基本术语
- 属性张成的空间称为属性空间(attribute space)或样本空间(sample space),也称为输入空间。
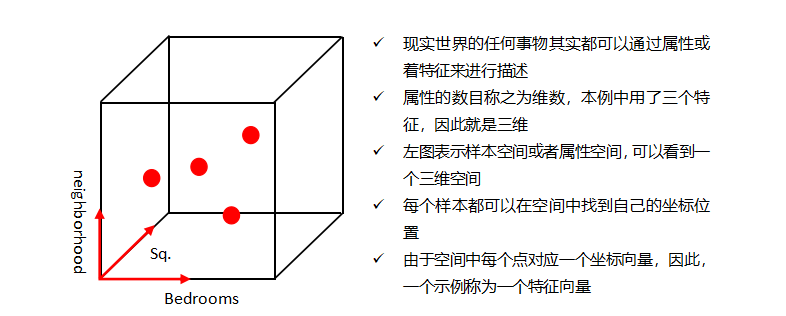
- 从数据中学得模型的过程称为学习(learning)或训练(training),训练过程中使用的数据称为训练数据(training data)。学得模型对应了关于数据的某种潜在的规律,因此称为假设(hypothesis)。这种潜在的规律知识,称为真相或真实(ground truth),学习的过程就是为了找出或逼近真实。模型有时被称为学习器(learner),可看做学习算法在给定数据和参数空间上的示例化。
- 机器学习在业界被分成三种类型,分别是监督学习、非监督学习和强化学习(集成学习)
区别:非监督式学习,数据集中没有明确的标记,需要通过算法找到暗含在数据背后的逻辑关系。在监督式学习回归任务中,数据集中包含标记信息(目标值),例如:线性回归的房价数据集中,Sale Price 具有明确的值。
机器学习中分类问题和回归问题是监督学习的代表,而聚类则是非监督学习的代表。
分类任务和回归任务
如果预测的值是离散的(比如图片的分类结果是猫或狗),此类学习任务称为分类(classification);对只涉及两个类别的叫做二分类(binary classification),通常其中一个类为正类(positive class),另一个类为反类(negative class)。涉及多个类别时,则称为多分类(multi-class classification)。
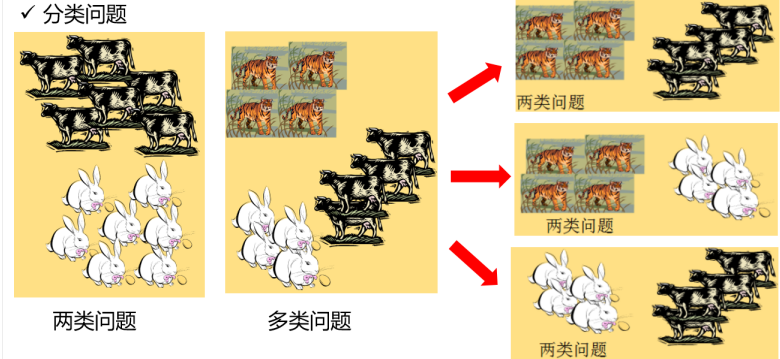
2.如果预测的值是连续的,比如房屋的价格25K,300K,此类任务称为线性回归(regression)。
泛化(generalization)能力
机器学习的目标是使学得的模型能很好的适用于新样本,即不仅在训练样本上工作得很好,在新的样本上同样适用,称为泛化(generalization)能力。具有强泛化能力的模型能够很好地适用于整个样本空间。如何衡量一个模型具备泛化能力能,衡量泛化能力的方式和指标如下:
1) 线性回归任务,使用均方误差MSE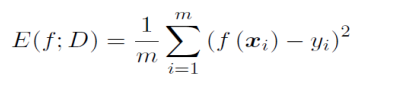
2) 分类任务,错误率和精度,如下:
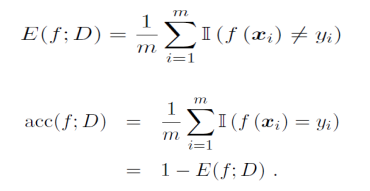
归纳和演绎
- 归纳(induction)和演绎(deduction)是科学推理的两大基本手段。
- 归纳是从特殊到一般的泛化(generalization)过程,即从具体的事实归结出一般性规律。
- 演绎是从一般到特殊的特化(specialization)过程,即从基本原理推演出具体状况。
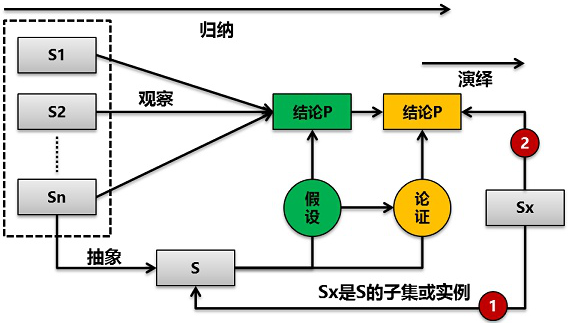
演绎推理是严格的逻辑推理,一般表现为大前提、小前提、结论的三段论模式:即从两个反映客观世界对象的联系和关系的判断中得出新的判断的推理形式。
例如三段式演绎推理:
知识分子都是应该受到尊重的,人民教师都是知识分子,所以,人民教师都是应该受到尊重的。可以描述为抽象的S-》结论P,而如果某个具体的S1是属于S的,那么S1必然满足结论P。
机器学习是:从样例中学习,显然是一个归纳的过程,也称为归纳学习(inductive learning)。
Q:


归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好,称为归纳偏好(inductive bias)。比如在回归学习中,每个训练样本是图中的一个点(x,y),要学得一个与训练集一致的模型,相当于找到一条穿过所有训练样本点的曲线。显然,对有限个样本点组成的训练集,存在多条曲线与其一致。我们的学习算法必须有某种偏好,才能产出它认为正确的模型。学习算法自身的归纳偏好与问题是否匹配,往往会起到决定性的作用。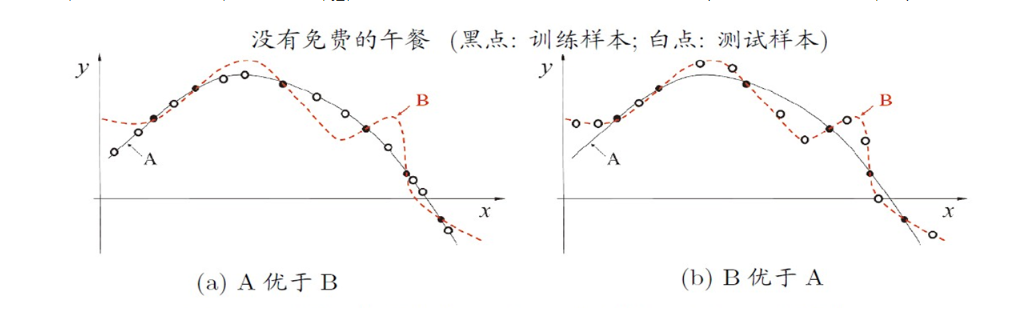

解析:
合适的特征应该是具体且可量化的。美观程度是一种过于模糊的概念,不能作为实用特征。美观程度可能是某些具体特征(例如样式和颜色)的综合表现。样式和颜色都比美观程度更适合用作特征。用户可能只是想要详细了解他们喜欢的鞋子。因此,用户点击次数是可观察且可量化的指标,可用来训练合适的标签。喜好不是可观察且可量化的指标。我们能做到最好的就是针对用户的喜好来搜索可观察的代理指标。鞋码是一种可量化的标志,可能对用户是否喜欢推荐的鞋子有很大影响。
总结
机器学习一些重要的概念:
Ø 样本是关于一个事件和对象的描述
Ø 多个样本构造成了数据集
Ø 反应事件和对象在某方面的表现或性质的事项,称为属性,属性的取值为属性值,可以是连续值和分类值
Ø 数据集中所有属性张成的空间称为属性空间、样本空间或输入空间
Ø 在样本空间中,由于空间中每个点对应一个坐标向量,因此,一个示例或样本称为一个特征向量
Ø 从数据中学得模型的过程称为学习或训练,训练中使用的数据集称为训练集,用来验证和评估模型的数据称为测试集
机器学习的分类:
Ø 如果数据集中包含有标记信息,那么使用这个数据集进行训练得到模型的过程称为监督学习
Ø 数据集不包含标记信息,使用算法找到数据集之间的潜在的逻辑关系,称为非监督学习
假设空间和归纳偏好:
Ø 模型属于由输入空间到输出空间的映射的集合,这个集合就是假设空间
Ø 机器学习算法在学习过程中对某种类型假设的偏好,称为归纳偏好
模型评估:
Ø 线性回归的模型评估指标是mse
Ø 逻辑回归的模型评估指标是预测准确度
线性模型(线性回归)
- 变量之间的关系一般来说,可分为确定性和非确定性两种:确定性关系可以用函数关系来表达,非确定性关系称为相关关系。对相关关系的研究使用回归分析这种数学工具,帮我们从一个变量或多个变量取得的值去估计另一个变量所取的值。
- 线性回归研究的是不确定性关系,意味着,我们不能准确的求得参数的值,求得的只是参数的最优值。
- 拟合线本质就是所有给定x得到所有的预测值y形成的直线
-
残差平方和及MSE
在机器学习中,一般在残差平方和的基础之上,除以分母m,即样本的数量,这样就形成了机器学习的优化目标,称为均方误差(Mean Square error,MSE)。
- 所以,在线性回归中,我们采用均方误差值作为损失函数,也称为代价函数。则有下面的数学表达式:
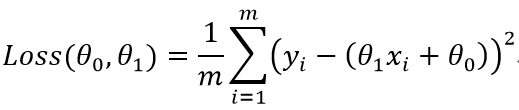
m表示样本的数量,yi表示每个样本的目标值,xi表示每个样本中特征的取值,θ0和θ1表示需要求取的参数值。在初始化这2个值的时候,一般设置初值为0或1。
平方损失函数及求解
梯度
一阶优化算法:
- 使用各参数的梯度值来最小化或最大化损失函数j(θ),最常用的一阶优化算法是梯度下降算法
- 梯度是方向导数中最大的一个
- 从数学上我们知道,平方损失函数是个凸函数,典型的凸函数是U型的严格凸函数只有一个局部最低点,该点也是全局最低点。经典的 U 形函数都是严格凸函数
- 梯度是对每个变量求偏导
-
Q:
机器学习损失的数学表达称为损失函数(代价函数)。线性回归模型使用的是一种称为平方损失(又称为 L2 损失)的损失函数。单个样本的平方损失如下:
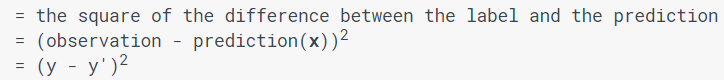
那么关于均方误差(MSE)作为损失函数说法正确的是?(ABC)
A. 要计算全部的训练样本的平方损失,需要把每个样本的平方损失求和
B. 所有训练样本的平方损失和除以样本的数量,得到单个样本的平均损失
C. 假设数据集D中包含N个样本,则应用上面的公式,MSE的公式表达如下图所示: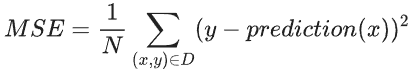
梯度下降算法
最小化风险函数
- 会计算损失曲线在起点处的梯度

梯度下降算法的流程:1.随机选取一个起点2.求斜率,根据斜率判断方向3.挪动步长
学习率
学习率α的大小直接决定着每次更新的挪动大小。如果α太小,那么每次挪动的距离只会一点一点挪动,这样就需要很多步才能到达最低点。
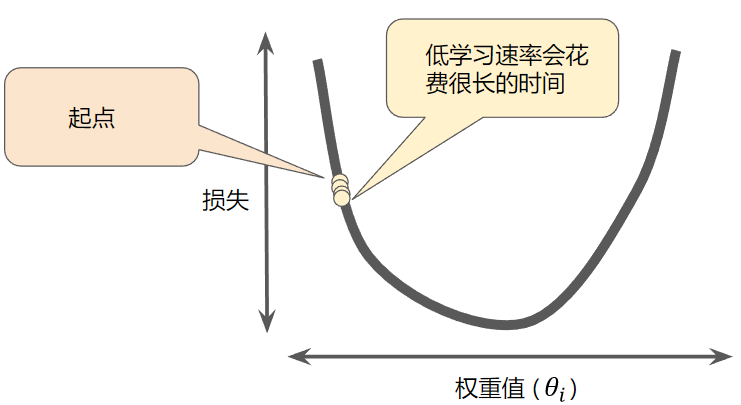
- 相反,如果您指定的学习速率过大,下一个点将永远在 U 形曲线的底部随意弹跳。如下图:
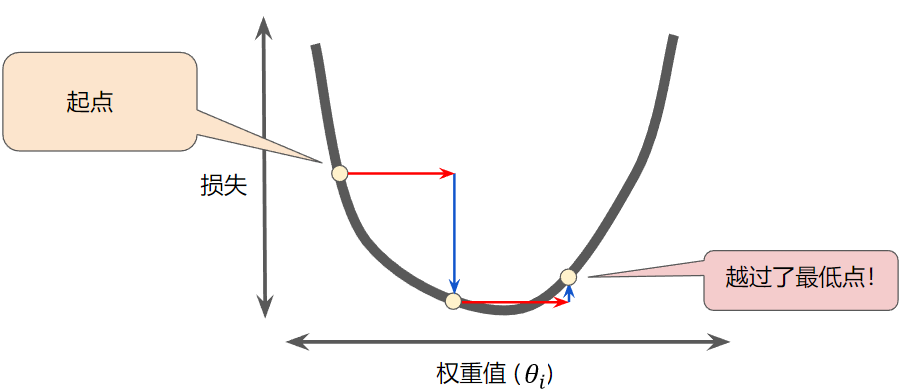
梯度的方向告诉我们哪个方向上升最陡(上图红线),幅度告诉我们上升/下降最陡(上图红线)。所以,在最小值处,当轮廓线几乎是平的,你会期望梯度几乎为零。事实上,它在极小点处恰好是0。
- 在实践中,我们可能永远不会精确地达到最小值,但是我们一直在接近最小值的平坦区域中振荡。当我们振荡这个区域时,损失几乎是我们能达到的最小值,变化不大因为我们一直在最小值附近跳跃。通常,当损失值没有在预先确定的数字(比如10或20次迭代)中得到改善时,我们就会停止迭代。当这样的事情发生时,我们说我们的训练收敛了,或者说收敛了。
- 如果您知道损失函数的梯度较小,则可以放心地试着采用更大的学习速率,以补偿较小的梯度并获得更大的步长。如下图所示:
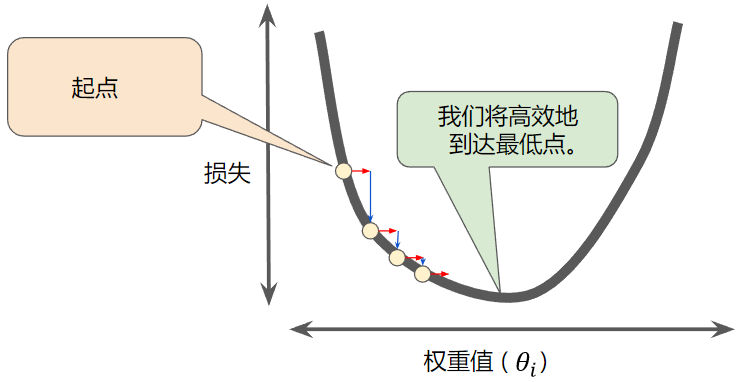
- 批量梯度下降算法能够得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果样本数目m很大,训练过程会很慢。整个的迭代过程如下图所示:
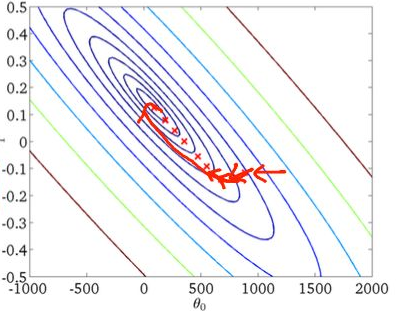
- 随机梯度下降法每次只使用一个样本的信息来更新参数,在样本很大的情况下,可能只用其中几万条或者几千条的样本,就已经将θ迭代到最优解
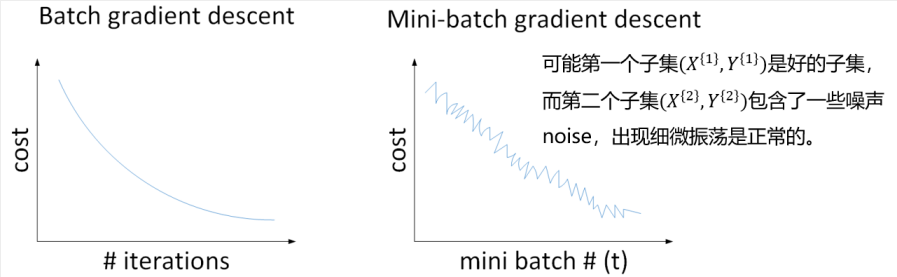
- 使用批量梯度下降,随着迭代次数增加,loss是不断减小的。然而,使用小批量梯度下降,随着在不同的mini-batch上迭代训练,其loss不是单调下降,而是受类似noise的影响,出现振荡。但整体的趋势是下降的,最终也能得到较低的loss值。
批量梯度下降和小批量梯度下降的代价曲线对比如下图所示:
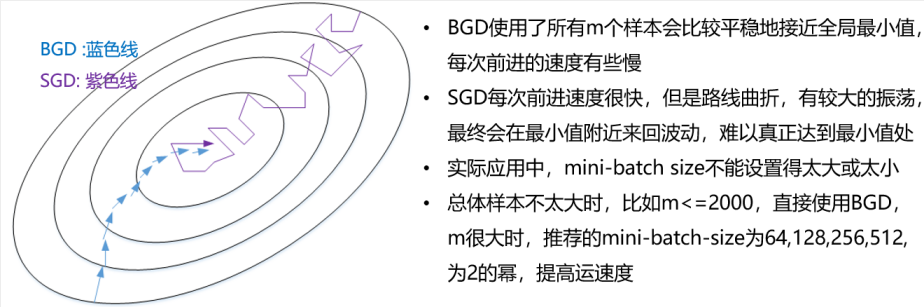
BGD和SGD的梯度下降曲线比较:
Q:

解析:
线性回归和逻辑回归中,关于损失函数对权重系数的偏导数是一样的。
多元线性回归
多元线性回归问题的解决,借助于科学库的矩阵运算更容易实现
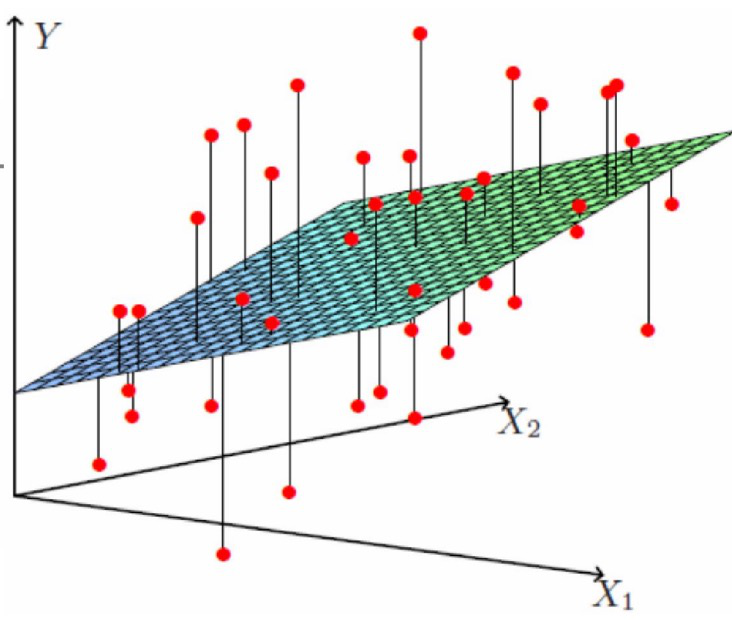
- 前面学习的一元线性回归是多元线性回顾的一个特例,是从多个特征中选择其中的一个。真实的应用场景中,特征的个数比较多,问题越复杂,特征的个数越多。针对多元线性回归,其问题的解决思路和一元线性回归一样,模型参数的求解过程除了使用逆矩阵之外,依旧采用梯度下降算法。在三维空间,拟合线变成一个面,如下图所示:
针对代价函数的公式: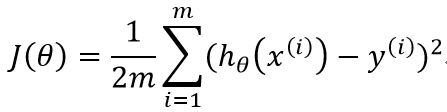
转换成python代码的表示为:
theta = np.zeros(X.shape[1])h_theta = numpy.dot(X, theta)delta =h_theta - ysquare_sum = np.dot(delta .T , delta )cost = square_sum / (2 * m)
批量梯度下降算法求解多元线性回归
多元线性回归中,需要求取的参数如下: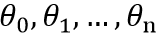
批量梯度下降算法的模型如下: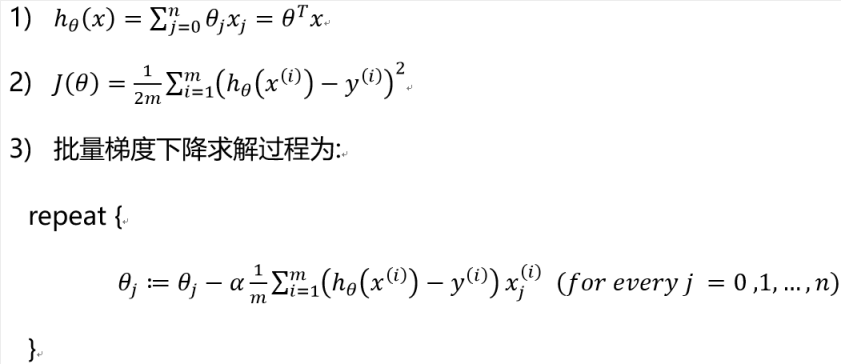
那么,实现过程如下:
式3)中的第一步,使用代码实现如下:
h_theta = np.dot(X, theta)eta = h_theta- yinner = np.dot(X.T, eta)m = X.shape[0]gradient = inner / m
Q:
在多元线性回归中,假设所有的特征组成的特征向量为X,所有的目标值组成的向量为Y,需要求取得参数向量为θ,则下面关于多元线性回归梯度下降说法正确的是?(ABCD)
A.
B.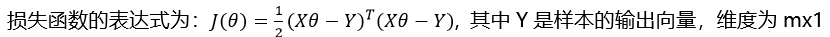
C.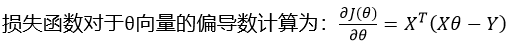
D.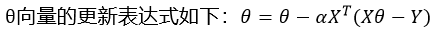

关于梯度下降法大家族中的BGD,SGD,MBGD,下面说法正确的是?(ABCD)
A. 三种梯度更新公式如下: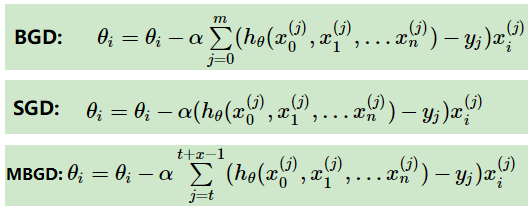
B. BGD和SGD的唯一区别是:没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度
C. 对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意
D. 对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优,对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
关于梯度下降法和最小二乘法相比,下面的说法正确的是?
A. 梯度下降法需要选择步长,而最小二乘法不需要
B. 梯度下降法是迭代求解,最小二乘法是计算解析解。如果样本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有优势,计算速度很快。但是如果样本量很大,用最小二乘法由于需要求一个超级大的逆矩阵,这时就很难或者很慢才能求解解析解了,使用迭代的梯度下降法比较有优势。
C. 梯度下降法和牛顿法/拟牛顿法相比,两者都是迭代求解,不过梯度下降法是梯度求解是一阶求解算法,而牛顿法/拟牛顿法是用二阶的海森矩阵的逆矩阵或伪逆矩阵求解。相对而言,使用牛顿法/拟牛顿法收敛更快。但是每次迭代的时间比梯度下降法长。
- 垂直坐标用于最小二乘拟合,假设水平轴为自变量,垂直轴为因变量。
最小二乘法的原则是以“残差平方和最小”确定直线位置,模型系数应该使计算出来的函数曲线与观察值的差的平方和最小。一般将残差看作垂直坐标,正交坐标在PCA的例子中很有用
总结线性模型
Ø 线性模型是通过各个属性的线性组合来进行预测,形式简单,易于建模,涵盖了机器学习中一些重要的基本思想
Ø 功能更加强大的非线性模型可以在线性模型的集成之上通过引入层级结构或高维映射得到,从这个意义上来说,线性模型是基础
线性回归
Ø 线性回归的任务是通过线性模型进行预测,预测的值能够尽量准确地接近实际的值
Ø 尽量准确接近,转换为评估标准为MSE,它是个无量纲的数,本质上为0是最好的,但是达不到这个数,因此,MSE的值尽可能接近0,但是不能为0
Ø 线性回归的任务中,模型参数值的求取可以使用通过计算逆矩阵的方式求得,因为引入的最小二乘法函数是个凸函数,但在真实的应用场景中用的最多的还是通过多次迭代逼近最优的值的梯度下降算法
梯度下降算法的总结:
Ø BGD: 每次迭代使用全部样本
Ø SGD: 每次迭代使用一个样本
Ø MBGD: 每次迭代使用b个样本线性模型(逻辑回归)
-
阶跃函数和对数几率函数
单位阶跃函数”(unit-step function)的定义如下:
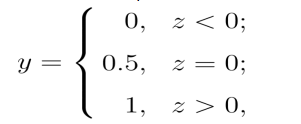
从定义上来看,这是一个分段函数,意味着图像不连续,我们的期望是找到一个数学性质很好的函数,单调可微,可导。
我们发现对数几率函数 (logistic function),简称“对率函数”能够满足我们的要求。其定义如下: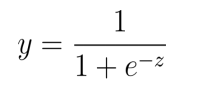
把阶跃函数对对率函数的图像表示在同一个坐标系中,如下图所示:
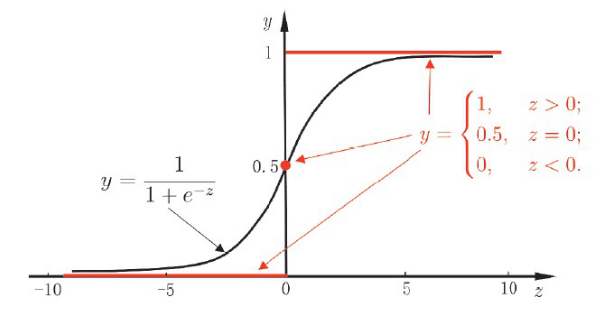
从图像上可以看出,对率函数在z=0附近变化很陡,当z=0时,函数值为0.5。对数几率函数在机器学习中应用比较广泛
逻辑函数
- 逻辑回归使用的假设函数是sigmoid函数,也即对数几率函数(Logistic Function),逻辑回归也因此而得名。为何叫做对数几率呢?
- 若将y视为样本X作为正例的可能性,则1-y是其为反例的可能性,两者的比值:y /(1-y)称为几率(odds),反应了x作为正例的相对可能性
- 对几率取对数,则得到对数几率(log odds,logit),即:
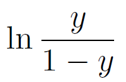
因此,将对数几率函数代入到广义线性回归模型中去,就得到了逻辑回归的数学原型了,即: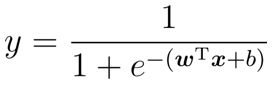
本质上是在用线性回归模型的预测结果取逼近真实标记的对数几率,我们通常称这个模型为对数几率回归(logistic regression,亦称logit regression)。名字上回归,本质上是分类学习方法。
与线性回归不同的是,逻辑回归由于其联系函数的选择,它的参数估计方法不再使用最小二乘法,而是使用极大似然法(maximum likehood method)来估计w和b。
极大似然估计
极大似然估计这种估计未知参数的方法,它建立在各样本间相互独立且样本满足随机抽样(可代表总体分布)下的估计方法,它的核心思想是:如果现有样本可以代表总体,那么最大似然估计就是找到一组参数使得出现现有样本的可能性最大,即从统计学角度需要使得所有观测样本的联合概率最大化,又因为样本间是相互独立的,所以所有观测样本的联合概率可以写成各样本出现概率的连乘积,如下式: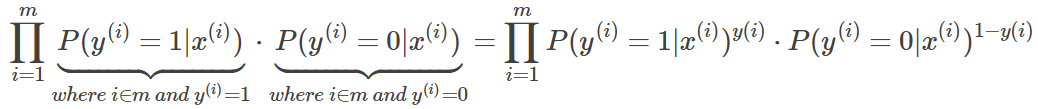
观察上式,可以看出,当y(i)=1和0时,上式分别等于为:
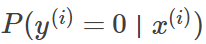
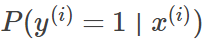
即为所有样本边际分布概率的连乘积,通常被称之为似然函数ℓ(θ),这里把多个w和b统一处理成参数θ。
因此,最大似然估计的目标是求得使得似然函数ℓ(θ)最大的参数θ的组合,理论上讲我们就可以采用梯度上升算法求解该目标函数(似然函数)的极大值。但是上式不是凸函数,在定义域内为非凸函数,具体形式如下: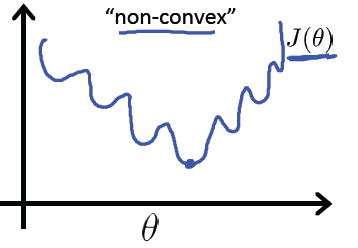
我们知道,之前线性回归可以采用梯度下降算法求解是因为线性回归的代价函数(均方误差函数)是凸函数,为碗状,而凸函数具有良好的性质(对于凸函数来说局部最小值点即为全局最小值点)使得我们一般会将非凸函数转换为凸函数进行求解。因此,最大似然估计采用自然对数变换,将似然函数转换为对数似然函数,其具体形式为: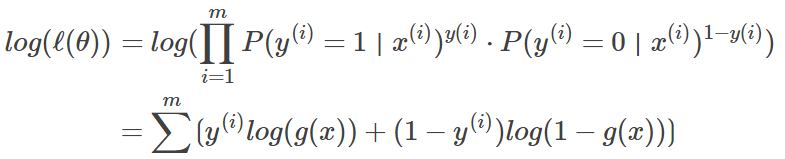
相对于求解对数似然函数的最大值,我们当然可以将该目标转换为对偶问题,即求解代价函数J(θ)=−log(ℓ(θ))的最小值。因此,我们定义逻辑回归的代价函数为:
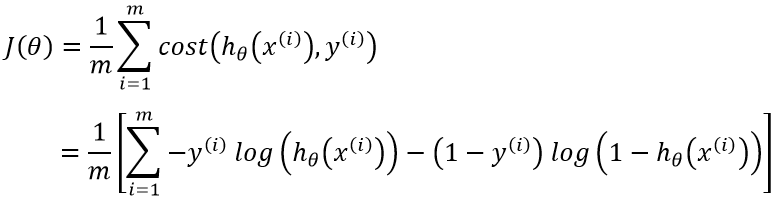
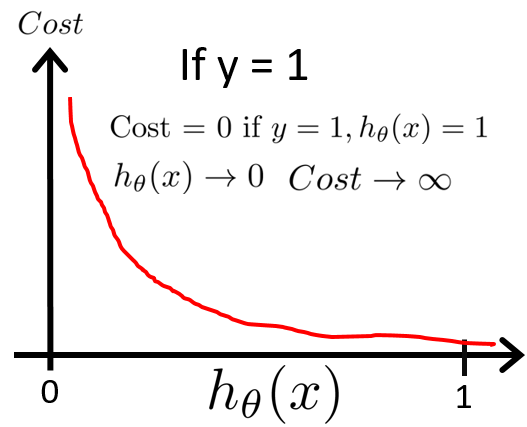
从代价函数的直观表达上来看,当y(i)=1,hθ(x(i))=1时(预测分类和真实分类相同):
当y(i)=1,hθ(x(i))->0时(预测分类和真实分类相反):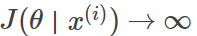
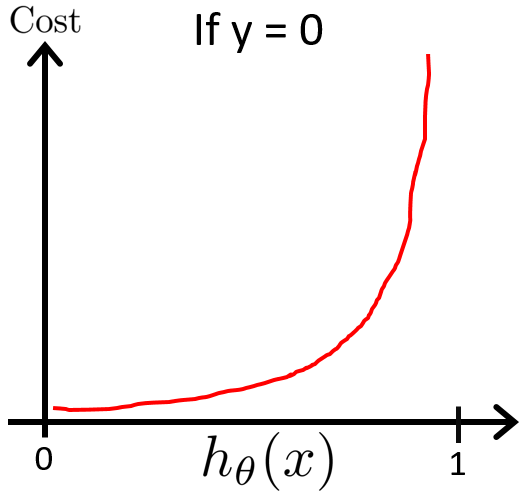
这就意味着,当预测结果和真实结果越接近时,预测产生的代价越小,当预测结果和真实结果完全相反时,预测会产生很大的惩罚,如下图左图所示,该理论同样适用于y(i)=0的情况,如下图右图所示:
极大似然估计参数估计
一旦,我们定义了逻辑回归的损失函数,我们自然而的选用梯度下降算法或者其他优化算法对目标函数进行求解。对于梯度下降算法,我们可以通过求解损失函数的一阶偏导数获得梯度,推导过程如下:
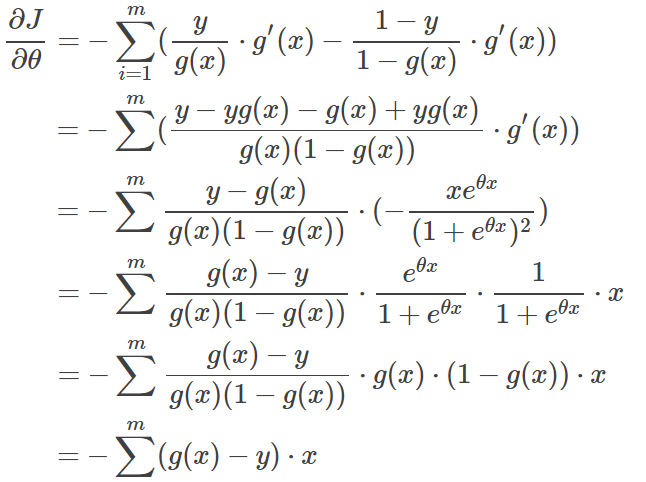
这里g(x)为sigmoid函数。
由此得到了梯度更新的表达式为: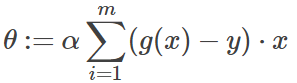
这里,alpha和线性回归一样,是学习率
不同学习率对loss的影响
学习率直接影响我们的模型能够以多快的速度收敛到局部最小值(也就是达到最好的精度)。一般来说,学习率越大,模型学习速度越快。如果学习率太小,网络很可能会陷入局部最优;但是如果太大,超过了极值,损失就会停止下降,在某一位置反复震荡。
如果我们记录每次训练迭代,画出相应的学习率(对数)和loss变化,我们可以发现,随着学习率不断提高,loss会在一段时间不断下降,并在触及最低点后开始回升。在实践中,最理想的学习率应该是使loss曲线到达最低点的那个值,以下图为例,图中模型的最佳学习率在0.001到0.01之间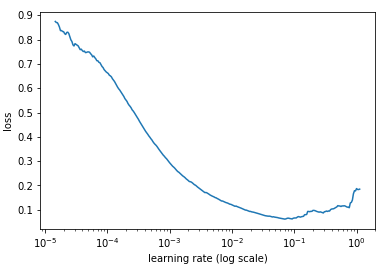
- 在线性回归中,我们学习了求解代价函数最小值的方法,梯度下降算法和正规方程两种方法可以求解
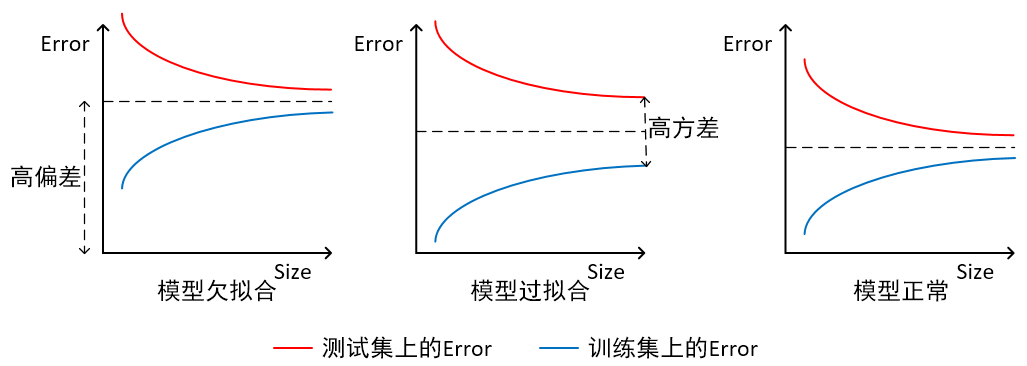
- 偏差和方差是两个相对的概念,就像欠拟合和过拟合一样。如果模型过于简单,通常会造成欠拟合,伴随着高偏差、低方差;如果模型过于复杂,通常会造成过拟合,伴随着低偏差、高方差
- 如果我使用数据集的全部特征并且能够达到100%的准确率,但在测试集上仅能达到70%左右,这说明:过拟合
- 假如我们利用 Y 是 X 的 3 阶多项式产生一些数据(3 阶多项式能很好地拟合数据。简单的线性回归容易造成高偏差(bias)、低方差(variance)4. 3 阶多项式拟合具备低偏差(bias)、低方差(variance)
- 关于线性回归与逻辑回归:线性回归观察的是两个变量之间变化的一个趋势,而逻辑回归观察的则是数据的分布情况
- 核函数的目标是得到更优的解
Q:
交叉熵函数一般用于分类问题,不适合用于线性回归问题。
下列有关学习率α和代价函数J(θ)说法正确的是( 1.2.3)?
1. 如果α过大,那么代价函数J(θ)可能越来越大甚至不收敛
2. 如果α过小,那么代价函数J(θ)可迭代速率会非常慢
3. 一般认定如果代价函数J(θ)迭代中下降小于一个值,例如1e-3,则判定函数收敛,但是实际应用中很难确定一个合适的判定范围
1.训练一个Bagging集成与直接使用基学习算法训练一个学习器的复杂度同阶,高效;
2.标准的AdaBoost只适用于二分类,Bagging能直接用于多分类,回归等任务;
3.因为自助采样,每个基学习器只使用了出事训练集中约63.2%的样本,剩下的样本可以用作验证集等等。
过拟合和欠拟合
逻辑回归模型中,假设数据集有2个特征x1和x2,那么,过拟合、欠拟和的直观表达如下图例所示:(红色叉表示一个分类,蓝色圆圈表示另一个分类)。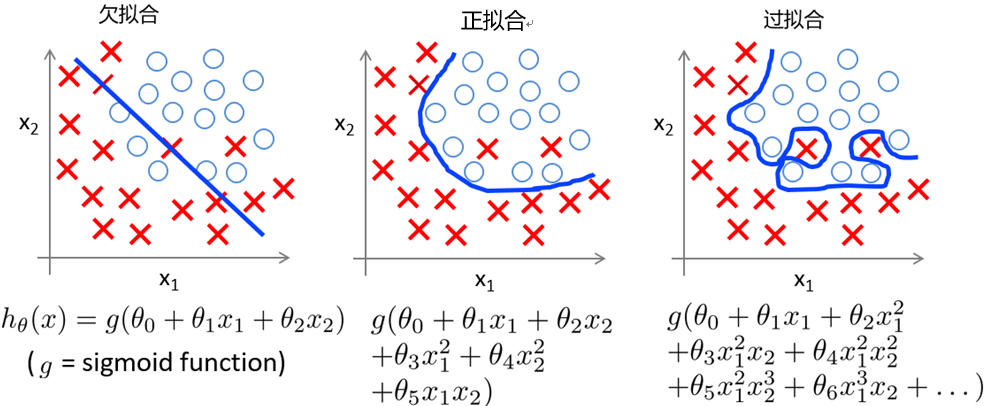
正则化原理
当出现过拟合的时候,我们需要对模型做适当的优化。其中正则化就是一种常见的解决方案。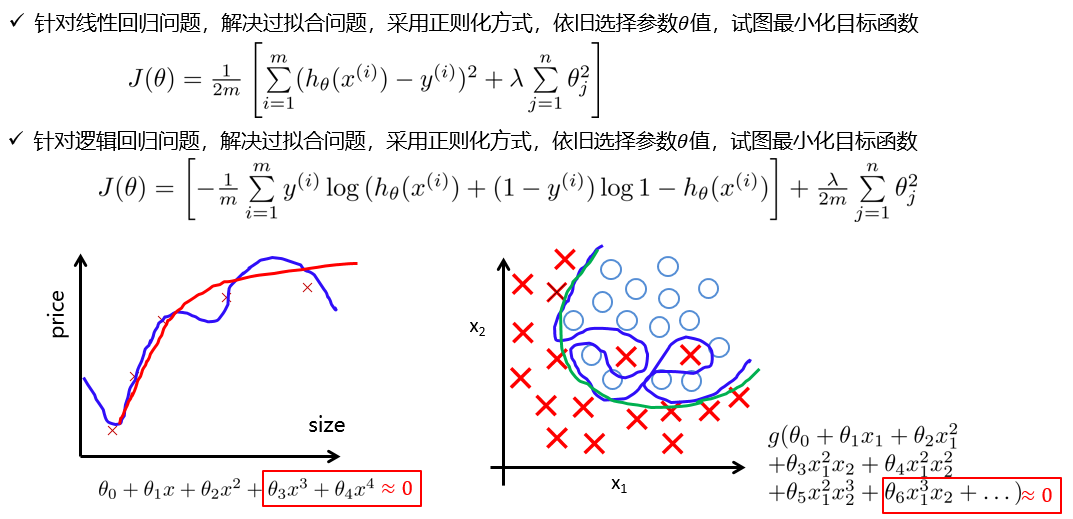
- 正则化的定义,在线性回归和逻辑回归中,我们都能做同样一件事,给代价函数增加了添加项来解决过拟合问题。
- 更一般地说,正则化一个学习函数f(x;θ)模型,可以给代价函数添加被称为正则化项(regularizer)的惩罚,通过在最小化的目标中额外增加一项,明确地表示了偏好权重较小的线性函数,这个方法称为正则化(regularization),通过对目标函数J 添加一个参数范数惩罚Ω(θ),限制模型的学习能力,正则化后目标函数如下:
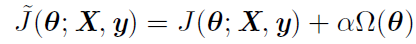
- α∈[0,∞)是权衡范数惩罚项Ω和标准目标函数相对贡献的超参数
- α为0 表示没有正则化,α越大,对应正则化惩罚越大
- 更多的正则化意味着更多的惩罚,还意味着更少的复杂的决策边界
- 因此,正则化目的是修改学习算法,使其降低泛化误差而非训练误差。
欠拟合
当出现欠拟合的时候,我们也需要对模型做适当的优化,通过对特征进行多项式变换,相当于增加特征。如下图所示: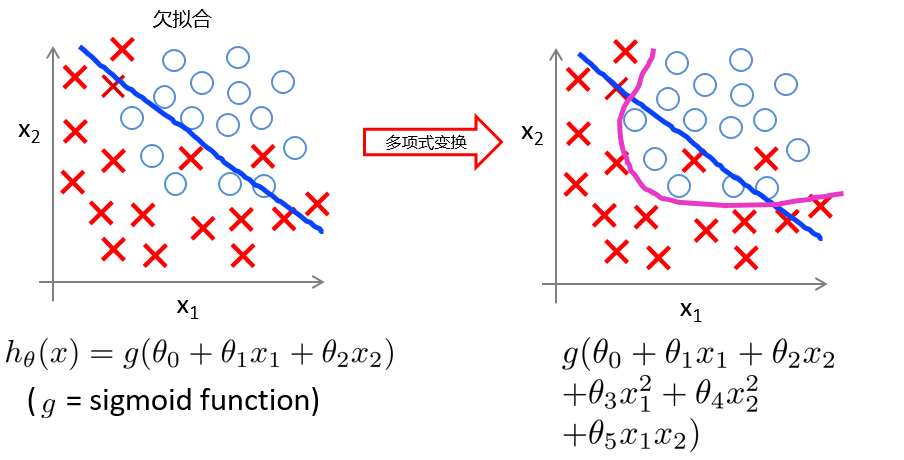
从图上可以看出,当出现欠拟合的情况的时候,一种有效的处理方法是针对特征做多项式变换,对特征数据进行高次变换,比如平方。
Numpy科学库提供的方法能够快速的对特征进行多项式变换,比如下面的代码实现了特征的平方变换。
Xnew = np.c[X, X ** 2]
线性不可分的问题
在分类问题中,我们会遇到一个重大的挑战,那就是数据集本身不能够使用一个条分类边界线严格的分开。假设数据集有两个特征x1和x2,那么,线性不可分问题最直观的表达如下图所示:(圆圈表示分类1,红叉表示分类2)。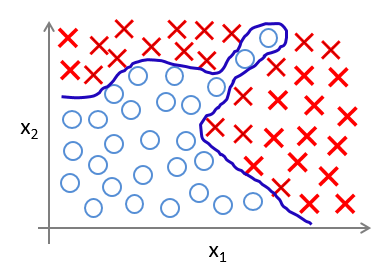
从图上可以看出,分类边界线是一条曲线。我们不可以使用一个直线把上面图像中的两类数据很好的划分。这就是线性不可分。
特征变换
- 针对线性不可分问题,比较流行的解决方案是使用核函数(kernel),其本质就是把原始的样本通过核函数映射到高维空间中,让样本在高维空间是线性可分的。
- 多项式变换是这种映射的简单的方式实现把线性不可分变成线性可分
总结
逻辑回归用来解决分类问题:
Ø 线性回归预测值是一个连续值,逻辑回归预测值是简单的离散值,因此需要找到一个连续函数,把连续值转换成离散值,单位阶跃函数是最好的联系函数;
Ø 阶跃函数的虽好,但是数学性质不好,那么,几率函数则是阶跃函数的良好替代,因为其连续、任意阶可导;
Ø 逻辑回归的代价函数采用对数似然函数,与线下回归不同,参数的求解与线性回归相同,都是梯度下降算法;
Ø 逻辑回归模型最好求取的参数经过和输入样本进行运算后,经过sigmoid函数的处理,得到一个0到1之间的值,我们把大于等于0.5的预测划归到正分类,小于0.5的预测划归到负分类;
模型优化
Ø 逻辑回归在进行模型训练的时候,模型会在训练集上拟合的很好,但是,使用新的样本,比如测试集进行预测的时候表现不好,这就是过拟合;
Ø 解决过拟合的问题,通常在代价函数后面加上惩罚项,机器学习称之为正则化项;
Ø 通过正则化项,解决为过拟合问题,在sklearn类库中,惩罚项表现为C值的设定。
线性不可分问题
Ø 真实的数据集也许并不是那么美好,我们不能够用一个线性模型把这个数据集严格的分开;
Ø 解决线性不可分的问题,最简单的方式是对特征进行多项式变换,当然,后面还有核函数方式。
多分类问题
Ø 线性回归不光只能解决二分类问题,也能解决多分类问题;
Ø 可以把一个多分类的问题看作是多个二分类问题的组合,典型的拆分策略有OvO、OvR、MvM。
模型选择与评估
GOF的问题
- 通常,我们拿到的数据,有缺失、错误,可以统称为噪音(noise)
- 在进行模型训练的时候,我们除了拟合了底层数据之间的逻辑关系(规则)之外,同样也拟合了噪音。
- 倘若提供更多的参数和特征的话,一定能够得到一个更加优质的GOF
- 模型过于复杂,直接导致模型在新的样本上预测的失败,意味着泛化性能下降。
-
性能度量概述
一般地说,我们把学习器的实际预测输出与样本真实输出之间的差异称为误差(error)。
- 学习器在训练集上的误差称为训练误差(training error)或经验误差(empircal error),在新样本上的误差称为泛化误差(generalization error)。评价模型泛化能力的评价标准,称为性能度量(performance measure)。
- 回归(regression) 任务常用性能度量是均方误差:

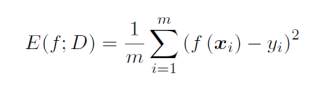
-
性能度量:查准率、查全率与F1
在二分类问题中,可以将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)四种情形,那么,样例总是=TP+FP+TN+FN。
- 给出查准率P和查全率R的定义,分别为:
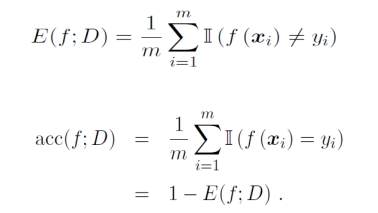
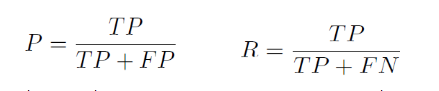
- 查准率和查全率是一对矛盾的度量,一般来说,查准率高时,查全率往往偏低,而查全率高时,查准率往往偏低。
- 但是,使用BEP过于简化,更常用的是使用F1度量。定义如下:
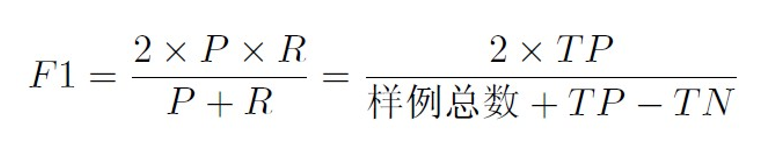
性能度量:宏查准率、宏查全率与宏F1
在各混淆矩阵上分别计算出查准率、查全率,再计算均值,于是就得到了宏查准率(macro-P)、宏查全率(macro-R)和宏F1(macro –F1)。由此,得到下面的公式: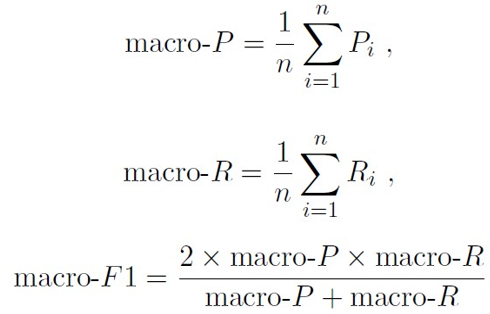
还可以将个混淆矩阵的对应元素进行平均,得到TP、FP、TN、FN的均值,因此,上式可以表达为下面的新的公式。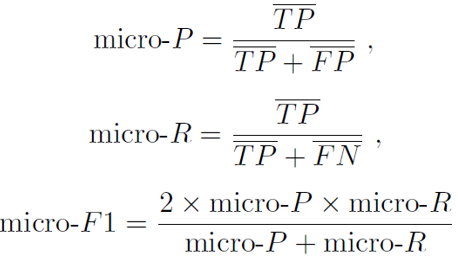
性能度量:ROC与AUC
- 很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与一个分类的阈值(threshold)进行比较,若大于阈值则分为正类,否则为反类。例如在逻辑回归中,常用的阈值为0.5。
- ROC曲线是研究机器学习泛化性能的有力工具。在信号检测理论中,接收者操作特征曲线(receiver operating characteristic curve,或者叫ROC曲线)是一种坐标图式的分析工具,用于:
(1) 选择最佳的信号侦测模型、舍弃次佳的模型。
(2) 在同一模型中设定最佳阈值。
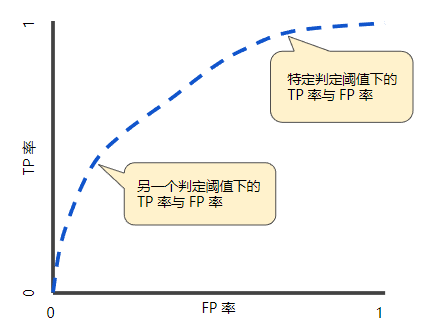
- ROC 曲线用于绘制采用不同分类阈值时的真正例率(True Positive Rate,TPR)与假正例率(False Positive Rate,FPR)。降低分类阈值会导致将更多样本归为正类别,从而增加假正例和真正例的个数。
- TPR和FPR定义如下:
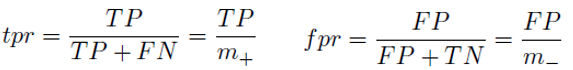
- 不同分类阈值下的 TP 率与 FP 率如下图。
- 准确率的计算公式:
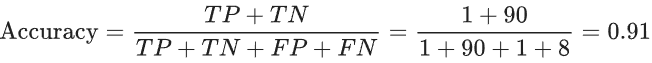
- 精确率
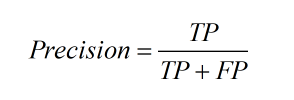
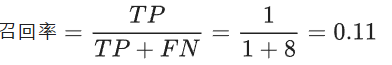
泛化误差分析
- 泛化误差可分解为偏差、方差与噪声之和,即:generalization error=bias^2+variance+noise 。
- “噪声”(noise):描述了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。假定期望噪声为零,则泛化误差可分解为偏差、方差之和,即generalization error=bias^2+variance。
- “偏差”(bias):描述了模型的期望预测与真实结果的偏离程度。偏离程度越大,说明模型的拟合能力越差,此时造成欠拟合。
- “方差”(variance):描述了数据的扰动造成的模型性能的变化,即模型在不同数据集上的稳定程度。方差越大,说明模型的稳定程度越差。如果模型在训练集上拟合效果比较优秀,但是在测试集上拟合效果比较差,则方差较大,出现这种现象可能是由于模型对训练集过拟合造成的。
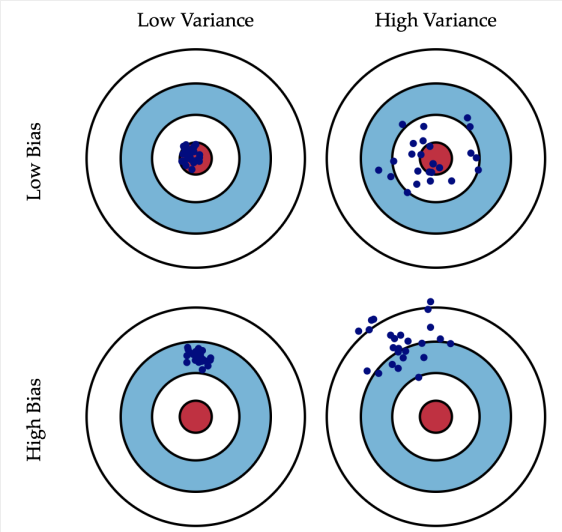
- 偏差和方差关系如下图所示(俯视):低偏差和低方差的点(拟合数据)都打在靶心,高偏差和低方差的点比较集中的偏离了靶心。
简单的总结一下:偏差大,说明模型欠拟合;方差大,说明模型过拟合。下图是从另一个方式来诠释偏差和方差之间的关系。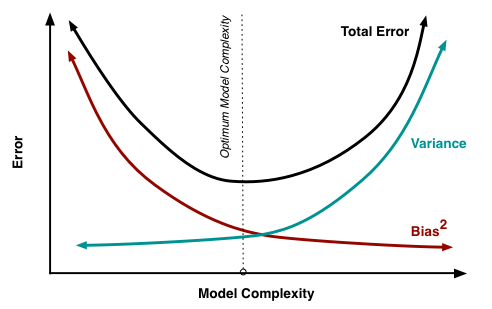
下面的图则更加直观地表达了方差和偏差在对数据拟合的影响。
- 典型的评估方法为:
- 用70%划分得到的训练集来训练模型:即最小化J(θ)
- 计算训练后的模型在测试集上的误差(test set error)
- 顺便提一句,针对逻辑回归,也是如此做。
- 从训练集中训练得到参数θ
- 计算测试误差:
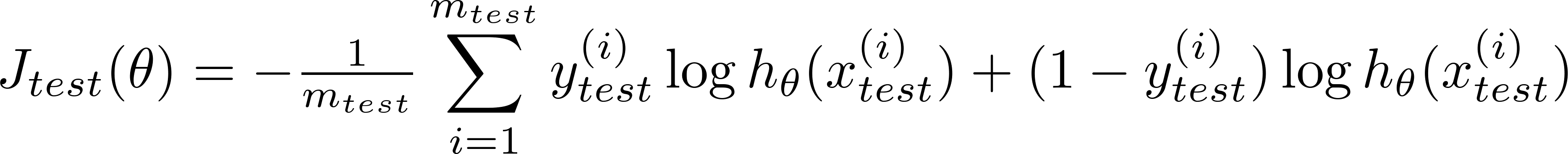
关于正则化:
- 根据奥卡姆剃刀定律,或许我们可以通过降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。
加入正则化后,并非只是以最小化损失(经验风险最小化)为目标,而是以最小化损失和复杂度为目标,这称为结构风险最小化。即:
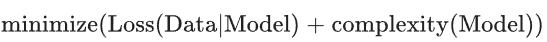
加入正则化后,我们的训练优化算法是一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度,另一个是正则化项,用于衡量模型复杂度
- L2 正则化会使权重接近于 0.0,但并非正好为 0.0。
- L2 正则化不会倾向于使权重正好为 0.0。L2 正则化降低较大权重的程度高于降低较小权重的程度。随着权重越来越接近于 0.0,L2 将权重“推”向 0.0 的力度越来越弱。
出乎意料的是,当某个信息缺乏的特征正好与标签相关时,便可能会出现这种情况。在这种情况下,模型会将本应给予信息丰富的特征的部分“积分”错误地给予此类信息缺乏的特征
Q:模型评估方法概述
在机器学习中,可以通过实验测试来对学习器的泛化误差进行评估并进而做出选择。为此,需要一个测试集来测试学习器对新样本的判别能力,然后以测试集上的测试误差(testing error)作为泛化误差的近似。
- 评估的方法大体有三种:



ü 留出法 (hold-out)
ü 交叉验证法 (cross validation)
ü 自助法 (bootstrap)
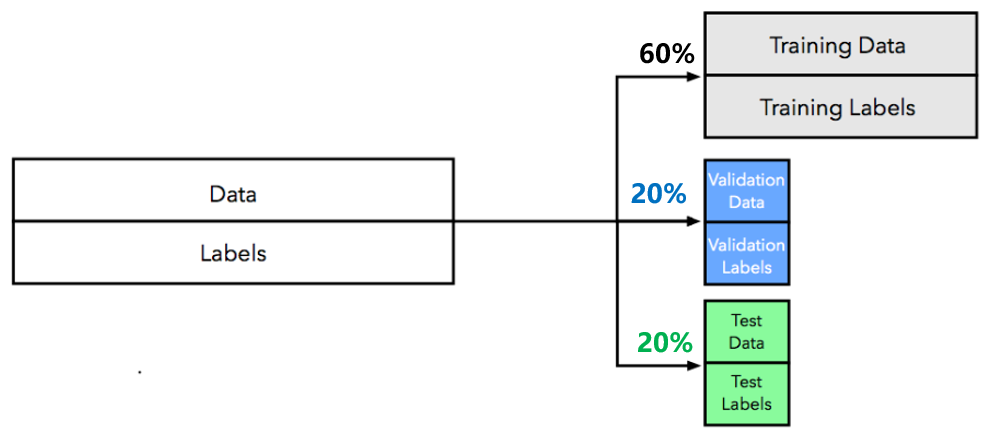
留出法把数据集分成三个互斥的集合:训练集、验证集和测试集。如下图:
交叉验证法(Cross Validation)现将数据集D划分成为k个大小相似的子集,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集。于是,能够得到k组训练/测试集,从而可以进行k次训练和测试,最后返回k个测试结果的均值。
- 通常把交叉验证法称为k折交叉验证(k-fold cross validation),k常用的取值是10,也可以取5,20等。假设数据集中包含m个样本,若令k=m,则得到交叉验证法的一个特例,留一法(Leave-One-Out,LOO)。
- 基于“自助采样”(bootsrap sampling),亦称“有放回采样”,“可重复采样”。如下图所示:
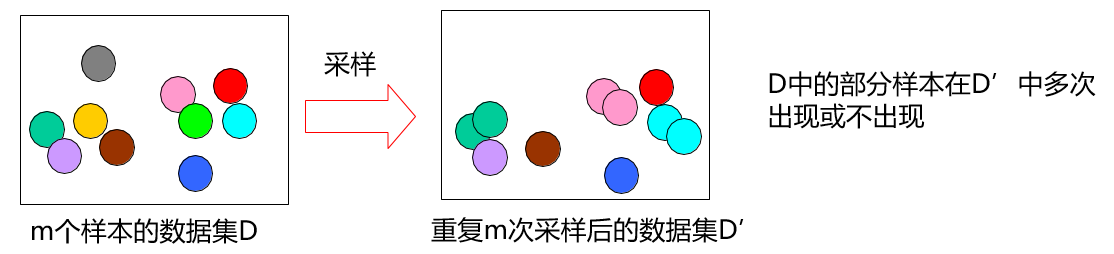
- 通过自助采样,初始数据集D中约有36.8%的样本未出现在采样数据集D’中。计算公式如下:
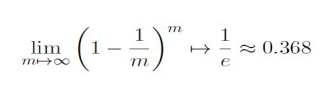
于是,我们D’作为训练集,D/D’作为测试集。这样实际评估的模型与期望评估的模型都使用了m个训练样本,而我们仍有数据总量的1/3没有在训练集中出现的样本用于测试,这样的测试结果,又称为包外估计(out of bag estimate)。
比较检验
先问一个问题:
Q:在某种度量下取得评估结果后,是否可以直接比较以评判优劣?
A:不可以。因为:
1) 测试性能不等于泛化性能
2) 测试性能随着测试集的变化而变化
3) 很多机器学习算法本身有一定的随机性
从这个意义上来说,机器学习的本质是概率近似正确
统计假设检验 (hypothesis test) 为学习器性能比较提供了重要依据,基于假设检验结果我们可以推断出,若在测试集上观察到A比B好,则A的泛化性能是都在统计意义上优于B,以及这个结论的把握有多大。
两学习器比较:
交叉验证 t 检验 (基于成对 t 检验)
k 折交叉验证; 5x2交叉验证
McNemar 检验 (基于列联表,卡方检验)
多学习器比较:
- Friedman + Nemenyi
Friedman检验 (基于序值,F检验; 判断”是否都相同”)
Nemenyi 后续检验 (基于序值,进一步判断两两差别)
总结
模型的选择:
Ø 对候选模型的泛化误差进行评估,选择泛化误差最小的模型;
Ø 通常把数据集拆分成三个互斥的部分,分别为训练集、验证集和测试集;
Ø 模型选择的过程中,主要选择多项式的幂次和λ值的大小;
评估方法:
Ø 留出法;
Ø 交叉验证法;
Ø 自助法。
性能度量:
Ø 性能度量的指标对于回归任务是均方误差,对分类任务是精度和错误率
Ø 针对有些应用,需要用到的性能度量的指标是查准率、查全率和F1
Ø PR曲线是查全率和查准率在同一个坐标系中的图形表达
Ø ROC曲线则是横轴为假正例率,纵轴为真正例率在同一个坐标系中的图形表达
Ø ROC曲线与横轴间的面积定义为AUC
决策树
两个属性的信息熵
所以,套用香农的公式:X的取值为5,9,概率(这里用频次比较合适)分别为0.36和0.64,那么随机变量play的信息熵为:

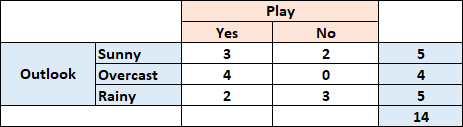
上述表格数据的信息熵计算,应用下面的公式:
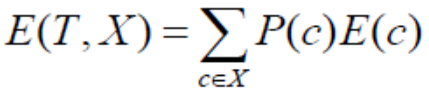
在这个公式中,T表示某个特征,E(c)表示特征某个具体的取值(例如:Outlook=Sunny)形成的子集({‘yes’:3,’No’:2})的信息熵,P(c)表示特征某个具体的取值(Outlook=Sunny)形成的子集在整个数据集上的占比(5/14),所以,计算这个经过拆分后的数据子集的信息熵为:
E(Play,Outlook)=P(Sunny)E(3,2)+P(Overcast)E(4,0)+P(Rainy)E(2,3)
=(5/14)0.971 +(4/14)0.0 +(5/14)0.971
=0.693
互信息
- 使用信息增益(Information Gain)来表达输入属性X和目标y之间的交互信息。信息增益表达的是数据集S中目标y的信息熵的期望值的减少。公式为:
Gain(T,X) = Entropy(X)-Entropy(T,X)
- ID3算法。该算法的核心是,使用信息增益来选择树根。
- ID3算法(Iterative Dichotomiser 3 迭代二叉树3代)是一个由Ross Quinlan发明的用于决策树的算法。
- ID3算法不能处理连续型的数据
- 这个算法是建立在奥卡姆剃刀的基础上:越是小型的决策树越优于大的决策树(简单理论)。尽管如此,该算法也不是总是生成最小的树形结构。
该算法的具体过程如下:
1)从根节点(root node)开始,对结点计算所有的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点;
2)再对子结点递归地调用以上方法,构建决策树;
3)直到所有特征的信息增益均很小(小于阈值varepsilon)或没有特征可以选择为止。
计算信息增益
- 信息增益最大的拆分是Outlook属性。因此,在使用ID3算法构建决策树的时候,树根的选择为Outlook。
在使用ID3算法构建决策树的时候,树根的选择为Outlook,因为信息增益的值最大。
ID3算法缺点考量
对ID3算法进行改进那就是,使用分裂信息(Split Information),将Gain规范化。如下:
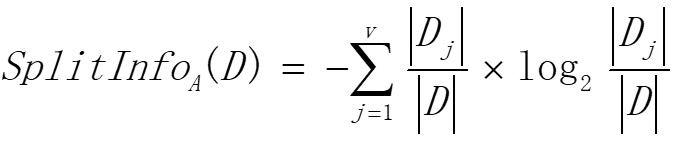

这样,定义信息增益比: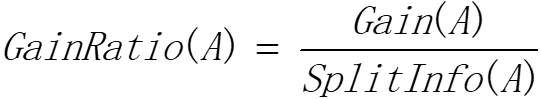
那么,采用信息增益比来选择特征的算法称为C4.5算法。
在真实的应用场景中,我们不选择ID3算法和C4.5算法,取而代之使用的是一种称为:分类回归树CART(Classification and Regression Trees)的算法。分类树:目标变量是分类的,该树用于标识目标变量可能落入的“类”。
-
分类树:
分类树是用基尼指数(Gini index)最小化准则,进行特征选择,生成二叉树,分类决策树的生成就是递归地构建二叉决策树的过程。
- 分类问题中,假设有K个类,样本点属于第k类的概率为pk,则概率分布的基尼指数定义为:
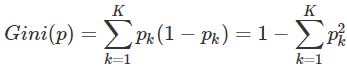
对于二分类问题,若样本点属于第1个类的概率是p,则概率分布的基尼指数为: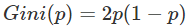
- 基尼指数Gini(D)表示集合D的不确定性,基尼指数Gini(D,A)表示经A=a分割后集合D的不确定性,基尼指数越大,样本集合的不确定性也就越大,这一点和熵相似。
- 从分类决策树的构建过程可以看出,要完成python代码来实现,需要经历以下步骤:
第一步,编写函数完成对原始数据集基尼系数的计算。
第二步,编写函数完成依据某个特征的不同取值,计算划分后子集的基尼指数。
第三步,编写函数,完成原始数据集的最好的2个子集的 ,中间用到了基尼指数最小作为判别标准。
第四步,编写函数,递归的方式构建左右子树。
- 使用信息熵来度量不确定性(Use to entropy to measure uncertainty)
- C4.5分类树使用信息熵度量不确定性
- CART树使用基尼指数度量不确定性
Q:
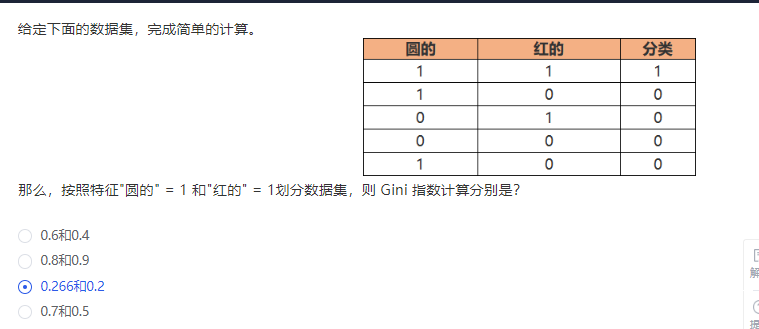
解析:
1)按特征”圆的” = 1 划分数据集,则 Gini 为:
3/5 Gini(D1) + 2/5 Gini(D0)= 3/5 [1/3 2/3 + 2/3 1/3] + 2/5 [0]= 0.266
2)按特征”红的” = 1 划分数据集,则 Gini 为:
2/5 Gini(D1) + 3/5 Gini(D0)= 2/5 [1/2 1/2 + 1/2 1/2] + 3/5 [0]= 0.2
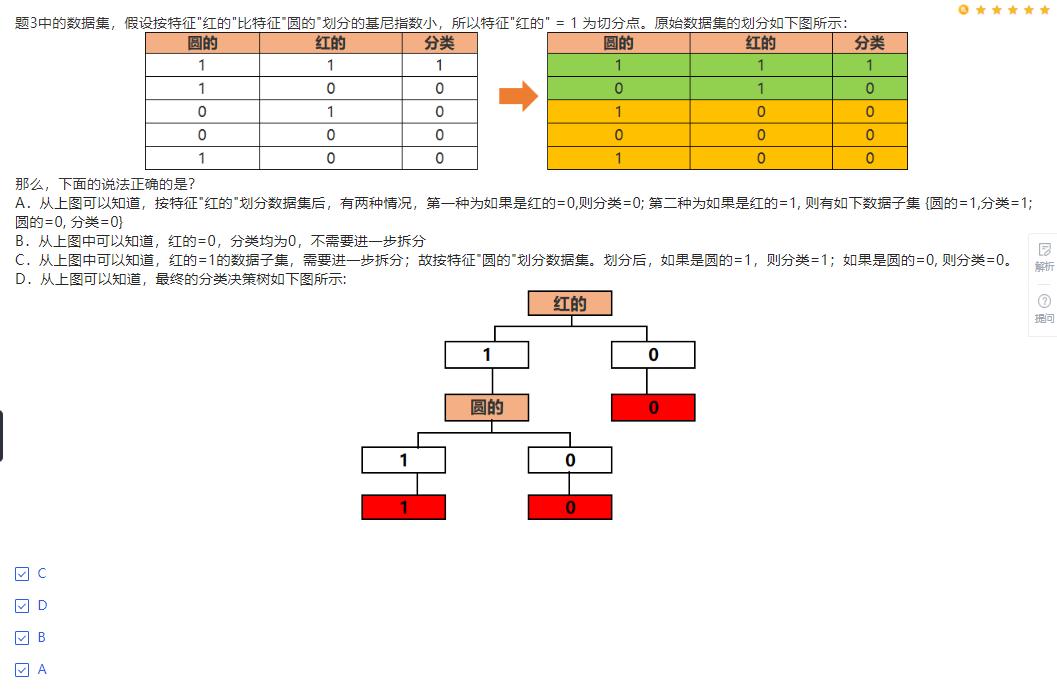
回归树
- 假设数据样本的目标值为连续的值,那么,通过决策树需要解决的问题由此演变成了回归问题,这个决策树被称为回归决策树。
- 决策树的划分可以通过信息增益、基尼指数作为判断标准。
-
标准差
我们用标准差来计算一个数值样本的同质性。如果数值样本是完全均匀的,其标准差为零。
计算:
特征和目标两列的标准差如何计算呢?以Outlook列和Hours Played为例,计算公式为: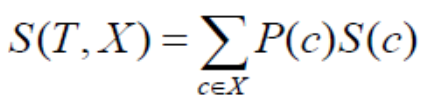
- 构造决策树时,树根的判别标准为:找到最大标准差减少的属性。
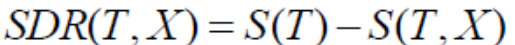
Q:
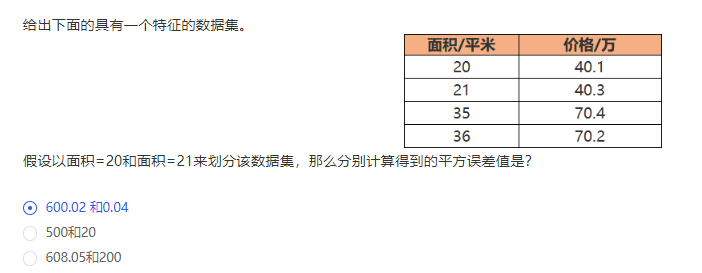
解析:
1)按特征”面积” = 20 划分数据集,y1 均值为 40.1,y2 均值为(40.3 + 70.4 + 70.2) / 3 = 60.3,
则平方误差为:0 + (40.3 – 60.3)^2 + (70.4 – 60.3)^2 +(70.2 – 60.3)^2= 600.02
2)按特征”面积” = 21 划分数据集,则平方误差为:y1 均值为(40.1 + 40.3)/ 2 = 40.2,y2 均值为(70.4 + 70.2) / 2 = 70.3,
则平方误差为:(40.1 –40.2)^2 + (40.3 –40.2)^2 + (70.4 –70.3)2 +(70.2 –70.3)^2= 0.04
决策树剪枝:
- 在决策树的学习中,为了尽可能正确分类训练样本,结点的划分过程将不断的重复,这样会造成分支过多。从而导致了过拟合,那么。我们在树的构建过程中,可以提前终止某些分支的增长,意味着,使用经验来修改某些规则。或者,先构建生成一棵完整的树,再回头来剪枝。
- 预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)。
- 预剪枝是指在决策树的生成过程中,对每个结点在划分前先进行评估,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前的结点标记为叶结点。
- 总结一下,预剪枝使得决策树的很多分支都没有展开,不仅降低了过拟合的风险,还显著减少了决策树训练时间开销和测试时间开销。在另一方面,有些分支的当前划分虽然不能提升泛化性能,甚至可能导致泛化性能暂时下降,但在此基础上进行的后续划分却有可能导致性能显著提高。预剪枝基于贪心本质是禁止这些分支的展开,给预剪枝决策树带来了欠拟合的风险。、
- 后剪枝先从训练阶生成一颗完整的决策树,再回头剪枝。
剪枝的数理基础是,基于统计显著性检验,当任何属性和特定节点上的类之间没有统计上的显著关联时,停止生成树,最流行的测试方式:卡方测试。
剪枝的过程是:形成一个子树序列,在剪枝的过程中,计算子树的损失函数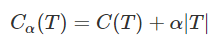
后剪枝—- α选取
**
**
**
1)当α = 0 或者极小的时候,有不等式:
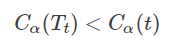
不等式成立的原因是因为,当α=0或者极小的时候,起决定作用的就是预测误差C(t),C(Tt),而模型越复杂其预测误差总是越小的。
2) 当α增大时,在某一α有:
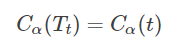
等式成立的原因时因为,当α慢慢增大时,就不能忽略模型复杂度所带来的影响(也就是第二项);但由于剪枝前的模型更为复杂,所以总有个时候,两者会相等。
3)当α再增大时,不等式反向。因此,当Cα(Tt)=Cα(t)时,有α=C(t)−C(Tt)/|Tt|−1,则Tt,t有相同的损失函数值,而t的结点少,模型更简单,因此t比Tt更可取,对Tt进行剪枝。(注:此时的α时通过Cα(Tt)=Cα(t)计算出来的),计算g(t)。
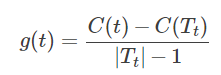
它表示剪枝后整体损失函数减少的程度。在T0中减去g(t)最小的Tt,将得到的子树作为T1。如此剪枝下去,直到得到根结点。
在剪枝的过程,得到一系列的g(t),即α,都能使得在每种情况下剪枝前和剪枝后的损失值相等,因此按照上面第3种情况的规则,肯定是要剪枝的,但为什么是减去其中g(t)最小的呢?如下图:
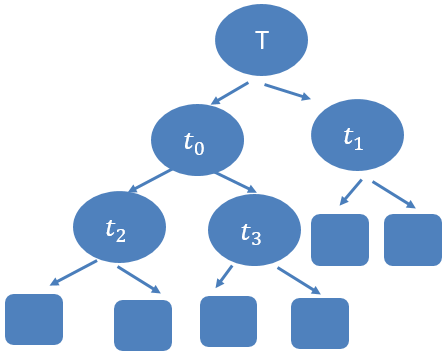
对于树T来说,其内部可能的结点t有t0,t1,t2,t3。因此我们便可以计算得到g(t0),g(t1),g(t2),g(t3),也即对应的α0,α1,α2,α3。
从上面的第3种情况我们可以知道,g(t)是根据Cα(Tt)=Cα(t)推导出来的,因此这四种情况下ti比Tti更可取,都满足剪枝。但是由于以ti为根结点的子树对应的复杂度各不相同,也就意味着αi≠αj,(i,j=0,1,2,3;i≠j),即αi,αj存在着大小关系。又因为:当α大的时候,最优子树Tα偏小;当α小的时候,最优子树Tα偏大;且子树偏大意味着拟合程度更好。因此,在都满足剪枝的条件下,选择拟合程度更高的子树,当然是最好的选择。
剪枝算法
- 后剪枝算法包括Reduced-Error Pruning (REP,错误率降低剪枝)、Pessimistic Error Pruning (PEP,悲观剪枝)、Cost-Complexity Pruning(CCP,代价复杂度剪枝)。
- 在决策树中,使用预剪枝防止过拟合的说法正确的是?
(ABC)
A. 预剪枝本质是提前停止(Early Stopping),在决策树形成之前早期停止生长
B. 对结点来说,典型的停止条件是:所有的样本分类值是一样的和所有的属性值是一样的
C. 早期停止更多限制条件是:1)样本数小于某个用户定义的阈值,比如2.3 。2)如果结点展开不能显著的提升基尼指数和信息增益
总结
三种比较常见的分类决策树分支划分方式包括:ID3, C4.5, CART:
CART树
• 目标值为离散值,称为分类树
• 目标值为连续值,称为回归树
决策树剪枝:
• 预剪枝:在构建树的过程中,让某个分支提前停止分裂
• 后剪枝:先构造一个完整的树,然后从下往上剪去某个分支
• 两种剪枝的方式目标都是为了提升决策树的泛化性能
贝叶斯分类器
在做逻辑回归的时候,我们默认了一些大的前提,那就是:
ü 无需事先假设数据分布状态
ü 能够得到分类的近似概率预测
ü 可以直接使用数值优化算法求取最优解
贝叶斯公式,如下: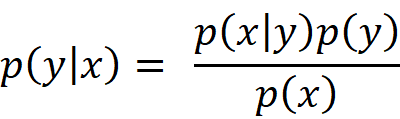
公式中,p(y)表示事件y出现的概率,可通过各类样本出现的频率估计(先验概率)。
p(x|y)表示在已知事件y情况下,样本x的条件概率或称为似然。p(x)表示事件x出现的概率,也是先验概率。
所以,贝叶斯公式提供了一种从训练数据中计算p(y)、p(x|y)计算后验概率p(y|x)的方法。
贝叶斯决策论概述
贝叶斯决策论(Bayesian Decision Theory),是在概率框架下实施决策的基本方法。

总结:
上面的公式中的符合∏表示乘法运算。即所有的条件概率做乘法运算。
极大似然估计
- 正态分布(normal distribution)又名高斯分布(Gaussian distribution)。正态分布是自然科学与行为科学中的定量现象的一个方便模型。各种各样的心理学测试分数和物理现象比如光子计数都被发现近似地服从正态分布。尽管这些现象的根本原因经常是未知的,理论上可以证明如果把许多小作用加起来看做一个变量,那么这个变量服从正态分布。从这个意义上来说,我们有足够的理由相信我们数据集中数据都是服从高斯分布。
假如我们的数据集的特征的取值都服从正态分布的话, 那么,可以直接利用特征值的均值和方差来计算条件概率。
Q:
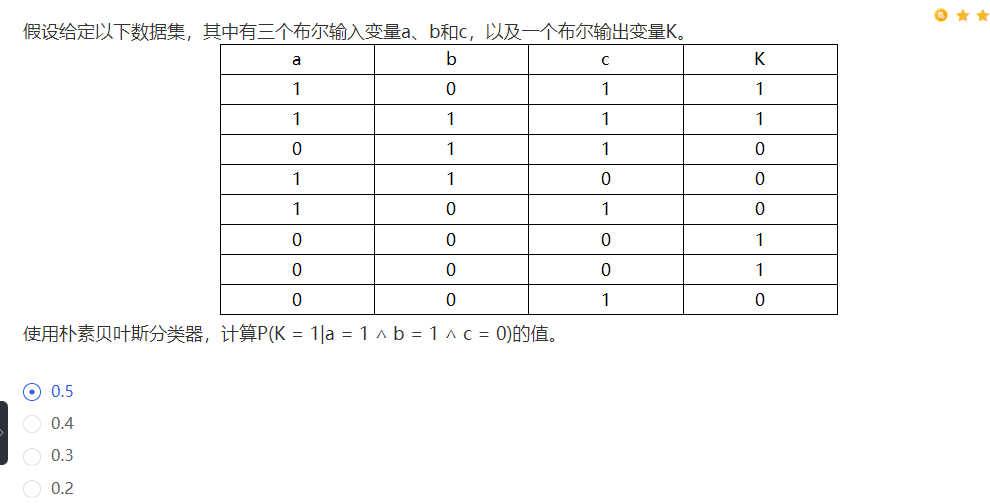
解析:
P(K = 1|a = 1 ∧ b = 1 ∧ c = 0) = P(K = 1 ∧ a = 1 ∧ b = 1 ∧ c = 0)/P(a = 1 ∧ b = 1 ∧ c = 0)
= P(K= 1) · P(a = 1|K = 1) · P(b = 1|K = 1) · P(c = 0|K = 1)/
P(a = 1 ∧ b = 1 ∧ c = 0 ∧ K = 1) + P(a = 1 ∧ b = 1 ∧ c = 0 ∧ K = 0)
解析:
1)P(K = 0|a = 1 ∧ b = 1) = P(K = 0 ∧ a = 1 ∧ b = 1)/P(a = 1 ∧ b = 1)
= P(K= 0) · P(a = 1|K = 0) · P(b = 1|K = 0)/
P(a = 1 ∧ b = 1 ∧ K = 1) + P(a = 1 ∧ b = 1 ∧ K = 0)
2)P(K = 0|a = 1 ∧ b = 1) = num(K = 0 ∧ a = 1 ∧ b = 1)/num(a = 1 ∧ b = 1) = 1/2
解析:
NB的核心在于它假设向量的所有分量之间是独立的。在贝叶斯理论系统中,都有一个重要的条件独立性假设:假设所有特征之间相互独立,这样才能将联合概率拆分。半朴素贝叶斯
基本思路:适当考虑一部分属性间的相互依赖信息,从而既不需进行完全联合概率计算,又不至于彻底忽略比较强的属性依赖,假设每个属性在类别之外最多仅依赖一个其他属性,称为独依赖估计(One-Dependent Estimator)。
- ODE是半朴素贝叶斯分类器最常用的一种策略,所谓独依赖就是假设米格属性在类别之外最多仅依赖一个其他属性
贝叶斯网络:
• 又称为“信念网”(brief network)或概率有向无环图形模型(probabilistic directed acyclic graphical model)
• 借助于有向无环图(Directed Acyclic Graph,DAG)来刻画属性之间的依赖关系,并使用条件概率表(Conditional Probability Table,CPT)来描述属性的联合概率分布
贝叶斯网,为了强调:
• 输入信息的主观本质
• 对贝叶斯条件的依赖性
• 因果与证据推理的区别总结:
贝叶斯决策论:
• 是在概率框架下实施决策的基本方法
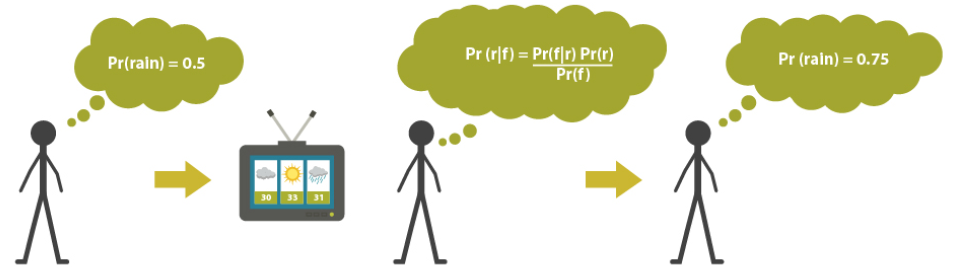
• 贝叶斯理论用于计算事件A的概率,如果有新的证据B,则可以根据新的证据更新A的概率。如下图所示:
极大似然估计:
• 就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值
• 极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”
• 假定该类样本服从高斯分布,那么接下来就是利用训练集中该类样本来估计高斯分布的参数:均值和方差
朴素贝叶斯和半朴素贝叶斯:
• 朴素贝叶斯分类器采用属性条件独立性假设。也就是说,假设所有属性相互独立,单独地对分类结果产生影响
• 朴素贝叶斯分类器基于属性条件独立性假设,每个属性仅依赖于类别。但这个假设往往很难成立的,有时候属性之间会存在依赖关系,这时我们就需要对属性条件独立性假设适度地进行放松,适当考虑一部分属性间的相互依赖信息,这就是半朴素贝叶斯分类器的基本思想
贝叶斯网络:
• 是一个有向无环图
• 结点代表随机变量,边代表节点间的关系(因果关系),用条件概率表达关系的强度
• 没有父结点的先验概率表达信息
• 下图简单的表达了贝叶斯网络的特点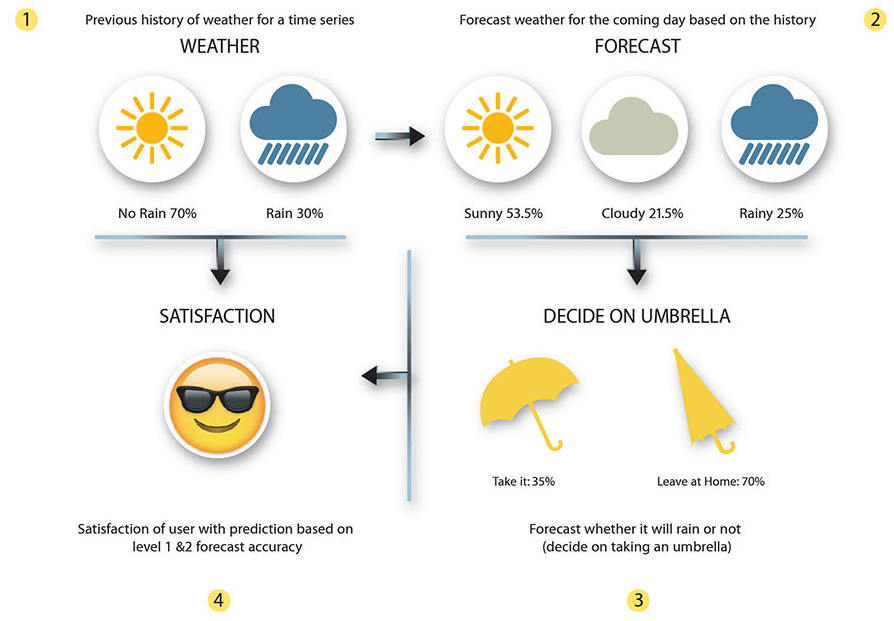
支持向量机
- SVM模型的任务就是求取一系列的参数w和b。和逻辑回归不同的是,使用SVM完成参数求取的时,标签的取值为-1和1,不能是0和1。同时,定义z(x) = 0,为决策边界(decision boundary)。
超平面
从数学上,我们知道,点点成线,线线成面,面面成体。二维平面上的线(上例中的棍子,分类边界)在多维空间,便是一个面,因此引入超平面(hyperplane)的定义,如下图: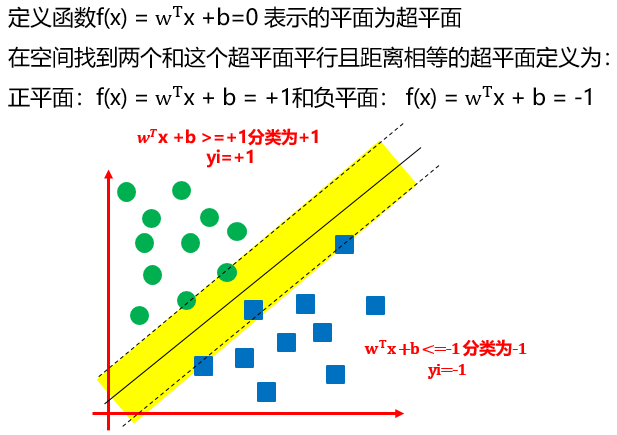
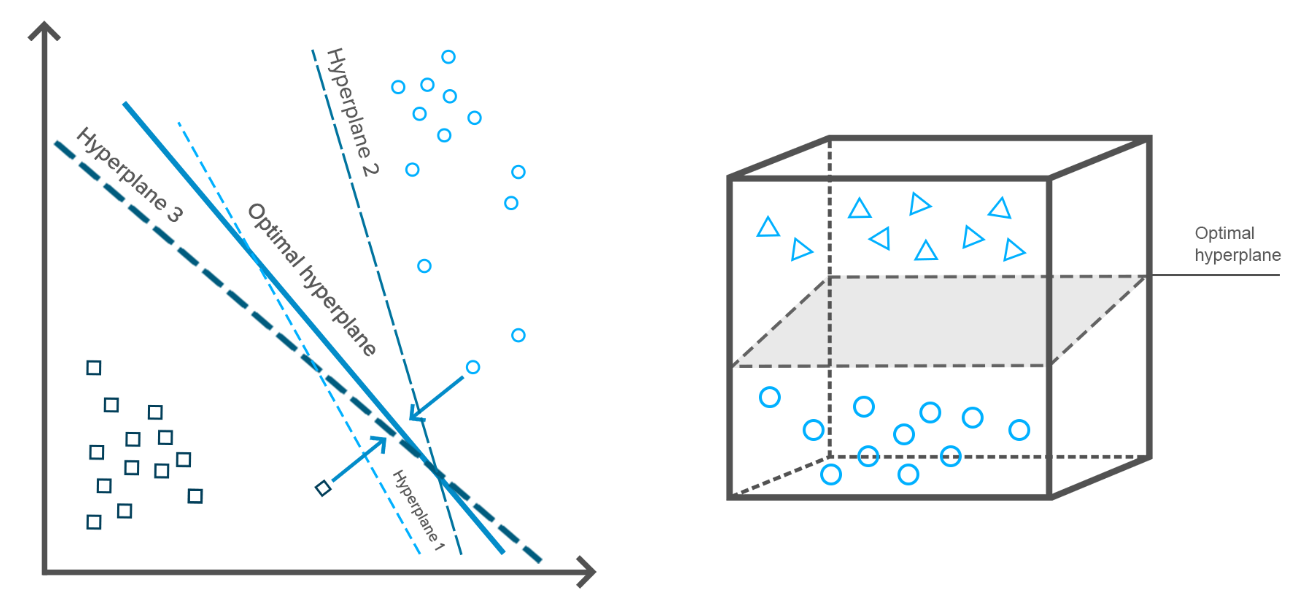
SVM的定义
SVM思想:
SVM试图寻找一个超平面来对样本进行分割,把样本中的正例和反例用超平面分开,但是不是简单的分开,而是尽最大的努力使正例和反例之间的间隔(margin)最大。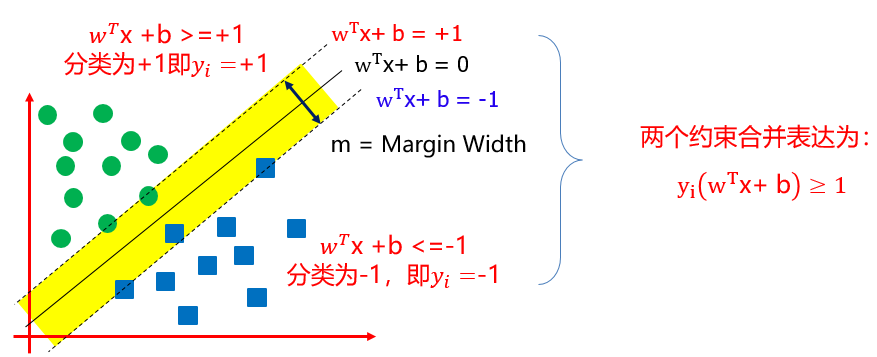
- 所以,特征空间上的间隔最大的线性分类器称为支持向量机(SVM)(Maximum Margin Linear Classifier)。
- 线性分类器,因为维度高的时候,数据一般在维度空间里面会比较稀疏,很有可能线性可分。
- 位于正负超平面的上的点称为支持向量(Support Vecter),支持向量机也由此得名。
- SVM算法中使用高斯核/RBF核代替容易引起机器学习中的过拟合问题
- SVM核函数包括线性核函数、多项式核函数、径向基核函数、高斯核函数、幂指数核函数、拉普拉斯核函数、ANOVA核函数、二次有理核函数、多元二次核函数、逆多元二次核函数以及Sigmoid核函数。
- SVM中的代价参数表示:误分类与模型复杂性之间的平衡
- 正负平面之间间隔定义为m,其值为:m = 2/||w||
- 正或负平面到超平面的间隔为:1/|||w|。
- 所以SVM的目标是寻找w和b,使得间隔m最大。如下图所示:
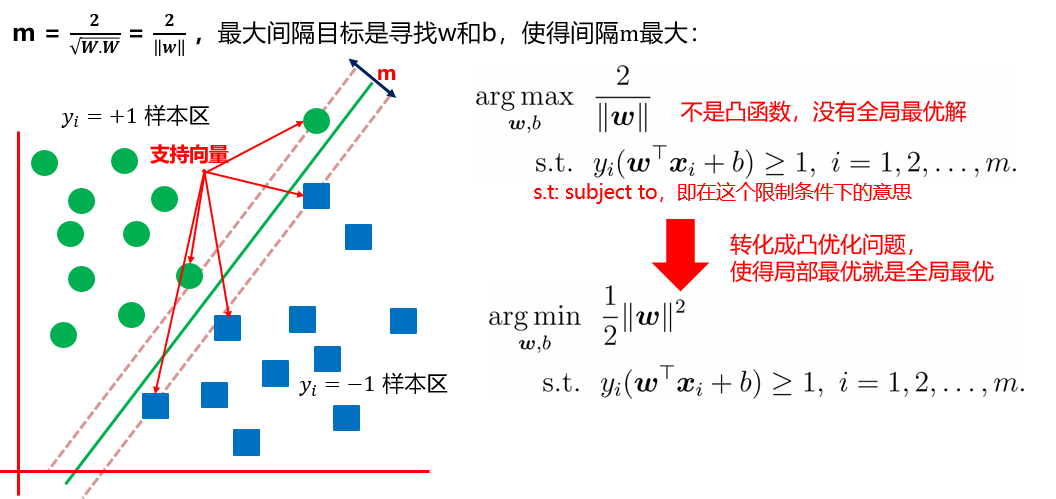
上面的优化目标是凸二次规划问题就可以通过一些现成的 QP (Quadratic Programming) 的优化工具来得到最优解。
极值问题的求解
VM最大间隔m问题转换成求取条件极值问题,如下:
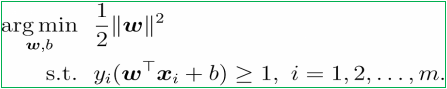
我们知道,求极值问题,如果在函数的定义域内并无其他约束条件,称为无条件极值。而SVM的优化问题对自变量附加了约束条件,称为条件极值问题。
而解决条件极值问题的解决思路为转化成无条件极值问题。
• 约束条件为等式时使用拉格朗日乘子法(Lagrange Multiplier)
• 约束条件为不等式时使用KKT条件 (Karush Kuhn Tucker)
拉格朗日乘子法数理基础
- 欲求一个函数z = f(x,y) 在附加条件φ(x,y) = 0(等式条件)下可能的极值点,使用下面的步骤:
1) 可以先作拉格朗日函数: L(x,y) = f(x,y) +λφ(x,y),λ为参数
2) 分别对x,y求一阶偏导数,令其为0 ,联立方程求解x,y和λ,这样得到的x,y就函数在附加条件下的极值点,即: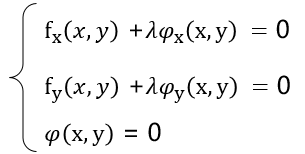
- 拉格朗日乘子法图解如下:
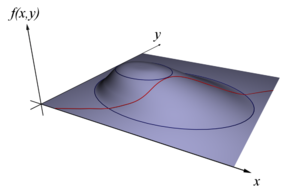
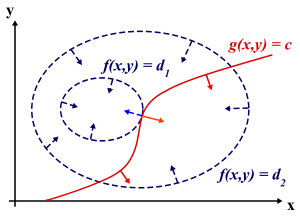
左图:求取函数f(x,y)在约束条件g(x,y) = c的最大值。本质是两个曲线的交点。
右图:虚线形成的椭圆是函数f(x,y)等高线(当然,你能够画很多的等高线,图中画2条作为示意),意味着在这条线上,不同的x,y经过函数f(x,y)得到的值是相同的,也可以成为等值线。红线表示约束条件g(x,y) = c。红线和蓝线的切点就是解。
- 一个使用拉格朗日乘子法的例子
求取椭球最大值。
椭球方程为: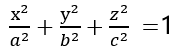
求解这个椭球的内接长方体的最大体积,即求f(x,y,z) =8xyz的最大值?
求解过程如下:
ü 这是等式条件极值问题,使用拉格朗日乘子法将问题转化为: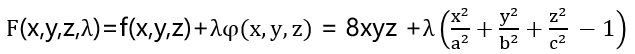
- 分别对x,y,z,λ求偏导,得到下面的等式:
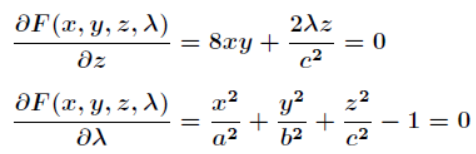
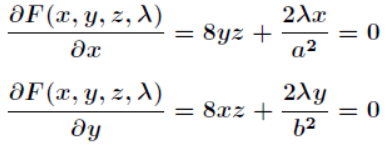
联立前3个方程,得到bx=ay,az=cx,代入第4个方程,得到: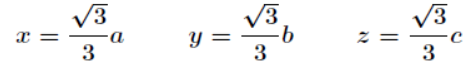
代入得到最大体积:
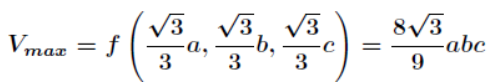
松弛变量
引入一个叫做松弛变量的参数ξ,并令其取值范围>=0,由于异常点不只有一个,假设有i个吧,因此,也就有了这个不等式:ξi>=0。
做如下的规定:
• 0<ξi≤1 表示边界和超平面之间的点,叫做margin violation
• ξi>1 表示错误分类的点(misclassified)
坐标变换
- 坐标变换是解决线性不可分的方式之一:

- “核函数选择”成为决定支持向量机性能的关键!
常用的核函数
SVR的问题的优化目标为:
SVR问题求解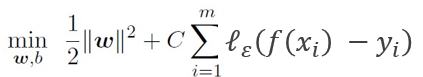
这里ℓε 为ε-不敏感损失函数,和SVM一样,C为惩罚系数,取值为某个特定的值或∞。
• C=∞,强制所有样本满足约束条件(f(xi ) −yi≥∈),正则化项的值为0.
• C取某个特定的值时,允许一些样本不满足约束,但是正则化项取值不会超过C
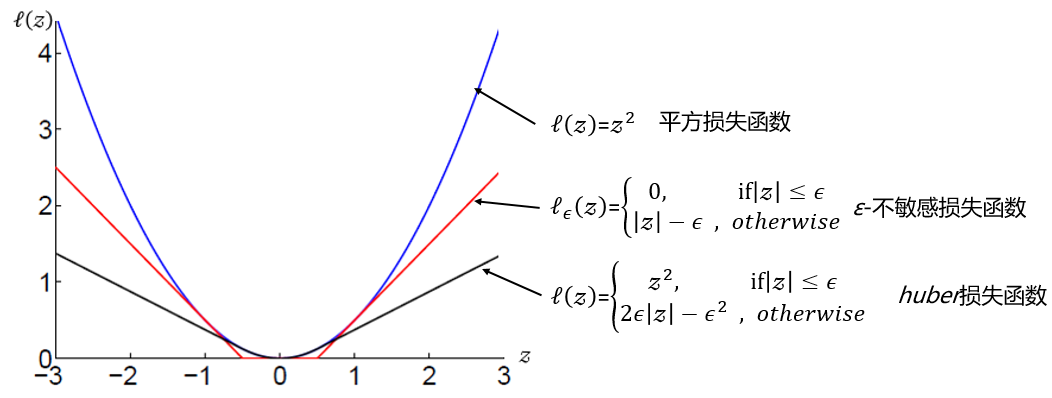
重点说下ε-不敏感损失函数ℓε(z):
• 当|z| <=ε时,ℓε(z) = 0
• 否则,ℓε(z) = |z|-ε
图像上看,函数是连续的,但是存在拐点,所以在真实的应用中,通常选择与这个函数近似的替代函数:平方损失函数或者huber损失函数。三个函数的图像如下图所示:
总结
SVM和SVR:
无论SVM还是SVR, 学得模型总能表示成核函数的线性组合: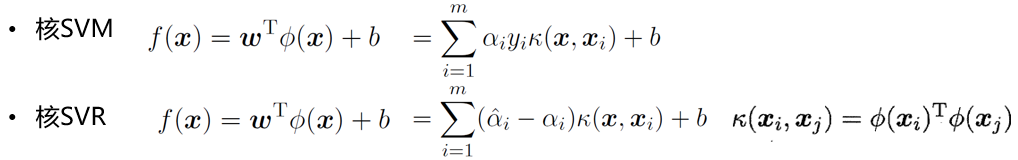
核函数和核方法:
• 基于核函数的学习方法,统称为核方法
• 线性不可分问题可以通过核函数来完成
支持向量:
• 那些散落在正负超平面上的样本点,我们称为支持向量
• 通过拉格朗日乘子法,我们来求得这些支持向量
松弛变量:
• 数据集中异常点的存在,让最大间隔编写,如果我们能够容忍一些点存在,我们依旧能够得到一个比较宽的间隔,这本质上是一种妥协
• 松弛变量能够让我们得到一个2ε的回归带
集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,也称为多分类器系统(multi-classifier)、基于委员会的学习(committee-base learning)。
- 一个简单的更好的分类器是将这个分类器放到一起进行分类预测,采用投票表决的方法(a hard voting classifier)进行分类决定。
- 根据基分类器的生成方式,集成学习可以分为两大类:
个体的学习器之间存在着很强的依赖关系,必须串行生成的方法,代表的是Boosting(演进)
另一种不存在强的依赖关系,可以同时生成的并行化方法:
1) Bagging
2)Random Forest
Boosting原理


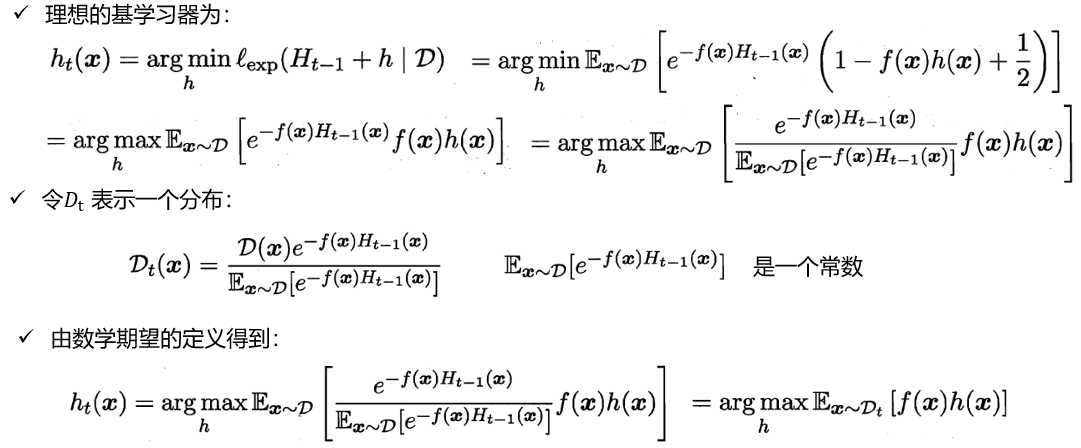

AdaBoost算法的例子
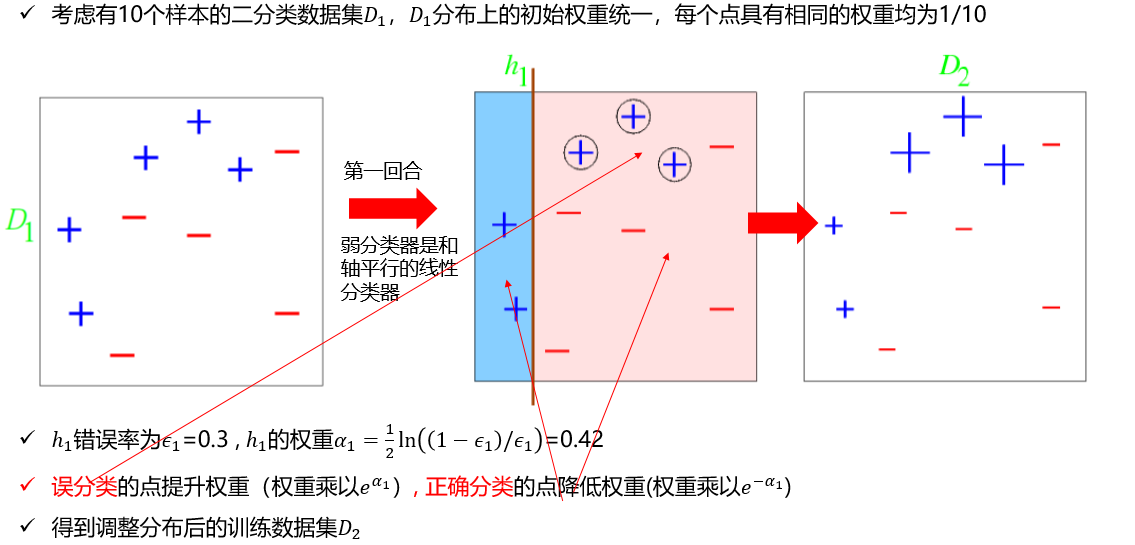
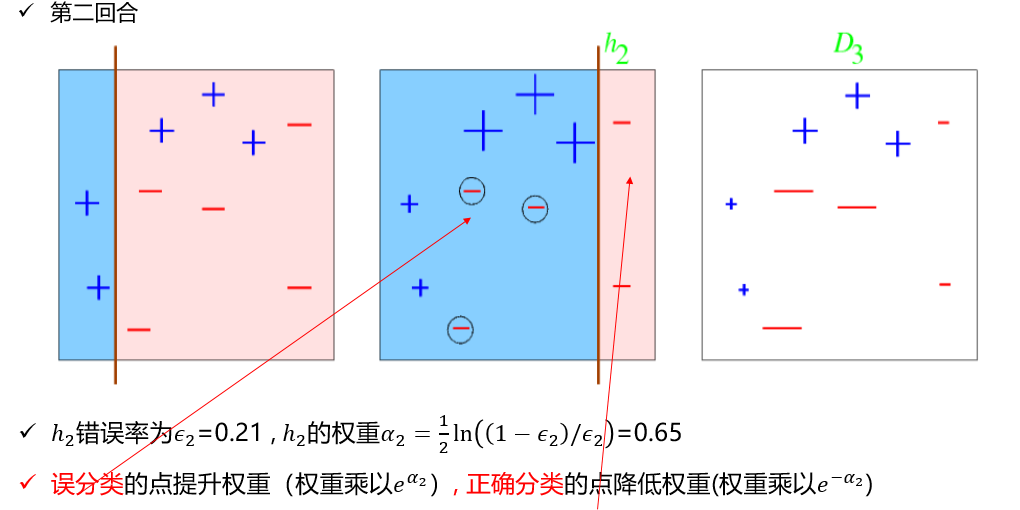
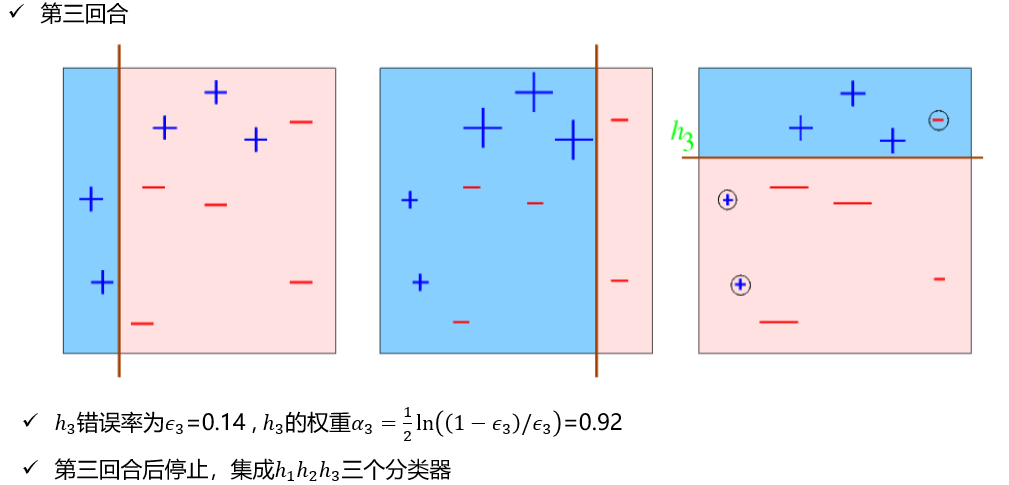
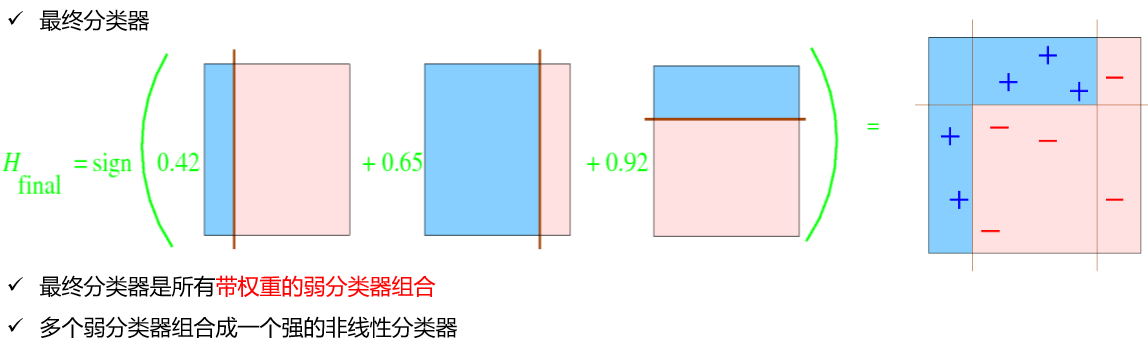
Q:
题中有3个样本,在Boosting中,每个样本的初始化权重为:1/n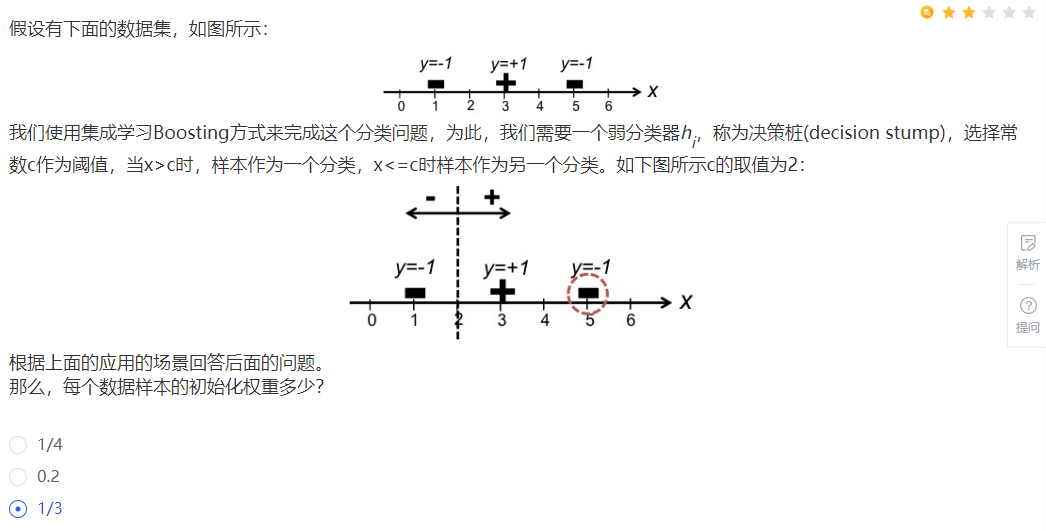
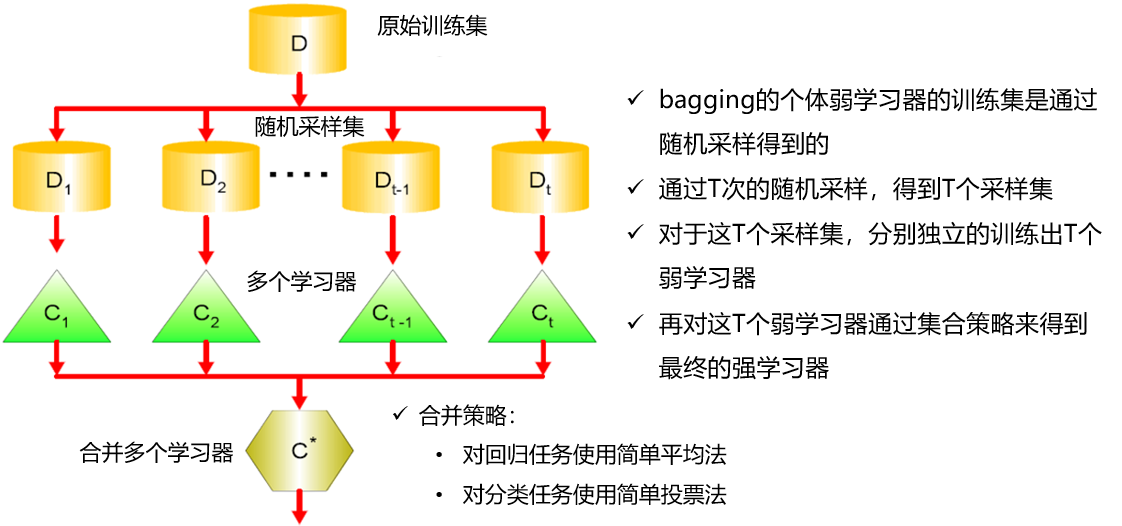
Bagging的定义

Bagging原理
随机森林
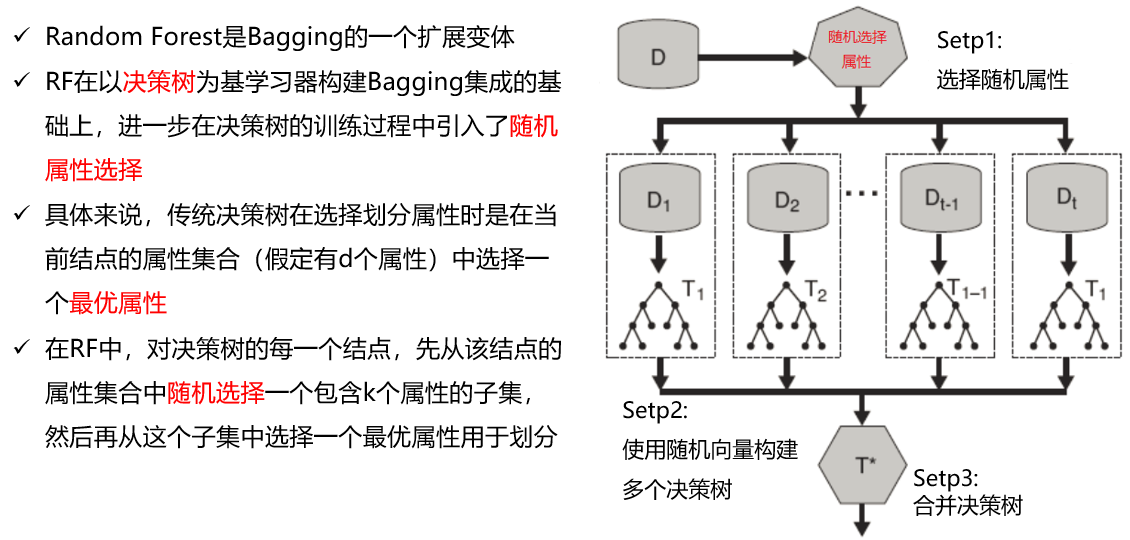
- 随机森林在建立每一棵决策树的过程中,有两点需要注意:采样与完全分裂。
- 对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现过拟合
- 然后进行列采样,从M个feature中,选择m个(m << M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。
- 决策树中的熵的概念:比较不同特征的分类效果
Boosting和Bagging区别
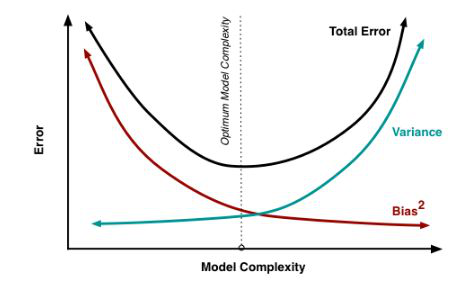
ü 从偏差-方差分解的角度看:
• Boosting主要关注降低偏差,能基于泛化性能相当弱的学习器构建出很强的集成
• Bagging主要关注降低方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更加明显
ü 从训练集的角度看:
• Bagging的训练集的选择是随机的,各轮训练集之间相互独立,采用均匀取样
• Boosting的各轮训练集的选择与前面各轮的学习结果有关,根据错误率来取样
• Boosting的分类精度要优于Bagging
ü 从预测函数的角度看:
• Bagging的各个预测函数没有权重,而Boosting是有权重的;
• Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成
ü 其他角度看:
• 对于像神经网络这样极为耗时的学习方法,Bagging可通过并行训练节省大量时间开销
• 两者都可以有效地提高分类的准确性。在大多数数据集中,boosting的准确性比bagging高。但在有些数据集中,boosting会导致过拟合
ü 偏差(Bias)和方差(Variance)如下图:
- 硬投票就是我们平常所说的:少数服从多数。按照硬投票的原理,大多数模型认同的结果将是最终的预测结果。
- Sklearn内置了RandomForestClassifier分类器和VotingClassifier分类器,在构造VotingClassifier分类器对象的时候,设置属性voting=’hard’即是硬投票模式。当然,倘若设置voting=’soft’,则为软投票。意味着分类器返回的结果是一组概率的加权平均。



结合方法
学习器结合方法如下:
ü 平均法:
• 简单平均法
• 加权平均法
ü 投票法:
• 绝对多数投票法
• 相对多数投票法
• 加权投票法
ü 学习法
投票法
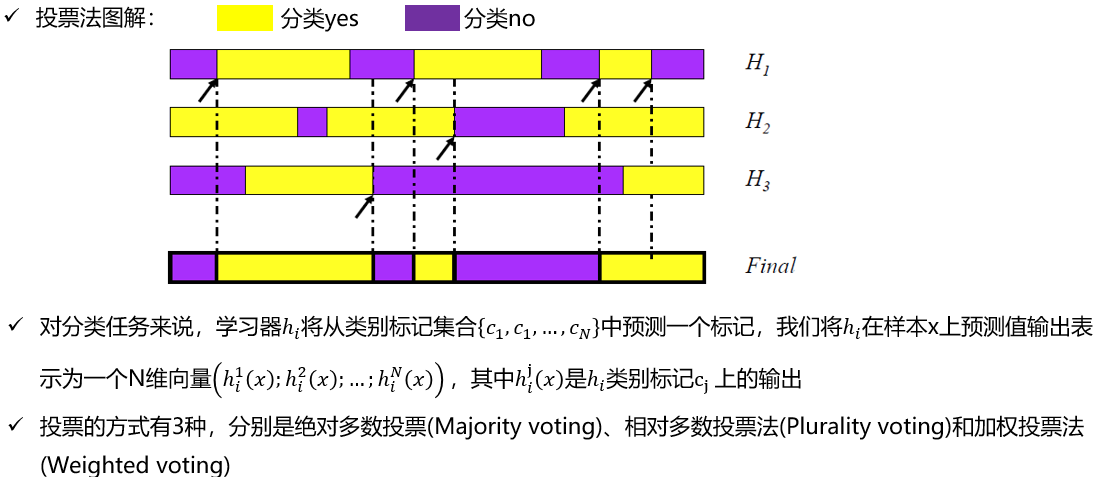

学习法
- 当训练数据很多时,采用更为强大的结合策略是使用学习法,即通过另一个学习器来进行结合。
- Stacking是学习法的典型代表。
- Stacking先从初始数据集训练出初级学习器,然后“生成”一个新的数据集用于训练次级学习器。在这个新的数据集中,初级学习器的输出被当作样例输入特征,而初级样本的标记仍被当作样例标记。
总结
集成学习:
Ø 欲得到泛化能力强的集成学习器,个体弱学习器应该尽可能相互独立
Ø 但在现实任务中无法做到,可以设法使弱学习器尽可能具有较大的差异
Ø 给定一个训练数据集,最有可能的做法是对训练样本进行采样,产生若干个不同的子集,再从每个数据子集中训练出一个弱学习器,由于训练数据的不同,获得的弱学习器可望具有较大的差异
Ø 如果采样出的每个子集完全不同,每个弱学习器只能用到一小部分训练数据,显然无法保证产出比较好的弱学习器
Ø 为解决这个问题,可以考虑使用相互交叠的采样子集
Bagging:
• Bagging直接基于自助采样(Bootstrap Sampling),又称有放回采样或可重复采样

• Bagging中的多个分类器的训练集来自同一个数据集的多次采样
• 训练多个分类器之后,采用投票的方式(voting)来生成预测结果
Boosting:
• 使用同一个数据训练不同的分类器(决策树、逻辑回归、贝叶斯分类器、SVM等)
• 训练完成之后,依旧采用投票的方式来生成预测结果
组合策略:
• 投票法
• 绝对多数投票法
• 相对多数投票法
• 加权投票法
• 平均法
• 简单平均法
• 加权平均法
• 学习法

若有收获,就点个赞吧
0 人点赞
