀分布,避免hash冲突
当put数据计算主干数组索引位置时,计算公式为(容量-1)&hash。如果容量为2的倍数,那么容量-1之后得到的数二进制之后低位都是1,1和任何数进行&操作都不会影响原来的数,这样做可以尽可能的保证hash值不重复。因此最大程度避免了hash冲突6.HashMap插入流程
JDK1.7之前采用头插法,在高并发情况下会造成死循环问题
JDK1.8开始采用尾插法,解决了死循环的问题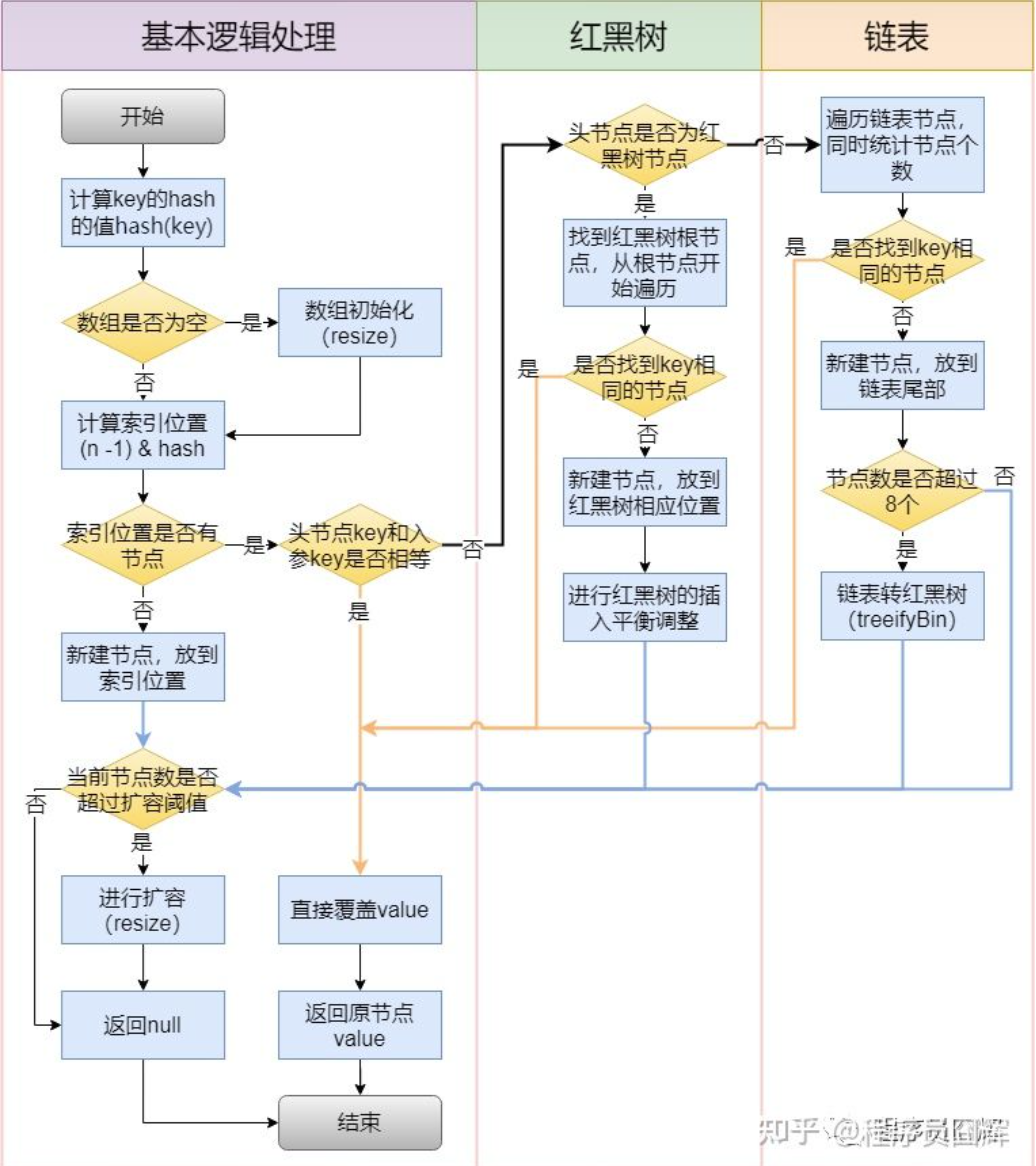
7.如何计算key的Hash值
获取key的HashCode,HashCode的高16位与HashCode进行异或操作
高16位参与运算,可以让计算索引位置时的Hash冲突概率进一步降低8.扩容流程
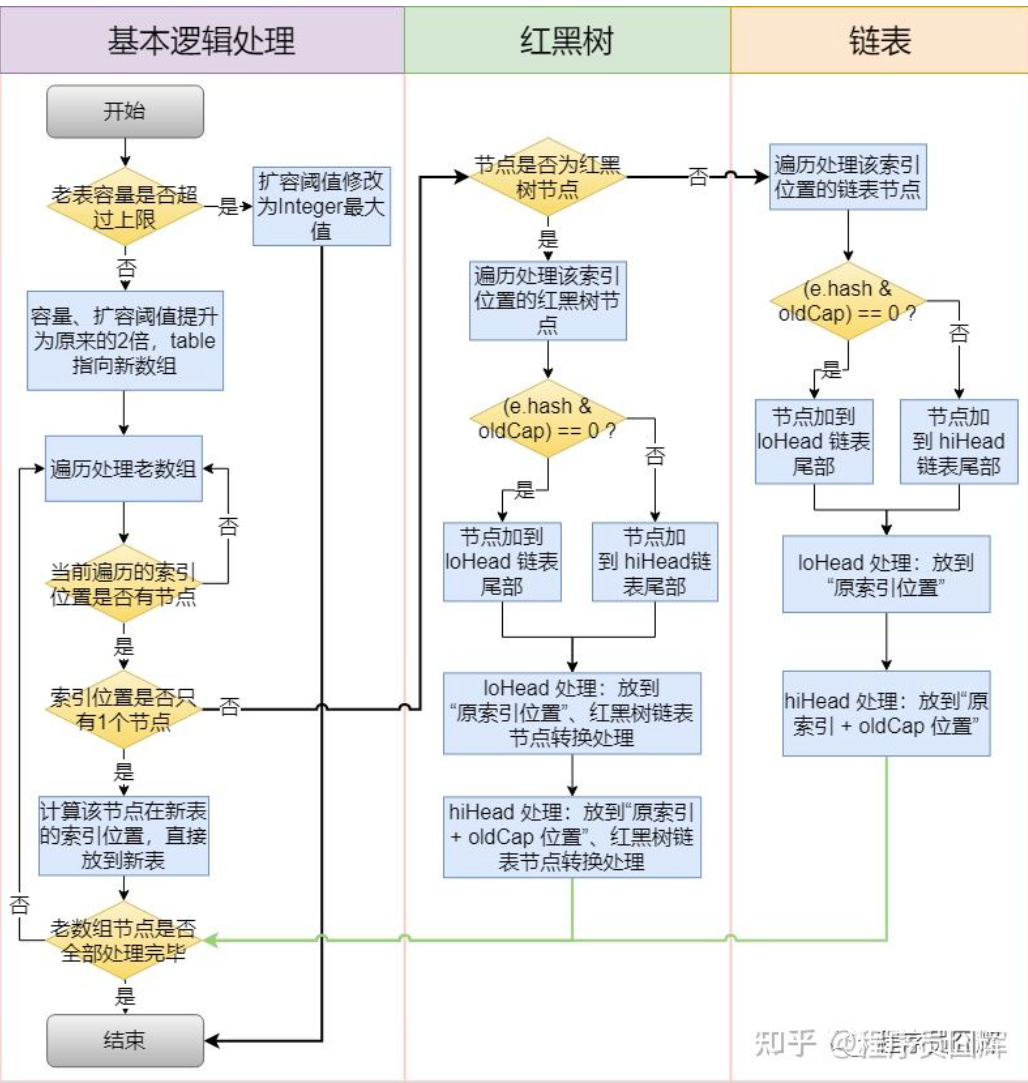
9.LinkedHashMap和TreeMap
| Map | 底层结构 | 排序规则 | | —- | —- | —- | | LinkedHashMap | 有序链表 | 按照键的存入顺序排序 | | TreeMap | 红黑树 | 默认按照Key的自然顺序升序排列(如果 key 没有实现 Comparable接口,则会抛异常),也可指定比较器(Comparator 比较器),通过重写 compare 方法来自定义排序 |
10.ConcurrentHashMap1.7原理
底层数据结构为Segment数组,Segment继承了ReentrantLock。可以理解为每一个Segment都是一个线程安全的HashMap,多个Segment组成了ConcurrmentHashMap。
因此在put时需要计算两次hash值来进行存入,第一次hash计算segment位置,第二次计算segment里面hash桶的具体位置
此时锁粒度为分段级别,还没细化到具体节点。
初始Segment节点个数为16
11.ConcurrentHashMap1.8原理
底层数据结构与HashMap相同,都是数组+链表+红黑树。另外在put值得时候采用了CAS算法以及Sync关键字。
但是1.8的Entry被封装在了一个Node对象中,Node对象里面的value,next指针都是被volatile关键字修饰的。volatile实现了线程之间的变量的可见性。
因此1.8的get方法不需要加锁。

若有收获,就点个赞吧
0 人点赞
