一 、List 和 Map、Set 的区别(必会)
List和Set是存储单列数据的集合,Map是存储键值对这样的双列数据的集合;
List: 中存储的数据是有顺序的,并且值允许重复;
Map: 中存储的数据是无序的,它的键是不允许重复的,但是值是允许重复的;
Set: 中存储的数据是无顺序的,并且不允许重复,但元素在集合中的位置是由元素的hashcode决定,即位置是固定的(Set集合是根据hashcode来进行数据存储的,所以位置是固定的,但是这个位置不是用户可以控制的,所以对于用户来说set中的元素还是无序的)。
二 、List 和 Map、Set 的实现类(必会)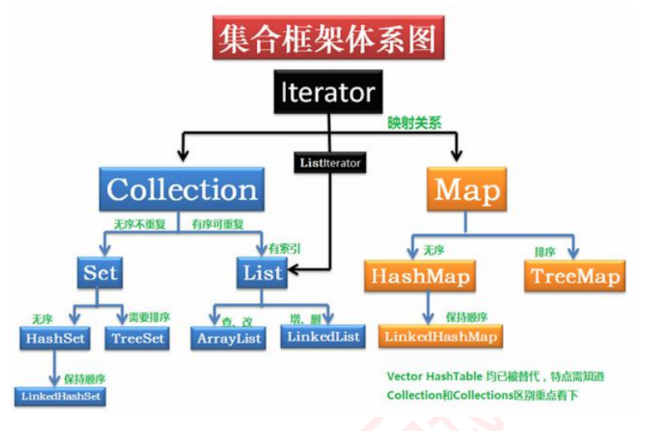
List 有序,可重复
ArrayList:
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
Vector:
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低, 已给舍弃了
LinkedList:
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高
Set 无序,唯一
HashSet:
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
依赖两个方法:hashCode()和equals()
LinkedHashSet:
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一
TreeSet:
底层数据结构是红黑树。(唯一,有序)
1. 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
(2)Map接口有四个实现类:
HashMap :
基于 hash 表的 Map 接口实现,非线程安全,高效,支持 null 值和 null 键, 线程不安全。
HashTable :
线程安全,低效,不支持 null 值和 null 键;
LinkedHashMap:
线程不安全,是 HashMap 的一个子类,保存了记录的插入顺序;
TreeMap:
能够把它保存的记录根据键排序,默认是键值的升序排序,线程不安全。
三 、HashSet的底层原理
底层数据结构是哈希表。(无序,唯一)
往HashSet添加元素的时候,HashSet会先调用元素的HashCode方法得到元素的哈希值,然后通过元素的哈希值经过异或移位等运算,就可以算出该元素在哈希表中的存储位置。然后调用元素的equals()方法比较元素内容是否相等,来确保元素的唯一性.
四 、泛型常用特点
所谓泛型,就是允许在定义类、接口时通过一个标识表示类中某个属性的类型或者是某个方法的返
回值及参数类型。这个类型参数将在使用时(例如,继承或实现这个接口,用这个类型声明变量、
创建对象时确定(即传入实际的类型参数,也称为类型实参)。
泛型是Java SE 1.5之后的特性,《Java 核心技术》中对泛型的定义是:“泛型” 意味着编写的代码可以被不同类型的对象所重用。“泛型”,顾名思义,“泛指的类型”。我们提供了泛指的概念,但具体执行的时候却可以有具体的规则来约束,比如我们用的非常多的ArrayList就是个泛型类,ArrayList作为集合可以存放各种元素,如Integer, String,自定义的各种类型等,但在我们使用的时候通过具体的规则来约束,如我们可以约束集合中只存放Integer类型的元素,如
使用泛型的好处?
以集合来举例,使用泛型的好处是我们不必因为添加元素类型的不同而定义不同类型的集合,如整型集合类,浮点型集合类,字符串集合类,我们可以定义一个集合来存放整型、浮点型,字符串型数据,而这并不是最重要的,因为我们只要把底层存储设置了Object即可,添加的数据全部都可向上转型为Object。 更重要的是我们可以通过规则按照自己的想法控制存储的数据类型。
五、 Collection包结构,与Collections的区别?
Collection是集合类的上级接口,子接口有 Set、List、LinkedList、ArrayList、Vector、Stack、Set;Collections是集合类的一个帮助类,它包含有各种有关集合操作的静态多态方法,用于实现对各种集合的搜索、排序、线程安全化等操作。此类不能实例化,就像一个工具类,服务于Java的Collection框架。

若有收获,就点个赞吧
0 人点赞
