:::color5 更新于2023年5月
:::
1、什么是ControlNet
ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。
用于控制稳定出图。
2、插件安装
方法一:如下图复制网址进行安装。
https://jihulab.com/hunter0725/sd-webui-controlnet

方法二:如上图方法安装失败,则用下图方法安装。
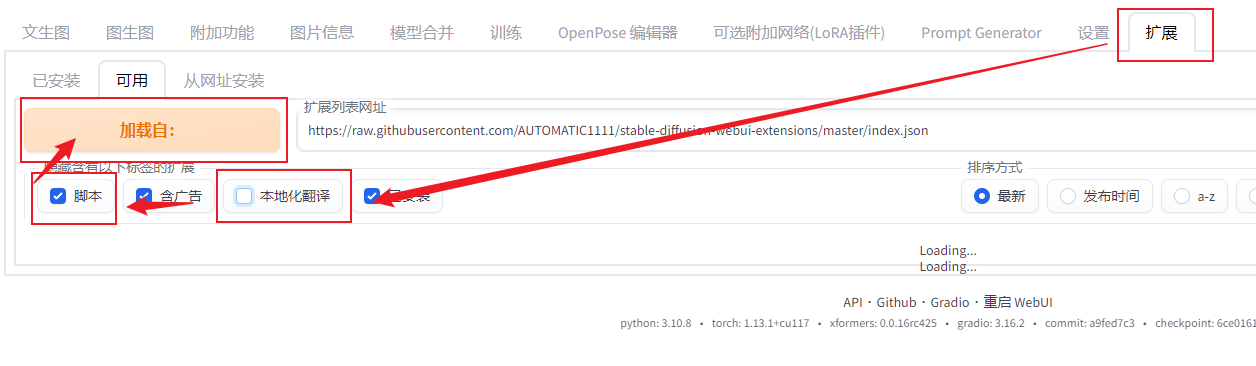

安装好了记得点重启界面。
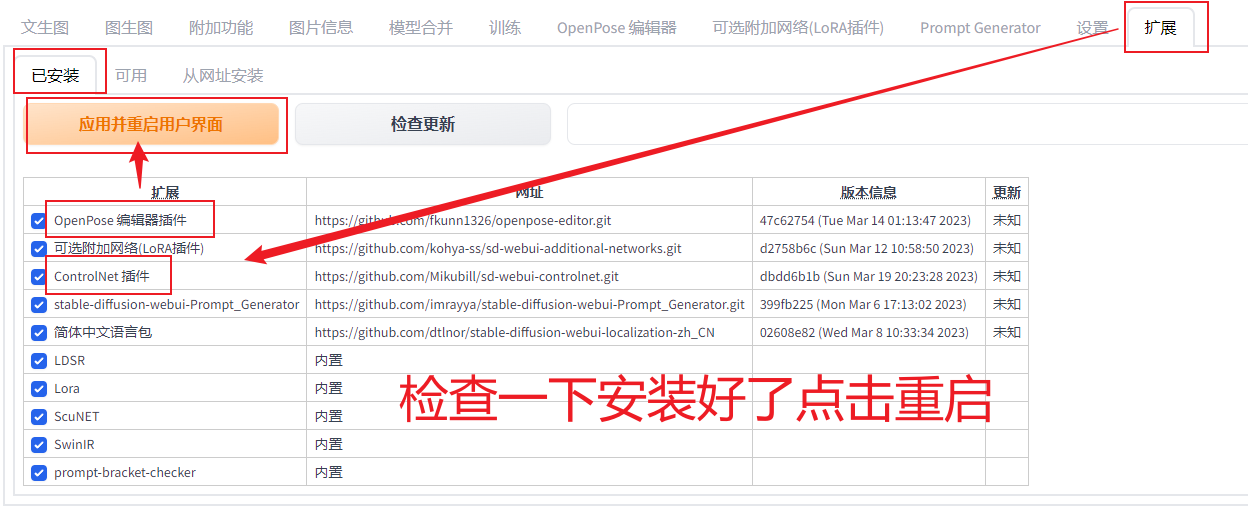
ControlNet 1.1模型与预处理器安装
(需要先安装controlnet插件,如已经安装需要升级插件)
接下来点击下方链接,下载所有的pth文件
lllyasviel/ControlNet-v1-1 at main
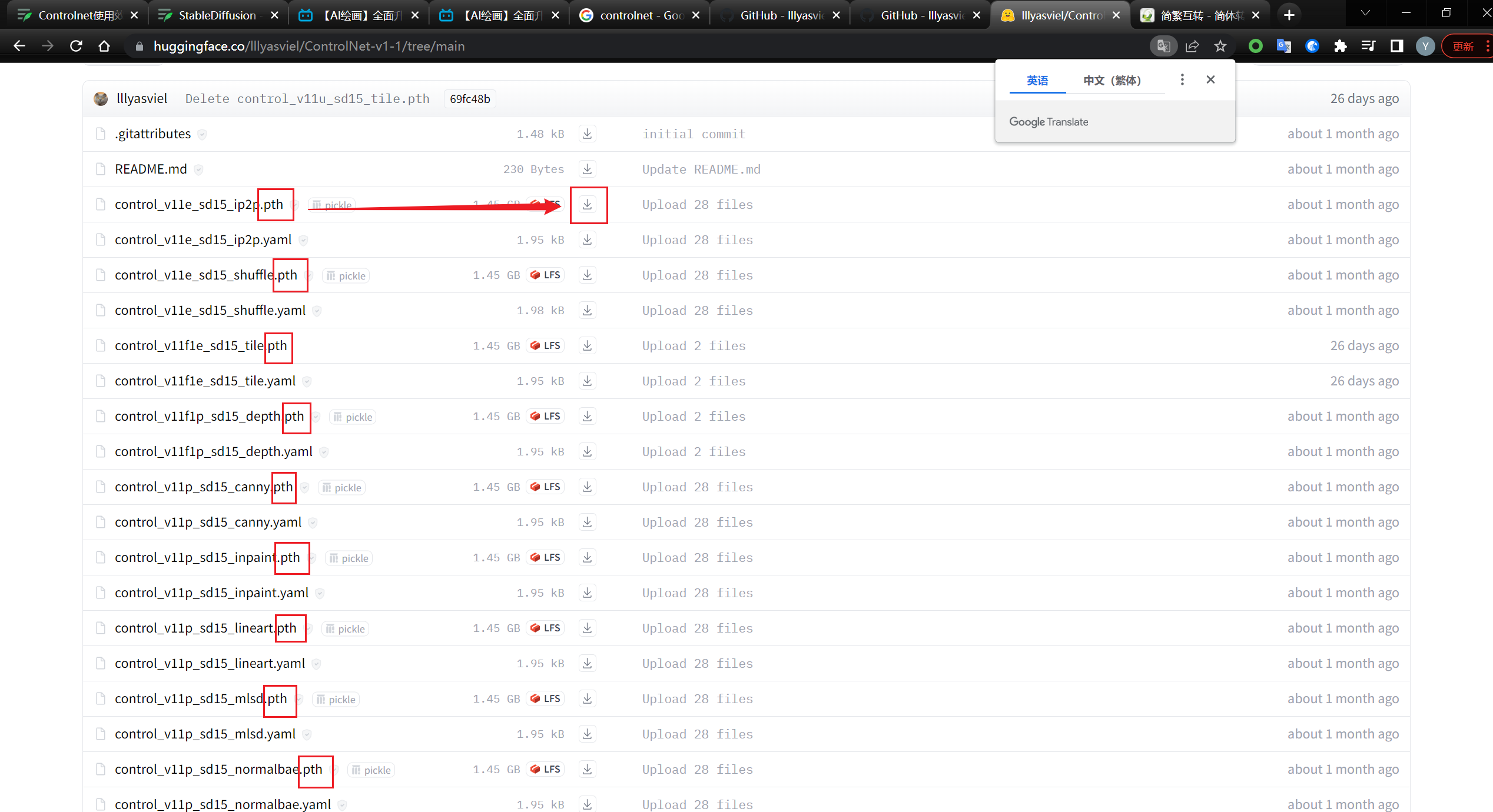
放置在models/controlnet文件夹
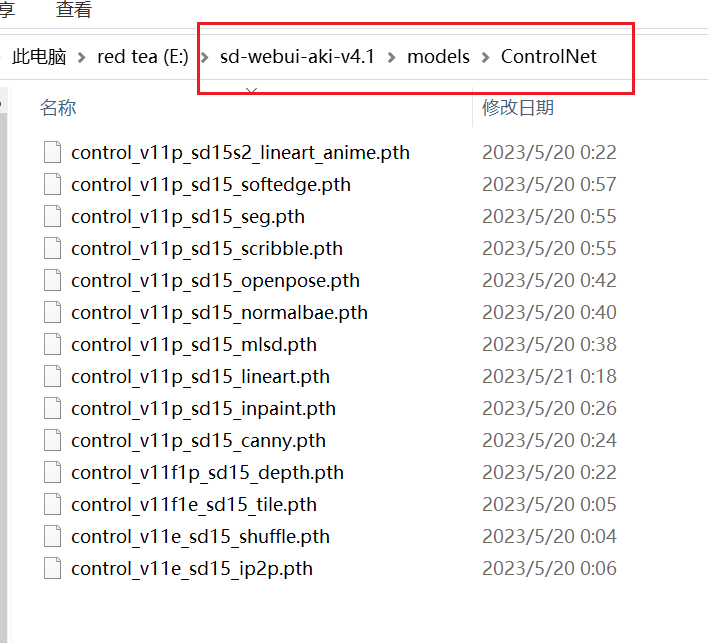
点击下方链接,下载所有的文件
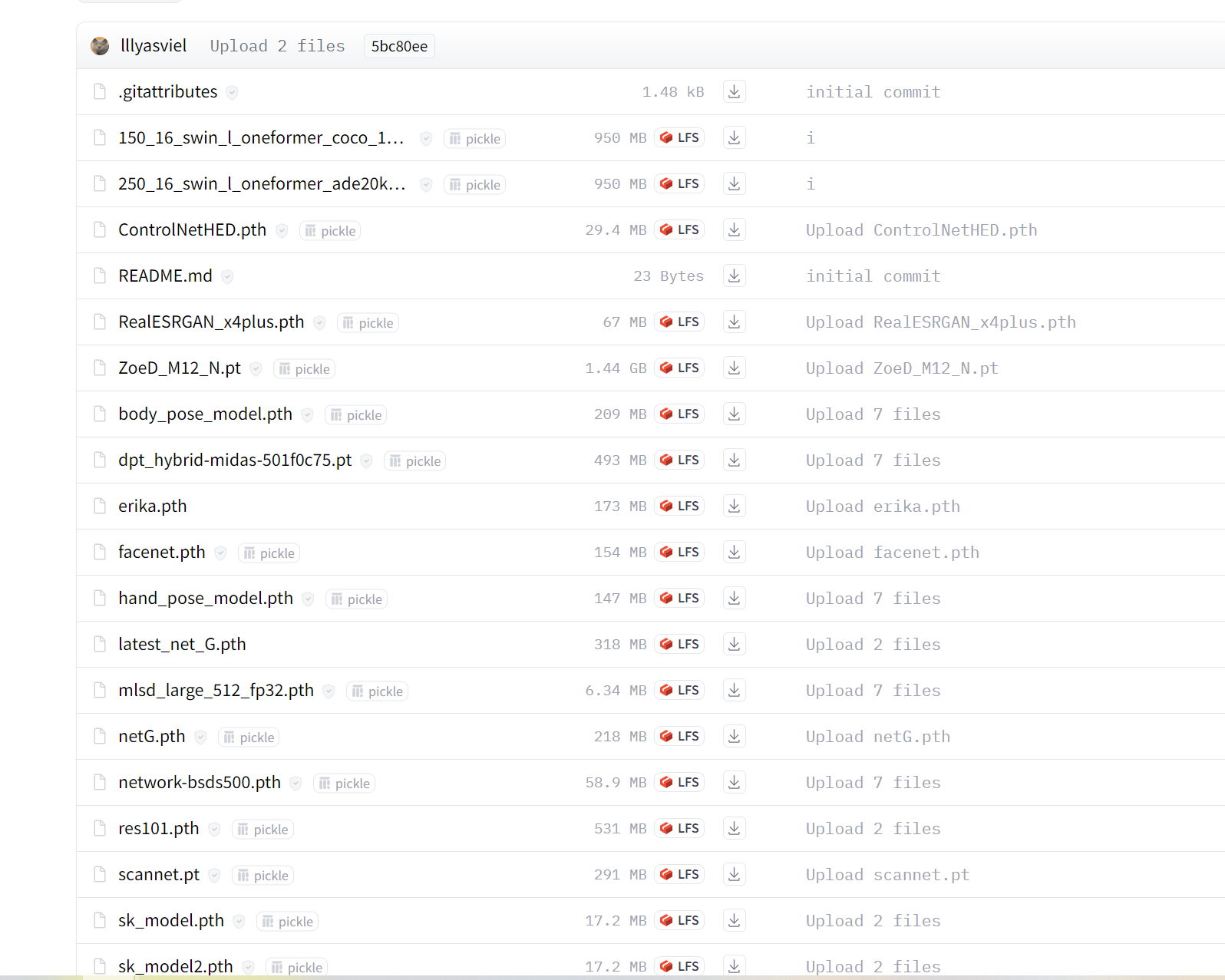
放置在extensions/sd-webui-controlnet/annotator文件夹内,文件比较散乱,可以多建一个文件夹放
3、Control Net 1.1种类
Depth
用深度图控制稳定扩散模型文件:control_v11f1p_sd15_depth.pth可接受的预处理器:Depth_Midas、Depth_Leres、Depth_Zoe 该模型可以处理来自渲染引擎的真实深度图。

Normal
使用法线贴图控制稳定扩散模型文件:control_v11p_sd15_normalbae.pth可接受的预处理器:Normal BAE 只要法线贴图遵循ScanNet 的协议,该模型就可以接受来自渲染引擎的法线贴图。也就是说,法线贴图的颜色应该看起来像这张图片的第二列。


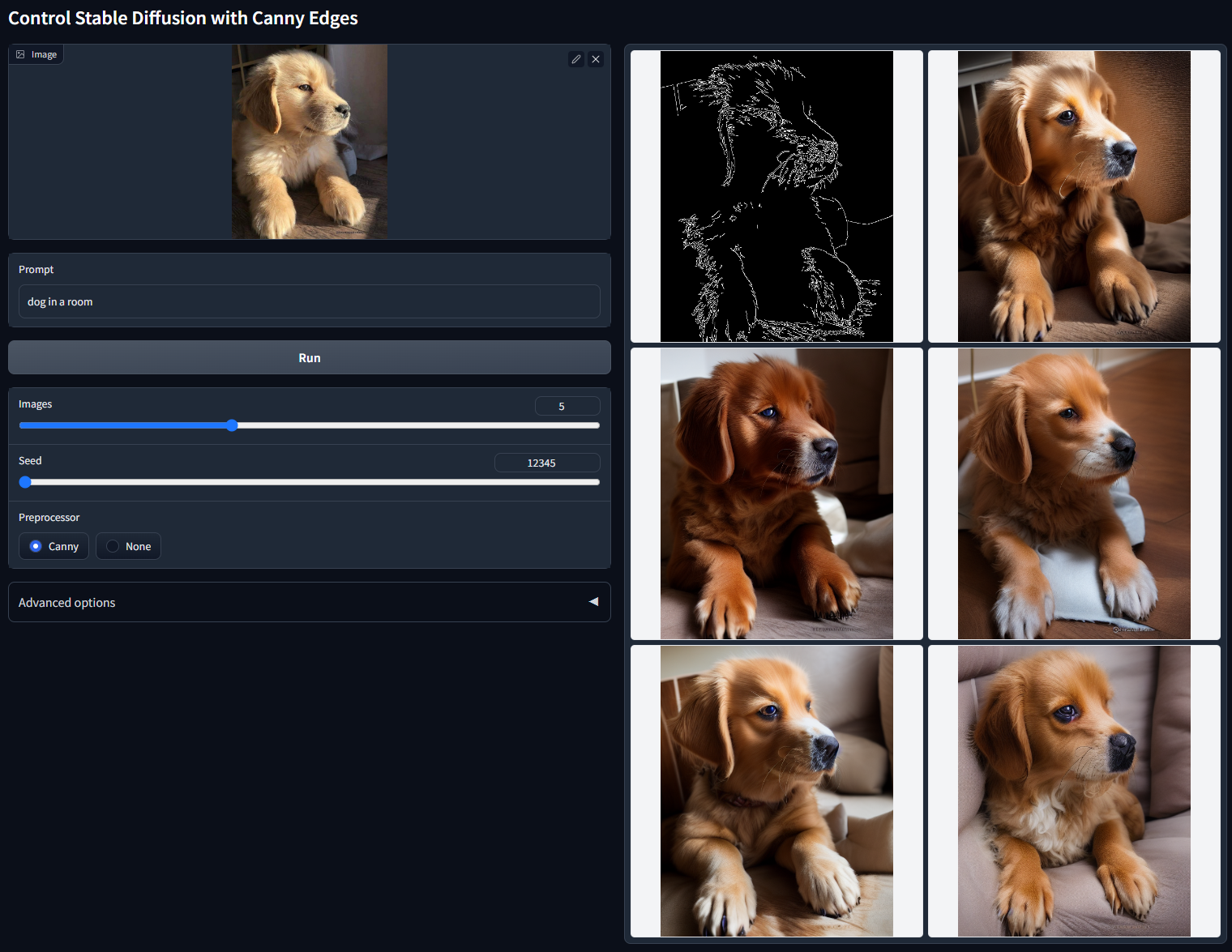
Canny
使用 Canny Maps 控制稳定扩散模型文件:control_v11p_sd15_canny.pth可接受的预处理器:Canny
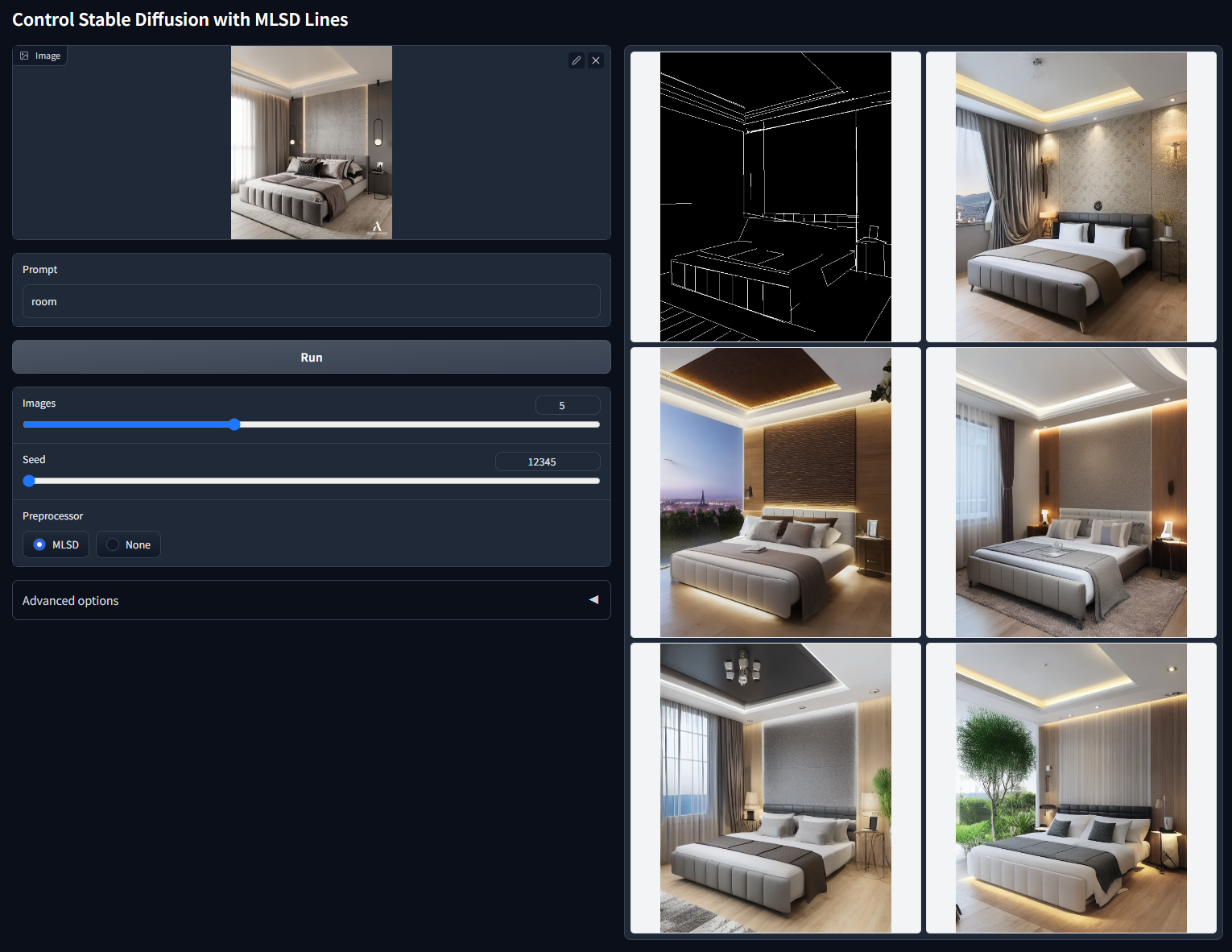
MLSD
用 M-LSD 直线控制稳定扩散模型文件:control_v11p_sd15_mlsd.pth可接受的预处理器:MLSD
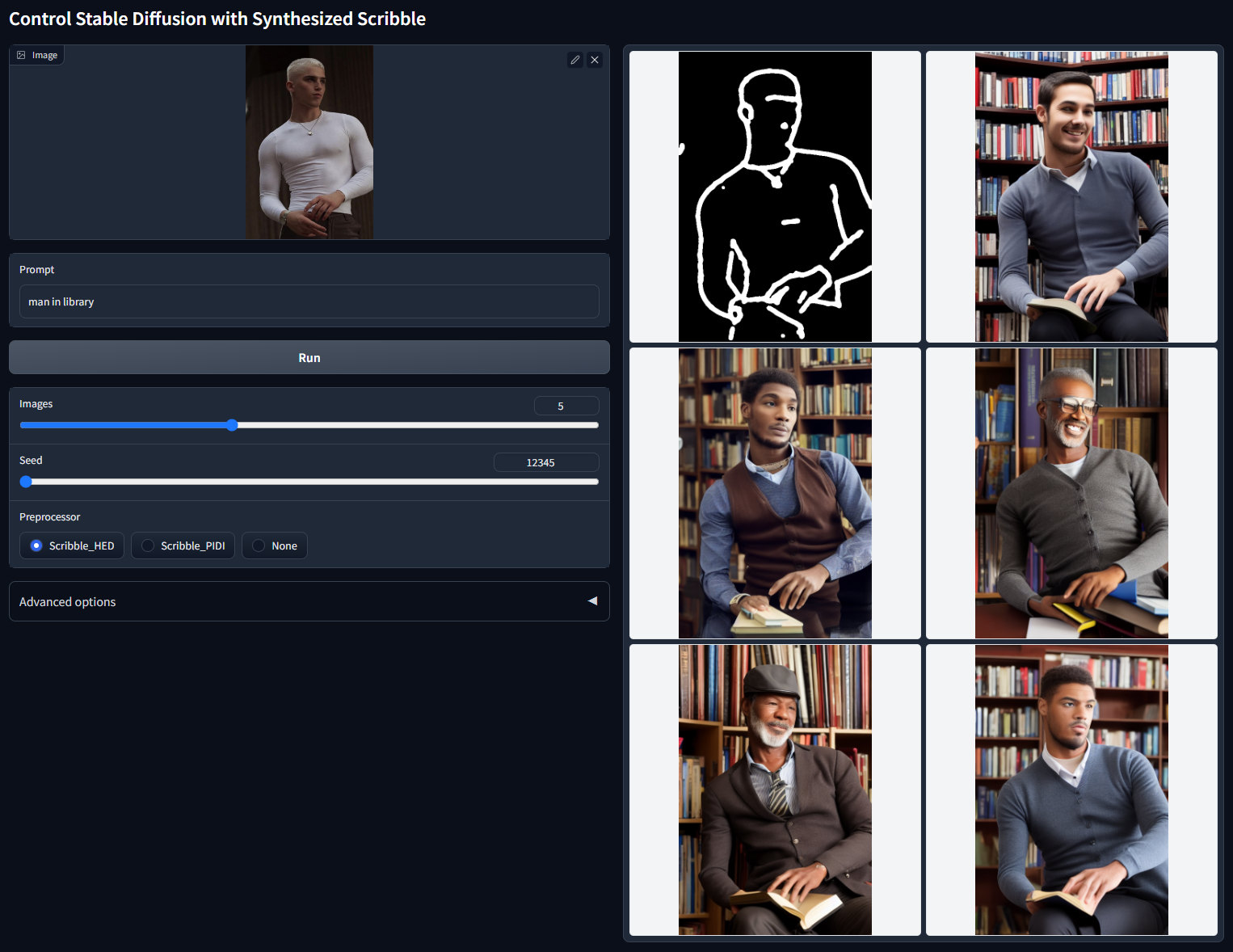
Scribble
用涂鸦控制稳定扩散模型文件:control_v11p_sd15_scribble.pth可接受的预处理器:Synthesized scribbles (Scribble_HED, Scribble_PIDI, etc.) 、hand-drawn scribbles

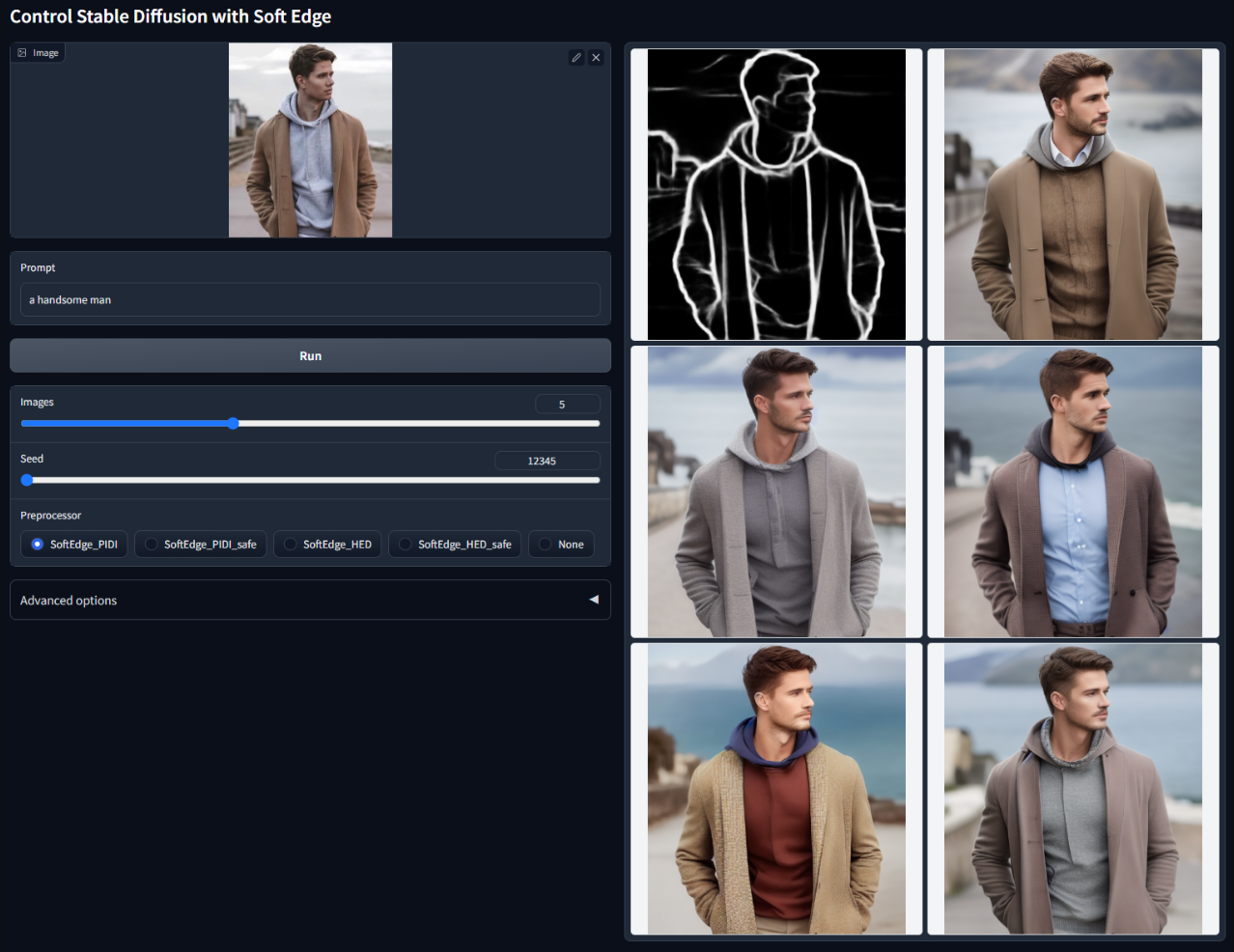
Soft Edge
使用软边缘控制稳定扩散模型文件:control_v11p_sd15_softedge.pth可接受的预处理器:SoftEdge_PIDI, SoftEdge_PIDI_safe, SoftEdge_HED, SoftEdge_HED_safe
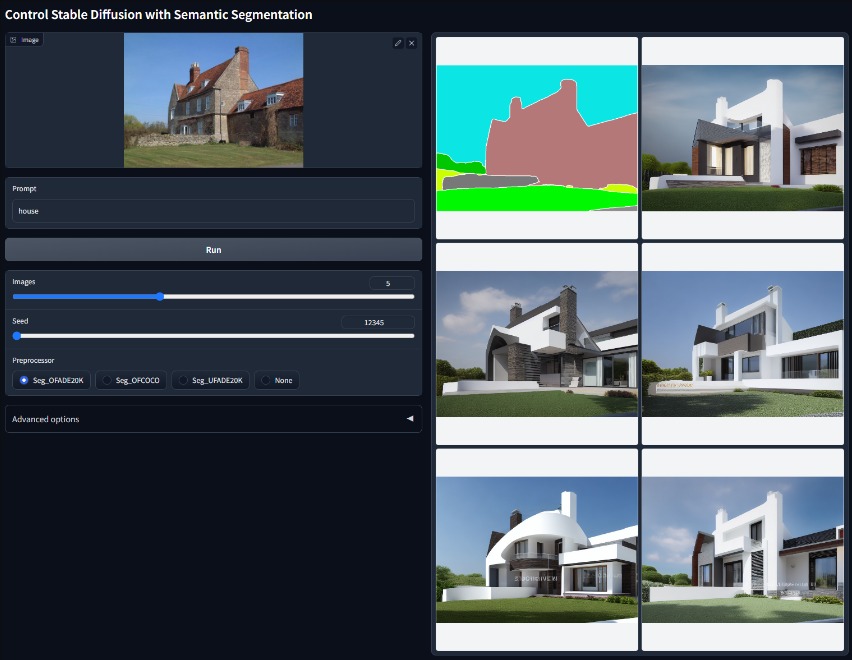
Segmentation
用语义分割控制稳定扩散模型文件:control_v11p_sd15_seg.pth可接受的预处理器:Seg_OFADE20K (Oneformer ADE20K)、Seg_OFCOCO (Oneformer COCO)、Seg_UFADE20K (Uniformer ADE20K)、manually created masks
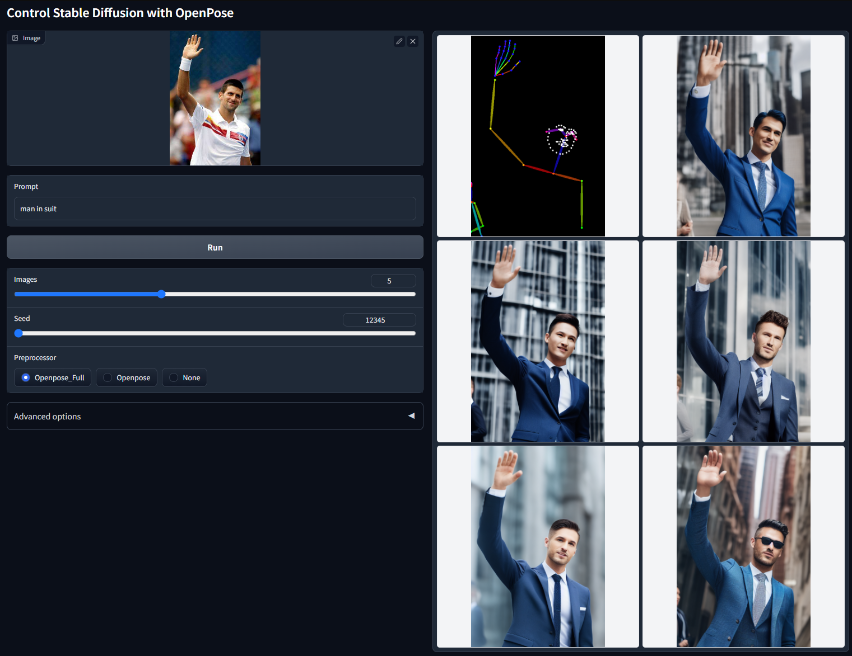
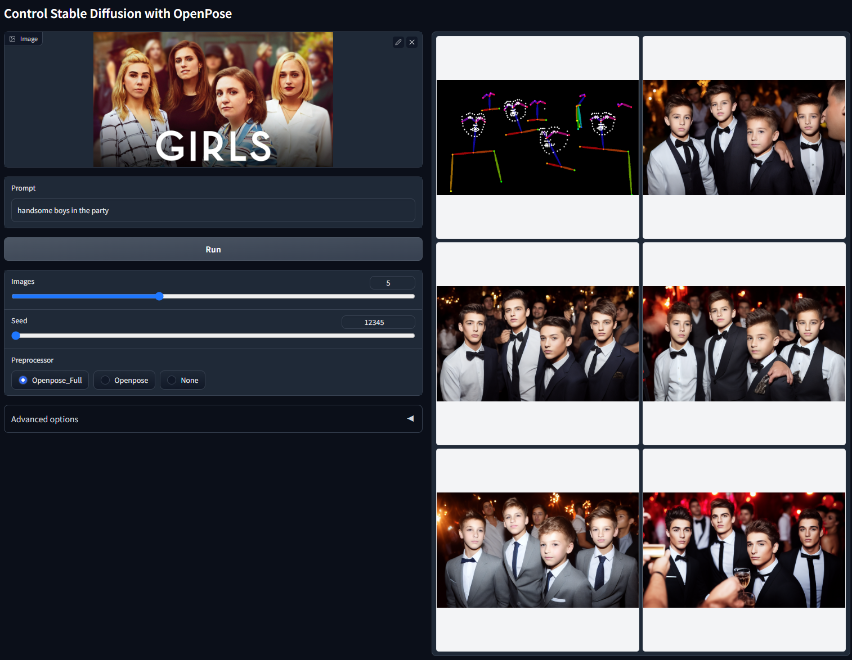
Openpose
使用 Openpose 控制稳定扩散模型文件:control_v11p_sd15_openpose.pth该模型经过训练,可以接受以下组合:
- “Openpose”= Openpose 身体
- “Openpose Full” = Openpose 身体 + Openpose 手 + Openpose 脸
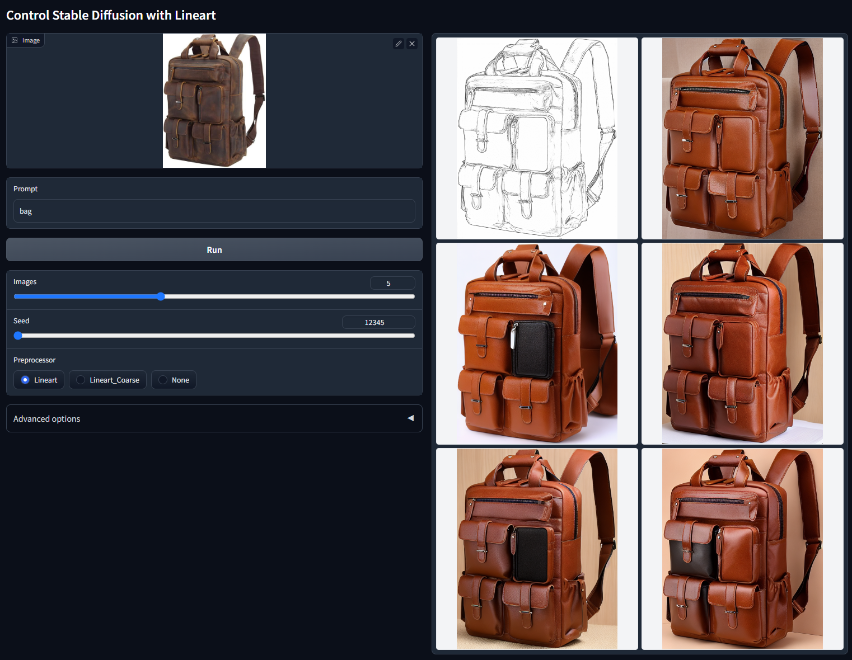
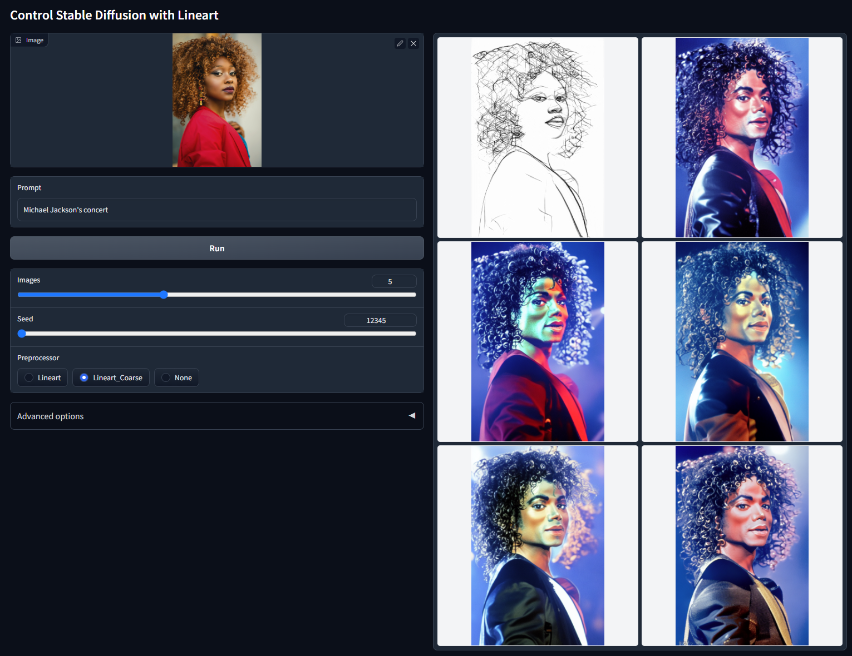
Lineart
用语义分割控制稳定扩散模型文件:control_v11p_sd15_lineart.pth该模型是在 awacke1/Image-to-Line-Drawings 上训练的。预处理器可以从图像(Lineart 和 Lineart_Coarse)生成详细或粗略的线稿。该模型经过足够的数据增强训练,可以接收手动绘制的线稿。
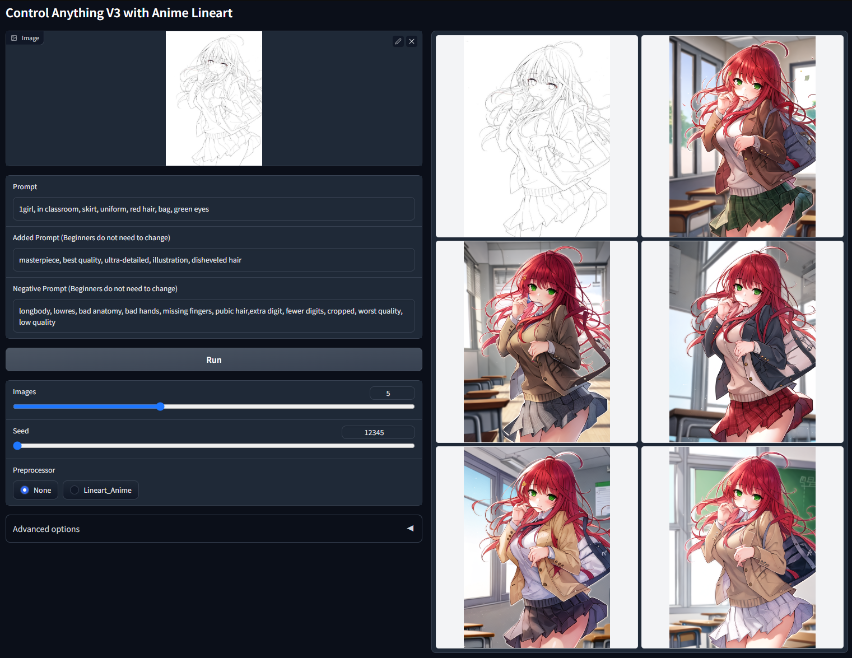
Anime Lineart
用动漫线稿控制稳定扩散模型文件:control_v11p_sd15s2_lineart_anime.pth该模型可以将真实的动漫线条图或提取的线条图作为输入

Shuffle
通过内容随机播放控制稳定的传播模型文件:control_v11e_sd15_shuffle.pth这个ControlNet可以通过提示或者其他ControlNet的引导来改变图像风格

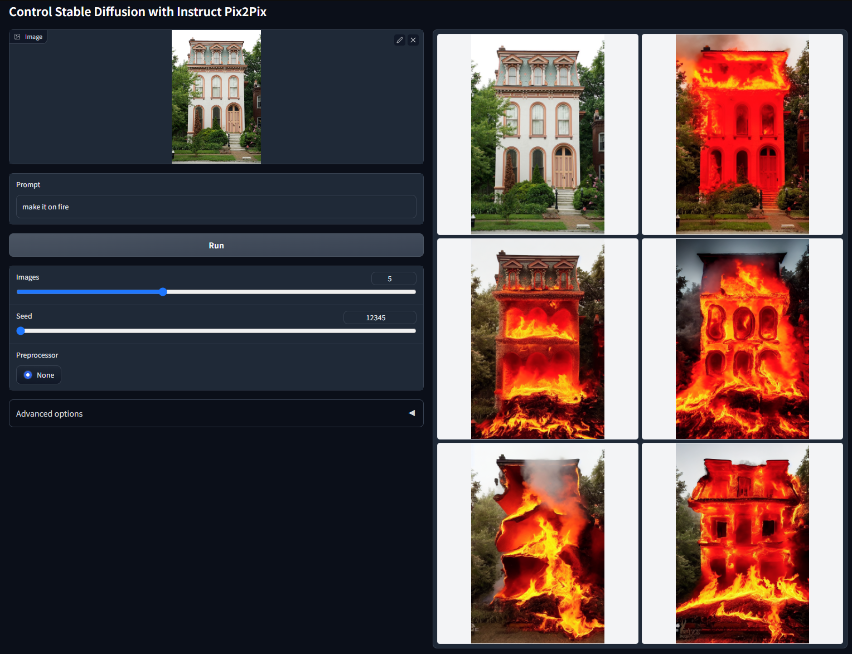
Instruct Pix2Pix
使用 Instruct Pix2Pix 控制稳定扩散。模型文件:control_v11e_sd15_ip2p.pth
在不大幅度改变画面大体的情况下改变部分画面内容

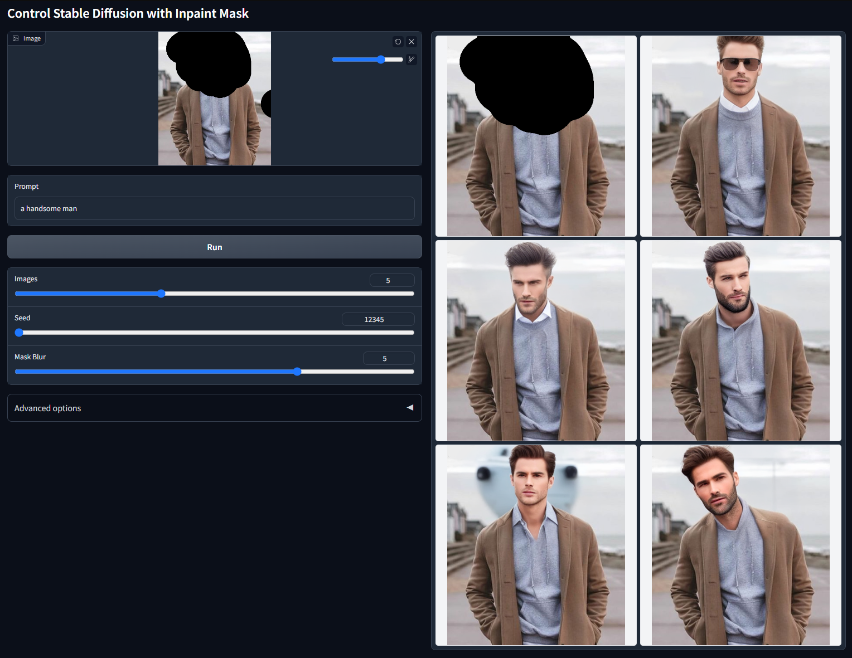
Inpaint
使用修复控制稳定扩散模型文件:control_v11p_sd15_inpaint.pth支持修复应用程序,还可以处理视频光流扭曲,类似局部重绘
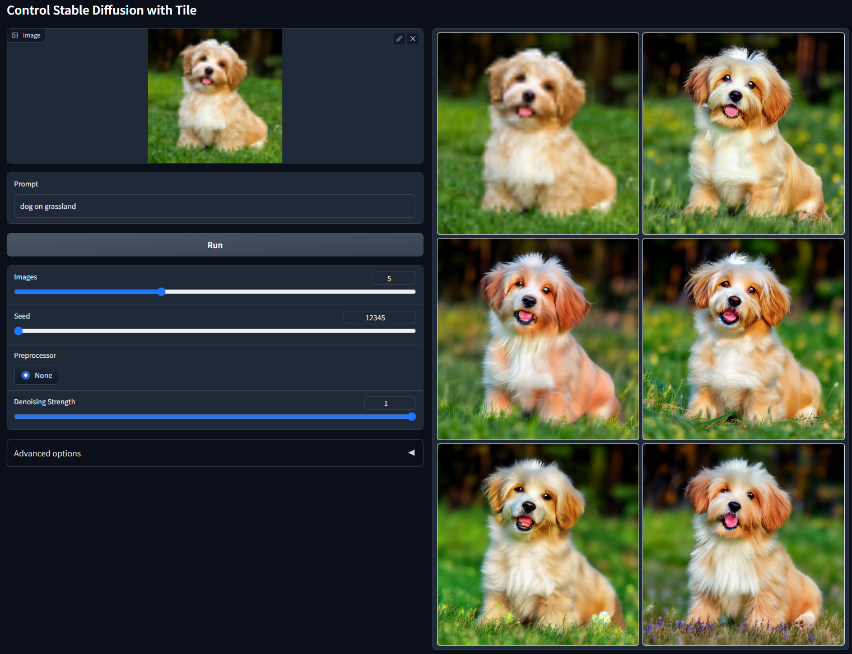
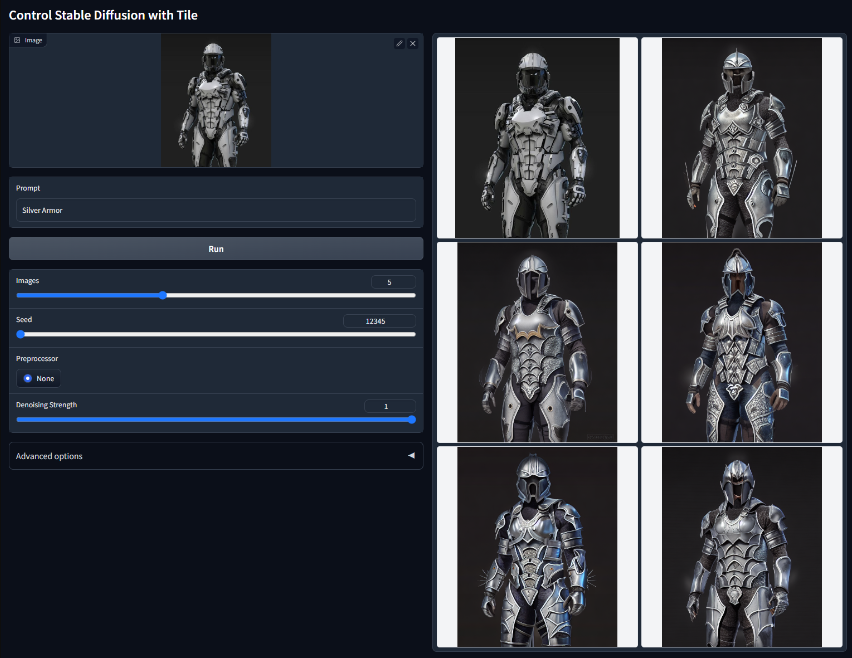
Tile
用Tile控制稳定扩散。模型文件:control_v11f1e_sd15_tile.pth该模型可以以多种方式使用。总的来说,该模型有两种行为:
- 忽略图像中的细节并生成新的细节
- 如果部分语义和提示不匹配,则忽略全局提示,并根据局部上下文引导扩散

若有收获,就点个赞吧
0 人点赞

{kind=link}