特别说明:本示例的主要目的仅仅是告诉大家如何使用LTS,所以偷了个懒,将所有节点都揉合到了一个工程,实际项目是分开部署的,因需而定。
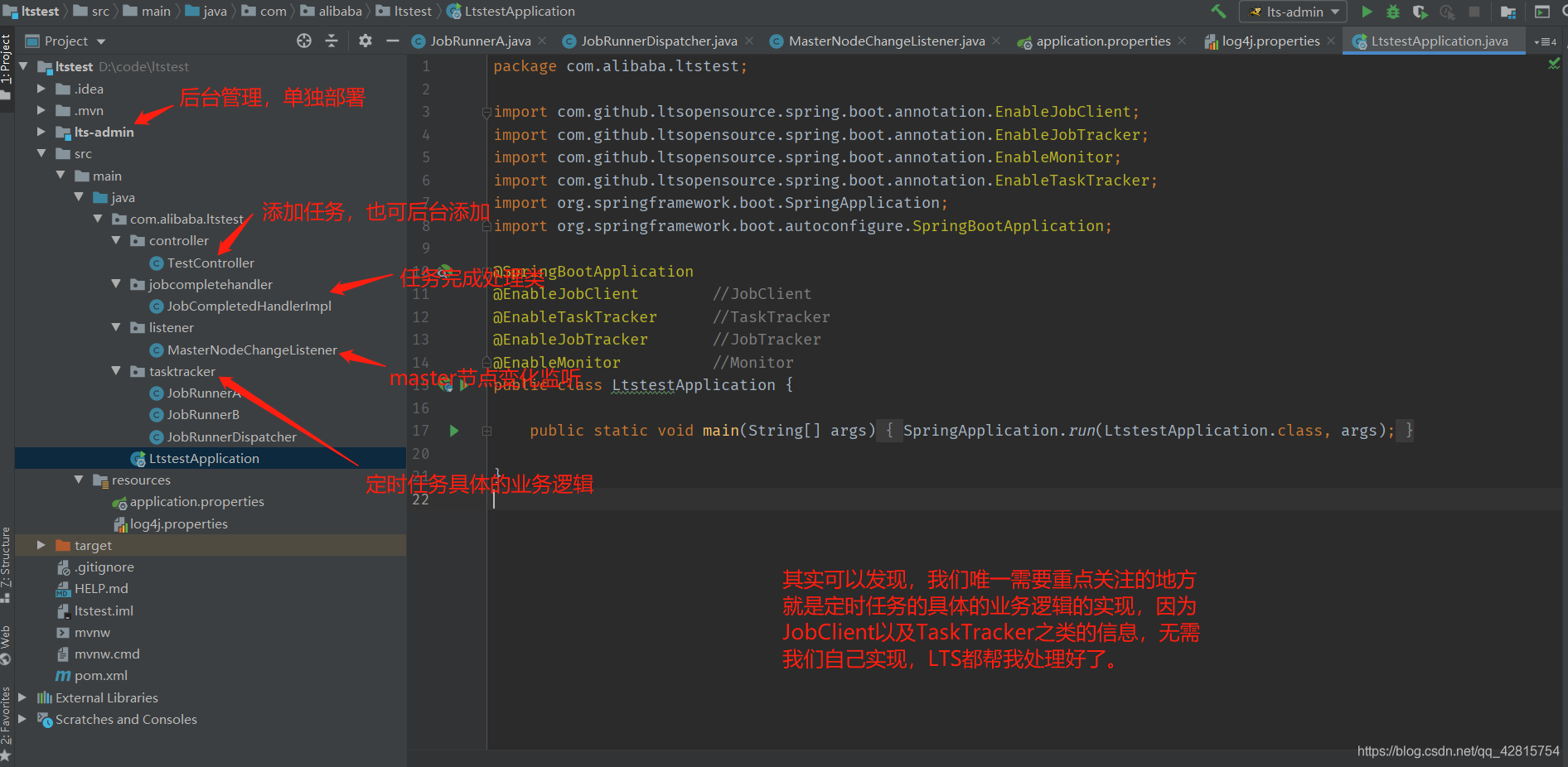
(1) 准备工作
- 新建SpringBoot工程
-
(1.1) 项目依赖
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--lts--><dependency><groupId>com.github.ltsopensource</groupId><artifactId>lts</artifactId><version>1.7.0</version></dependency><dependency><groupId>io.netty</groupId><artifactId>netty-all</artifactId><version>4.1.25.Final</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.58</version></dependency><dependency><groupId>org.mapdb</groupId><artifactId>mapdb</artifactId><version>2.0-beta10</version></dependency><dependency><groupId>com.101tec</groupId><artifactId>zkclient</artifactId><version>0.3</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.0.14</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.26</version></dependency><dependency><groupId>org.javassist</groupId><artifactId>javassist</artifactId><version>3.20.0-GA</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>
注意:
如果你用的是Redis作为注册中心,mongodb作为任务队列,那么请引入相应的依赖,我这里用的是Zookeeper和mysql。
(1.2) 项目配置文件
配置文件:
# 应用名称spring.application.name=ltsserver.port=8081########################################### jobclient->负责提交任务以及接收任务执行结果 ############################################集群名称lts.jobclient.cluster-name=test_cluster#注册中心lts.jobclient.registry-address=zookeeper://127.0.0.1:2181#JobClient节点组名称lts.jobclient.node-group=test_jobClient#是否使用RetryClientlts.jobclient.use-retry-client=true#失败存储,用于服务正常后再次执行(容错处理)lts.jobclient.configs.job.fail.store=mapdb######################################## jobtracker->负责调度任务 接收并分配任务 ########################################lts.jobtracker.cluster-name=test_clusterlts.jobtracker.listen-port=35001lts.jobtracker.registry-address=zookeeper://127.0.0.1:2181lts.jobtracker.configs.job.logger=mysqllts.jobtracker.configs.job.queue=mysqllts.jobtracker.configs.jdbc.url=jdbc:mysql://rm-2ze29e1gr6iu0p31oko.mysql.rds.aliyuncs.com:3306/lts?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=UTClts.jobtracker.configs.jdbc.username=rootlts.jobtracker.configs.jdbc.password=自己mysql的密码############################################################ tasktracker->负责执行任务 执行完任务将执行结果反馈给JobTracker #############################################################lts.tasktracker.cluster-name=test_clusterlts.tasktracker.registry-address=zookeeper://127.0.0.1:2181#TaskTracker节点组默认是64个线程用于执行任务#lts.tasktracker.work-threads=64lts.tasktracker.node-group=test_trade_TaskTracker#lts.tasktracker.dispatch-runner.enable=true#lts.tasktracker.dispatch-runner.shard-value=taskIdlts.tasktracker.configs.job.fail.store=mapdb################################################################# jmonitor->负责收集各个节点的监控信息,包括任务监控信息,节点JVM监控信息 #################################################################lts.monitor.cluster-name=test_clusterlts.monitor.registry-address=zookeeper://127.0.0.1:2181lts.monitor.configs.job.logger=mysqllts.monitor.configs.job.queue=mysqllts.monitor.configs.jdbc.url=jdbc:mysql://rm-2ze29e1gr6iu0p31oko.mysql.rds.aliyuncs.com:3306/lts?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=UTClts.monitor.configs.jdbc.username=rootlts.monitor.configs.jdbc.password=自己mysql的密码################################################################################ log4j.properties日志配置文件 ####################################################################################log4j.rootLogger=INFO,stdoutlog4j.appender.stdout.Threshold=INFOlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%d [%t] (%F:%L) %-5p %c %x - %m%n
(1.3) 数据库操作
在mysql数据库中创建一个新的数据库lts即可,项目初始化会自动创建相应表格
完成以上准备工作之后,接着便是实现任务提交以及任务执行了。
另外说明:以上配置信息,均可以在官方示例lts-example找到。
(2) 项目启动类设置
开启相应注解即可:
@SpringBootApplication@EnableJobClient //JobClient@EnableTaskTracker //TaskTracker@EnableJobTracker //JobTracker@EnableMonitor //Monitorpublic class LtstestApplication {public static void main(String[] args) {SpringApplication.run(LtstestApplication.class, args);}}
(3)JobClient提交任务
关于**Jobclient使用的官方建议**:
一般在一个JVM中只需要一个JobClient实例即可,不要为每种任务都新建一个JobClient实例,这样会大大的浪费资源,因为一个JobClient可以提交多种任务。
本示例中,我直接写在了TestController中,模拟了提交两个不同的任务:
@Autowiredprivate JobClient jobClient;@GetMapping("test01")public Map<String, Object> test01() {//模拟提交一个任务Job job = new Job();job.setTaskId("task-AAAAAAAAAAAAAAA");job.setCronExpression("0/3 * * * * ?");//设置任务类型 区分不同的任务 执行不同的业务逻辑job.setParam("type", "aType");job.setNeedFeedback(true);//任务触发时间 如果设置了 cron 则该设置无效// job.setTriggerTime(DateUtils.addDay(new Date(), 1).getTime());//任务执行节点组job.setTaskTrackerNodeGroup("test_trade_TaskTracker");//当任务队列中存在这个任务的时候,是否替换更新job.setReplaceOnExist(false);Map<String, Object> submitResult = new HashMap<String, Object>(4);try {//任务提交返回值 responseResponse response = jobClient.submitJob(job);submitResult.put("success", response.isSuccess());submitResult.put("msg", response.getMsg());submitResult.put("code", response.getCode());} catch (Exception e) {log.error("提交任务失败", e);throw new RuntimeException("提交任务失败");}return submitResult;}@GetMapping("test02")public Map<String, Object> test02() {//模拟提交一个任务Job job = new Job();job.setTaskId("task-BBBBBBBBBBBBBBB");job.setCronExpression("0/6 * * * * ?");//设置任务类型 区分不同的任务 执行不同的业务逻辑job.setParam("type", "bType");job.setNeedFeedback(true);//任务触发时间 如果设置了 cron 则该设置无效// job.setTriggerTime(DateUtils.addDay(new Date(), 1).getTime());//任务执行节点组job.setTaskTrackerNodeGroup("test_trade_TaskTracker");//当任务队列中存在这个任务的时候,是否替换更新job.setReplaceOnExist(false);Map<String, Object> submitResult = new HashMap<String, Object>(4);try {Response response = jobClient.submitJob(job);submitResult.put("success", response.isSuccess());submitResult.put("msg", response.getMsg());submitResult.put("code", response.getCode());} catch (Exception e) {log.error("提交任务失败", e);throw new RuntimeException("提交任务失败");}return submitResult;}
注意:JobClient我们可以直接引入,然后构建一个Job,通过JobClient进行提交。任务提交之后,JobTracker会对任务进行分发,分发方式有如下两种:
TaskTracker会定时发送pull请求给JobTracker, 默认1s一次, 在发送pull请求之前,会检查当前TaskTracker是否有可用的空闲线程,如果没有则不会发送pull请求,同时也会检查本节点机器资源是否足够,主要是检查cpu和内存使用率,默认超过90%就不会发送pull请求,当JobTracker收到TaskTracker节点的pull请求之后,再从任务队列中取出相应的已经到了执行时间点的任务 push给TaskTracker,这里push的个数等于TaskTracker的空余线程数。
还有一种途径是,每个TaskTracker线程处理完当前任务之后,在反馈给JobTracker的时候,同时也会询问JobTracker是否有新的任务需要执行,如果有JobTracker会同时返回给TaskTracker一个新的任务执行。所以在任务量足够大的情况下,每个TaskTracker基本上是满负荷的执行的。
(4) TaskTracker执行任务
关于TaskTracker使用的官方建议:
一个JVM一般也尽量保持只有一个TaskTracker实例即可,多了就可能造成资源浪费。
当遇到一个TaskTracker要运行多种任务的时候,在一个JVM中,最好使用一个TaskTracker去运行多种任务,因为一个JVM中使用多个TaskTracker实例比较浪费资源(当然当你某种任务量比较多的时候,可以将这个任务单独使用一个TaskTracker节点来执行)。
上面提交了两个任务,分别是任务A和任务B,所以这里演示的是一个TaskTracker执行多种不同的任务。
任务的执行必须实现JobRunner接口,如下任务A:
public class JobRunnerA implements JobRunner {@Overridepublic Result run(JobContext jobContext) throws Throwable {// TODO A类型Job的逻辑System.out.println("我是Runner A");return null;}}
任务B同理,就不重复贴出代码了
需要指出的是,在SpringBoot中,任务的执行需要添加**@JobRunner4TaskTracker注解**,但是有且**只能有一个@JobRunner4TaskTracker注解**。所以,对于同一个TaskTracker执行不同的任务,需要进行调度执行,如下:
/*** 总入口,在 taskTracker.setJobRunnerClass(JobRunnerDispatcher.class)* JobClient 提交 任务时指定 Job 类型 job.setParam("type", "aType")*/@JobRunner4TaskTrackerpublic class JobRunnerDispatcher implements JobRunner {private static final Logger log = LoggerFactory.getLogger(JobRunnerDispatcher.class);private static final ConcurrentHashMap<String/*type*/, JobRunner>JOB_RUNNER_MAP = new ConcurrentHashMap<String, JobRunner>();static {JOB_RUNNER_MAP.put("aType", new JobRunnerA()); // 也可以从Spring中拿JOB_RUNNER_MAP.put("bType", new JobRunnerB());}@Overridepublic Result run(JobContext jobContext) throws Throwable {Job job = jobContext.getJob();String type = job.getParam("type");return JOB_RUNNER_MAP.get(type).run(jobContext);}}
说明:
该JobRunnerDispatcher 类同样实现了JobRunner接口,并且添加了@JobRunner4TaskTracker注解,表示该类才是真正会执行任务的地方。通过该类,实现不同的任务执行。
实际上,到这里基本整个LTS任务从提交到执行就已经完成了,也就是简单的集成完成了。
可以直接启动项目了
(5) master节点监听以及任务完成处理类
这个不必多说,直接看代码好了(来自lts-example):
/*** 主节点监听*/@MasterNodeListenerpublic class MasterNodeChangeListener implements MasterChangeListener {private static final Logger log = LoggerFactory.getLogger(MasterNodeChangeListener.class);/*** @param master master节点* @param isMaster 表示当前节点是不是master节点*/@Overridepublic void change(Node master, boolean isMaster) {// 一个节点组master节点变化后的处理 , 譬如我多个JobClient, 但是有些事情只想只有一个节点能做。if (isMaster) {log.info("我变成了节点组中的master节点了, 恭喜, 我要放大招了");} else {log.info(StringUtils.format("master节点变成了{},不是我,我不能放大招,要猥琐", master));}}}
/*** 任务完成处理类*/@Componentpublic class JobCompletedHandlerImpl implements JobCompletedHandler {private static final Logger log = LoggerFactory.getLogger(JobCompletedHandlerImpl.class);@Overridepublic void onComplete(List<JobResult> jobResults) {//对任务执行结果进行处理 打印相应的日志信息if (CollectionUtils.isNotEmpty(jobResults)) {for (JobResult jobResult : jobResults) {String time = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date());log.info("任务执行完成taskId={}, 执行完成时间={}, job={}",jobResult.getJob().getTaskId(), time, jobResult.getJob().toString());}}}}
(6) Admin后台管理
(6.1) 下载源码
(6.2) 修改配置文件
lts-admin项目下\lightTaskScheduler\lts-admin\src\main\resources
lts-admin.cfg配置文件:(主要修改mysql和zookeeper地址)
// 后台的用户名密码console.username=adminconsole.password=admin# 注册中心地址,可以是zk,也可以是redisregistryAddress=zookeeper://127.0.0.1:2181# registryAddress=redis://127.0.0.1:6379# 集群名称clusterName=test_cluster# zk客户端,可选值 zkclient, curatorconfigs.zk.client=zkclient# ------ 这个是Admin存储数据的地方,也可以和JobQueue的地址一样 ------configs.jdbc.url=jdbc:mysql://127.0.0.1:3306/ltsconfigs.jdbc.username=fioraconfigs.jdbc.password=fiora# admin 数据使用mysql 默认 mysql, 可以自行扩展jdbc.datasource.provider=mysql# 使用 可选值 fastjson, jackson# configs.lts.json=fastjson# 是否在admin启动monitor服务, monitor服务也可以单独启动lts.monitorAgent.enable=true#======================以下相关配置是JobTracker的JobQueue和JobLogger的相关配置 要保持和JobTracker一样==========================## (可选配置)jobT. 开头的, 因为JobTracker和Admin可能使用的数据库不是同一个# LTS业务日志, 可选值 mysql, mongojobT.job.logger=mysql# ---------以下是任务队列配置-----------# 任务队列,可选值 mysql, mongojobT.job.queue=mysql# ------ 1. 如果是mysql作为任务队列 (如果不配置,表示和Admin的在一个数据库)------# jobT.jdbc.url=jdbc:mysql://127.0.0.1:3306/lts# jobT.jdbc.username=root# jobT.jdbc.password=root# ------ 2. 如果是mongo作为任务队列 ------# jobT.mongo.addresses=127.0.0.1:27017# jobT.mongo.database=lts# jobT.mongo.username=xxx #如果有的话# jobT.mongo.password=xxx #如果有的话# admin 数据使用mysql 默认 mysql, 可以自行扩展# jobT.jdbc.datasource.provider=mysql
lts-monitor.cfg,自行修改zookeeper和mysql配置
# 注册中心地址,可以是zk,也可以是redisregistryAddress=zookeeper://127.0.0.1:2181# registryAddress=redis://127.0.0.1:6379# 集群名称clusterName=test_cluster# LTS业务日志, 可选值 mysql, mongoconfigs.job.logger=mysql# zk客户端,可选值 zkclient, curatorconfigs.zk.client=zkclient# ---------以下是任务队列配置-----------# 任务队列,可选值 mysql, mongoconfigs.job.queue=mysql# ------ 1. 如果是mysql作为任务队列 ------configs.jdbc.url=jdbc:mysql://127.0.0.1:3306/ltsconfigs.jdbc.username=fioraconfigs.jdbc.password=fiora# ------ 2. 如果是mongo作为任务队列 ------configs.mongo.addresses=127.0.0.1:27017configs.mongo.database=lts# configs.mongo.username=xxx #如果有的话# configs.mongo.password=xxx #如果有的话# admin 数据使用mysql, h2 默认 h2 embeddedjdbc.datasource.provider=mysql# 使用 可选值 fastjson, jackson# configs.lts.json=fastjson
(6.2) 编译打包
下载完的源码中,总目录下,有build.cmd脚本,执行该脚本
编译,获得lts-admin管理项目war包
(6.3) 启动访问
将war包扔给tomcat执行即可
访问路径:
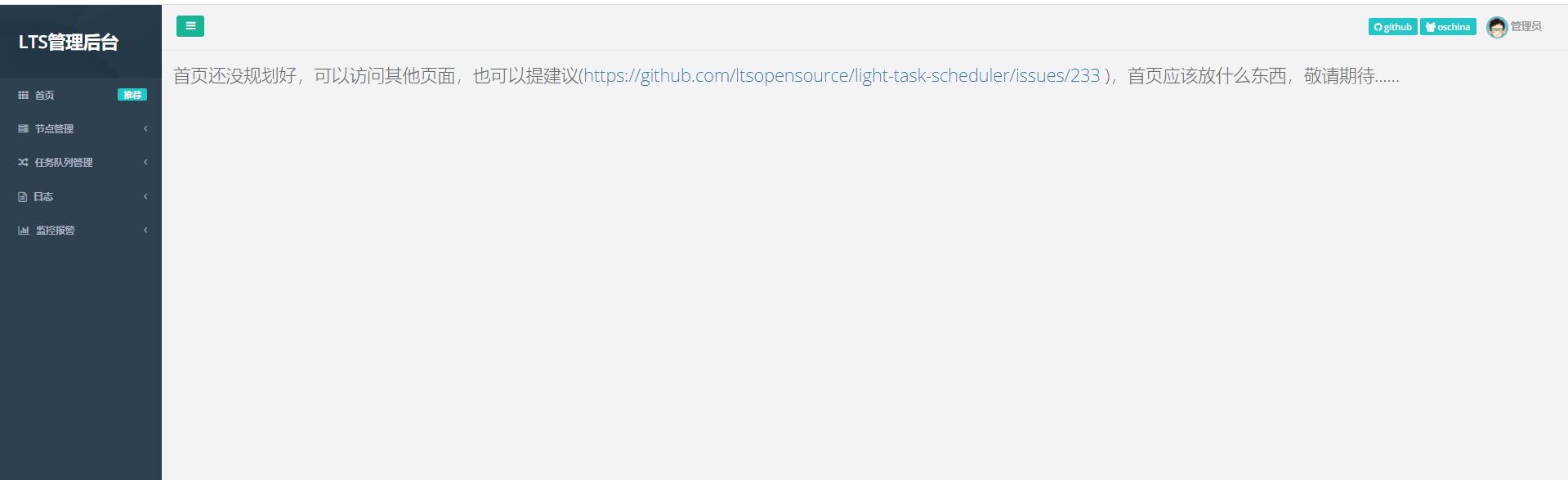
注意:默认账户密码为admin,admin

若有收获,就点个赞吧
0 人点赞
