一,urllib.parse 模块
是什么:这个是python的一个模块,可以直接拿过来使用
可以做什么:可以把前端浏览器发过来的内容进行一定的修改
由于python不像js直接运行在浏览器里面,使用浏览器的api,浏览器做了url的一些编解码操作,python这样其他的后端语言需要使用一定的方法才能对url进行操作,以便浏览器识别,所以才有这个模块的出现,就是封装了一系列url操作的模块
使用时需要导入对应的模块
from urllib import parse
unquote 解码方法
使用场景:
在web框架时,前端如果使用get请求并且输入中文,浏览器的url可以显示完整,但是传给后端的请求会造成url显示为乱码,所以需要后端python对其进行解码,python就提供了一个urllib.parse的编解码模块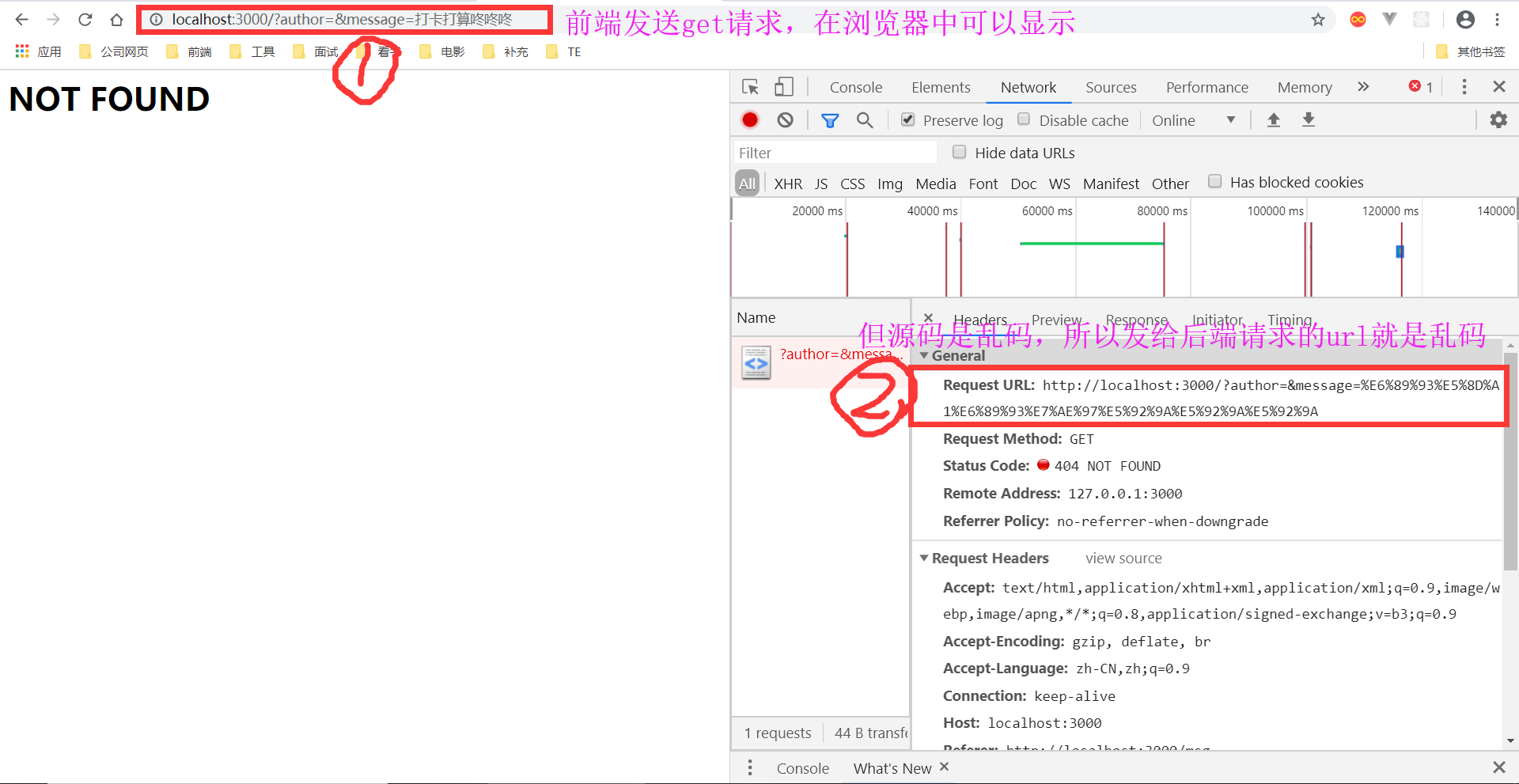
# unquote:可以将URL编码进行解码url = 'http://www.baidu.com/s?wd=%E4%B8%AD%E5%9B%BD%E6%A2%A6'print(parse.unquote(url))"""http://www.baidu.com/s?wd=中国梦"""
与之对应的 quote 编码
# quote 编码word = '中国梦'url = 'http://www.baidu.com/s?wd='+parse.quote(word)print(parse.quote(word))print(url)"""%E4%B8%AD%E5%9B%BD%E6%A2%A6http://www.baidu.com/s?wd=%E4%B8%AD%E5%9B%BD%E6%A2%A6"""
urlencode() 返回字符串
将字典构形式的参数序列化为url编码后的字符串
parmas = {'wd':'123','page':20}parmas_str = parse.urlencode(parmas)print(parmas_str)"""page=20&wd=123"""
与之对应 parse_qs 方法
parse_qs()将url编码格式的字符串参数反序列化为字典类型
parmas_str = 'page=20&wd=123'parmas = parse.parse_qs(parmas_str)print(parmas)"""{'page': ['20'], 'wd': ['123']}"""
urljoin()方法 是python拼接 url字符串
传递一个基础链接,根据基础链接可以将某一个不完整的链接拼接为一个完整链接
base_url = 'https://book.qidian.com/info/1004608738?wd=123&page=20#Catalog'sub_url = '/info/100861102'full_url = parse.urljoin(base_url,sub_url)print(full_url)
urlunparse() 改造url
可以修改url,给一些url必须参数,可以使用此方法把这些参数合并为一个url连接
url_parmas = ('https', 'book.qidian.com', '/info/1004608738', '', 'wd=123&page=20', 'Catalog')result = parse.urlunparse(url_parmas)print(result)"""https://book.qidian.com/info/1004608738?wd=123&page=20#Catalog"""
urlparse 方法 解析url内容
url = 'https://book.qidian.com/info/1004608738?wd=123&page=20#Catalog'"""url:待解析的urlscheme='':假如解析的url没有协议,可以设置默认的协议,如果url有协议,设置此参数无效allow_fragments=True:是否忽略锚点,默认为True表示不忽略,为False表示忽略"""result = parse.urlparse(url=url,scheme='http',allow_fragments=True)print(result)print(result.scheme)"""(scheme='https', netloc='book.qidian.com', path='/info/1004608738', params='', query='wd=123&page=20', fragment='Catalog')scheme:表示协议netloc:域名path:路径params:参数query:查询条件,一般都是get请求的urlfragment:锚点,用于直接定位页面的下拉位置,跳转到网页的指定位置"""
参考连接:
https://www.jianshu.com/p/e7d87e1ed38c
二,time方法
time time方法
time strftime方法
返回可读的字符串
time.strftime(format[, t])
两者联系:
1,返回内容不同,一个是时间戳,一个是字符串
2,参数不同,一个不需要参数,一个需要格式的参数
3,两者可以互相转化

若有收获,就点个赞吧
0 人点赞
